 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Refer-it-in-RGBD: A Bottom-up Approach for 3D Visual Grounding in RGBD Images
Mar 16, 2021


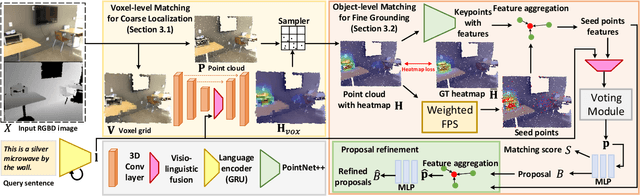
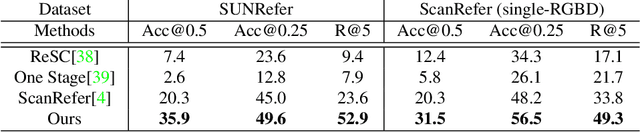
Grounding referring expressions in RGBD image has been an emerging field. We present a novel task of 3D visual grounding in single-view RGBD image where the referred objects are often only partially scanned due to occlusion. In contrast to previous works that directly generate object proposals for grounding in the 3D scenes, we propose a bottom-up approach to gradually aggregate context-aware information, effectively addressing the challenge posed by the partial geometry. Our approach first fuses the language and the visual features at the bottom level to generate a heatmap that coarsely localizes the relevant regions in the RGBD image. Then our approach conducts an adaptive feature learning based on the heatmap and performs the object-level matching with another visio-linguistic fusion to finally ground the referred object. We evaluate the proposed method by comparing to the state-of-the-art methods on both the RGBD images extracted from the ScanRefer dataset and our newly collected SUNRefer dataset. Experiments show that our method outperforms the previous methods by a large margin (by 11.2% and 15.6% Acc@0.5) on both datasets.
Deep Bag-of-Sub-Emotions for Depression Detection in Social Media
Mar 01, 2021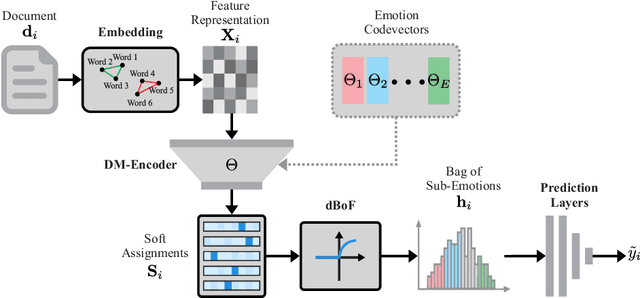
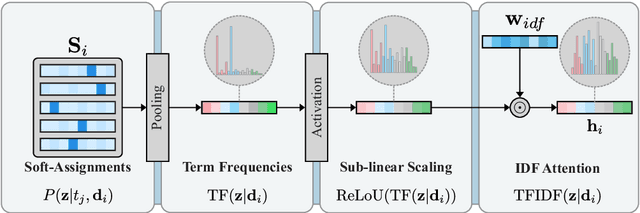
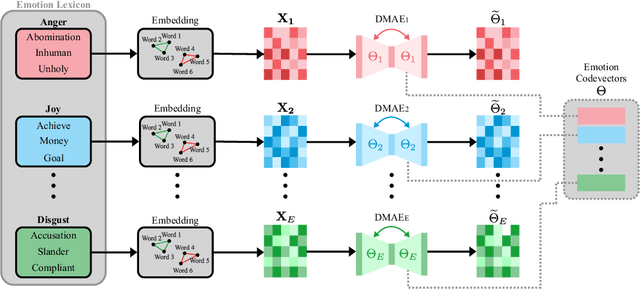
This paper presents the Deep Bag-of-Sub-Emotions (DeepBoSE), a novel deep learning model for depression detection in social media. The model is formulated such that it internally computes a differentiable Bag-of-Features (BoF) representation that incorporates emotional information. This is achieved by a reinterpretation of classical weighting schemes like term frequency-inverse document frequency into probabilistic deep learning operations. An important advantage of the proposed method is that it can be trained under the transfer learning paradigm, which is useful to enhance conventional BoF models that cannot be directly integrated into deep learning architectures. Experiments were performed in the eRisk17 and eRisk18 datasets for the depression detection task; results show that DeepBoSE outperforms conventional BoF representations and it is competitive with the state of the art, achieving a F1-score over the positive class of 0.64 in eRisk17 and 0.65 in eRisk18.
