 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgexMOD: Cross-Modal Distillation for 2D/3D Multi-Object Discovery from 2D motion
Mar 19, 2025



Object discovery, which refers to the task of localizing objects without human annotations, has gained significant attention in 2D image analysis. However, despite this growing interest, it remains under-explored in 3D data, where approaches rely exclusively on 3D motion, despite its several challenges. In this paper, we present a novel framework that leverages advances in 2D object discovery which are based on 2D motion to exploit the advantages of such motion cues being more flexible and generalizable and to bridge the gap between 2D and 3D modalities. Our primary contributions are twofold: (i) we introduce DIOD-3D, the first baseline for multi-object discovery in 3D data using 2D motion, incorporating scene completion as an auxiliary task to enable dense object localization from sparse input data; (ii) we develop xMOD, a cross-modal training framework that integrates 2D and 3D data while always using 2D motion cues. xMOD employs a teacher-student training paradigm across the two modalities to mitigate confirmation bias by leveraging the domain gap. During inference, the model supports both RGB-only and point cloud-only inputs. Additionally, we propose a late-fusion technique tailored to our pipeline that further enhances performance when both modalities are available at inference. We evaluate our approach extensively on synthetic (TRIP-PD) and challenging real-world datasets (KITTI and Waymo). Notably, our approach yields a substantial performance improvement compared with the 2D object discovery state-of-the-art on all datasets with gains ranging from +8.7 to +15.1 in F1@50 score. The code is available at https://github.com/CEA-LIST/xMOD
GaussianBeV: 3D Gaussian Representation meets Perception Models for BeV Segmentation
Jul 19, 2024The Bird's-eye View (BeV) representation is widely used for 3D perception from multi-view camera images. It allows to merge features from different cameras into a common space, providing a unified representation of the 3D scene. The key component is the view transformer, which transforms image views into the BeV. However, actual view transformer methods based on geometry or cross-attention do not provide a sufficiently detailed representation of the scene, as they use a sub-sampling of the 3D space that is non-optimal for modeling the fine structures of the environment. In this paper, we propose GaussianBeV, a novel method for transforming image features to BeV by finely representing the scene using a set of 3D gaussians located and oriented in 3D space. This representation is then splattered to produce the BeV feature map by adapting recent advances in 3D representation rendering based on gaussian splatting. GaussianBeV is the first approach to use this 3D gaussian modeling and 3D scene rendering process online, i.e. without optimizing it on a specific scene and directly integrated into a single stage model for BeV scene understanding. Experiments show that the proposed representation is highly effective and place GaussianBeV as the new state-of-the-art on the BeV semantic segmentation task on the nuScenes dataset.
Smooth Pseudo-Labeling
May 23, 2024



Semi-Supervised Learning (SSL) seeks to leverage large amounts of non-annotated data along with the smallest amount possible of annotated data in order to achieve the same level of performance as if all data were annotated. A fruitful method in SSL is Pseudo-Labeling (PL), which, however, suffers from the important drawback that the associated loss function has discontinuities in its derivatives, which cause instabilities in performance when labels are very scarce. In the present work, we address this drawback with the introduction of a Smooth Pseudo-Labeling (SP L) loss function. It consists in adding a multiplicative factor in the loss function that smooths out the discontinuities in the derivative due to thresholding. In our experiments, we test our improvements on FixMatch and show that it significantly improves the performance in the regime of scarce labels, without addition of any modules, hyperparameters, or computational overhead. In the more stable regime of abundant labels, performance remains at the same level. Robustness with respect to variation of hyperparameters and training parameters is also significantly improved. Moreover, we introduce a new benchmark, where labeled images are selected randomly from the whole dataset, without imposing representation of each class proportional to its frequency in the dataset. We see that the smooth version of FixMatch does appear to perform better than the original, non-smooth implementation. However, more importantly, we notice that both implementations do not necessarily see their performance improve when labeled images are added, an important issue in the design of SSL algorithms that should be addressed so that Active Learning algorithms become more reliable and explainable.
RING-NeRF: A Versatile Architecture based on Residual Implicit Neural Grids
Dec 06, 2023Since their introduction, Neural Fields have become very popular for 3D reconstruction and new view synthesis. Recent researches focused on accelerating the process, as well as improving the robustness to variation of the observation distance and limited number of supervised viewpoints. However, those approaches often led to dedicated solutions that cannot be easily combined. To tackle this issue, we introduce a new simple but efficient architecture named RING-NeRF, based on Residual Implicit Neural Grids, that provides a control on the level of detail of the mapping function between the scene and the latent spaces. Associated with a distance-aware forward mapping mechanism and a continuous coarse-to-fine reconstruction process, our versatile architecture demonstrates both fast training and state-of-the-art performances in terms of: (1) anti-aliased rendering, (2) reconstruction quality from few supervised viewpoints, and (3) robustness in the absence of appropriate scene-specific initialization for SDF-based NeRFs. We also demonstrate that our architecture can dynamically add grids to increase the details of the reconstruction, opening the way to adaptive reconstruction.
MonoProb: Self-Supervised Monocular Depth Estimation with Interpretable Uncertainty
Nov 10, 2023



