 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Domain Transfer in Latent Space (DTLS) Wins on Image Super-Resolution -- a Non-Denoising Model
Nov 20, 2023
Large scale image super-resolution is a challenging computer vision task, since vast information is missing in a highly degraded image, say for example forscale x16 super-resolution. Diffusion models are used successfully in recent years in extreme super-resolution applications, in which Gaussian noise is used as a means to form a latent photo-realistic space, and acts as a link between the space of latent vectors and the latent photo-realistic space. There are quite a few sophisticated mathematical derivations on mapping the statistics of Gaussian noises making Diffusion Models successful. In this paper we propose a simple approach which gets away from using Gaussian noise but adopts some basic structures of diffusion models for efficient image super-resolution. Essentially, we propose a DNN to perform domain transfer between neighbor domains, which can learn the differences in statistical properties to facilitate gradual interpolation with results of reasonable quality. Further quality improvement is achieved by conditioning the domain transfer with reference to the input LR image. Experimental results show that our method outperforms not only state-of-the-art large scale super resolution models, but also the current diffusion models for image super-resolution. The approach can readily be extended to other image-to-image tasks, such as image enlightening, inpainting, denoising, etc.
Conditional Modeling Based Automatic Video Summarization
Nov 20, 2023The aim of video summarization is to shorten videos automatically while retaining the key information necessary to convey the overall story. Video summarization methods mainly rely on visual factors, such as visual consecutiveness and diversity, which may not be sufficient to fully understand the content of the video. There are other non-visual factors, such as interestingness, representativeness, and storyline consistency that should also be considered for generating high-quality video summaries. Current methods do not adequately take into account these non-visual factors, resulting in suboptimal performance. In this work, a new approach to video summarization is proposed based on insights gained from how humans create ground truth video summaries. The method utilizes a conditional modeling perspective and introduces multiple meaningful random variables and joint distributions to characterize the key components of video summarization. Helper distributions are employed to improve the training of the model. A conditional attention module is designed to mitigate potential performance degradation in the presence of multi-modal input. The proposed video summarization method incorporates the above innovative design choices that aim to narrow the gap between human-generated and machine-generated video summaries. Extensive experiments show that the proposed approach outperforms existing methods and achieves state-of-the-art performance on commonly used video summarization datasets.
On Elastic Language Models
Nov 13, 2023Large-scale pretrained language models have achieved compelling performance in a wide range of language understanding and information retrieval tasks. Knowledge distillation offers an opportunity to compress a large language model to a small one, in order to reach a reasonable latency-performance tradeoff. However, for scenarios where the number of requests (e.g., queries submitted to a search engine) is highly variant, the static tradeoff attained by the compressed language model might not always fit. Once a model is assigned with a static tradeoff, it could be inadequate in that the latency is too high when the number of requests is large or the performance is too low when the number of requests is small. To this end, we propose an elastic language model (ElasticLM) that elastically adjusts the tradeoff according to the request stream. The basic idea is to introduce a compute elasticity to the compressed language model, so that the tradeoff could vary on-the-fly along scalable and controllable compute. Specifically, we impose an elastic structure to enable ElasticLM with compute elasticity and design an elastic optimization to learn ElasticLM under compute elasticity. To serve ElasticLM, we apply an elastic schedule. Considering the specificity of information retrieval, we adapt ElasticLM to dense retrieval and reranking and present ElasticDenser and ElasticRanker respectively. Offline evaluation is conducted on a language understanding benchmark GLUE; and several information retrieval tasks including Natural Question, Trivia QA, and MS MARCO. The results show that ElasticLM along with ElasticDenser and ElasticRanker can perform correctly and competitively compared with an array of static baselines. Furthermore, online simulation with concurrency is also carried out. The results demonstrate that ElasticLM can provide elastic tradeoffs with respect to varying request stream.