Energy-Efficient Resource Allocation in Massive MIMO-NOMA Networks with Wireless Power Transfer: A Distributed ADMM Approach
Mar 24, 2021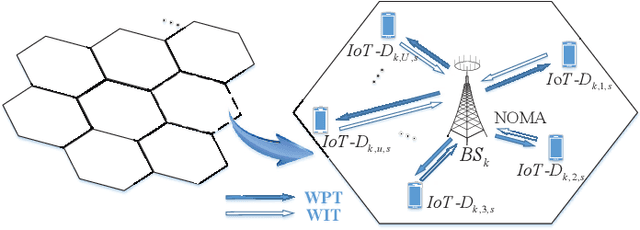
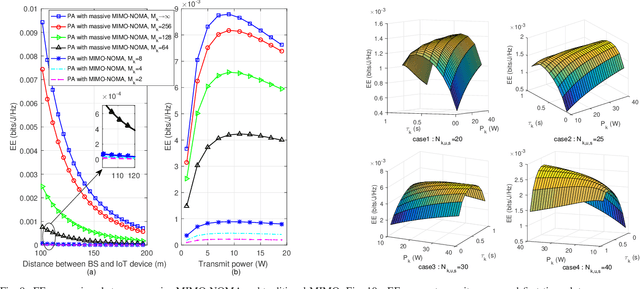
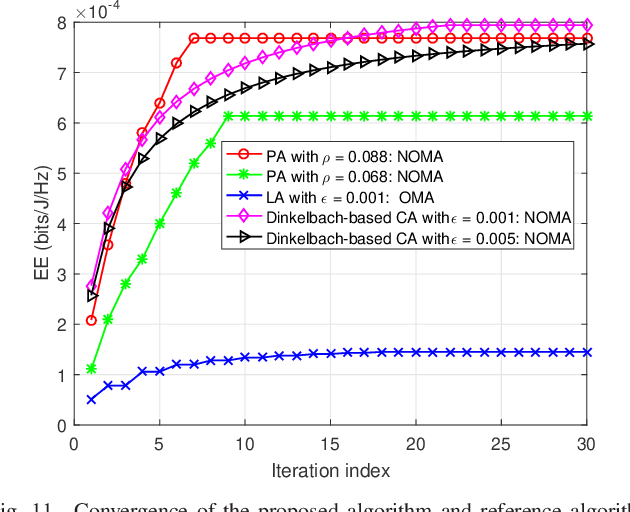
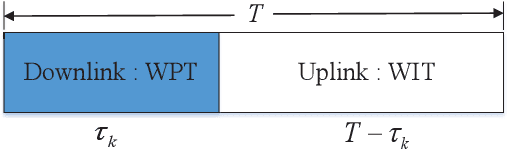
In multicell massive multiple-input multiple-output (MIMO) non-orthogonal multiple access (NOMA) networks, base stations (BSs) with multiple antennas deliver their radio frequency energy in the downlink, and Internet-of-Things (IoT) devices use their harvested energy to support uplink data transmission. This paper investigates the energy efficiency (EE) problem for multicell massive MIMO NOMA networks with wireless power transfer (WPT). To maximize the EE of the network, we propose a novel joint power, time, antenna selection, and subcarrier resource allocation scheme, which can properly allocate the time for energy harvesting and data transmission. Both perfect and imperfect channel state information (CSI) are considered, and their corresponding EE performance is analyzed. Under quality-of-service (QoS) requirements, an EE maximization problem is formulated, which is non-trivial due to non-convexity. We first adopt nonlinear fraction programming methods to convert the problem to be convex, and then, develop a distributed alternating direction method of multipliers (ADMM)- based approach to solve the problem. Simulation results demonstrate that compared to alternative methods, the proposed algorithm can converge quickly within fewer iterations, and can achieve better EE performance.