Self-supervised monocular depth estimation methods aim to be used in critical applications such as autonomous vehicles for environment analysis. To circumvent the potential imperfections of these approaches, a quantification of the prediction confidence is crucial to guide decision-making systems that rely on depth estimation. In this paper, we propose MonoProb, a new unsupervised monocular depth estimation method that returns an interpretable uncertainty, which means that the uncertainty reflects the expected error of the network in its depth predictions. We rethink the stereo or the structure-from-motion paradigms used to train unsupervised monocular depth models as a probabilistic problem. Within a single forward pass inference, this model provides a depth prediction and a measure of its confidence, without increasing the inference time. We then improve the performance on depth and uncertainty with a novel self-distillation loss for which a student is supervised by a pseudo ground truth that is a probability distribution on depth output by a teacher. To quantify the performance of our models we design new metrics that, unlike traditional ones, measure the absolute performance of uncertainty predictions. Our experiments highlight enhancements achieved by our method on standard depth and uncertainty metrics as well as on our tailored metrics. https://github.com/CEA-LIST/MonoProb
The Background Also Matters: Background-Aware Motion-Guided Objects Discovery
Nov 05, 2023



Recent works have shown that objects discovery can largely benefit from the inherent motion information in video data. However, these methods lack a proper background processing, resulting in an over-segmentation of the non-object regions into random segments. This is a critical limitation given the unsupervised setting, where object segments and noise are not distinguishable. To address this limitation we propose BMOD, a Background-aware Motion-guided Objects Discovery method. Concretely, we leverage masks of moving objects extracted from optical flow and design a learning mechanism to extend them to the true foreground composed of both moving and static objects. The background, a complementary concept of the learned foreground class, is then isolated in the object discovery process. This enables a joint learning of the objects discovery task and the object/non-object separation. The conducted experiments on synthetic and real-world datasets show that integrating our background handling with various cutting-edge methods brings each time a considerable improvement. Specifically, we improve the objects discovery performance with a large margin, while establishing a strong baseline for object/non-object separation.
Image Segmentation-based Unsupervised Multiple Objects Discovery
Dec 20, 2022



