 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Barwise Music Structure Analysis with the Correlation Block-Matching Segmentation Algorithm
Nov 30, 2023
Music Structure Analysis (MSA) is a Music Information Retrieval task consisting of representing a song in a simplified, organized manner by breaking it down into sections typically corresponding to ``chorus'', ``verse'', ``solo'', etc. In this work, we extend an MSA algorithm called the Correlation Block-Matching (CBM) algorithm introduced by (Marmoret et al., 2020, 2022b). The CBM algorithm is a dynamic programming algorithm that segments self-similarity matrices, which are a standard description used in MSA and in numerous other applications. In this work, self-similarity matrices are computed from the feature representation of an audio signal and time is sampled at the bar-scale. This study examines three different standard similarity functions for the computation of self-similarity matrices. Results show that, in optimal conditions, the proposed algorithm achieves a level of performance which is competitive with supervised state-of-the-art methods while only requiring knowledge of bar positions. In addition, the algorithm is made open-source and is highly customizable.
* 19 pages, 13 figures, 11 tables, 1 algorithm, published in Transactions of the International Society for Music Information Retrieval
ZeST-NeRF: Using temporal aggregation for Zero-Shot Temporal NeRFs
Nov 30, 2023In the field of media production, video editing techniques play a pivotal role. Recent approaches have had great success at performing novel view image synthesis of static scenes. But adding temporal information adds an extra layer of complexity. Previous models have focused on implicitly representing static and dynamic scenes using NeRF. These models achieve impressive results but are costly at training and inference time. They overfit an MLP to describe the scene implicitly as a function of position. This paper proposes ZeST-NeRF, a new approach that can produce temporal NeRFs for new scenes without retraining. We can accurately reconstruct novel views using multi-view synthesis techniques and scene flow-field estimation, trained only with unrelated scenes. We demonstrate how existing state-of-the-art approaches from a range of fields cannot adequately solve this new task and demonstrate the efficacy of our solution. The resulting network improves quantitatively by 15% and produces significantly better visual results.
Perceptual Group Tokenizer: Building Perception with Iterative Grouping
Nov 30, 2023Human visual recognition system shows astonishing capability of compressing visual information into a set of tokens containing rich representations without label supervision. One critical driving principle behind it is perceptual grouping. Despite being widely used in computer vision in the early 2010s, it remains a mystery whether perceptual grouping can be leveraged to derive a neural visual recognition backbone that generates as powerful representations. In this paper, we propose the Perceptual Group Tokenizer, a model that entirely relies on grouping operations to extract visual features and perform self-supervised representation learning, where a series of grouping operations are used to iteratively hypothesize the context for pixels or superpixels to refine feature representations. We show that the proposed model can achieve competitive performance compared to state-of-the-art vision architectures, and inherits desirable properties including adaptive computation without re-training, and interpretability. Specifically, Perceptual Group Tokenizer achieves 80.3% on ImageNet-1K self-supervised learning benchmark with linear probe evaluation, marking a new progress under this paradigm.
Dispersed Structured Light for Hyperspectral 3D Imaging
Nov 30, 2023Hyperspectral 3D imaging aims to acquire both depth and spectral information of a scene. However, existing methods are either prohibitively expensive and bulky or compromise on spectral and depth accuracy. In this work, we present Dispersed Structured Light (DSL), a cost-effective and compact method for accurate hyperspectral 3D imaging. DSL modifies a traditional projector-camera system by placing a sub-millimeter thick diffraction grating film front of the projector. The grating disperses structured light based on light wavelength. To utilize the dispersed structured light, we devise a model for dispersive projection image formation and a per-pixel hyperspectral 3D reconstruction method. We validate DSL by instantiating a compact experimental prototype. DSL achieves spectral accuracy of 18.8nm full-width half-maximum (FWHM) and depth error of 1mm. We demonstrate that DSL outperforms prior work on practical hyperspectral 3D imaging. DSL promises accurate and practical hyperspectral 3D imaging for diverse application domains, including computer vision and graphics, cultural heritage, geology, and biology.
LLVMs4Protest: Harnessing the Power of Large Language and Vision Models for Deciphering Protests in the News
Nov 30, 2023Large language and vision models have transformed how social movements scholars identify protest and extract key protest attributes from multi-modal data such as texts, images, and videos. This article documents how we fine-tuned two large pretrained transformer models, including longformer and swin-transformer v2, to infer potential protests in news articles using textual and imagery data. First, the longformer model was fine-tuned using the Dynamic of Collective Action (DoCA) Corpus. We matched the New York Times articles with the DoCA database to obtain a training dataset for downstream tasks. Second, the swin-transformer v2 models was trained on UCLA-protest imagery data. UCLA-protest project contains labeled imagery data with information such as protest, violence, and sign. Both fine-tuned models will be available via \url{https://github.com/Joshzyj/llvms4protest}. We release this short technical report for social movement scholars who are interested in using LLVMs to infer protests in textual and imagery data.