GKD: Semi-supervised Graph Knowledge Distillation for Graph-Independent Inference
Apr 08, 2021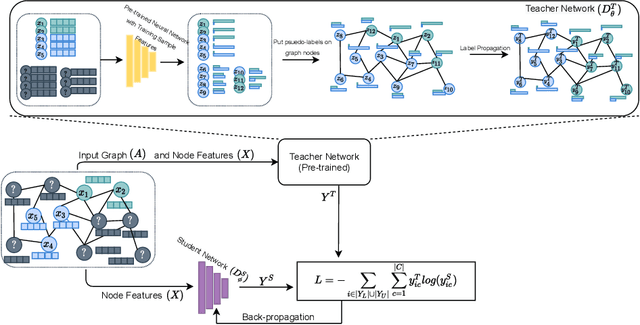
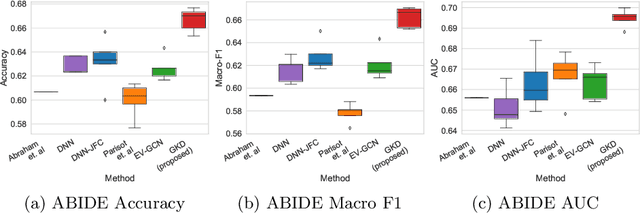
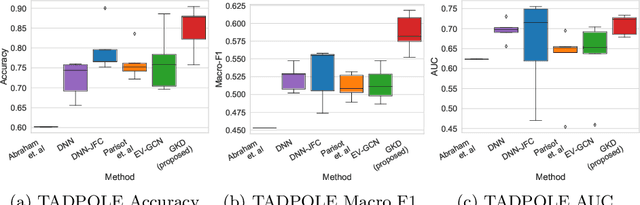
The increased amount of multi-modal medical data has opened the opportunities to simultaneously process various modalities such as imaging and non-imaging data to gain a comprehensive insight into the disease prediction domain. Recent studies using Graph Convolutional Networks (GCNs) provide novel semi-supervised approaches for integrating heterogeneous modalities while investigating the patients' associations for disease prediction. However, when the meta-data used for graph construction is not available at inference time (e.g., coming from a distinct population), the conventional methods exhibit poor performance. To address this issue, we propose a novel semi-supervised approach named GKD based on knowledge distillation. We train a teacher component that employs the label-propagation algorithm besides a deep neural network to benefit from the graph and non-graph modalities only in the training phase. The teacher component embeds all the available information into the soft pseudo-labels. The soft pseudo-labels are then used to train a deep student network for disease prediction of unseen test data for which the graph modality is unavailable. We perform our experiments on two public datasets for diagnosing Autism spectrum disorder, and Alzheimer's disease, along with a thorough analysis on synthetic multi-modal datasets. According to these experiments, GKD outperforms the previous graph-based deep learning methods in terms of accuracy, AUC, and Macro F1.