Unsupervised object discovery aims to localize objects in images, while removing the dependence on annotations required by most deep learning-based methods. To address this problem, we propose a fully unsupervised, bottom-up approach, for multiple objects discovery. The proposed approach is a two-stage framework. First, instances of object parts are segmented by using the intra-image similarity between self-supervised local features. The second step merges and filters the object parts to form complete object instances. The latter is performed by two CNN models that capture semantic information on objects from the entire dataset. We demonstrate that the pseudo-labels generated by our method provide a better precision-recall trade-off than existing single and multiple objects discovery methods. In particular, we provide state-of-the-art results for both unsupervised class-agnostic object detection and unsupervised image segmentation.
Self-Supervised Pre-training of Vision Transformers for Dense Prediction Tasks
Jun 07, 2022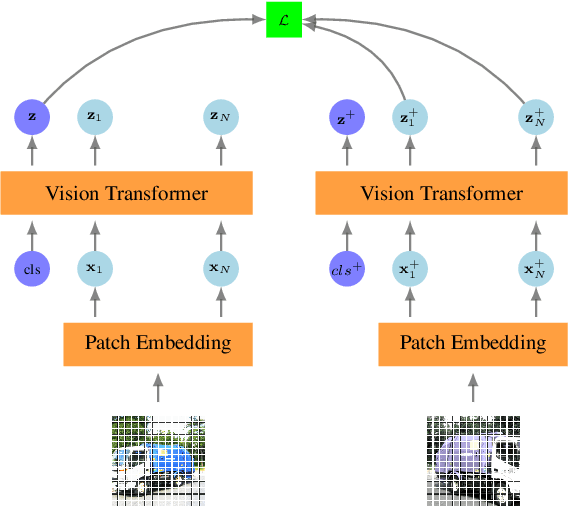
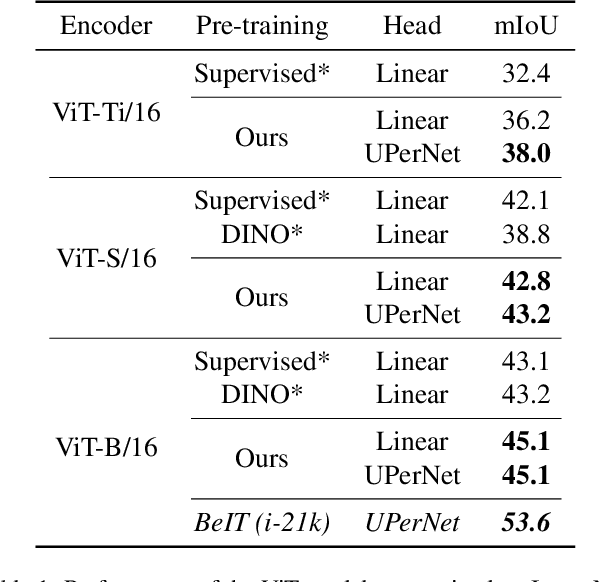
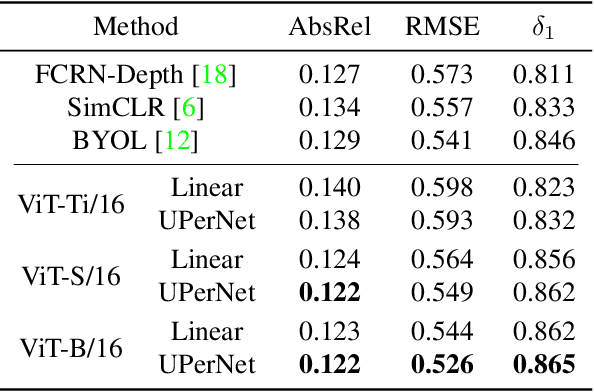
We present a new self-supervised pre-training of Vision Transformers for dense prediction tasks. It is based on a contrastive loss across views that compares pixel-level representations to global image representations. This strategy produces better local features suitable for dense prediction tasks as opposed to contrastive pre-training based on global image representation only. Furthermore, our approach does not suffer from a reduced batch size since the number of negative examples needed in the contrastive loss is in the order of the number of local features. We demonstrate the effectiveness of our pre-training strategy on two dense prediction tasks: semantic segmentation and monocular depth estimation.
PandaNet : Anchor-Based Single-Shot Multi-Person 3D Pose Estimation
Jan 07, 2021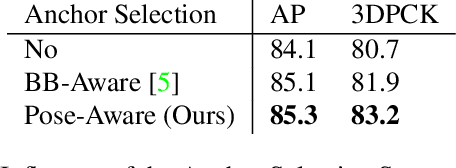

