 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
HandRefiner: Refining Malformed Hands in Generated Images by Diffusion-based Conditional Inpainting
Nov 29, 2023
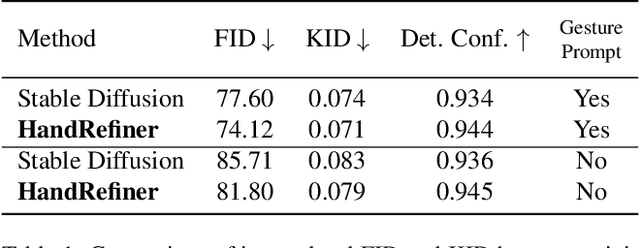
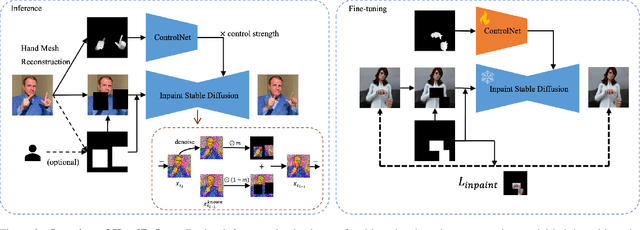


Diffusion models have achieved remarkable success in generating realistic images but suffer from generating accurate human hands, such as incorrect finger counts or irregular shapes. This difficulty arises from the complex task of learning the physical structure and pose of hands from training images, which involves extensive deformations and occlusions. For correct hand generation, our paper introduces a lightweight post-processing solution called $\textbf{HandRefiner}$. HandRefiner employs a conditional inpainting approach to rectify malformed hands while leaving other parts of the image untouched. We leverage the hand mesh reconstruction model that consistently adheres to the correct number of fingers and hand shape, while also being capable of fitting the desired hand pose in the generated image. Given a generated failed image due to malformed hands, we utilize ControlNet modules to re-inject such correct hand information. Additionally, we uncover a phase transition phenomenon within ControlNet as we vary the control strength. It enables us to take advantage of more readily available synthetic data without suffering from the domain gap between realistic and synthetic hands. Experiments demonstrate that HandRefiner can significantly improve the generation quality quantitatively and qualitatively. The code is available at https://github.com/wenquanlu/HandRefiner .
PEAN: A Diffusion-based Prior-Enhanced Attention Network for Scene Text Image Super-Resolution
Nov 29, 2023Scene text image super-resolution (STISR) aims at simultaneously increasing the resolution and readability of low-resolution scene text images, thus boosting the performance of the downstream recognition task. Two factors in scene text images, semantic information and visual structure, affect the recognition performance significantly. To mitigate the effects from these factors, this paper proposes a Prior-Enhanced Attention Network (PEAN). Specifically, a diffusion-based module is developed to enhance the text prior, hence offering better guidance for the SR network to generate SR images with higher semantic accuracy. Meanwhile, the proposed PEAN leverages an attention-based modulation module to understand scene text images by neatly perceiving the local and global dependence of images, despite the shape of the text. A multi-task learning paradigm is employed to optimize the network, enabling the model to generate legible SR images. As a result, PEAN establishes new SOTA results on the TextZoom benchmark. Experiments are also conducted to analyze the importance of the enhanced text prior as a means of improving the performance of the SR network. Code will be made available at https://github.com/jdfxzzy/PEAN.
LGFCTR: Local and Global Feature Convolutional Transformer for Image Matching
Nov 29, 2023Image matching that finding robust and accurate correspondences across images is a challenging task under extreme conditions. Capturing local and global features simultaneously is an important way to mitigate such an issue but recent transformer-based decoders were still stuck in the issues that CNN-based encoders only extract local features and the transformers lack locality. Inspired by the locality and implicit positional encoding of convolutions, a novel convolutional transformer is proposed to capture both local contexts and global structures more sufficiently for detector-free matching. Firstly, a universal FPN-like framework captures global structures in self-encoder as well as cross-decoder by transformers and compensates local contexts as well as implicit positional encoding by convolutions. Secondly, a novel convolutional transformer module explores multi-scale long range dependencies by a novel multi-scale attention and further aggregates local information inside dependencies for enhancing locality. Finally, a novel regression-based sub-pixel refinement module exploits the whole fine-grained window features for fine-level positional deviation regression. The proposed method achieves superior performances on a wide range of benchmarks. The code will be available on https://github.com/zwh0527/LGFCTR.
