 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
MusicAOG: an Energy-Based Model for Learning and Sampling a Hierarchical Representation of Symbolic Music
Jan 05, 2024
In addressing the challenge of interpretability and generalizability of artificial music intelligence, this paper introduces a novel symbolic representation that amalgamates both explicit and implicit musical information across diverse traditions and granularities. Utilizing a hierarchical and-or graph representation, the model employs nodes and edges to encapsulate a broad spectrum of musical elements, including structures, textures, rhythms, and harmonies. This hierarchical approach expands the representability across various scales of music. This representation serves as the foundation for an energy-based model, uniquely tailored to learn musical concepts through a flexible algorithm framework relying on the minimax entropy principle. Utilizing an adapted Metropolis-Hastings sampling technique, the model enables fine-grained control over music generation. A comprehensive empirical evaluation, contrasting this novel approach with existing methodologies, manifests considerable advancements in interpretability and controllability. This study marks a substantial contribution to the fields of music analysis, composition, and computational musicology.
BRAU-Net++: U-Shaped Hybrid CNN-Transformer Network for Medical Image Segmentation
Jan 01, 2024Accurate medical image segmentation is essential for clinical quantification, disease diagnosis, treatment planning and many other applications. Both convolution-based and transformer-based u-shaped architectures have made significant success in various medical image segmentation tasks. The former can efficiently learn local information of images while requiring much more image-specific inductive biases inherent to convolution operation. The latter can effectively capture long-range dependency at different feature scales using self-attention, whereas it typically encounters the challenges of quadratic compute and memory requirements with sequence length increasing. To address this problem, through integrating the merits of these two paradigms in a well-designed u-shaped architecture, we propose a hybrid yet effective CNN-Transformer network, named BRAU-Net++, for an accurate medical image segmentation task. Specifically, BRAU-Net++ uses bi-level routing attention as the core building block to design our u-shaped encoder-decoder structure, in which both encoder and decoder are hierarchically constructed, so as to learn global semantic information while reducing computational complexity. Furthermore, this network restructures skip connection by incorporating channel-spatial attention which adopts convolution operations, aiming to minimize local spatial information loss and amplify global dimension-interaction of multi-scale features. Extensive experiments on three public benchmark datasets demonstrate that our proposed approach surpasses other state-of-the-art methods including its baseline: BRAU-Net under almost all evaluation metrics. We achieve the average Dice-Similarity Coefficient (DSC) of 82.47, 90.10, and 92.94 on Synapse multi-organ segmentation, ISIC-2018 Challenge, and CVC-ClinicDB, as well as the mIoU of 84.01 and 88.17 on ISIC-2018 Challenge and CVC-ClinicDB, respectively.
QoS-Aware Graph Contrastive Learning for Web Service Recommendation
Jan 06, 2024With the rapid growth of cloud services driven by advancements in web service technology, selecting a high-quality service from a wide range of options has become a complex task. This study aims to address the challenges of data sparsity and the cold-start problem in web service recommendation using Quality of Service (QoS). We propose a novel approach called QoS-aware graph contrastive learning (QAGCL) for web service recommendation. Our model harnesses the power of graph contrastive learning to handle cold-start problems and improve recommendation accuracy effectively. By constructing contextually augmented graphs with geolocation information and randomness, our model provides diverse views. Through the use of graph convolutional networks and graph contrastive learning techniques, we learn user and service embeddings from these augmented graphs. The learned embeddings are then utilized to seamlessly integrate QoS considerations into the recommendation process. Experimental results demonstrate the superiority of our QAGCL model over several existing models, highlighting its effectiveness in addressing data sparsity and the cold-start problem in QoS-aware service recommendations. Our research contributes to the potential for more accurate recommendations in real-world scenarios, even with limited user-service interaction data.
Interpersonal Relationship Analysis with Dyadic EEG Signals via Learning Spatial-Temporal Patterns
Jan 06, 2024Interpersonal relationship quality is pivotal in social and occupational contexts. Existing analysis of interpersonal relationships mostly rely on subjective self-reports, whereas objective quantification remains challenging. In this paper, we propose a novel social relationship analysis framework using spatio-temporal patterns derived from dyadic EEG signals, which can be applied to quantitatively measure team cooperation in corporate team building, and evaluate interpersonal dynamics between therapists and patients in psychiatric therapy. First, we constructed a dyadic-EEG dataset from 72 pairs of participants with two relationships (stranger or friend) when watching emotional videos simultaneously. Then we proposed a deep neural network on dyadic-subject EEG signals, in which we combine the dynamic graph convolutional neural network for characterizing the interpersonal relationships among the EEG channels and 1-dimension convolution for extracting the information from the time sequence. To obtain the feature vectors from two EEG recordings that well represent the relationship of two subjects, we integrate deep canonical correlation analysis and triplet loss for training the network. Experimental results show that the social relationship type (stranger or friend) between two individuals can be effectively identified through their EEG data.
