 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCertified but Fooled! Breaking Certified Defences with Ghost Certificates
Nov 18, 2025Certified defenses promise provable robustness guarantees. We study the malicious exploitation of probabilistic certification frameworks to better understand the limits of guarantee provisions. Now, the objective is to not only mislead a classifier, but also manipulate the certification process to generate a robustness guarantee for an adversarial input certificate spoofing. A recent study in ICLR demonstrated that crafting large perturbations can shift inputs far into regions capable of generating a certificate for an incorrect class. Our study investigates if perturbations needed to cause a misclassification and yet coax a certified model into issuing a deceptive, large robustness radius for a target class can still be made small and imperceptible. We explore the idea of region-focused adversarial examples to craft imperceptible perturbations, spoof certificates and achieve certification radii larger than the source class ghost certificates. Extensive evaluations with the ImageNet demonstrate the ability to effectively bypass state-of-the-art certified defenses such as Densepure. Our work underscores the need to better understand the limits of robustness certification methods.
GyroCopter: Differential Bearing Measuring Trajectory Planner for Tracking and Localizing Radio Frequency Sources
Oct 16, 2024



Autonomous aerial vehicles can provide efficient and effective solutions for radio frequency (RF) source tracking and localizing problems with applications ranging from wildlife conservation to search and rescue operations. Existing lightweight, low-cost, bearing measurements-based methods with a single antenna-receiver sensor system configurations necessitate in situ rotations, leading to substantial measurement acquisition times restricting searchable areas and number of measurements. We propose a GyroCopter for the task. Our approach plans the trajectory of a multi-rotor unmanned aerial vehicle (UAV) whilst utilizing UAV flight dynamics to execute a constant gyration motion to derive "pseudo-bearing" measurements to track RF sources. The gyration-based pseudo-bearing approach: i) significantly reduces the limitations associated with in situ rotation bearing; while ii) capitalizing on the simplicity, affordability, and lightweight nature of signal strength measurement acquisition hardware to estimate bearings. This method distinguishes itself from other pseudo-bearing approaches by eliminating the need for additional hardware to maintain simplicity, lightweightness and cost-effectiveness. To validate our approach, we derived the optimal rotation speed and conducted extensive simulations and field missions with our GyroCopter to track and localize multiple RF sources. The results confirm the effectiveness of our method, highlighting its potential as a practical and rapid solution for RF source localization tasks.
Bayesian Low-Rank LeArning (Bella): A Practical Approach to Bayesian Neural Networks
Jul 30, 2024



Computational complexity of Bayesian learning is impeding its adoption in practical, large-scale tasks. Despite demonstrations of significant merits such as improved robustness and resilience to unseen or out-of-distribution inputs over their non- Bayesian counterparts, their practical use has faded to near insignificance. In this study, we introduce an innovative framework to mitigate the computational burden of Bayesian neural networks (BNNs). Our approach follows the principle of Bayesian techniques based on deep ensembles, but significantly reduces their cost via multiple low-rank perturbations of parameters arising from a pre-trained neural network. Both vanilla version of ensembles as well as more sophisticated schemes such as Bayesian learning with Stein Variational Gradient Descent (SVGD), previously deemed impractical for large models, can be seamlessly implemented within the proposed framework, called Bayesian Low-Rank LeArning (Bella). In a nutshell, i) Bella achieves a dramatic reduction in the number of trainable parameters required to approximate a Bayesian posterior; and ii) it not only maintains, but in some instances, surpasses the performance of conventional Bayesian learning methods and non-Bayesian baselines. Our results with large-scale tasks such as ImageNet, CAMELYON17, DomainNet, VQA with CLIP, LLaVA demonstrate the effectiveness and versatility of Bella in building highly scalable and practical Bayesian deep models for real-world applications.
MEXGEN: An Effective and Efficient Information Gain Approximation for Information Gathering Path Planning
May 04, 2024Autonomous robots for gathering information on objects of interest has numerous real-world applications because of they improve efficiency, performance and safety. Realizing autonomy demands online planning algorithms to solve sequential decision making problems under uncertainty; because, objects of interest are often dynamic, object state, such as location is not directly observable and are obtained from noisy measurements. Such planning problems are notoriously difficult due to the combinatorial nature of predicting the future to make optimal decisions. For information theoretic planning algorithms, we develop a computationally efficient and effective approximation for the difficult problem of predicting the likely sensor measurements from uncertain belief states}. The approach more accurately predicts information gain from information gathering actions. Our theoretical analysis proves the proposed formulation achieves a lower prediction error than the current efficient-method. We demonstrate improved performance gains in radio-source tracking and localization problems using extensive simulated and field experiments with a multirotor aerial robot.
BruSLeAttack: A Query-Efficient Score-Based Black-Box Sparse Adversarial Attack
Apr 08, 2024We study the unique, less-well understood problem of generating sparse adversarial samples simply by observing the score-based replies to model queries. Sparse attacks aim to discover a minimum number-the l0 bounded-perturbations to model inputs to craft adversarial examples and misguide model decisions. But, in contrast to query-based dense attack counterparts against black-box models, constructing sparse adversarial perturbations, even when models serve confidence score information to queries in a score-based setting, is non-trivial. Because, such an attack leads to i) an NP-hard problem; and ii) a non-differentiable search space. We develop the BruSLeAttack-a new, faster (more query-efficient) Bayesian algorithm for the problem. We conduct extensive attack evaluations including an attack demonstration against a Machine Learning as a Service (MLaaS) offering exemplified by Google Cloud Vision and robustness testing of adversarial training regimes and a recent defense against black-box attacks. The proposed attack scales to achieve state-of-the-art attack success rates and query efficiency on standard computer vision tasks such as ImageNet across different model architectures. Our artefacts and DIY attack samples are available on GitHub. Importantly, our work facilitates faster evaluation of model vulnerabilities and raises our vigilance on the safety, security and reliability of deployed systems.
Distributed Multi-Object Tracking Under Limited Field of View Heterogeneous Sensors with Density Clustering
Dec 31, 2023