DocPedia: Unleashing the Power of Large Multimodal Model in the Frequency Domain for Versatile Document Understanding
Nov 30, 2023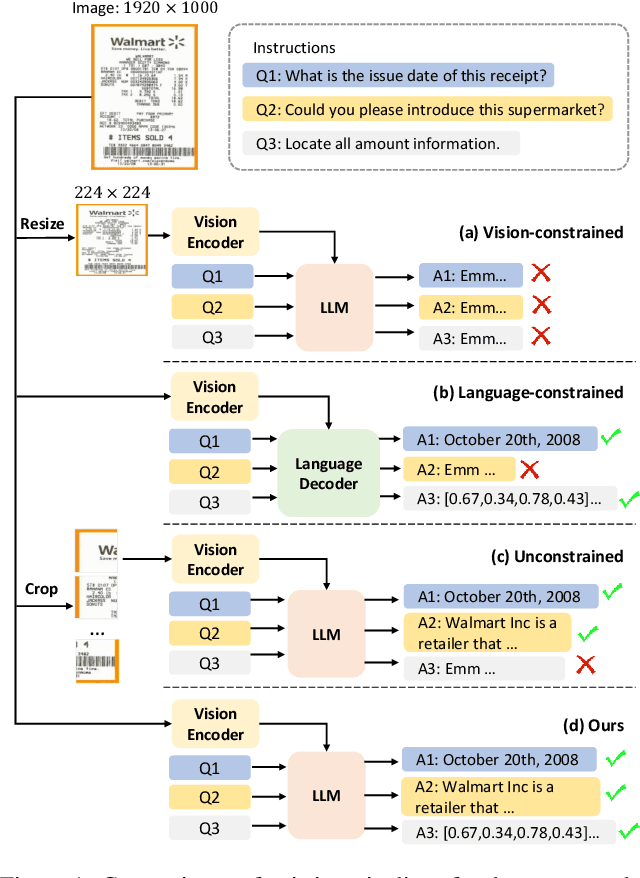
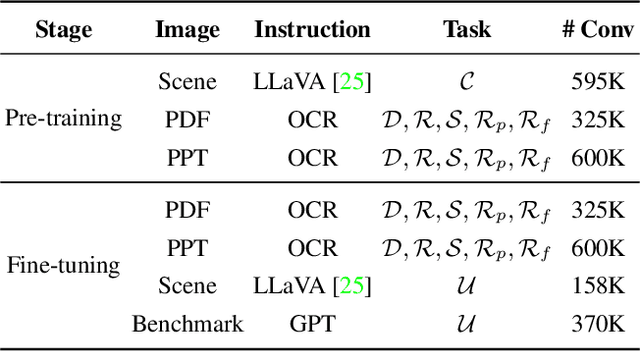
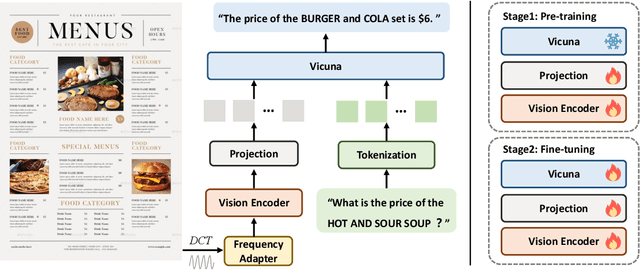
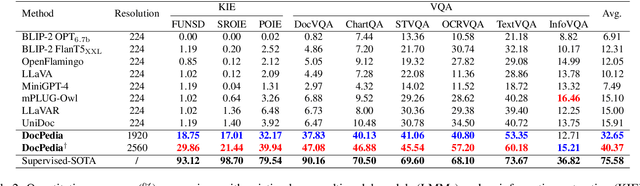
This work presents DocPedia, a novel large multimodal model (LMM) for versatile OCR-free document understanding, capable of parsing images up to 2,560$\times$2,560 resolution. Unlike existing work either struggle with high-resolution documents or give up the large language model thus vision or language ability constrained, our DocPedia directly processes visual input in the frequency domain rather than the pixel space. The unique characteristic enables DocPedia to capture a greater amount of visual and textual information using a limited number of visual tokens. To consistently enhance both perception and comprehension abilities of our model, we develop a dual-stage training strategy and enrich instructions/annotations of all training tasks covering multiple document types. Extensive quantitative and qualitative experiments conducted on various publicly available benchmarks confirm the mutual benefits of jointly learning perception and comprehension tasks. The results provide further evidence of the effectiveness and superior performance of our DocPedia over other methods.
