 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Interpretable Medical Image Classification using Prototype Learning and Privileged Information
Oct 24, 2023
Interpretability is often an essential requirement in medical imaging. Advanced deep learning methods are required to address this need for explainability and high performance. In this work, we investigate whether additional information available during the training process can be used to create an understandable and powerful model. We propose an innovative solution called Proto-Caps that leverages the benefits of capsule networks, prototype learning and the use of privileged information. Evaluating the proposed solution on the LIDC-IDRI dataset shows that it combines increased interpretability with above state-of-the-art prediction performance. Compared to the explainable baseline model, our method achieves more than 6 % higher accuracy in predicting both malignancy (93.0 %) and mean characteristic features of lung nodules. Simultaneously, the model provides case-based reasoning with prototype representations that allow visual validation of radiologist-defined attributes.
* MICCAI 2023 Medical Image Computing and Computer Assisted Intervention
Relightful Harmonization: Lighting-aware Portrait Background Replacement
Dec 11, 2023Portrait harmonization aims to composite a subject into a new background, adjusting its lighting and color to ensure harmony with the background scene. Existing harmonization techniques often only focus on adjusting the global color and brightness of the foreground and ignore crucial illumination cues from the background such as apparent lighting direction, leading to unrealistic compositions. We introduce Relightful Harmonization, a lighting-aware diffusion model designed to seamlessly harmonize sophisticated lighting effect for the foreground portrait using any background image. Our approach unfolds in three stages. First, we introduce a lighting representation module that allows our diffusion model to encode lighting information from target image background. Second, we introduce an alignment network that aligns lighting features learned from image background with lighting features learned from panorama environment maps, which is a complete representation for scene illumination. Last, to further boost the photorealism of the proposed method, we introduce a novel data simulation pipeline that generates synthetic training pairs from a diverse range of natural images, which are used to refine the model. Our method outperforms existing benchmarks in visual fidelity and lighting coherence, showing superior generalization in real-world testing scenarios, highlighting its versatility and practicality.
ControlNet-XS: Designing an Efficient and Effective Architecture for Controlling Text-to-Image Diffusion Models
Dec 11, 2023The field of image synthesis has made tremendous strides forward in the last years. Besides defining the desired output image with text-prompts, an intuitive approach is to additionally use spatial guidance in form of an image, such as a depth map. For this, a recent and highly popular approach is to use a controlling network, such as ControlNet, in combination with a pre-trained image generation model, such as Stable Diffusion. When evaluating the design of existing controlling networks, we observe that they all suffer from the same problem of a delay in information flowing between the generation and controlling process. This, in turn, means that the controlling network must have generative capabilities. In this work we propose a new controlling architecture, called ControlNet-XS, which does not suffer from this problem, and hence can focus on the given task of learning to control. In contrast to ControlNet, our model needs only a fraction of parameters, and hence is about twice as fast during inference and training time. Furthermore, the generated images are of higher quality and the control is of higher fidelity. All code and pre-trained models will be made publicly available.
Unsupervised KPIs-Based Clustering of Jobs in HPC Data Centers
Dec 11, 2023Performance analysis is an essential task in High-Performance Computing (HPC) systems and it is applied for different purposes such as anomaly detection, optimal resource allocation, and budget planning. HPC monitoring tasks generate a huge number of Key Performance Indicators (KPIs) to supervise the status of the jobs running in these systems. KPIs give data about CPU usage, memory usage, network (interface) traffic, or other sensors that monitor the hardware. Analyzing this data, it is possible to obtain insightful information about running jobs, such as their characteristics, performance, and failures. The main contribution in this paper is to identify which metric/s (KPIs) is/are the most appropriate to identify/classify different types of jobs according to their behavior in the HPC system. With this aim, we have applied different clustering techniques (partition and hierarchical clustering algorithms) using a real dataset from the Galician Computation Center (CESGA). We have concluded that (i) those metrics (KPIs) related to the Network (interface) traffic monitoring provide the best cohesion and separation to cluster HPC jobs, and (ii) hierarchical clustering algorithms are the most suitable for this task. Our approach was validated using a different real dataset from the same HPC center.
