 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTrends in AI Supercomputers
Apr 22, 2025



Frontier AI development relies on powerful AI supercomputers, yet analysis of these systems is limited. We create a dataset of 500 AI supercomputers from 2019 to 2025 and analyze key trends in performance, power needs, hardware cost, ownership, and global distribution. We find that the computational performance of AI supercomputers has doubled every nine months, while hardware acquisition cost and power needs both doubled every year. The leading system in March 2025, xAI's Colossus, used 200,000 AI chips, had a hardware cost of \$7B, and required 300 MW of power, as much as 250,000 households. As AI supercomputers evolved from tools for science to industrial machines, companies rapidly expanded their share of total AI supercomputer performance, while the share of governments and academia diminished. Globally, the United States accounts for about 75% of total performance in our dataset, with China in second place at 15%. If the observed trends continue, the leading AI supercomputer in 2030 will achieve $2\times10^{22}$ 16-bit FLOP/s, use two million AI chips, have a hardware cost of \$200 billion, and require 9 GW of power. Our analysis provides visibility into the AI supercomputer landscape, allowing policymakers to assess key AI trends like resource needs, ownership, and national competitiveness.
IDs for AI Systems
Jun 17, 2024



AI systems are increasingly pervasive, yet information needed to decide whether and how to engage with them may not exist or be accessible. A user may not be able to verify whether a system satisfies certain safety standards. An investigator may not know whom to investigate when a system causes an incident. A platform may find it difficult to penalize repeated negative interactions with the same system. Across a number of domains, IDs address analogous problems by identifying \textit{particular} entities (e.g., a particular Boeing 747) and providing information about other entities of the same class (e.g., some or all Boeing 747s). We propose a framework in which IDs are ascribed to \textbf{instances} of AI systems (e.g., a particular chat session with Claude 3), and associated information is accessible to parties seeking to interact with that system. We characterize IDs for AI systems, argue that there could be significant demand for IDs from key actors, analyze how those actors could incentivize ID adoption, explore potential implementations of our framework, and highlight limitations and risks. IDs seem most warranted in high-stakes settings, where certain actors (e.g., those that enable AI systems to make financial transactions) could experiment with incentives for ID use. Deployers of AI systems could experiment with developing ID implementations. With further study, IDs could help to manage a world where AI systems pervade society.
Training Compute Thresholds: Features and Functions in AI Governance
May 17, 2024



This paper examines the use of training compute thresholds as a tool for governing artificial intelligence (AI) systems. We argue that compute thresholds serve as a valuable trigger for further evaluation of AI models, rather than being the sole determinant of the regulation. Key advantages of compute thresholds include their correlation with model capabilities and risks, quantifiability, ease of measurement, robustness to circumvention, knowability before model development and deployment, potential for external verification, and targeted scope. Compute thresholds provide a practical starting point for identifying potentially high-risk models and can be used as an initial filter in AI governance frameworks alongside other sector-specific regulations and broader governance measures.
Societal Adaptation to Advanced AI
May 16, 2024


Existing strategies for managing risks from advanced AI systems often focus on affecting what AI systems are developed and how they diffuse. However, this approach becomes less feasible as the number of developers of advanced AI grows, and impedes beneficial use-cases as well as harmful ones. In response, we urge a complementary approach: increasing societal adaptation to advanced AI, that is, reducing the expected negative impacts from a given level of diffusion of a given AI capability. We introduce a conceptual framework which helps identify adaptive interventions that avoid, defend against and remedy potentially harmful uses of AI systems, illustrated with examples in election manipulation, cyberterrorism, and loss of control to AI decision-makers. We discuss a three-step cycle that society can implement to adapt to AI. Increasing society's ability to implement this cycle builds its resilience to advanced AI. We conclude with concrete recommendations for governments, industry, and third-parties.
Responsible Reporting for Frontier AI Development
Apr 03, 2024



Mitigating the risks from frontier AI systems requires up-to-date and reliable information about those systems. Organizations that develop and deploy frontier systems have significant access to such information. By reporting safety-critical information to actors in government, industry, and civil society, these organizations could improve visibility into new and emerging risks posed by frontier systems. Equipped with this information, developers could make better informed decisions on risk management, while policymakers could design more targeted and robust regulatory infrastructure. We outline the key features of responsible reporting and propose mechanisms for implementing them in practice.
Visibility into AI Agents
Feb 04, 2024