What Really is `Molecule' in Molecular Communications? The Quest for Physics of Particle-based Information Carriers
Dec 03, 2023Molecular communication, as implied by its name, uses molecules as information carriers for communication between objects. It has an advantage over traditional electromagnetic-wave-based communication in that molecule-based systems could be biocompatible, operable in challenging environments, and energetically undemanding. Consequently, they are envisioned to have a broad range of applications, such as in the Internet of Bio-nano Things, targeted drug delivery, and agricultural monitoring. Despite the rapid development of the field, with an increasing number of theoretical models and experimental testbeds established by researchers, a fundamental aspect of the field has often been sidelined, namely, the nature of the molecule in molecular communication. The potential information molecules could exhibit a wide range of properties, making them require drastically different treatments when being modeled and experimented upon. Therefore, in this paper, we delve into the intricacies of commonly used information molecules, examining their fundamental physical characteristics, associated communication systems, and potential applications in a more realistic manner, focusing on the influence of their own properties. Through this comprehensive survey, we aim to offer a novel yet essential perspective on molecular communication, thereby bridging the current gap between theoretical research and real-world applications.
CCNETS: A Novel Brain-Inspired Approach for Enhanced Pattern Recognition in Imbalanced Datasets
Jan 07, 2024This study introduces CCNETS (Causal Learning with Causal Cooperative Nets), a novel generative model-based classifier designed to tackle the challenge of generating data for imbalanced datasets in pattern recognition. CCNETS is uniquely crafted to emulate brain-like information processing and comprises three main components: Explainer, Producer, and Reasoner. Each component is designed to mimic specific brain functions, which aids in generating high-quality datasets and enhancing classification performance. The model is particularly focused on addressing the common and significant challenge of handling imbalanced datasets in machine learning. CCNETS's effectiveness is demonstrated through its application to a "fraud dataset," where normal transactions significantly outnumber fraudulent ones (99.83% vs. 0.17%). Traditional methods often struggle with such imbalances, leading to skewed performance metrics. However, CCNETS exhibits superior classification ability, as evidenced by its performance metrics. Specifically, it achieved an F1-score of 0.7992, outperforming traditional models like Autoencoders and Multi-layer Perceptrons (MLP) in the same context. This performance indicates CCNETS's proficiency in more accurately distinguishing between normal and fraudulent patterns. The innovative structure of CCNETS enhances the coherence between generative and classification models, helping to overcome the limitations of pattern recognition that rely solely on generative models. This study emphasizes CCNETS's potential in diverse applications, especially where quality data generation and pattern recognition are key. It proves effective in machine learning, particularly for imbalanced datasets. CCNETS overcomes current challenges in these datasets and advances machine learning with brain-inspired approaches.
GOAT-Bench: Safety Insights to Large Multimodal Models through Meme-Based Social Abuse
Jan 07, 2024The exponential growth of social media has profoundly transformed how information is created, disseminated, and absorbed, exceeding any precedent in the digital age. Regrettably, this explosion has also spawned a significant increase in the online abuse of memes. Evaluating the negative impact of memes is notably challenging, owing to their often subtle and implicit meanings, which are not directly conveyed through the overt text and imagery. In light of this, large multimodal models (LMMs) have emerged as a focal point of interest due to their remarkable capabilities in handling diverse multimodal tasks. In response to this development, our paper aims to thoroughly examine the capacity of various LMMs (e.g. GPT-4V) to discern and respond to the nuanced aspects of social abuse manifested in memes. We introduce the comprehensive meme benchmark, GOAT-Bench, comprising over 6K varied memes encapsulating themes such as implicit hate speech, sexism, and cyberbullying, etc. Utilizing GOAT-Bench, we delve into the ability of LMMs to accurately assess hatefulness, misogyny, offensiveness, sarcasm, and harmful content. Our extensive experiments across a range of LMMs reveal that current models still exhibit a deficiency in safety awareness, showing insensitivity to various forms of implicit abuse. We posit that this shortfall represents a critical impediment to the realization of safe artificial intelligence. The GOAT-Bench and accompanying resources are publicly accessible at https://goatlmm.github.io/, contributing to ongoing research in this vital field.
BEAST: Online Joint Beat and Downbeat Tracking Based on Streaming Transformer
Jan 05, 2024Many deep learning models have achieved dominant performance on the offline beat tracking task. However, online beat tracking, in which only the past and present input features are available, still remains challenging. In this paper, we propose BEAt tracking Streaming Transformer (BEAST), an online joint beat and downbeat tracking system based on the streaming Transformer. To deal with online scenarios, BEAST applies contextual block processing in the Transformer encoder. Moreover, we adopt relative positional encoding in the attention layer of the streaming Transformer encoder to capture relative timing position which is critically important information in music. Carrying out beat and downbeat experiments on benchmark datasets for a low latency scenario with maximum latency under 50 ms, BEAST achieves an F1-measure of 80.04% in beat and 52.73% in downbeat, which is a substantial improvement of about 5 and 13 percentage points over the state-of-the-art online beat and downbeat tracking model.