Watching You: Global-guided Reciprocal Learning for Video-based Person Re-identification
Apr 01, 2021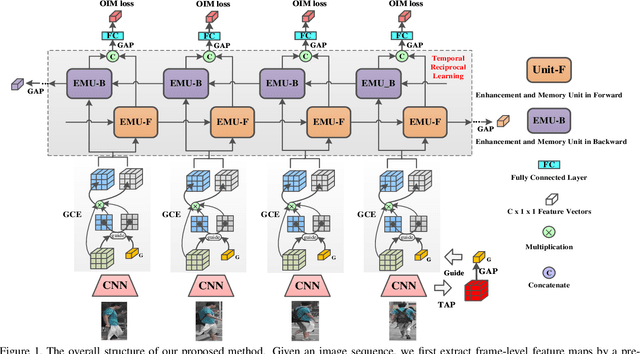
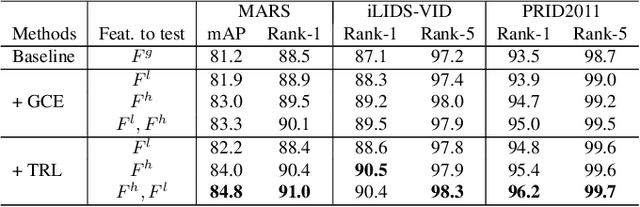
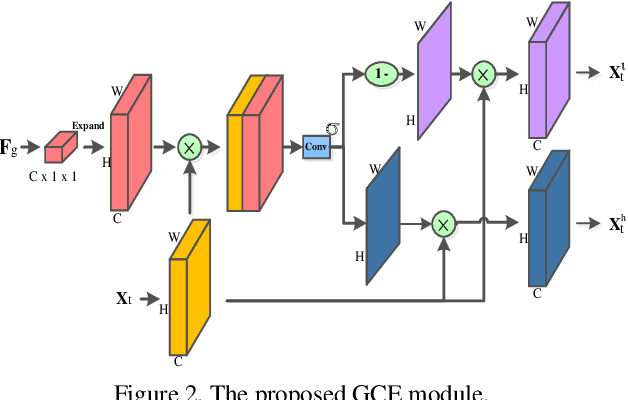
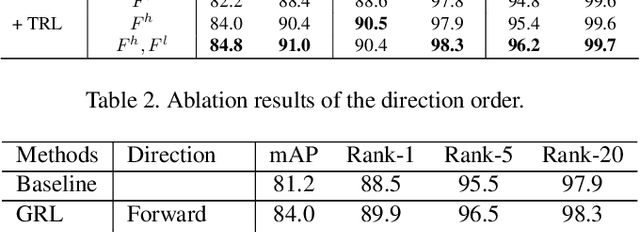
Video-based person re-identification (Re-ID) aims to automatically retrieve video sequences of the same person under non-overlapping cameras. To achieve this goal, it is the key to fully utilize abundant spatial and temporal cues in videos. Existing methods usually focus on the most conspicuous image regions, thus they may easily miss out fine-grained clues due to the person varieties in image sequences. To address above issues, in this paper, we propose a novel Global-guided Reciprocal Learning (GRL) framework for video-based person Re-ID. Specifically, we first propose a Global-guided Correlation Estimation (GCE) to generate feature correlation maps of local features and global features, which help to localize the high- and low-correlation regions for identifying the same person. After that, the discriminative features are disentangled into high-correlation features and low-correlation features under the guidance of the global representations. Moreover, a novel Temporal Reciprocal Learning (TRL) mechanism is designed to sequentially enhance the high-correlation semantic information and accumulate the low-correlation sub-critical clues. Extensive experiments are conducted on three public benchmarks. The experimental results indicate that our approach can achieve better performance than other state-of-the-art approaches. The code is released at https://github.com/flysnowtiger/GRL.
