 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Multiple Object Tracking based on Occlusion-Aware Embedding Consistency Learning
Nov 05, 2023
The Joint Detection and Embedding (JDE) framework has achieved remarkable progress for multiple object tracking. Existing methods often employ extracted embeddings to re-establish associations between new detections and previously disrupted tracks. However, the reliability of embeddings diminishes when the region of the occluded object frequently contains adjacent objects or clutters, especially in scenarios with severe occlusion. To alleviate this problem, we propose a novel multiple object tracking method based on visual embedding consistency, mainly including: 1) Occlusion Prediction Module (OPM) and 2) Occlusion-Aware Association Module (OAAM). The OPM predicts occlusion information for each true detection, facilitating the selection of valid samples for consistency learning of the track's visual embedding. The OAAM leverages occlusion cues and visual embeddings to generate two separate embeddings for each track, guaranteeing consistency in both unoccluded and occluded detections. By integrating these two modules, our method is capable of addressing track interruptions caused by occlusion in online tracking scenarios. Extensive experimental results demonstrate that our approach achieves promising performance levels in both unoccluded and occluded tracking scenarios.
The Background Also Matters: Background-Aware Motion-Guided Objects Discovery
Nov 05, 2023Recent works have shown that objects discovery can largely benefit from the inherent motion information in video data. However, these methods lack a proper background processing, resulting in an over-segmentation of the non-object regions into random segments. This is a critical limitation given the unsupervised setting, where object segments and noise are not distinguishable. To address this limitation we propose BMOD, a Background-aware Motion-guided Objects Discovery method. Concretely, we leverage masks of moving objects extracted from optical flow and design a learning mechanism to extend them to the true foreground composed of both moving and static objects. The background, a complementary concept of the learned foreground class, is then isolated in the object discovery process. This enables a joint learning of the objects discovery task and the object/non-object separation. The conducted experiments on synthetic and real-world datasets show that integrating our background handling with various cutting-edge methods brings each time a considerable improvement. Specifically, we improve the objects discovery performance with a large margin, while establishing a strong baseline for object/non-object separation.
AMIR: Automated MisInformation Rebuttal -- A COVID-19 Vaccination Datasets based Recommendation System
Oct 29, 2023Misinformation has emerged as a major societal threat in recent years in general; specifically in the context of the COVID-19 pandemic, it has wrecked havoc, for instance, by fuelling vaccine hesitancy. Cost-effective, scalable solutions for combating misinformation are the need of the hour. This work explored how existing information obtained from social media and augmented with more curated fact checked data repositories can be harnessed to facilitate automated rebuttal of misinformation at scale. While the ideas herein can be generalized and reapplied in the broader context of misinformation mitigation using a multitude of information sources and catering to the spectrum of social media platforms, this work serves as a proof of concept, and as such, it is confined in its scope to only rebuttal of tweets, and in the specific context of misinformation regarding COVID-19. It leverages two publicly available datasets, viz. FaCov (fact-checked articles) and misleading (social media Twitter) data on COVID-19 Vaccination.
Semantic Communications Based on Adaptive Generative Models and Information Bottleneck
Sep 05, 2023Semantic communications represent a significant breakthrough with respect to the current communication paradigm, as they focus on recovering the meaning behind the transmitted sequence of symbols, rather than the symbols themselves. In semantic communications, the scope of the destination is not to recover a list of symbols symbolically identical to the transmitted ones, but rather to recover a message that is semantically equivalent to the semantic message emitted by the source. This paradigm shift introduces many degrees of freedom to the encoding and decoding rules that can be exploited to make the design of communication systems much more efficient. In this paper, we present an approach to semantic communication building on three fundamental ideas: 1) represent data over a topological space as a formal way to capture semantics, as expressed through relations; 2) use the information bottleneck principle as a way to identify relevant information and adapt the information bottleneck online, as a function of the wireless channel state, in order to strike an optimal trade-off between transmit power, reconstruction accuracy and delay; 3) exploit probabilistic generative models as a general tool to adapt the transmission rate to the wireless channel state and make possible the regeneration of the transmitted images or run classification tasks at the receiver side.