Text mining arXiv: a look through quantitative finance papers
Jan 03, 2024This paper explores articles hosted on the arXiv preprint server with the aim to uncover valuable insights hidden in this vast collection of research. Employing text mining techniques and through the application of natural language processing methods, we examine the contents of quantitative finance papers posted in arXiv from 1997 to 2022. We extract and analyze crucial information from the entire documents, including the references, to understand the topics trends over time and to find out the most cited researchers and journals on this domain. Additionally, we compare numerous algorithms to perform topic modeling, including state-of-the-art approaches.
Difference of Probability and Information Entropy for Skills Classification and Prediction in Student Learning
Dec 10, 2023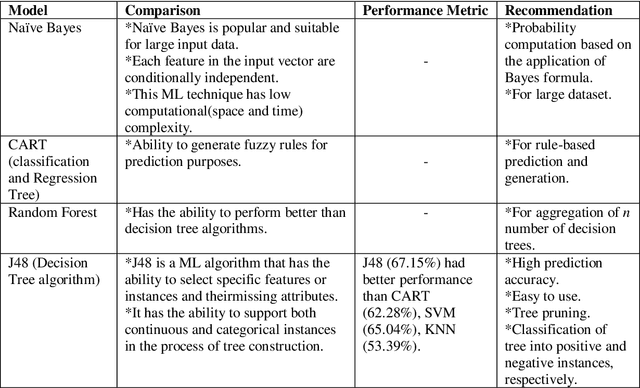
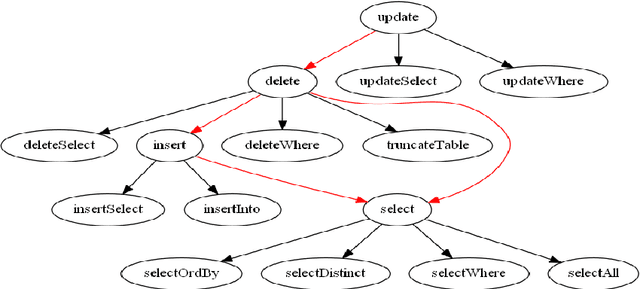
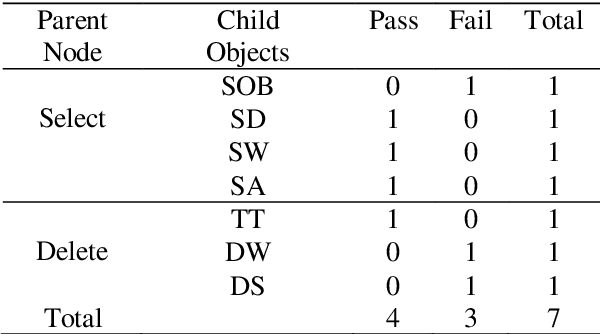
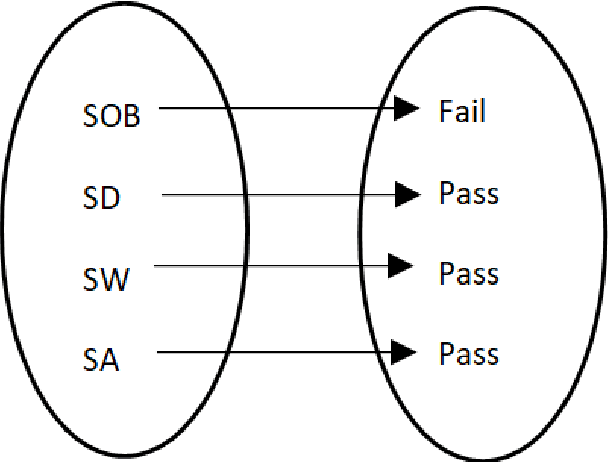
The probability of an event is in the range of [0, 1]. In a sample space S, the value of probability determines whether an outcome is true or false. The probability of an event Pr(A) that will never occur = 0. The probability of the event Pr(B) that will certainly occur = 1. This makes both events A and B thus a certainty. Furthermore, the sum of probabilities Pr(E1) + Pr(E2) + ... + Pr(En) of a finite set of events in a given sample space S = 1. Conversely, the difference of the sum of two probabilities that will certainly occur is 0. Firstly, this paper discusses Bayes' theorem, then complement of probability and the difference of probability for occurrences of learning-events, before applying these in the prediction of learning objects in student learning. Given the sum total of 1; to make recommendation for student learning, this paper submits that the difference of argMaxPr(S) and probability of student-performance quantifies the weight of learning objects for students. Using a dataset of skill-set, the computational procedure demonstrates: i) the probability of skill-set events that has occurred that would lead to higher level learning; ii) the probability of the events that has not occurred that requires subject-matter relearning; iii) accuracy of decision tree in the prediction of student performance into class labels; and iv) information entropy about skill-set data and its implication on student cognitive performance and recommendation of learning [1].