* 22 pages, 6 figures, journal
Robust Graph Neural Network based on Graph Denoising
Dec 11, 2023Graph Neural Networks (GNNs) have emerged as a notorious alternative to address learning problems dealing with non-Euclidean datasets. However, although most works assume that the graph is perfectly known, the observed topology is prone to errors stemming from observational noise, graph-learning limitations, or adversarial attacks. If ignored, these perturbations may drastically hinder the performance of GNNs. To address this limitation, this work proposes a robust implementation of GNNs that explicitly accounts for the presence of perturbations in the observed topology. For any task involving GNNs, our core idea is to i) solve an optimization problem not only over the learnable parameters of the GNN but also over the true graph, and ii) augment the fitting cost with a term accounting for discrepancies on the graph. Specifically, we consider a convolutional GNN based on graph filters and follow an alternating optimization approach to handle the (non-differentiable and constrained) optimization problem by combining gradient descent and projected proximal updates. The resulting algorithm is not limited to a particular type of graph and is amenable to incorporating prior information about the perturbations. Finally, we assess the performance of the proposed method through several numerical experiments.
MMDesign: Multi-Modality Transfer Learning for Generative Protein Design
Dec 11, 2023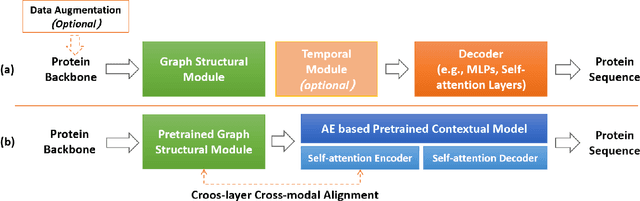
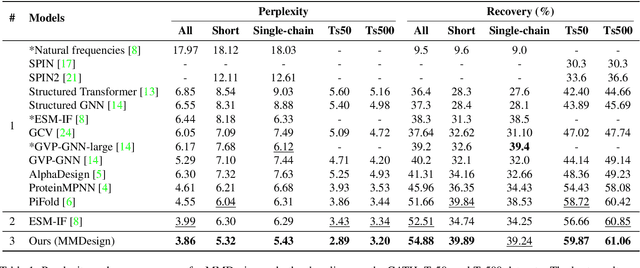
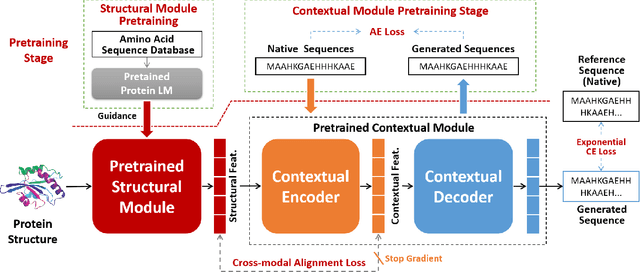
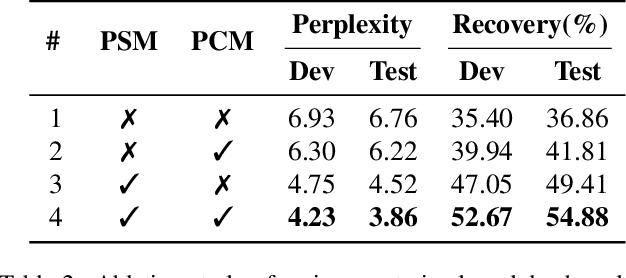
Protein design involves generating protein sequences based on their corresponding protein backbones. While deep generative models show promise for learning protein design directly from data, the lack of publicly available structure-sequence pairings limits their generalization capabilities. Previous efforts of generative protein design have focused on architectural improvements and pseudo-data augmentation to overcome this bottleneck. To further address this challenge, we propose a novel protein design paradigm called MMDesign, which leverages multi-modality transfer learning. To our knowledge, MMDesign is the first framework that combines a pretrained structural module with a pretrained contextual module, using an auto-encoder (AE) based language model to incorporate prior semantic knowledge of protein sequences. We also introduce a cross-layer cross-modal alignment algorithm to enable the structural module to learn long-term temporal information and ensure consistency between structural and contextual modalities. Experimental results, only training with the small CATH dataset, demonstrate that our MMDesign framework consistently outperforms other baselines on various public test sets. To further assess the biological plausibility of the generated protein sequences and data distribution, we present systematic quantitative analysis techniques that provide interpretability and reveal more about the laws of protein design.