UniHPE: Towards Unified Human Pose Estimation via Contrastive Learning
Nov 24, 2023In recent times, there has been a growing interest in developing effective perception techniques for combining information from multiple modalities. This involves aligning features obtained from diverse sources to enable more efficient training with larger datasets and constraints, as well as leveraging the wealth of information contained in each modality. 2D and 3D Human Pose Estimation (HPE) are two critical perceptual tasks in computer vision, which have numerous downstream applications, such as Action Recognition, Human-Computer Interaction, Object tracking, etc. Yet, there are limited instances where the correlation between Image and 2D/3D human pose has been clearly researched using a contrastive paradigm. In this paper, we propose UniHPE, a unified Human Pose Estimation pipeline, which aligns features from all three modalities, i.e., 2D human pose estimation, lifting-based and image-based 3D human pose estimation, in the same pipeline. To align more than two modalities at the same time, we propose a novel singular value based contrastive learning loss, which better aligns different modalities and further boosts the performance. In our evaluation, UniHPE achieves remarkable performance metrics: MPJPE $50.5$mm on the Human3.6M dataset and PAMPJPE $51.6$mm on the 3DPW dataset. Our proposed method holds immense potential to advance the field of computer vision and contribute to various applications.
Binarized 3D Whole-body Human Mesh Recovery
Nov 24, 2023
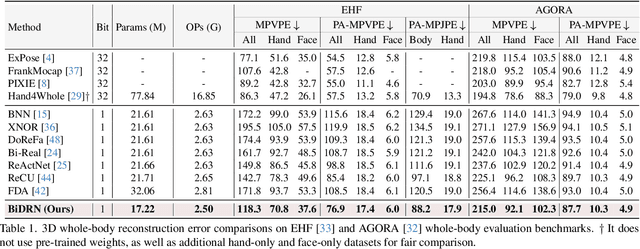
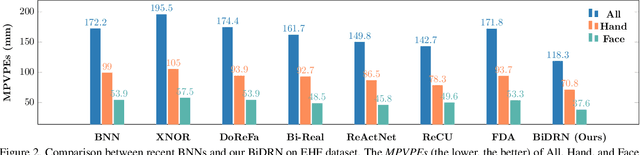
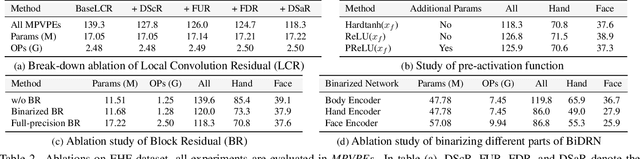
3D whole-body human mesh recovery aims to reconstruct the 3D human body, face, and hands from a single image. Although powerful deep learning models have achieved accurate estimation in this task, they require enormous memory and computational resources. Consequently, these methods can hardly be deployed on resource-limited edge devices. In this work, we propose a Binarized Dual Residual Network (BiDRN), a novel quantization method to estimate the 3D human body, face, and hands parameters efficiently. Specifically, we design a basic unit Binarized Dual Residual Block (BiDRB) composed of Local Convolution Residual (LCR) and Block Residual (BR), which can preserve full-precision information as much as possible. For LCR, we generalize it to four kinds of convolutional modules so that full-precision information can be propagated even between mismatched dimensions. We also binarize the face and hands box-prediction network as Binaried BoxNet, which can further reduce the model redundancy. Comprehensive quantitative and qualitative experiments demonstrate the effectiveness of BiDRN, which has a significant improvement over state-of-the-art binarization algorithms. Moreover, our proposed BiDRN achieves comparable performance with full-precision method Hand4Whole while using just 22.1% parameters and 14.8% operations. We will release all the code and pretrained models.
Addressing the Length Bias Problem in Document-Level Neural Machine Translation
Nov 20, 2023Document-level neural machine translation (DNMT) has shown promising results by incorporating more context information. However, this approach also introduces a length bias problem, whereby DNMT suffers from significant translation quality degradation when decoding documents that are much shorter or longer than the maximum sequence length during training. %i.e., the length bias problem. To solve the length bias problem, we propose to improve the DNMT model in training method, attention mechanism, and decoding strategy. Firstly, we propose to sample the training data dynamically to ensure a more uniform distribution across different sequence lengths. Then, we introduce a length-normalized attention mechanism to aid the model in focusing on target information, mitigating the issue of attention divergence when processing longer sequences. Lastly, we propose a sliding window strategy during decoding that integrates as much context information as possible without exceeding the maximum sequence length. The experimental results indicate that our method can bring significant improvements on several open datasets, and further analysis shows that our method can significantly alleviate the length bias problem.