Improving Speaker Diarization using Semantic Information: Joint Pairwise Constraints Propagation
Sep 19, 2023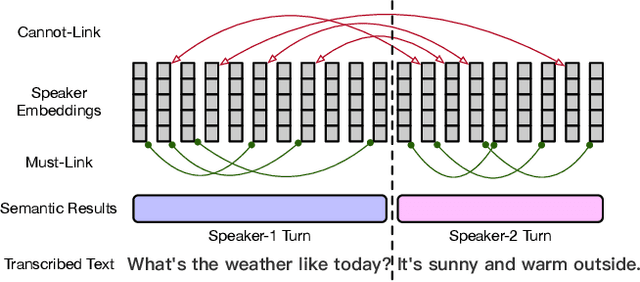
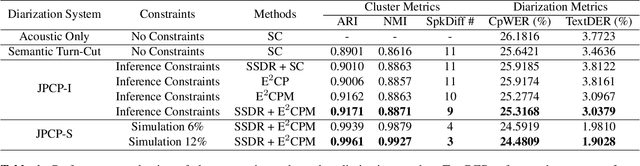
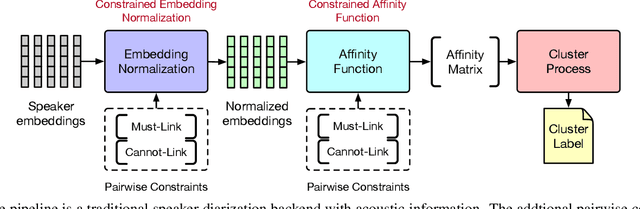
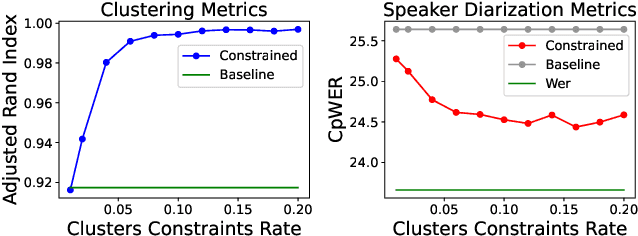
Speaker diarization has gained considerable attention within speech processing research community. Mainstream speaker diarization rely primarily on speakers' voice characteristics extracted from acoustic signals and often overlook the potential of semantic information. Considering the fact that speech signals can efficiently convey the content of a speech, it is of our interest to fully exploit these semantic cues utilizing language models. In this work we propose a novel approach to effectively leverage semantic information in clustering-based speaker diarization systems. Firstly, we introduce spoken language understanding modules to extract speaker-related semantic information and utilize these information to construct pairwise constraints. Secondly, we present a novel framework to integrate these constraints into the speaker diarization pipeline, enhancing the performance of the entire system. Extensive experiments conducted on the public dataset demonstrate the consistent superiority of our proposed approach over acoustic-only speaker diarization systems.
Deep Joint Source Channel Coding With Attention Modules Over MIMO Channels
Nov 13, 2023In this paper, we propose two deep joint source and channel coding (DJSCC) structures with attention modules for the multi-input multi-output (MIMO) channel, including a serial structure and a parallel structure. With singular value decomposition (SVD)-based precoding scheme, the MIMO channel can be decomposed into various sub-channels, and the feature outputs will experience sub-channels with different channel qualities. In the serial structure, one single network is used at both the transmitter and the receiver to jointly process data streams of all MIMO subchannels, while data steams of different MIMO subchannels are processed independently via multiple sub-networks in the parallel structure. The attention modules in both serial and parallel architectures enable the system to adapt to varying channel qualities and adjust the quantity of information outputs in accordance with the channel qualities. Experimental results demonstrate the proposed DJSCC structures have improved image transmission performance, and reveal the phenomenon via non-parameter entropy estimation that the learned DJSCC transceivers tend to transmit more information over better sub-channels.