Why "classic" Transformers are shallow and how to make them go deep
Dec 11, 2023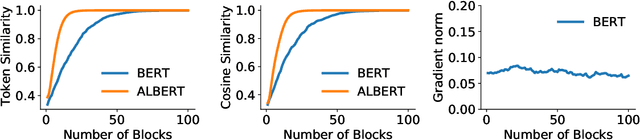

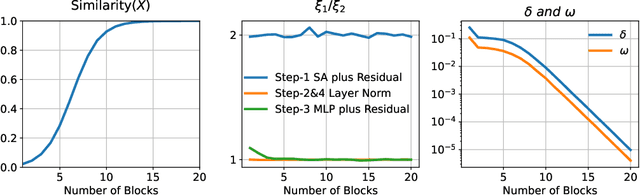
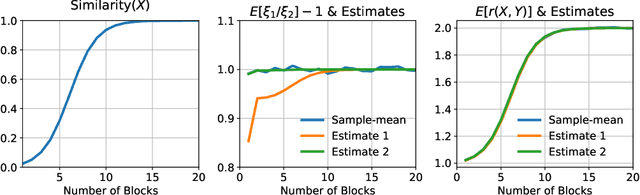
Since its introduction in 2017, Transformer has emerged as the leading neural network architecture, catalyzing revolutionary advancements in many AI disciplines. The key innovation in Transformer is a Self-Attention (SA) mechanism designed to capture contextual information. However, extending the original Transformer design to models of greater depth has proven exceedingly challenging, if not impossible. Even though various modifications have been proposed in order to stack more layers of SA mechanism into deeper models, a full understanding of this depth problem remains elusive. In this paper, we conduct a comprehensive investigation, both theoretically and empirically, to substantiate the claim that the depth problem is caused by \emph{token similarity escalation}; that is, tokens grow increasingly alike after repeated applications of the SA mechanism. Our analysis reveals that, driven by the invariant leading eigenspace and large spectral gaps of attention matrices, token similarity provably escalates at a linear rate. Based on the gained insight, we propose a simple strategy that, unlike most existing methods, surgically removes excessive similarity without discounting the SA mechanism as a whole. Preliminary experimental results confirm the effectiveness of the proposed approach on moderate-scale post-norm Transformer models.
ConvD: Attention Enhanced Dynamic Convolutional Embeddings for Knowledge Graph Completion
Dec 11, 2023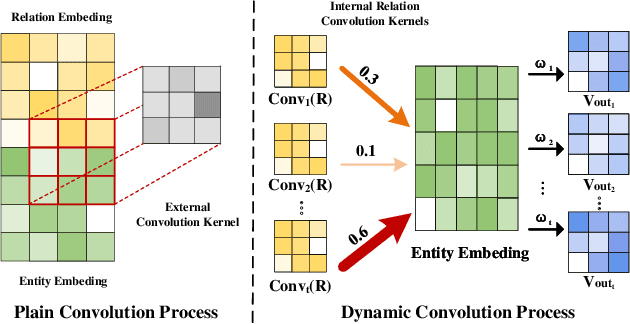

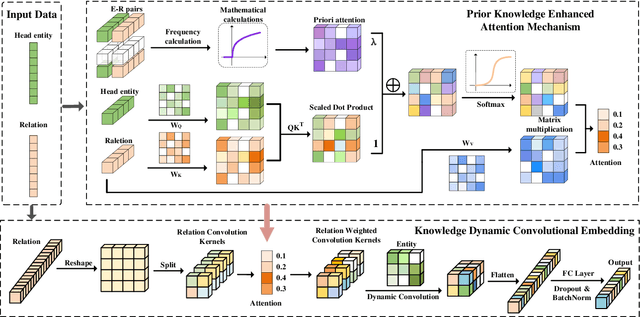
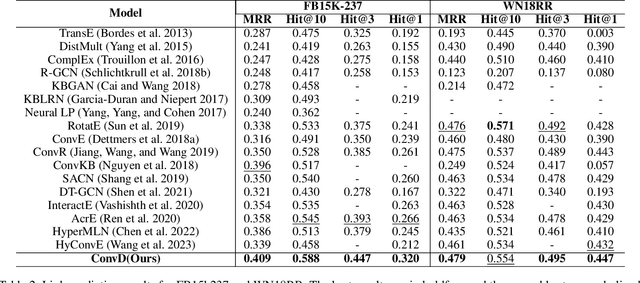
Knowledge graphs generally suffer from incompleteness, which can be alleviated by completing the missing information. Deep knowledge convolutional embedding models based on neural networks are currently popular methods for knowledge graph completion. However, most existing methods use external convolution kernels and traditional plain convolution processes, which limits the feature interaction capability of the model. In this paper, we propose a novel dynamic convolutional embedding model ConvD for knowledge graph completion, which directly reshapes the relation embeddings into multiple internal convolution kernels to improve the external convolution kernels of the traditional convolutional embedding model. The internal convolution kernels can effectively augment the feature interaction between the relation embeddings and entity embeddings, thus enhancing the model embedding performance. Moreover, we design a priori knowledge-optimized attention mechanism, which can assign different contribution weight coefficients to multiple relation convolution kernels for dynamic convolution to improve the expressiveness of the model further. Extensive experiments on various datasets show that our proposed model consistently outperforms the state-of-the-art baseline methods, with average improvements ranging from 11.30\% to 16.92\% across all model evaluation metrics. Ablation experiments verify the effectiveness of each component module of the ConvD model.
