 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
A secure and private ensemble matcher using multi-vault obfuscated templates
Apr 08, 2024
Given the irrevocability of biometric samples and mounting privacy concerns, biometric template security and secure matching are among the essential features of any well-designed modern biometric system. In this paper, we propose an obfuscation method that hides the biometric template information with just enough chaff. The main idea is to reduce the number of chaff points to a practical level by creating n sub-templates from the original template and hiding each sub-template with m chaff points. During verification, s closest vectors to the biometric query are retrieved from each vault and then combined to generate hash values that are compared with the stored hash value. We demonstrate the effectiveness of synthetic facial images, generated by a Generative Adversarial Network (GAN), as ``random chaff points'' within a secure-vault authorization system. This approach safeguards user identities during training and deployment. We tested our protocol using the AT&T, GT, and LFW face datasets, with the ROC areas under the curve being 0.99, 0.99, and 0.90, respectively. These numbers were close to those of the unprotected templates, showing that our method does not adversely affect accuracy.
360+x: A Panoptic Multi-modal Scene Understanding Dataset
Apr 08, 2024Human perception of the world is shaped by a multitude of viewpoints and modalities. While many existing datasets focus on scene understanding from a certain perspective (e.g. egocentric or third-person views), our dataset offers a panoptic perspective (i.e. multiple viewpoints with multiple data modalities). Specifically, we encapsulate third-person panoramic and front views, as well as egocentric monocular/binocular views with rich modalities including video, multi-channel audio, directional binaural delay, location data and textual scene descriptions within each scene captured, presenting comprehensive observation of the world. Figure 1 offers a glimpse of all 28 scene categories of our 360+x dataset. To the best of our knowledge, this is the first database that covers multiple viewpoints with multiple data modalities to mimic how daily information is accessed in the real world. Through our benchmark analysis, we presented 5 different scene understanding tasks on the proposed 360+x dataset to evaluate the impact and benefit of each data modality and perspective in panoptic scene understanding. We hope this unique dataset could broaden the scope of comprehensive scene understanding and encourage the community to approach these problems from more diverse perspectives.
* CVPR 2024 (Oral Presentation), Project page: https://x360dataset.github.io/
Enhancing the Performance of Aspect-Based Sentiment Analysis Systems
Apr 04, 2024Aspect-based sentiment analysis aims to predict sentiment polarity with fine granularity. While Graph Convolutional Networks (GCNs) are widely utilized for sentimental feature extraction, their naive application for syntactic feature extraction can compromise information preservation. This study introduces an innovative edge-enhanced GCN, named SentiSys, to navigate the syntactic graph while preserving intact feature information, leading to enhanced performance. Specifically,we first integrate a bidirectional long short-term memory (Bi-LSTM) network and a self-attention-based transformer. This combination facilitates effective text encoding, preventing the loss of information and predicting long dependency text. A bidirectional GCN (Bi-GCN) with message passing is then employed to encode relationships between entities. Additionally, unnecessary information is filtered out using an aspect-specific masking technique. To validate the effectiveness of our proposed model, we conduct extensive evaluation experiments and ablation studies on four benchmark datasets. The results consistently demonstrate improved performance in aspect-based sentiment analysis when employing SentiSys. This approach successfully addresses the challenges associated with syntactic feature extraction, highlighting its potential for advancing sentiment analysis methodologies.
FollowIR: Evaluating and Teaching Information Retrieval Models to Follow Instructions
Mar 22, 2024Modern Large Language Models (LLMs) are capable of following long and complex instructions that enable a diverse amount of user tasks. However, despite Information Retrieval (IR) models using LLMs as the backbone of their architectures, nearly all of them still only take queries as input, with no instructions. For the handful of recent models that do take instructions, it's unclear how they use them. We introduce our dataset FollowIR, which contains a rigorous instruction evaluation benchmark as well as a training set for helping IR models learn to better follow real-world instructions. FollowIR builds off the long history of the TREC conferences: as TREC provides human annotators with instructions (also known as narratives) to determine document relevance, so should IR models be able to understand and decide relevance based on these detailed instructions. Our evaluation benchmark starts with three deeply judged TREC collections and alters the annotator instructions, re-annotating relevant documents. Through this process, we can measure how well IR models follow instructions, through a new pairwise evaluation framework. Our results indicate that existing retrieval models fail to correctly use instructions, using them for basic keywords and struggling to understand long-form information. However, we show that it is possible for IR models to learn to follow complex instructions: our new FollowIR-7B model has significant improvements (over 13%) after fine-tuning on our training set.