Collaborative Large Language Model for Recommender Systems
Nov 08, 2023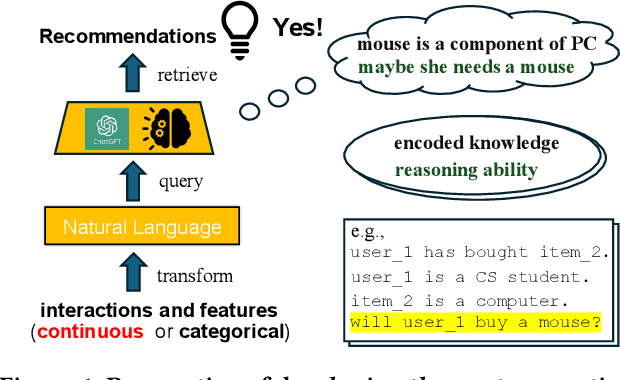
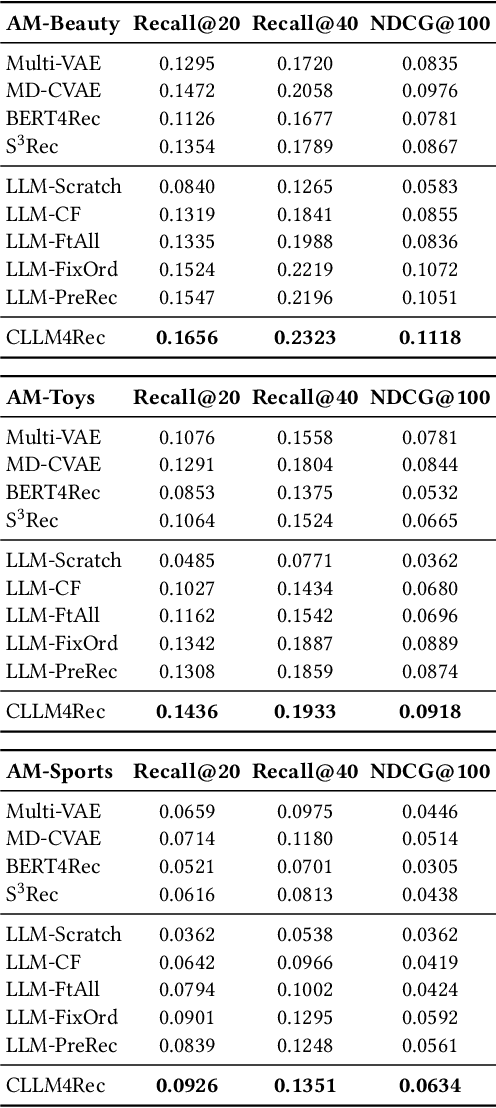
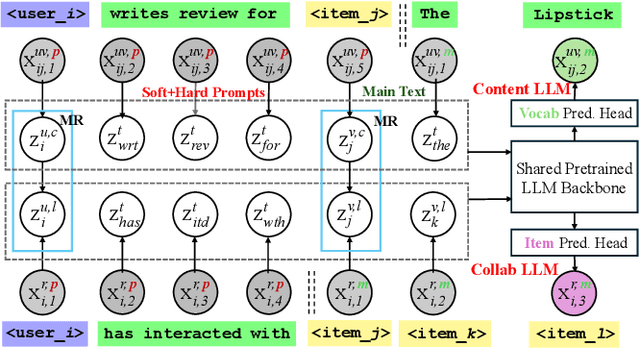
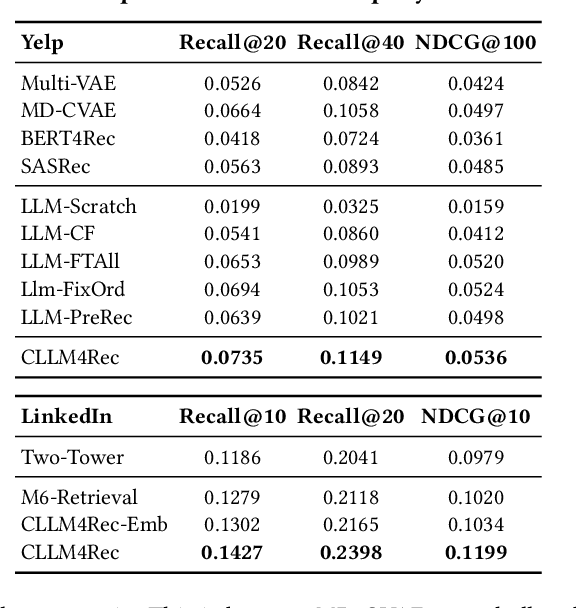
Recently, there is a growing interest in developing next-generation recommender systems (RSs) based on pretrained large language models (LLMs), fully utilizing their encoded knowledge and reasoning ability. However, the semantic gap between natural language and recommendation tasks is still not well addressed, leading to multiple issues such as spuriously-correlated user/item descriptors, ineffective language modeling on user/item contents, and inefficient recommendations via auto-regression, etc. In this paper, we propose CLLM4Rec, the first generative RS that tightly integrates the LLM paradigm and ID paradigm of RS, aiming to address the above challenges simultaneously. We first extend the vocabulary of pretrained LLMs with user/item ID tokens to faithfully model the user/item collaborative and content semantics. Accordingly, in the pretraining stage, a novel soft+hard prompting strategy is proposed to effectively learn user/item collaborative/content token embeddings via language modeling on RS-specific corpora established from user-item interactions and user/item features, where each document is split into a prompt consisting of heterogeneous soft (user/item) tokens and hard (vocab) tokens and a main text consisting of homogeneous item tokens or vocab tokens that facilitates stable and effective language modeling. In addition, a novel mutual regularization strategy is introduced to encourage the CLLM4Rec to capture recommendation-oriented information from user/item contents. Finally, we propose a novel recommendation-oriented finetuning strategy for CLLM4Rec, where an item prediction head with multinomial likelihood is added to the pretrained CLLM4Rec backbone to predict hold-out items based on the soft+hard prompts established from masked user-item interaction history, where recommendations of multiple items can be generated efficiently.