Towards Robust Speaker Verification with Target Speaker Enhancement
Mar 16, 2021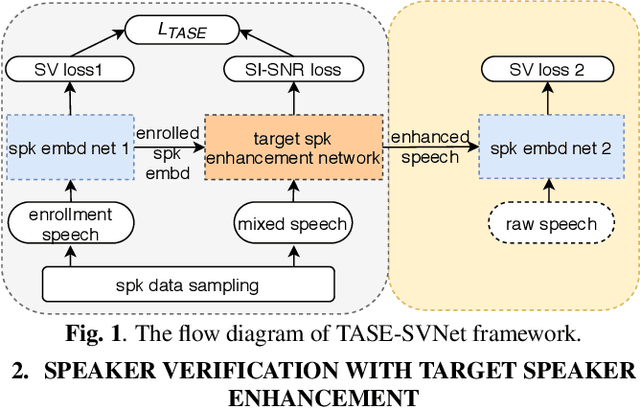
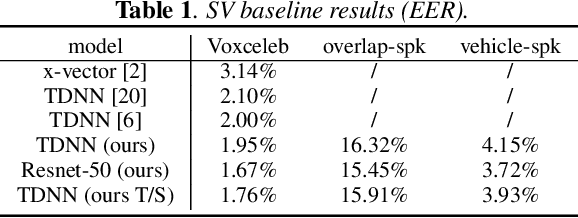
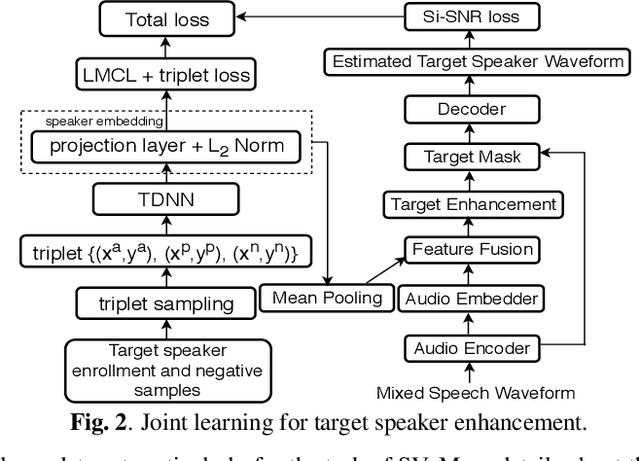
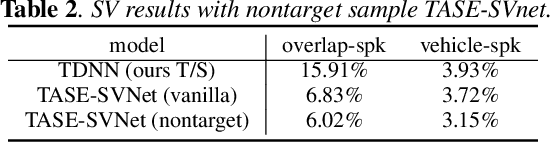
This paper proposes the target speaker enhancement based speaker verification network (TASE-SVNet), an all neural model that couples target speaker enhancement and speaker embedding extraction for robust speaker verification (SV). Specifically, an enrollment speaker conditioned speech enhancement module is employed as the front-end for extracting target speaker from its mixture with interfering speakers and environmental noises. Compared with the conventional target speaker enhancement models, nontarget speaker/interference suppression should draw additional attention for SV. Therefore, an effective nontarget speaker sampling strategy is explored. To improve speaker embedding extraction with a light-weighted model, a teacher-student (T/S) training is proposed to distill speaker discriminative information from large models to small models. Iterative inference is investigated to address the noisy speaker enrollment problem. We evaluate the proposed method on two SV tasks, i.e., one heavily overlapped speech and the other one with comprehensive noise types in vehicle environments. Experiments show significant and consistent improvements in Equal Error Rate (EER) over the state-of-the-art baselines.
Opinion-aware Answer Generation for Review-driven Question Answering in E-Commerce
Aug 27, 2020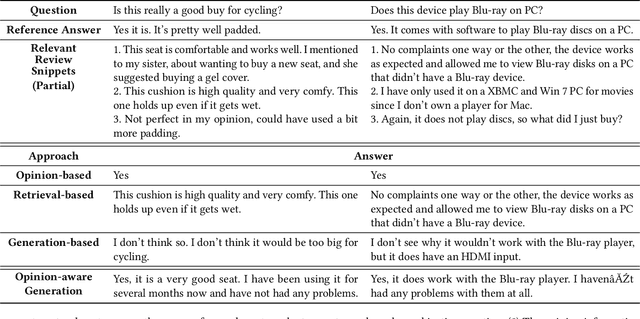
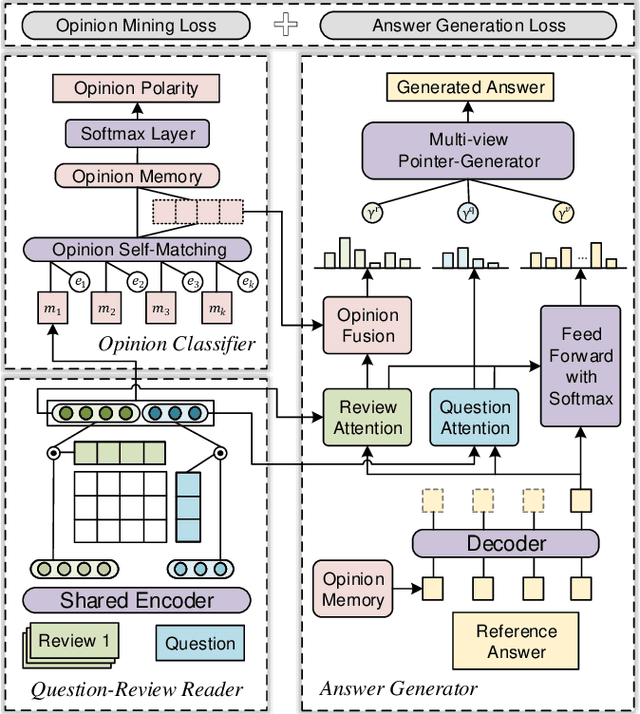