Few-shot Image Generation via Style Adaptation and Content Preservation
Nov 30, 2023Training a generative model with limited data (e.g., 10) is a very challenging task. Many works propose to fine-tune a pre-trained GAN model. However, this can easily result in overfitting. In other words, they manage to adapt the style but fail to preserve the content, where \textit{style} denotes the specific properties that defines a domain while \textit{content} denotes the domain-irrelevant information that represents diversity. Recent works try to maintain a pre-defined correspondence to preserve the content, however, the diversity is still not enough and it may affect style adaptation. In this work, we propose a paired image reconstruction approach for content preservation. We propose to introduce an image translation module to GAN transferring, where the module teaches the generator to separate style and content, and the generator provides training data to the translation module in return. Qualitative and quantitative experiments show that our method consistently surpasses the state-of-the-art methods in few shot setting.
A deep learning pipeline for cross-sectional and longitudinal multiview data integration
Dec 02, 2023Biomedical research now commonly integrates diverse data types or views from the same individuals to better understand the pathobiology of complex diseases, but the challenge lies in meaningfully integrating these diverse views. Existing methods often require the same type of data from all views (cross-sectional data only or longitudinal data only) or do not consider any class outcome in the integration method, presenting limitations. To overcome these limitations, we have developed a pipeline that harnesses the power of statistical and deep learning methods to integrate cross-sectional and longitudinal data from multiple sources. Additionally, it identifies key variables contributing to the association between views and the separation among classes, providing deeper biological insights. This pipeline includes variable selection/ranking using linear and nonlinear methods, feature extraction using functional principal component analysis and Euler characteristics, and joint integration and classification using dense feed-forward networks and recurrent neural networks. We applied this pipeline to cross-sectional and longitudinal multi-omics data (metagenomics, transcriptomics, and metabolomics) from an inflammatory bowel disease (IBD) study and we identified microbial pathways, metabolites, and genes that discriminate by IBD status, providing information on the etiology of IBD. We conducted simulations to compare the two feature extraction methods. The proposed pipeline is available from the following GitHub repository: https://github.com/lasandrall/DeepIDA-GRU.
Spectral-wise Implicit Neural Representation for Hyperspectral Image Reconstruction
Dec 02, 2023
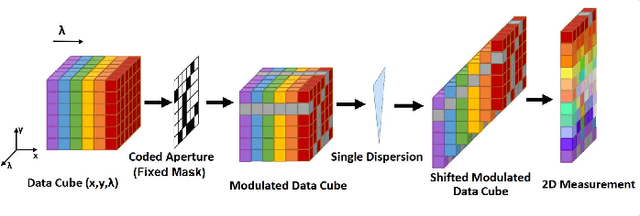
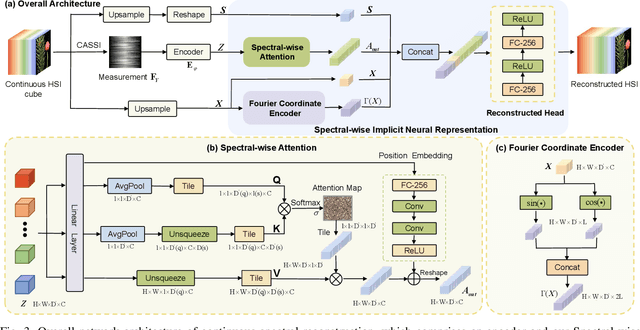
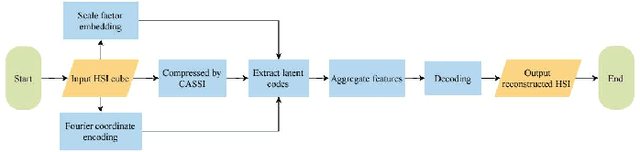
Coded Aperture Snapshot Spectral Imaging (CASSI) reconstruction aims to recover the 3D spatial-spectral signal from 2D measurement. Existing methods for reconstructing Hyperspectral Image (HSI) typically involve learning mappings from a 2D compressed image to a predetermined set of discrete spectral bands. However, this approach overlooks the inherent continuity of the spectral information. In this study, we propose an innovative method called Spectral-wise Implicit Neural Representation (SINR) as a pioneering step toward addressing this limitation. SINR introduces a continuous spectral amplification process for HSI reconstruction, enabling spectral super-resolution with customizable magnification factors. To achieve this, we leverage the concept of implicit neural representation. Specifically, our approach introduces a spectral-wise attention mechanism that treats individual channels as distinct tokens, thereby capturing global spectral dependencies. Additionally, our approach incorporates two components, namely a Fourier coordinate encoder and a spectral scale factor module. The Fourier coordinate encoder enhances the SINR's ability to emphasize high-frequency components, while the spectral scale factor module guides the SINR to adapt to the variable number of spectral channels. Notably, the SINR framework enhances the flexibility of CASSI reconstruction by accommodating an unlimited number of spectral bands in the desired output. Extensive experiments demonstrate that our SINR outperforms baseline methods. By enabling continuous reconstruction within the CASSI framework, we take the initial stride toward integrating implicit neural representation into the field.