SECNN: Squeeze-and-Excitation Convolutional Neural Network for Sentence Classification
Dec 11, 2023Sentence classification is one of the basic tasks of natural language processing. Convolution neural network (CNN) has the ability to extract n-grams features through convolutional filters and capture local correlations between consecutive words in parallel, so CNN is a popular neural network architecture to dealing with the task. But restricted by the width of convolutional filters, it is difficult for CNN to capture long term contextual dependencies. Attention is a mechanism that considers global information and pays more attention to keywords in sentences, thus attention mechanism is cooperated with CNN network to improve performance in sentence classification task. In our work, we don't focus on keyword in a sentence, but on which CNN's output feature map is more important. We propose a Squeeze-and-Excitation Convolutional neural Network (SECNN) for sentence classification. SECNN takes the feature maps from multiple CNN as different channels of sentence representation, and then, we can utilize channel attention mechanism, that is SE attention mechanism, to enable the model to learn the attention weights of different channel features. The results show that our model achieves advanced performance in the sentence classification task.
LiDAR-based Person Re-identification
Dec 11, 2023Camera-based person re-identification (ReID) systems have been widely applied in the field of public security. However, cameras often lack the perception of 3D morphological information of human and are susceptible to various limitations, such as inadequate illumination, complex background, and personal privacy. In this paper, we propose a LiDAR-based ReID framework, ReID3D, that utilizes pre-training strategy to retrieve features of 3D body shape and introduces Graph-based Complementary Enhancement Encoder for extracting comprehensive features. Due to the lack of LiDAR datasets, we build LReID, the first LiDAR-based person ReID dataset, which is collected in several outdoor scenes with variations in natural conditions. Additionally, we introduce LReID-sync, a simulated pedestrian dataset designed for pre-training encoders with tasks of point cloud completion and shape parameter learning. Extensive experiments on LReID show that ReID3D achieves exceptional performance with a rank-1 accuracy of 94.0, highlighting the significant potential of LiDAR in addressing person ReID tasks. To the best of our knowledge, we are the first to propose a solution for LiDAR-based ReID. The code and datasets will be released soon.