Integrating Pre-trained Language Model into Neural Machine Translation
Nov 13, 2023Neural Machine Translation (NMT) has become a significant technology in natural language processing through extensive research and development. However, the deficiency of high-quality bilingual language pair data still poses a major challenge to improving NMT performance. Recent studies are exploring the use of contextual information from pre-trained language model (PLM) to address this problem. Yet, the issue of incompatibility between PLM and NMT model remains unresolved. This study proposes a PLM-integrated NMT (PiNMT) model to overcome the identified problems. The PiNMT model consists of three critical components, PLM Multi Layer Converter, Embedding Fusion, and Cosine Alignment, each playing a vital role in providing effective PLM information to NMT. Furthermore, two training strategies, Separate Learning Rates and Dual Step Training, are also introduced in this paper. By implementing the proposed PiNMT model and training strategy, we achieved state-of-the-art performance on the IWSLT'14 En$\leftrightarrow$De dataset. This study's outcomes are noteworthy as they demonstrate a novel approach for efficiently integrating PLM with NMT to overcome incompatibility and enhance performance.
Fast Normalized Cross-Correlation for Template Matching with Rotations
Nov 13, 2023Normalized cross-correlation is the reference approach to carry out template matching on images. When it is computed in Fourier space, it can handle efficiently template translations but it cannot do so with template rotations. Including rotations requires sampling the whole space of rotations, repeating the computation of the correlation each time. This article develops an alternative mathematical theory to handle efficiently, at the same time, rotations and translations. Our proposal has a reduced computational complexity because it does not require to repeatedly sample the space of rotations. To do so, we integrate the information relative to all rotated versions of the template into a unique symmetric tensor template -which is computed only once per template-. Afterward, we demonstrate that the correlation between the image to be processed with the independent tensor components of the tensorial template contains enough information to recover template instance positions and rotations. Our proposed method has the potential to speed up conventional template matching computations by a factor of several magnitude orders for the case of 3D images.
On Retrieval Augmentation and the Limitations of Language Model Training
Nov 16, 2023Augmenting a language model (LM) with $k$-nearest neighbors (kNN) retrieval on its training data alone can decrease its perplexity, though the underlying reasons for this remains elusive. In this work, we first rule out one previously posited possibility -- the "softmax bottleneck." We further identify the MLP hurdle phenomenon, where the final MLP layer in LMs may impede LM optimization early on. We explore memorization and generalization in language models with two new datasets, where advanced model like GPT-3.5-turbo find generalizing to irrelevant information in the training data challenging. However, incorporating kNN retrieval to vanilla GPT-2 117M can consistently improve performance in this setting.
PET Tracer Conversion among Brain PET via Variable Augmented Invertible Network
Nov 15, 2023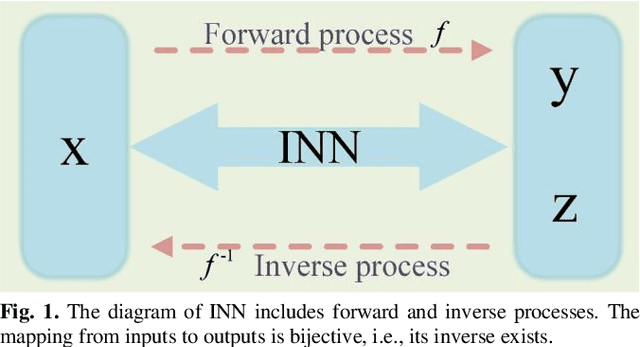
