 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEEG-to-Voice Decoding of Spoken and Imagined speech Using Non-Invasive EEG
Dec 14, 2025Restoring speech communication from neural signals is a central goal of brain-computer interface research, yet EEG-based speech reconstruction remains challenging due to limited spatial resolution, susceptibility to noise, and the absence of temporally aligned acoustic targets in imagined speech. In this study, we propose an EEG-to-Voice paradigm that directly reconstructs speech from non-invasive EEG signals without dynamic time warping (DTW) or explicit temporal alignment. The proposed pipeline generates mel-spectrograms from EEG in an open-loop manner using a subject-specific generator, followed by pretrained vocoder and automatic speech recognition (ASR) modules to synthesize speech waveforms and decode text. Separate generators were trained for spoken speech and imagined speech, and transfer learning-based domain adaptation was applied by pretraining on spoken speech and adapting to imagined speech. A minimal language model-based correction module was optionally applied to correct limited ASR errors while preserving semantic structure. The framework was evaluated under 2 s and 4 s speech conditions using acoustic-level metrics (PCC, RMSE, MCD) and linguistic-level metrics (CER, WER). Stable acoustic reconstruction and comparable linguistic accuracy were observed for both spoken speech and imagined speech. While acoustic similarity decreased for longer utterances, text-level decoding performance was largely preserved, and word-position analysis revealed a mild increase in decoding errors toward later parts of sentences. The language model-based correction consistently reduced CER and WER without introducing semantic distortion. These results demonstrate the feasibility of direct, open-loop EEG-to-Voice reconstruction for spoken speech and imagined speech without explicit temporal alignment.
CCNETS: A Novel Brain-Inspired Approach for Enhanced Pattern Recognition in Imbalanced Datasets
Jan 07, 2024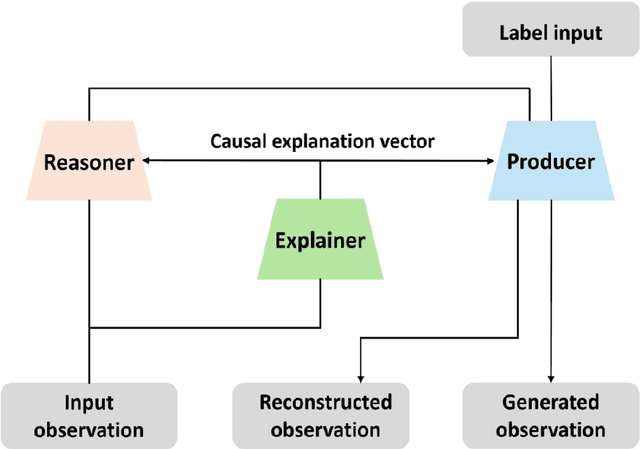
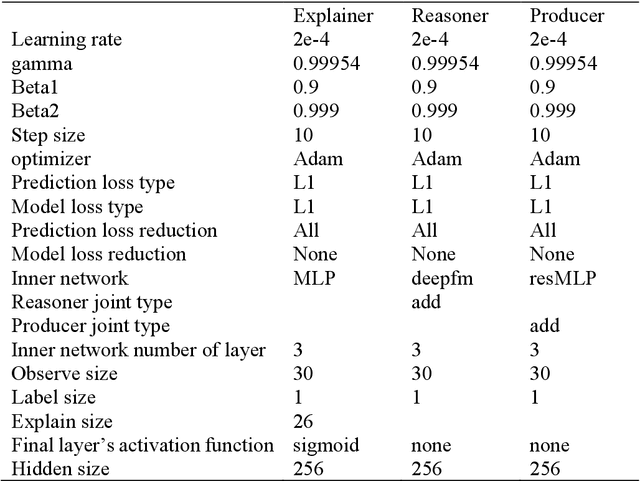
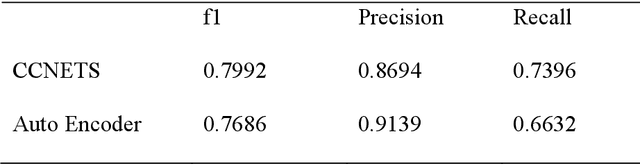
This study introduces CCNETS (Causal Learning with Causal Cooperative Nets), a novel generative model-based classifier designed to tackle the challenge of generating data for imbalanced datasets in pattern recognition. CCNETS is uniquely crafted to emulate brain-like information processing and comprises three main components: Explainer, Producer, and Reasoner. Each component is designed to mimic specific brain functions, which aids in generating high-quality datasets and enhancing classification performance. The model is particularly focused on addressing the common and significant challenge of handling imbalanced datasets in machine learning. CCNETS's effectiveness is demonstrated through its application to a "fraud dataset," where normal transactions significantly outnumber fraudulent ones (99.83% vs. 0.17%). Traditional methods often struggle with such imbalances, leading to skewed performance metrics. However, CCNETS exhibits superior classification ability, as evidenced by its performance metrics. Specifically, it achieved an F1-score of 0.7992, outperforming traditional models like Autoencoders and Multi-layer Perceptrons (MLP) in the same context. This performance indicates CCNETS's proficiency in more accurately distinguishing between normal and fraudulent patterns. The innovative structure of CCNETS enhances the coherence between generative and classification models, helping to overcome the limitations of pattern recognition that rely solely on generative models. This study emphasizes CCNETS's potential in diverse applications, especially where quality data generation and pattern recognition are key. It proves effective in machine learning, particularly for imbalanced datasets. CCNETS overcomes current challenges in these datasets and advances machine learning with brain-inspired approaches.