Increased delegation of commercial, scientific, governmental, and personal activities to AI agents -- systems capable of pursuing complex goals with limited supervision -- may exacerbate existing societal risks and introduce new risks. Understanding and mitigating these risks involves critically evaluating existing governance structures, revising and adapting these structures where needed, and ensuring accountability of key stakeholders. Information about where, why, how, and by whom certain AI agents are used, which we refer to as visibility, is critical to these objectives. In this paper, we assess three categories of measures to increase visibility into AI agents: agent identifiers, real-time monitoring, and activity logging. For each, we outline potential implementations that vary in intrusiveness and informativeness. We analyze how the measures apply across a spectrum of centralized through decentralized deployment contexts, accounting for various actors in the supply chain including hardware and software service providers. Finally, we discuss the implications of our measures for privacy and concentration of power. Further work into understanding the measures and mitigating their negative impacts can help to build a foundation for the governance of AI agents.
The Compute Divide in Machine Learning: A Threat to Academic Contribution and Scrutiny?
Jan 08, 2024



There are pronounced differences in the extent to which industrial and academic AI labs use computing resources. We provide a data-driven survey of the role of the compute divide in shaping machine learning research. We show that a compute divide has coincided with a reduced representation of academic-only research teams in compute intensive research topics, especially foundation models. We argue that, academia will likely play a smaller role in advancing the associated techniques, providing critical evaluation and scrutiny, and in the diffusion of such models. Concurrent with this change in research focus, there is a noticeable shift in academic research towards embracing open source, pre-trained models developed within the industry. To address the challenges arising from this trend, especially reduced scrutiny of influential models, we recommend approaches aimed at thoughtfully expanding academic insights. Nationally-sponsored computing infrastructure coupled with open science initiatives could judiciously boost academic compute access, prioritizing research on interpretability, safety and security. Structured access programs and third-party auditing may also allow measured external evaluation of industry systems.
Compute at Scale -- A Broad Investigation into the Data Center Industry
Nov 18, 2023



This report characterizes the data center industry and its importance for AI development. Data centers are industrial facilities that efficiently provide compute at scale and thus constitute the engine rooms of today's digital economy. As large-scale AI training and inference become increasingly computationally expensive, they are dominantly executed from this designated infrastructure. Key features of data centers include large-scale compute clusters that require extensive cooling and consume large amounts of power, the need for fast connectivity both within the data center and to the internet, and an emphasis on security and reliability. The global industry is valued at approximately $250B and is expected to double over the next seven years. There are likely about 500 large (above 10 MW) data centers globally, with the US, Europe, and China constituting the most important markets. The report further covers important actors, business models, main inputs, and typical locations of data centers.
International Governance of Civilian AI: A Jurisdictional Certification Approach
Sep 11, 2023