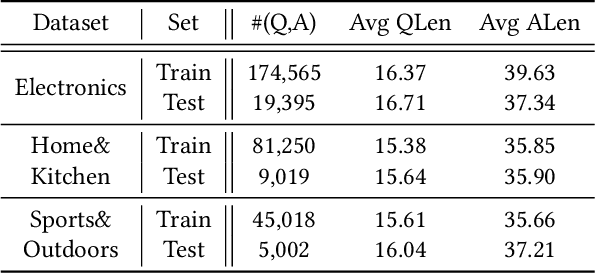
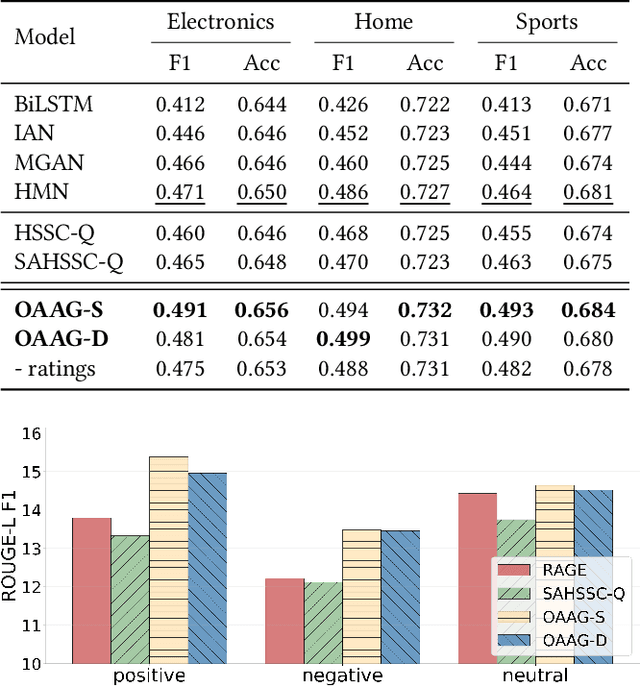
Product-related question answering (QA) is an important but challenging task in E-Commerce. It leads to a great demand on automatic review-driven QA, which aims at providing instant responses towards user-posted questions based on diverse product reviews. Nevertheless, the rich information about personal opinions in product reviews, which is essential to answer those product-specific questions, is underutilized in current generation-based review-driven QA studies. There are two main challenges when exploiting the opinion information from the reviews to facilitate the opinion-aware answer generation: (i) jointly modeling opinionated and interrelated information between the question and reviews to capture important information for answer generation, (ii) aggregating diverse opinion information to uncover the common opinion towards the given question. In this paper, we tackle opinion-aware answer generation by jointly learning answer generation and opinion mining tasks with a unified model. Two kinds of opinion fusion strategies, namely, static and dynamic fusion, are proposed to distill and aggregate important opinion information learned from the opinion mining task into the answer generation process. Then a multi-view pointer-generator network is employed to generate opinion-aware answers for a given product-related question. Experimental results show that our method achieves superior performance in real-world E-Commerce QA datasets, and effectively generate opinionated and informative answers.