We consider the problem of tracking multiple, unknown, and time-varying numbers of objects using a distributed network of heterogeneous sensors. In an effort to derive a formulation for practical settings, we consider limited and unknown sensor field-of-views (FoVs), sensors with limited local computational resources and communication channel capacity. The resulting distributed multi-object tracking algorithm involves solving an NP-hard multidimensional assignment problem either optimally for small-size problems or sub-optimally for general practical problems. For general problems, we propose an efficient distributed multi-object tracking algorithm that performs track-to-track fusion using a clustering-based analysis of the state space transformed into a density space to mitigate the complexity of the assignment problem. The proposed algorithm can more efficiently group local track estimates for fusion than existing approaches. To ensure we achieve globally consistent identities for tracks across a network of nodes as objects move between FoVs, we develop a graph-based algorithm to achieve label consensus and minimise track segmentation. Numerical experiments with a synthetic and a real-world trajectory dataset demonstrate that our proposed method is significantly more computationally efficient than state-of-the-art solutions, achieving similar tracking accuracy and bandwidth requirements but with improved label consistency.
ConservationBots: Autonomous Aerial Robot for Fast Robust Wildlife Tracking in Complex Terrains
Aug 17, 2023Today, the most widespread, widely applicable technology for gathering data relies on experienced scientists armed with handheld radio telemetry equipment to locate low-power radio transmitters attached to wildlife from the ground. Although aerial robots can transform labor-intensive conservation tasks, the realization of autonomous systems for tackling task complexities under real-world conditions remains a challenge. We developed ConservationBots-small aerial robots for tracking multiple, dynamic, radio-tagged wildlife. The aerial robot achieves robust localization performance and fast task completion times -- significant for energy-limited aerial systems while avoiding close encounters with potential, counter-productive disturbances to wildlife. Our approach overcomes the technical and practical problems posed by combining a lightweight sensor with new concepts: i) planning to determine both trajectory and measurement actions guided by an information-theoretic objective, which allows the robot to strategically select near-instantaneous range-only measurements to achieve faster localization, and time-consuming sensor rotation actions to acquire bearing measurements and achieve robust tracking performance; ii) a bearing detector more robust to noise and iii) a tracking algorithm formulation robust to missed and false detections experienced in real-world conditions. We conducted extensive studies: simulations built upon complex signal propagation over high-resolution elevation data on diverse geographical terrains; field testing; studies with wombats (Lasiorhinus latifrons; nocturnal, vulnerable species dwelling in underground warrens) and tracking comparisons with a highly experienced biologist to validate the effectiveness of our aerial robot and demonstrate the significant advantages over the manual method.
Bayesian Learning with Information Gain Provably Bounds Risk for a Robust Adversarial Defense
Dec 05, 2022We present a new algorithm to learn a deep neural network model robust against adversarial attacks. Previous algorithms demonstrate an adversarially trained Bayesian Neural Network (BNN) provides improved robustness. We recognize the adversarial learning approach for approximating the multi-modal posterior distribution of a Bayesian model can lead to mode collapse; consequently, the model's achievements in robustness and performance are sub-optimal. Instead, we first propose preventing mode collapse to better approximate the multi-modal posterior distribution. Second, based on the intuition that a robust model should ignore perturbations and only consider the informative content of the input, we conceptualize and formulate an information gain objective to measure and force the information learned from both benign and adversarial training instances to be similar. Importantly. we prove and demonstrate that minimizing the information gain objective allows the adversarial risk to approach the conventional empirical risk. We believe our efforts provide a step toward a basis for a principled method of adversarially training BNNs. Our model demonstrate significantly improved robustness--up to 20%--compared with adversarial training and Adv-BNN under PGD attacks with 0.035 distortion on both CIFAR-10 and STL-10 datasets.
* Published at ICML 2022
Transferable Graph Backdoor Attack
Jul 05, 2022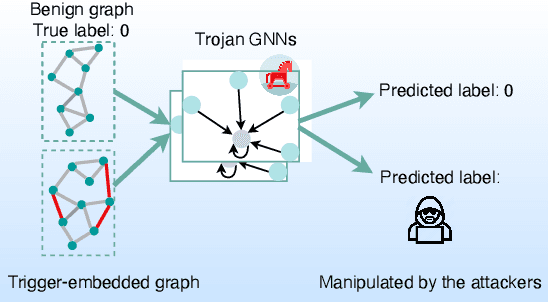