This report describes trade-offs in the design of international governance arrangements for civilian artificial intelligence (AI) and presents one approach in detail. This approach represents the extension of a standards, licensing, and liability regime to the global level. We propose that states establish an International AI Organization (IAIO) to certify state jurisdictions (not firms or AI projects) for compliance with international oversight standards. States can give force to these international standards by adopting regulations prohibiting the import of goods whose supply chains embody AI from non-IAIO-certified jurisdictions. This borrows attributes from models of existing international organizations, such as the International Civilian Aviation Organization (ICAO), the International Maritime Organization (IMO), and the Financial Action Task Force (FATF). States can also adopt multilateral controls on the export of AI product inputs, such as specialized hardware, to non-certified jurisdictions. Indeed, both the import and export standards could be required for certification. As international actors reach consensus on risks of and minimum standards for advanced AI, a jurisdictional certification regime could mitigate a broad range of potential harms, including threats to public safety.
Machine Learning Model Sizes and the Parameter Gap
Jul 05, 2022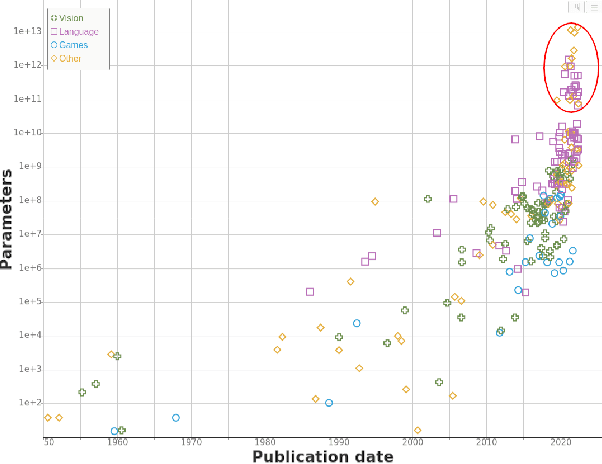
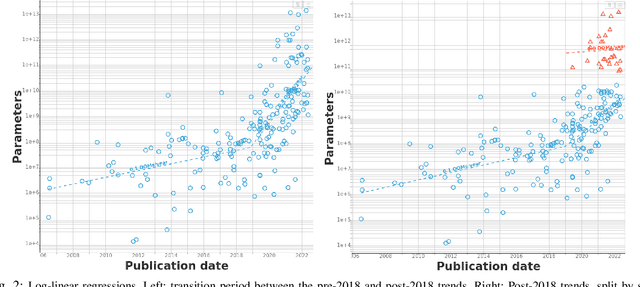
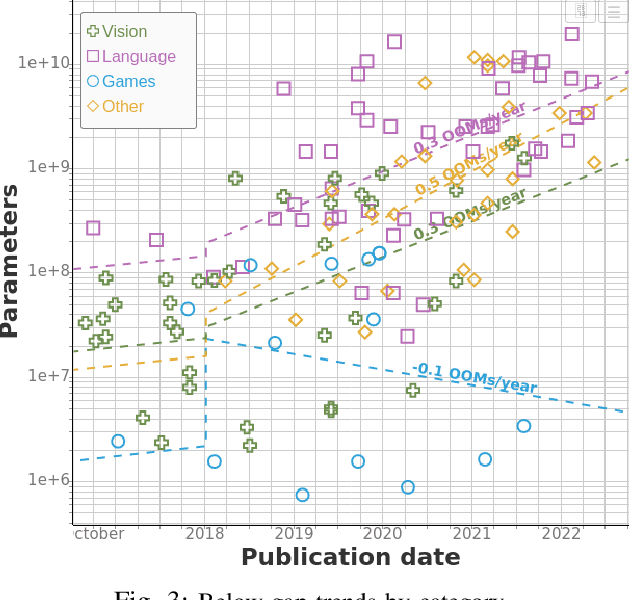
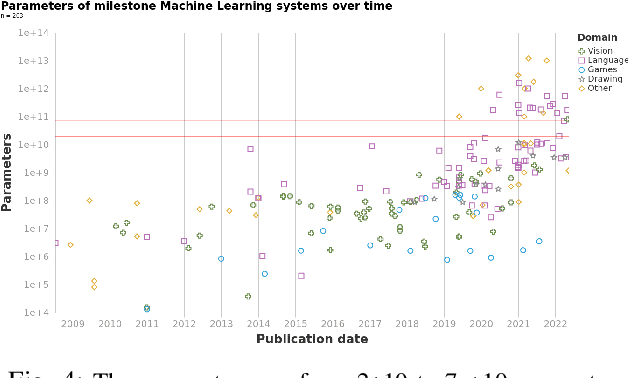
We study trends in model size of notable machine learning systems over time using a curated dataset. From 1950 to 2018, model size in language models increased steadily by seven orders of magnitude. The trend then accelerated, with model size increasing by another five orders of magnitude in just 4 years from 2018 to 2022. Vision models grew at a more constant pace, totaling 7 orders of magnitude of growth between 1950 and 2022. We also identify that, since 2020, there have been many language models below 20B parameters, many models above 70B parameters, but a scarcity of models in the 20-70B parameter range. We refer to that scarcity as the parameter gap. We provide some stylized facts about the parameter gap and propose a few hypotheses to explain it. The explanations we favor are: (a) increasing model size beyond 20B parameters requires adopting different parallelism techniques, which makes mid-sized models less cost-effective, (b) GPT-3 was one order of magnitude larger than previous language models, and researchers afterwards primarily experimented with bigger models to outperform it. While these dynamics likely exist, and we believe they play some role in generating the gap, we don't have high confidence that there are no other, more important dynamics at play.