FIT-RAG: Black-Box RAG with Factual Information and Token Reduction
Mar 21, 2024
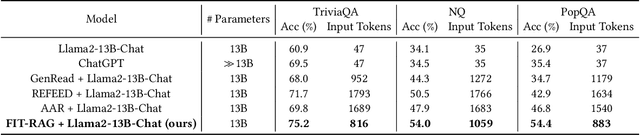
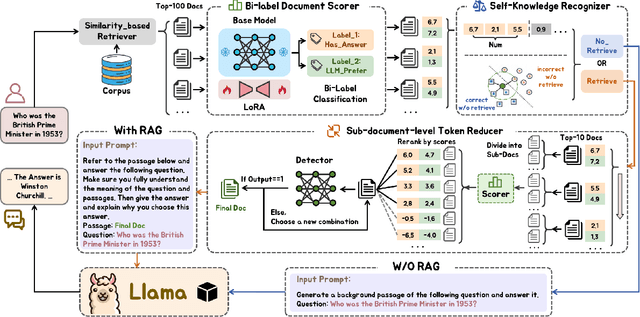
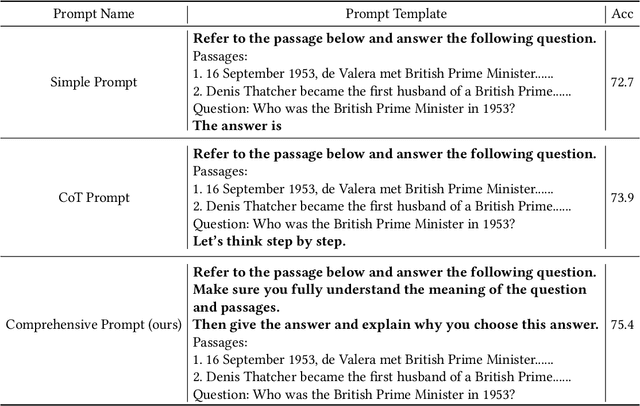
Due to the extraordinarily large number of parameters, fine-tuning Large Language Models (LLMs) to update long-tail or out-of-date knowledge is impractical in lots of applications. To avoid fine-tuning, we can alternatively treat a LLM as a black-box (i.e., freeze the parameters of the LLM) and augment it with a Retrieval-Augmented Generation (RAG) system, namely black-box RAG. Recently, black-box RAG has achieved success in knowledge-intensive tasks and has gained much attention. Existing black-box RAG methods typically fine-tune the retriever to cater to LLMs' preferences and concatenate all the retrieved documents as the input, which suffers from two issues: (1) Ignorance of Factual Information. The LLM preferred documents may not contain the factual information for the given question, which can mislead the retriever and hurt the effectiveness of black-box RAG; (2) Waste of Tokens. Simply concatenating all the retrieved documents brings large amounts of unnecessary tokens for LLMs, which degenerates the efficiency of black-box RAG. To address these issues, this paper proposes a novel black-box RAG framework which utilizes the factual information in the retrieval and reduces the number of tokens for augmentation, dubbed FIT-RAG. FIT-RAG utilizes the factual information by constructing a bi-label document scorer. Besides, it reduces the tokens by introducing a self-knowledge recognizer and a sub-document-level token reducer. FIT-RAG achieves both superior effectiveness and efficiency, which is validated by extensive experiments across three open-domain question-answering datasets: TriviaQA, NQ and PopQA. FIT-RAG can improve the answering accuracy of Llama2-13B-Chat by 14.3\% on TriviaQA, 19.9\% on NQ and 27.5\% on PopQA, respectively. Furthermore, it can save approximately half of the tokens on average across the three datasets.
BruSLeAttack: A Query-Efficient Score-Based Black-Box Sparse Adversarial Attack
Apr 08, 2024We study the unique, less-well understood problem of generating sparse adversarial samples simply by observing the score-based replies to model queries. Sparse attacks aim to discover a minimum number-the l0 bounded-perturbations to model inputs to craft adversarial examples and misguide model decisions. But, in contrast to query-based dense attack counterparts against black-box models, constructing sparse adversarial perturbations, even when models serve confidence score information to queries in a score-based setting, is non-trivial. Because, such an attack leads to i) an NP-hard problem; and ii) a non-differentiable search space. We develop the BruSLeAttack-a new, faster (more query-efficient) Bayesian algorithm for the problem. We conduct extensive attack evaluations including an attack demonstration against a Machine Learning as a Service (MLaaS) offering exemplified by Google Cloud Vision and robustness testing of adversarial training regimes and a recent defense against black-box attacks. The proposed attack scales to achieve state-of-the-art attack success rates and query efficiency on standard computer vision tasks such as ImageNet across different model architectures. Our artefacts and DIY attack samples are available on GitHub. Importantly, our work facilitates faster evaluation of model vulnerabilities and raises our vigilance on the safety, security and reliability of deployed systems.