Rethinking Event-based Human Pose Estimation with 3D Event Representations
Nov 08, 2023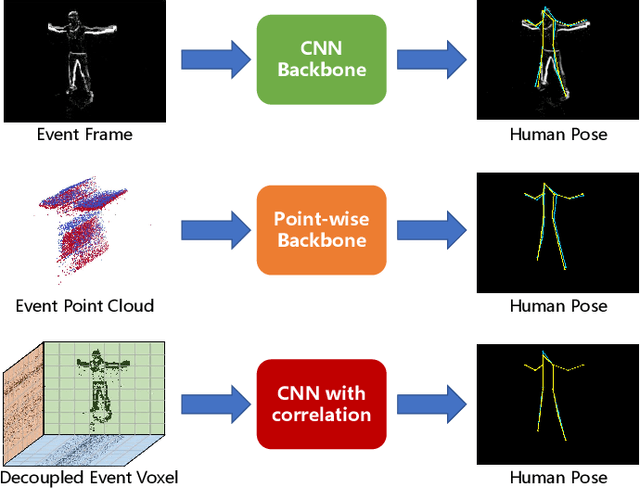
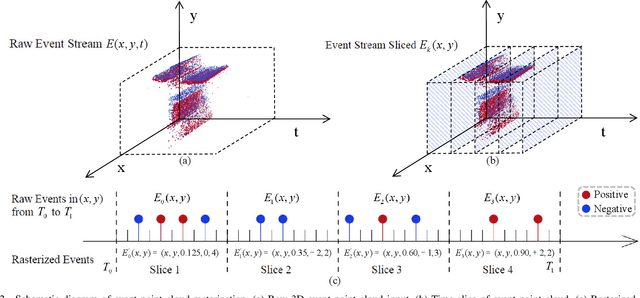
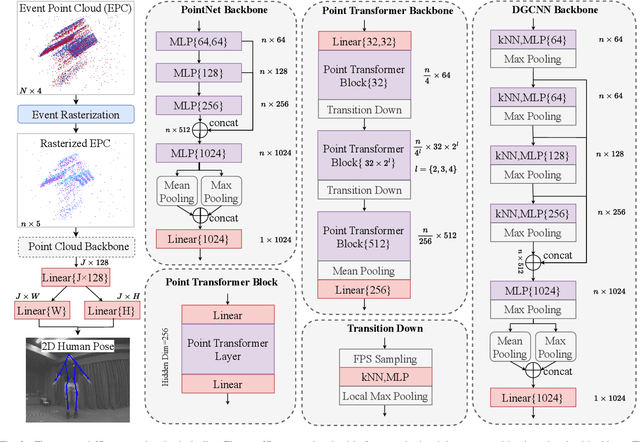
Human pose estimation is a critical component in autonomous driving and parking, enhancing safety by predicting human actions. Traditional frame-based cameras and videos are commonly applied, yet, they become less reliable in scenarios under high dynamic range or heavy motion blur. In contrast, event cameras offer a robust solution for navigating these challenging contexts. Predominant methodologies incorporate event cameras into learning frameworks by accumulating events into event frames. However, such methods tend to marginalize the intrinsic asynchronous and high temporal resolution characteristics of events. This disregard leads to a loss in essential temporal dimension data, crucial for safety-critical tasks associated with dynamic human activities. To address this issue and to unlock the 3D potential of event information, we introduce two 3D event representations: the Rasterized Event Point Cloud (RasEPC) and the Decoupled Event Voxel (DEV). The RasEPC collates events within concise temporal slices at identical positions, preserving 3D attributes with statistical cues and markedly mitigating memory and computational demands. Meanwhile, the DEV representation discretizes events into voxels and projects them across three orthogonal planes, utilizing decoupled event attention to retrieve 3D cues from the 2D planes. Furthermore, we develop and release EV-3DPW, a synthetic event-based dataset crafted to facilitate training and quantitative analysis in outdoor scenes. On the public real-world DHP19 dataset, our event point cloud technique excels in real-time mobile predictions, while the decoupled event voxel method achieves the highest accuracy. Experiments reveal our proposed 3D representation methods' superior generalization capacities against traditional RGB images and event frame techniques. Our code and dataset are available at https://github.com/MasterHow/EventPointPose.