HEALNet -- Hybrid Multi-Modal Fusion for Heterogeneous Biomedical Data
Nov 20, 2023Technological advances in medical data collection such as high-resolution histopathology and high-throughput genomic sequencing have contributed to the rising requirement for multi-modal biomedical modelling, specifically for image, tabular, and graph data. Most multi-modal deep learning approaches use modality-specific architectures that are trained separately and cannot capture the crucial cross-modal information that motivates the integration of different data sources. This paper presents the Hybrid Early-fusion Attention Learning Network (HEALNet): a flexible multi-modal fusion architecture, which a) preserves modality-specific structural information, b) captures the cross-modal interactions and structural information in a shared latent space, c) can effectively handle missing modalities during training and inference, and d) enables intuitive model inspection by learning on the raw data input instead of opaque embeddings. We conduct multi-modal survival analysis on Whole Slide Images and Multi-omic data on four cancer cohorts of The Cancer Genome Atlas (TCGA). HEALNet achieves state-of-the-art performance, substantially improving over both uni-modal and recent multi-modal baselines, whilst being robust in scenarios with missing modalities.
FRUITS: Feature Extraction Using Iterated Sums for Time Series Classification
Nov 24, 2023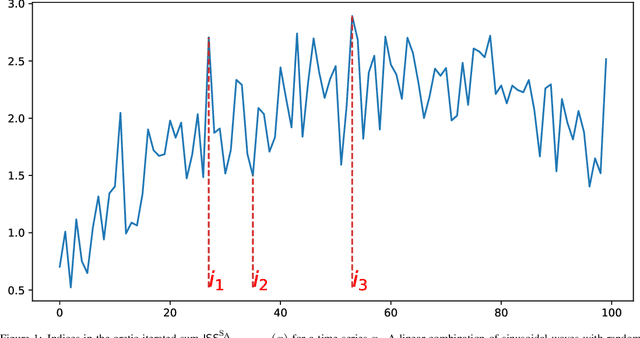
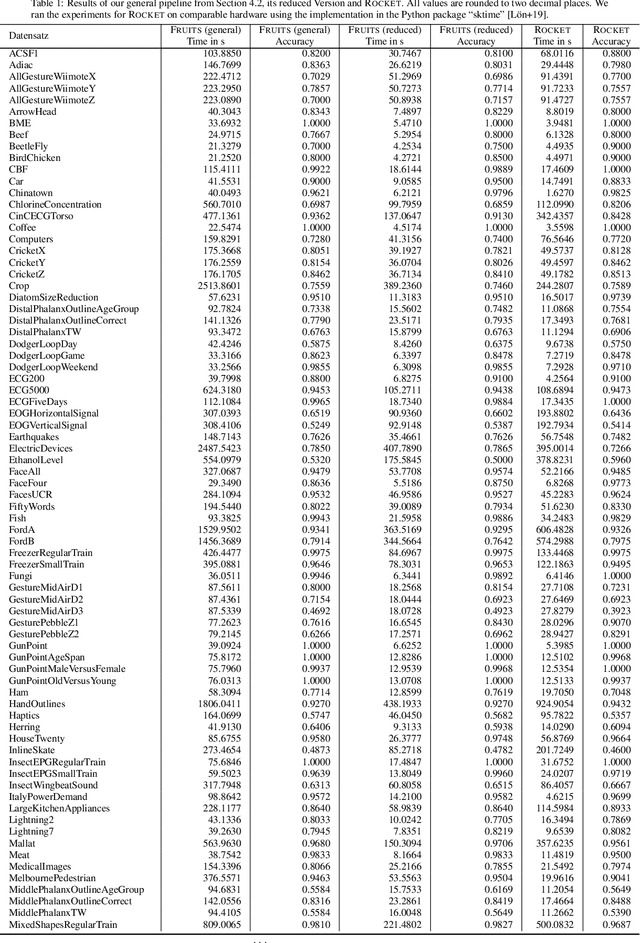

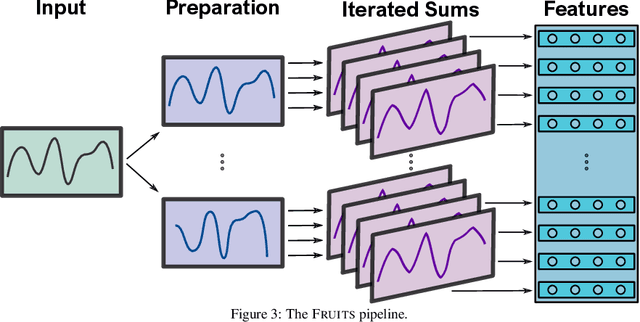
We introduce a pipeline for time series classification that extracts features based on the iterated-sums signature (ISS) and then applies a linear classifier. These features are intrinsically nonlinear, capture chronological information, and, under certain settings, are invariant to time-warping. We are competitive with state-of-the-art methods on the UCR archive, both in terms of accuracy and speed. We make our code available at \url{https://github.com/irkri/fruits}.