BinaryDM: Towards Accurate Binarization of Diffusion Model
Apr 08, 2024With the advancement of diffusion models (DMs) and the substantially increased computational requirements, quantization emerges as a practical solution to obtain compact and efficient low-bit DMs. However, the highly discrete representation leads to severe accuracy degradation, hindering the quantization of diffusion models to ultra-low bit-widths. In this paper, we propose BinaryDM, a novel accurate quantization-aware training approach to push the weights of diffusion models towards the limit of 1-bit. Firstly, we present a Learnable Multi-basis Binarizer (LMB) to recover the representations generated by the binarized DM, which improves the information in details of representations crucial to the DM. Secondly, a Low-rank Representation Mimicking (LRM) is applied to enhance the binarization-aware optimization of the DM, alleviating the optimization direction ambiguity caused by fine-grained alignment. Moreover, a progressive initialization strategy is applied to training DMs to avoid convergence difficulties. Comprehensive experiments demonstrate that BinaryDM achieves significant accuracy and efficiency gains compared to SOTA quantization methods of DMs under ultra-low bit-widths. As the first binarization method for diffusion models, BinaryDM achieves impressive 16.0 times FLOPs and 27.1 times storage savings with 1-bit weight and 4-bit activation, showcasing its substantial advantages and potential for deploying DMs on resource-limited scenarios.
Responsible Reporting for Frontier AI Development
Apr 03, 2024Mitigating the risks from frontier AI systems requires up-to-date and reliable information about those systems. Organizations that develop and deploy frontier systems have significant access to such information. By reporting safety-critical information to actors in government, industry, and civil society, these organizations could improve visibility into new and emerging risks posed by frontier systems. Equipped with this information, developers could make better informed decisions on risk management, while policymakers could design more targeted and robust regulatory infrastructure. We outline the key features of responsible reporting and propose mechanisms for implementing them in practice.
Panoptic Perception: A Novel Task and Fine-grained Dataset for Universal Remote Sensing Image Interpretation
Apr 06, 2024Current remote-sensing interpretation models often focus on a single task such as detection, segmentation, or caption. However, the task-specific designed models are unattainable to achieve the comprehensive multi-level interpretation of images. The field also lacks support for multi-task joint interpretation datasets. In this paper, we propose Panoptic Perception, a novel task and a new fine-grained dataset (FineGrip) to achieve a more thorough and universal interpretation for RSIs. The new task, 1) integrates pixel-level, instance-level, and image-level information for universal image perception, 2) captures image information from coarse to fine granularity, achieving deeper scene understanding and description, and 3) enables various independent tasks to complement and enhance each other through multi-task learning. By emphasizing multi-task interactions and the consistency of perception results, this task enables the simultaneous processing of fine-grained foreground instance segmentation, background semantic segmentation, and global fine-grained image captioning. Concretely, the FineGrip dataset includes 2,649 remote sensing images, 12,054 fine-grained instance segmentation masks belonging to 20 foreground things categories, 7,599 background semantic masks for 5 stuff classes and 13,245 captioning sentences. Furthermore, we propose a joint optimization-based panoptic perception model. Experimental results on FineGrip demonstrate the feasibility of the panoptic perception task and the beneficial effect of multi-task joint optimization on individual tasks. The dataset will be publicly available.
Enhancing Video Summarization with Context Awareness
Apr 06, 2024Video summarization is a crucial research area that aims to efficiently browse and retrieve relevant information from the vast amount of video content available today. With the exponential growth of multimedia data, the ability to extract meaningful representations from videos has become essential. Video summarization techniques automatically generate concise summaries by selecting keyframes, shots, or segments that capture the video's essence. This process improves the efficiency and accuracy of various applications, including video surveillance, education, entertainment, and social media. Despite the importance of video summarization, there is a lack of diverse and representative datasets, hindering comprehensive evaluation and benchmarking of algorithms. Existing evaluation metrics also fail to fully capture the complexities of video summarization, limiting accurate algorithm assessment and hindering the field's progress. To overcome data scarcity challenges and improve evaluation, we propose an unsupervised approach that leverages video data structure and information for generating informative summaries. By moving away from fixed annotations, our framework can produce representative summaries effectively. Moreover, we introduce an innovative evaluation pipeline tailored specifically for video summarization. Human participants are involved in the evaluation, comparing our generated summaries to ground truth summaries and assessing their informativeness. This human-centric approach provides valuable insights into the effectiveness of our proposed techniques. Experimental results demonstrate that our training-free framework outperforms existing unsupervised approaches and achieves competitive results compared to state-of-the-art supervised methods.