Lidar Annotation Is All You Need
Nov 08, 2023In recent years, computer vision has transformed fields such as medical imaging, object recognition, and geospatial analytics. One of the fundamental tasks in computer vision is semantic image segmentation, which is vital for precise object delineation. Autonomous driving represents one of the key areas where computer vision algorithms are applied. The task of road surface segmentation is crucial in self-driving systems, but it requires a labor-intensive annotation process in several data domains. The work described in this paper aims to improve the efficiency of image segmentation using a convolutional neural network in a multi-sensor setup. This approach leverages lidar (Light Detection and Ranging) annotations to directly train image segmentation models on RGB images. Lidar supplements the images by emitting laser pulses and measuring reflections to provide depth information. However, lidar's sparse point clouds often create difficulties for accurate object segmentation. Segmentation of point clouds requires time-consuming preliminary data preparation and a large amount of computational resources. The key innovation of our approach is the masked loss, addressing sparse ground-truth masks from point clouds. By calculating loss exclusively where lidar points exist, the model learns road segmentation on images by using lidar points as ground truth. This approach allows for blending of different ground-truth data types during model training. Experimental validation of the approach on benchmark datasets shows comparable performance to a high-quality image segmentation model. Incorporating lidar reduces the load on annotations and enables training of image-segmentation models without loss of segmentation quality. The methodology is tested on diverse datasets, both publicly available and proprietary. The strengths and weaknesses of the proposed method are also discussed in the paper.