Enabling On-Device Large Language Model Personalization with Self-Supervised Data Selection and Synthesis
Dec 02, 2023
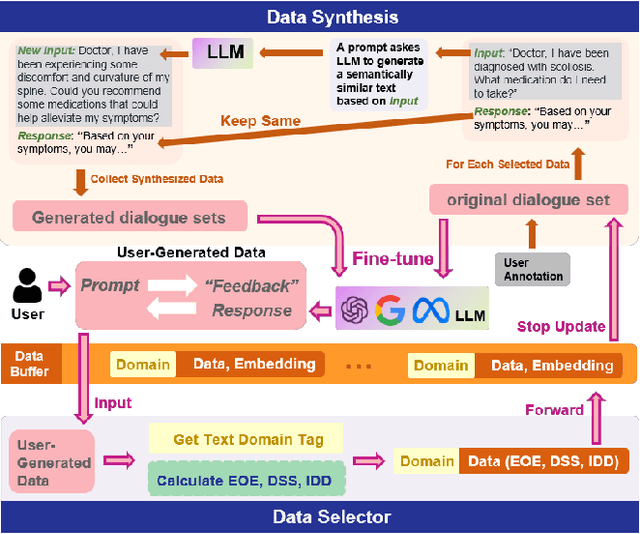
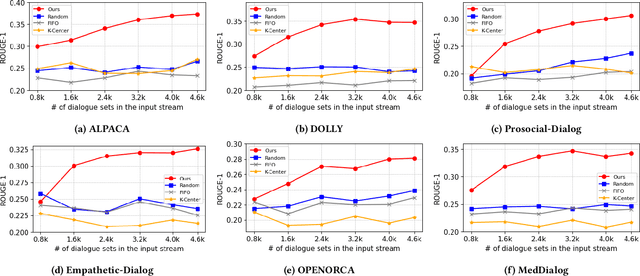
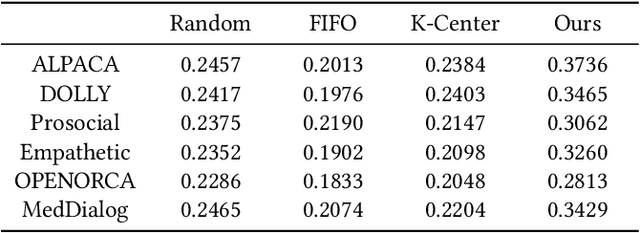
After a large language model (LLM) is deployed on edge devices, it is desirable for these devices to learn from user-generated conversation data to generate user-specific and personalized responses in real-time. However, user-generated data usually contains sensitive and private information, and uploading such data to the cloud for annotation is not preferred if not prohibited. While it is possible to obtain annotation locally by directly asking users to provide preferred responses, such annotations have to be sparse to not affect user experience. In addition, the storage of edge devices is usually too limited to enable large-scale fine-tuning with full user-generated data. It remains an open question how to enable on-device LLM personalization, considering sparse annotation and limited on-device storage. In this paper, we propose a novel framework to select and store the most representative data online in a self-supervised way. Such data has a small memory footprint and allows infrequent requests of user annotations for further fine-tuning. To enhance fine-tuning quality, multiple semantically similar pairs of question texts and expected responses are generated using the LLM. Our experiments show that the proposed framework achieves the best user-specific content-generating capability (accuracy) and fine-tuning speed (performance) compared with vanilla baselines. To the best of our knowledge, this is the very first on-device LLM personalization framework.