Locus: LiDAR-based Place Recognition using Spatiotemporal Higher-Order Pooling
Nov 30, 2020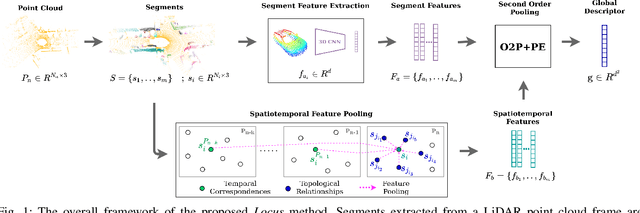
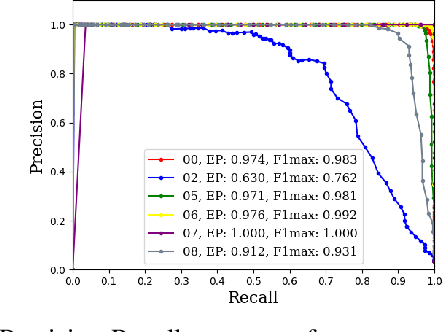
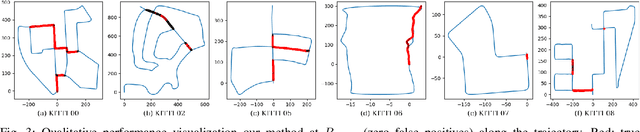
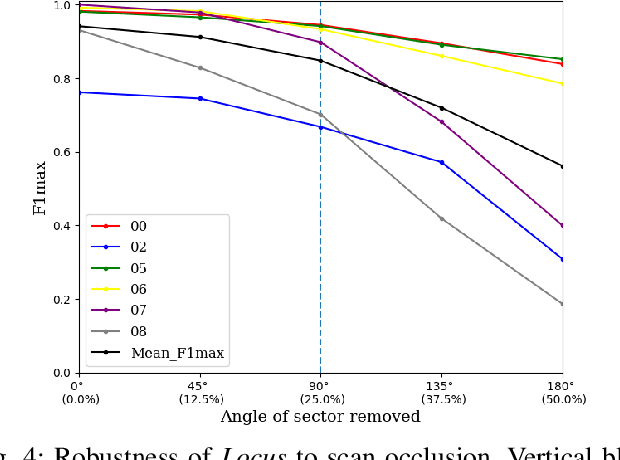
Place Recognition (PR) enables the estimation of a globally consistent map and trajectory by providing non-local constraints in Simultaneous Localisation and Mapping (SLAM). This paper presents Locus, a novel place recognition method using 3D LiDAR point clouds in large-scale environments. We propose a novel method for extracting and encoding topological and temporal information related to components in a scene and demonstrate how the inclusion of this auxiliary information in place description leads to more robust and discriminative scene representations. Second-order pooling along with a non-linear transform is used to aggregate these multi-level features to generate a fixed-length global descriptor, which is invariant to the permutation of input features. The proposed method outperforms state-of-the-art methods on the KITTI dataset. Furthermore, Locus is demonstrated to be robust across several challenging situations such as occlusions and viewpoint changes.