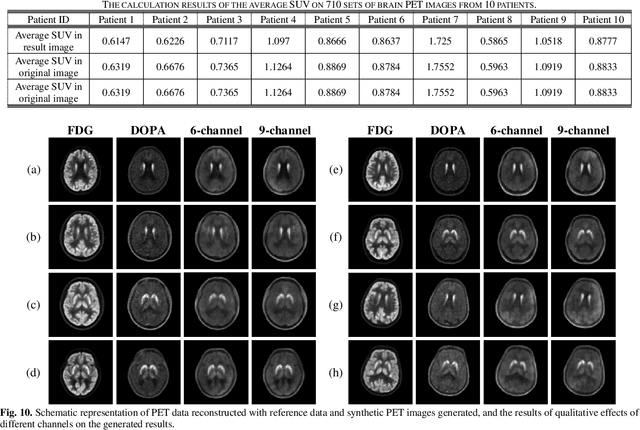
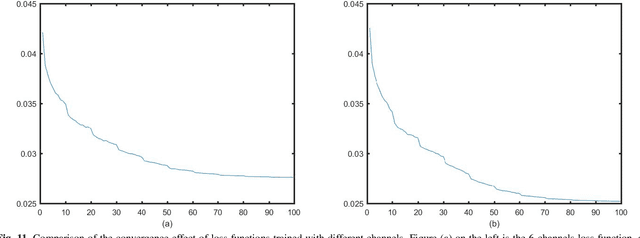
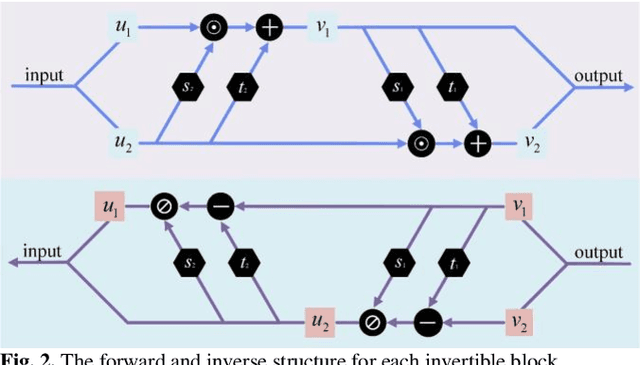
Positron emission tomography (PET) serves as an essential tool for diagnosis of encephalopathy and brain science research. However, it suffers from the limited choice of tracers. Nowadays, with the wide application of PET imaging in neuropsychiatric treatment, 6-18F-fluoro-3, 4-dihydroxy-L-phenylalanine (DOPA) has been found to be more effective than 18F-labeled fluorine-2-deoxyglucose (FDG) in the field. Nevertheless, due to the complexity of its preparation and other limitations, DOPA is far less widely used than FDG. To address this issue, a tracer conversion invertible neural network (TC-INN) for image projection is developed to map FDG images to DOPA images through deep learning. More diagnostic information is obtained by generating PET images from FDG to DOPA. Specifically, the proposed TC-INN consists of two separate phases, one for training traceable data, the other for rebuilding new data. The reference DOPA PET image is used as a learning target for the corresponding network during the training process of tracer conversion. Meanwhile, the invertible network iteratively estimates the resultant DOPA PET data and compares it to the reference DOPA PET data. Notably, the reversible model employs variable enhancement technique to achieve better power generation. Moreover, image registration needs to be performed before training due to the angular deviation of the acquired FDG and DOPA data information. Experimental results exhibited excellent generation capability in mapping between FDG and DOPA, suggesting that PET tracer conversion has great potential in the case of limited tracer applications.
Generative AI-Based Probabilistic Constellation Shaping With Diffusion Models
Nov 15, 2023Diffusion models are at the vanguard of generative AI research with renowned solutions such as ImageGen by Google Brain and DALL.E 3 by OpenAI. Nevertheless, the potential merits of diffusion models for communication engineering applications are not fully understood yet. In this paper, we aim to unleash the power of generative AI for PHY design of constellation symbols in communication systems. Although the geometry of constellations is predetermined according to networking standards, e.g., quadrature amplitude modulation (QAM), probabilistic shaping can design the probability of occurrence (generation) of constellation symbols. This can help improve the information rate and decoding performance of communication systems. We exploit the ``denoise-and-generate'' characteristics of denoising diffusion probabilistic models (DDPM) for probabilistic constellation shaping. The key idea is to learn generating constellation symbols out of noise, ``mimicking'' the way the receiver performs symbol reconstruction. This way, we make the constellation symbols sent by the transmitter, and what is inferred (reconstructed) at the receiver become as similar as possible, resulting in as few mismatches as possible. Our results show that the generative AI-based scheme outperforms deep neural network (DNN)-based benchmark and uniform shaping, while providing network resilience as well as robust out-of-distribution performance under low-SNR regimes and non-Gaussian assumptions. Numerical evaluations highlight 30% improvement in terms of cosine similarity and a threefold improvement in terms of mutual information compared to DNN-based approach for 64-QAM geometry.