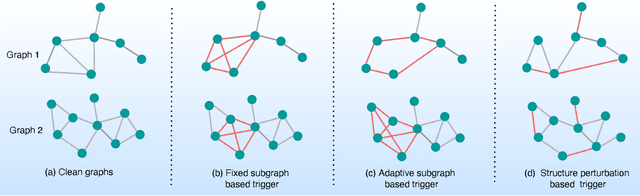
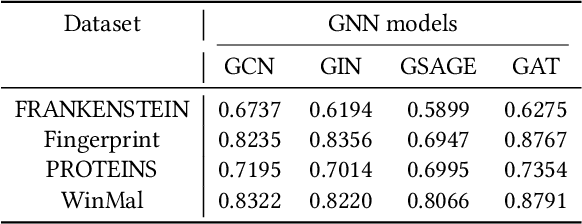
Graph Neural Networks (GNNs) have achieved tremendous success in many graph mining tasks benefitting from the message passing strategy that fuses the local structure and node features for better graph representation learning. Despite the success of GNNs, and similar to other types of deep neural networks, GNNs are found to be vulnerable to unnoticeable perturbations on both graph structure and node features. Many adversarial attacks have been proposed to disclose the fragility of GNNs under different perturbation strategies to create adversarial examples. However, vulnerability of GNNs to successful backdoor attacks was only shown recently. In this paper, we disclose the TRAP attack, a Transferable GRAPh backdoor attack. The core attack principle is to poison the training dataset with perturbation-based triggers that can lead to an effective and transferable backdoor attack. The perturbation trigger for a graph is generated by performing the perturbation actions on the graph structure via a gradient based score matrix from a surrogate model. Compared with prior works, TRAP attack is different in several ways: i) it exploits a surrogate Graph Convolutional Network (GCN) model to generate perturbation triggers for a blackbox based backdoor attack; ii) it generates sample-specific perturbation triggers which do not have a fixed pattern; and iii) the attack transfers, for the first time in the context of GNNs, to different GNN models when trained with the forged poisoned training dataset. Through extensive evaluations on four real-world datasets, we demonstrate the effectiveness of the TRAP attack to build transferable backdoors in four different popular GNNs using four real-world datasets.
Query Efficient Decision Based Sparse Attacks Against Black-Box Deep Learning Models
Jan 31, 2022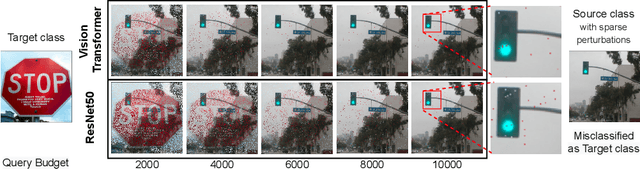

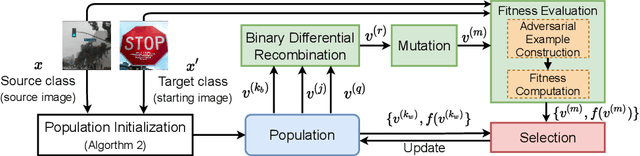
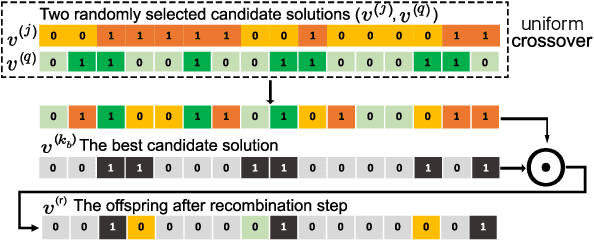
Despite our best efforts, deep learning models remain highly vulnerable to even tiny adversarial perturbations applied to the inputs. The ability to extract information from solely the output of a machine learning model to craft adversarial perturbations to black-box models is a practical threat against real-world systems, such as autonomous cars or machine learning models exposed as a service (MLaaS). Of particular interest are sparse attacks. The realization of sparse attacks in black-box models demonstrates that machine learning models are more vulnerable than we believe. Because these attacks aim to minimize the number of perturbed pixels measured by l_0 norm-required to mislead a model by solely observing the decision (the predicted label) returned to a model query; the so-called decision-based attack setting. But, such an attack leads to an NP-hard optimization problem. We develop an evolution-based algorithm-SparseEvo-for the problem and evaluate against both convolutional deep neural networks and vision transformers. Notably, vision transformers are yet to be investigated under a decision-based attack setting. SparseEvo requires significantly fewer model queries than the state-of-the-art sparse attack Pointwise for both untargeted and targeted attacks. The attack algorithm, although conceptually simple, is also competitive with only a limited query budget against the state-of-the-art gradient-based whitebox attacks in standard computer vision tasks such as ImageNet. Importantly, the query efficient SparseEvo, along with decision-based attacks, in general, raise new questions regarding the safety of deployed systems and poses new directions to study and understand the robustness of machine learning models.