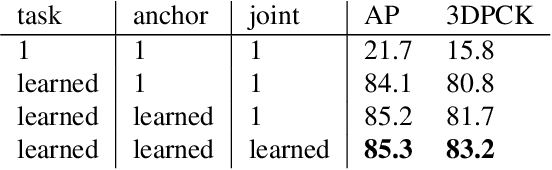

Recently, several deep learning models have been proposed for 3D human pose estimation. Nevertheless, most of these approaches only focus on the single-person case or estimate 3D pose of a few people at high resolution. Furthermore, many applications such as autonomous driving or crowd analysis require pose estimation of a large number of people possibly at low-resolution. In this work, we present PandaNet (Pose estimAtioN and Dectection Anchor-based Network), a new single-shot, anchor-based and multi-person 3D pose estimation approach. The proposed model performs bounding box detection and, for each detected person, 2D and 3D pose regression into a single forward pass. It does not need any post-processing to regroup joints since the network predicts a full 3D pose for each bounding box and allows the pose estimation of a possibly large number of people at low resolution. To manage people overlapping, we introduce a Pose-Aware Anchor Selection strategy. Moreover, as imbalance exists between different people sizes in the image, and joints coordinates have different uncertainties depending on these sizes, we propose a method to automatically optimize weights associated to different people scales and joints for efficient training. PandaNet surpasses previous single-shot methods on several challenging datasets: a multi-person urban virtual but very realistic dataset (JTA Dataset), and two real world 3D multi-person datasets (CMU Panoptic and MuPoTS-3D).
LapNet : Automatic Balanced Loss and Optimal Assignment for Real-Time Dense Object Detection
Nov 04, 2019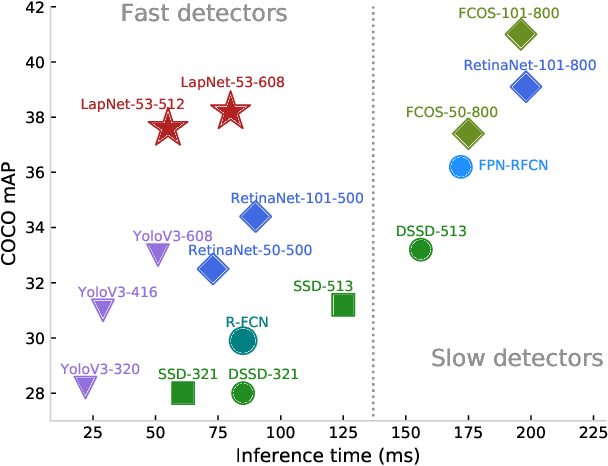
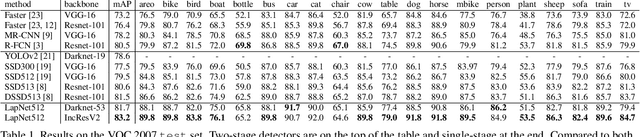

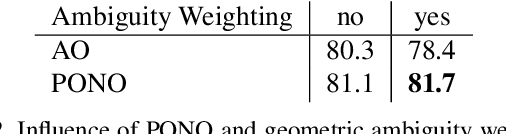
Several modern deep single-stage object detectors are really effective for real time processing but still remain less efficient than more complex ones. The trade-off between model performances and computing speed is an important challenge, directly related to the learning process. In this paper, we propose a new way to efficiently learn a single shot detector providing a very good trade-off between these two factors. For this purpose, we introduce LapNet, an anchor based detector, trained end-to-end without any sampling strategy. Our approach focuses on two limitations of anchor based detector training: (1) the ambiguity of anchor to ground truth assignment and (2) the imbalance between classes and the imbalance between object sizes. More specifically, a new method to assign positive and negative anchors is proposed, based on a new overlapping function called "Per-Object Normalized Overlap" (PONO). This more flexible assignment can be self-corrected by the network itself to avoid the ambiguity between close objects. In the learning process, we also propose to automatically learn weights to balance classes and object sizes to efficiently manage sample imbalance. It allows to build a robust object detector avoiding multi-scale prediction, in a semantic segmentation spirit.