Automated Annotation of Scientific Texts for ML-based Keyphrase Extraction and Validation
Nov 08, 2023Advanced omics technologies and facilities generate a wealth of valuable data daily; however, the data often lacks the essential metadata required for researchers to find and search them effectively. The lack of metadata poses a significant challenge in the utilization of these datasets. Machine learning-based metadata extraction techniques have emerged as a potentially viable approach to automatically annotating scientific datasets with the metadata necessary for enabling effective search. Text labeling, usually performed manually, plays a crucial role in validating machine-extracted metadata. However, manual labeling is time-consuming; thus, there is an need to develop automated text labeling techniques in order to accelerate the process of scientific innovation. This need is particularly urgent in fields such as environmental genomics and microbiome science, which have historically received less attention in terms of metadata curation and creation of gold-standard text mining datasets. In this paper, we present two novel automated text labeling approaches for the validation of ML-generated metadata for unlabeled texts, with specific applications in environmental genomics. Our techniques show the potential of two new ways to leverage existing information about the unlabeled texts and the scientific domain. The first technique exploits relationships between different types of data sources related to the same research study, such as publications and proposals. The second technique takes advantage of domain-specific controlled vocabularies or ontologies. In this paper, we detail applying these approaches for ML-generated metadata validation. Our results show that the proposed label assignment approaches can generate both generic and highly-specific text labels for the unlabeled texts, with up to 44% of the labels matching with those suggested by a ML keyword extraction algorithm.
Automatic Diary Generation System including Information on Joint Experiences between Humans and Robots
Sep 05, 2023In this study, we propose an automatic diary generation system that uses information from past joint experiences with the aim of increasing the favorability for robots through shared experiences between humans and robots. For the verbalization of the robot's memory, the system applies a large-scale language model, which is a rapidly developing field. Since this model does not have memories of experiences, it generates a diary by receiving information from joint experiences. As an experiment, a robot and a human went for a walk and generated a diary with interaction and dialogue history. The proposed diary achieved high scores in comfort and performance in the evaluation of the robot's impression. In the survey of diaries giving more favorable impressions, diaries with information on joint experiences were selected higher than diaries without such information, because diaries with information on joint experiences showed more cooperation between the robot and the human and more intimacy from the robot.
RegaVAE: A Retrieval-Augmented Gaussian Mixture Variational Auto-Encoder for Language Modeling
Oct 23, 2023Retrieval-augmented language models show promise in addressing issues like outdated information and hallucinations in language models (LMs). However, current research faces two main problems: 1) determining what information to retrieve, and 2) effectively combining retrieved information during generation. We argue that valuable retrieved information should not only be related to the current source text but also consider the future target text, given the nature of LMs that model future tokens. Moreover, we propose that aggregation using latent variables derived from a compact latent space is more efficient than utilizing explicit raw text, which is limited by context length and susceptible to noise. Therefore, we introduce RegaVAE, a retrieval-augmented language model built upon the variational auto-encoder (VAE). It encodes the text corpus into a latent space, capturing current and future information from both source and target text. Additionally, we leverage the VAE to initialize the latent space and adopt the probabilistic form of the retrieval generation paradigm by expanding the Gaussian prior distribution into a Gaussian mixture distribution. Theoretical analysis provides an optimizable upper bound for RegaVAE. Experimental results on various datasets demonstrate significant improvements in text generation quality and hallucination removal.