MirrorCalib: Utilizing Human Pose Information for Mirror-based Virtual Camera Calibration
Nov 05, 2023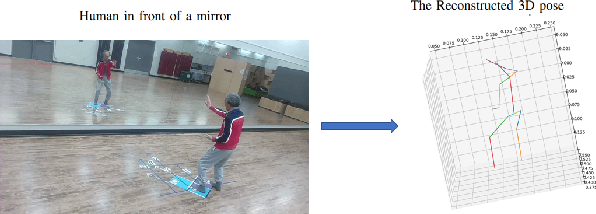
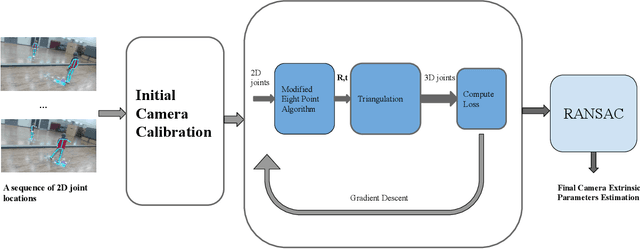
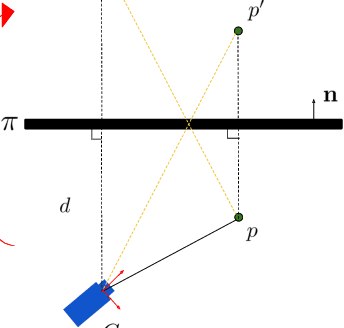
In this paper, we present the novel task of estimating the extrinsic parameters of a virtual camera with respect to a real camera with one single fixed planar mirror. This task poses a significant challenge in cases where objects captured lack overlapping views from both real and mirrored cameras. To address this issue, prior knowledge of a human body and 2D joint locations are utilized to estimate the camera extrinsic parameters when a person is in front of a mirror. We devise a modified eight-point algorithm to obtain an initial estimation from 2D joint locations. The 2D joint locations are then refined subject to human body constraints. Finally, a RANSAC algorithm is employed to remove outliers by comparing their epipolar distances to a predetermined threshold. MirrorCalib is evaluated on both synthetic and real datasets and achieves a rotation error of 0.62{\deg}/1.82{\deg} and a translation error of 37.33/69.51 mm on the synthetic/real dataset, which outperforms the state-of-art method.
Peeking Inside the Schufa Blackbox: Explaining the German Housing Scoring System
Nov 22, 2023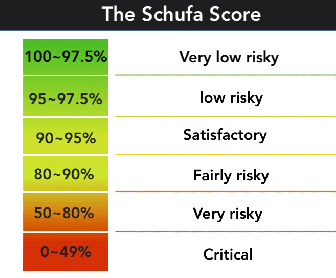

Explainable Artificial Intelligence is a concept aimed at making complex algorithms transparent to users through a uniform solution. Researchers have highlighted the importance of integrating domain specific contexts to develop explanations tailored to end users. In this study, we focus on the Schufa housing scoring system in Germany and investigate how users information needs and expectations for explanations vary based on their roles. Using the speculative design approach, we asked business information students to imagine user interfaces that provide housing credit score explanations from the perspectives of both tenants and landlords. Our preliminary findings suggest that although there are general needs that apply to all users, there are also conflicting needs that depend on the practical realities of their roles and how credit scores affect them. We contribute to Human centered XAI research by proposing future research directions that examine users explanatory needs considering their roles and agencies.