Multi-label Causal Variable Discovery: Learning Common Causal Variables and Label-specific Causal Variables
Nov 09, 2020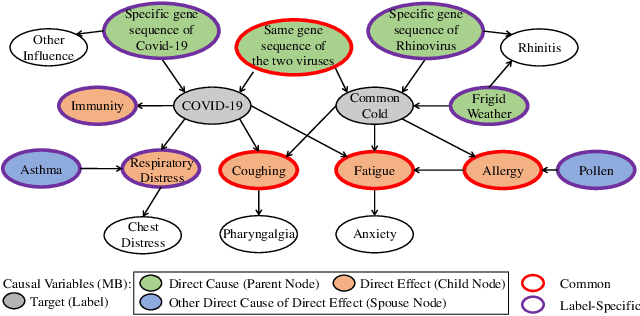
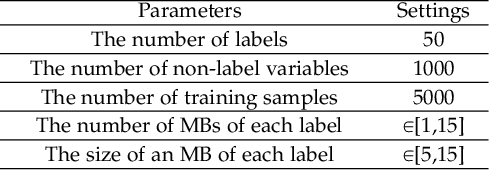

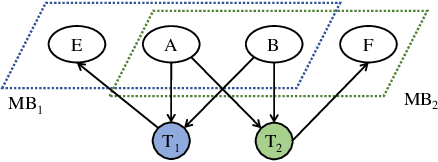
Causal variables in Markov boundary (MB) have been widely applied in extensive single-label tasks. While few researches focus on the causal variable discovery in multi-label data due to the complex causal relationships. Since some variables in multi-label scenario might contain causal information about multiple labels, this paper investigates the problem of multi-label causal variable discovery as well as the distinguishing between common causal variables shared by multiple labels and label-specific causal variables associated with some single labels. Considering the multiple MBs under the non-positive joint probability distribution, we explore the relationships between common causal variables and equivalent information phenomenon, and find that the solutions are influenced by equivalent information following different mechanisms with or without existence of label causality. Analyzing these mechanisms, we provide the theoretical property of common causal variables, based on which the discovery and distinguishing algorithm is designed to identify these two types of variables. Similar to single-label problem, causal variables for multiple labels also have extensive application prospects. To demonstrate this, we apply the proposed causal mechanism to multi-label feature selection and present an interpretable algorithm, which is proved to achieve the minimal redundancy and the maximum relevance. Extensive experiments demonstrate the efficacy of these contributions.
Synthetic Over-sampling with the Minority and Majority classes for imbalance problems
Nov 09, 2020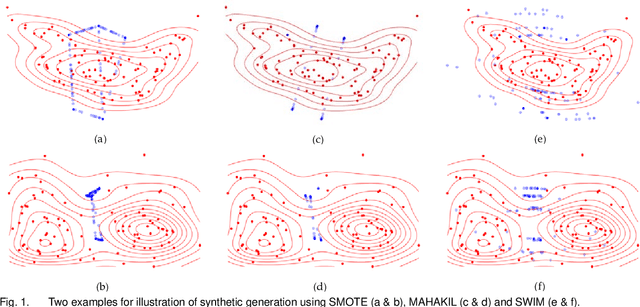
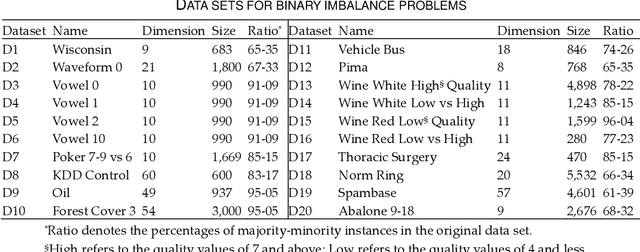
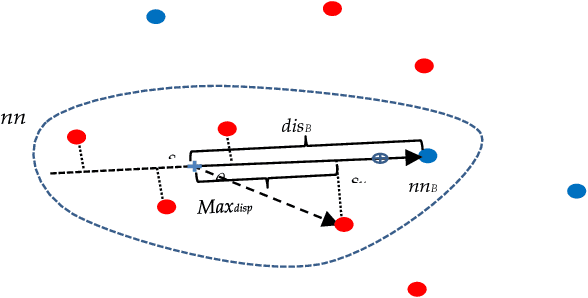
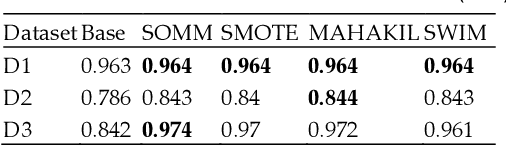
Class imbalance is a substantial challenge in classifying many real-world cases. Synthetic over-sampling methods have been effective to improve the performance of classifiers for imbalance problems. However, most synthetic over-sampling methods generate non-diverse synthetic instances within the convex hull formed by the existing minority instances as they only concentrate on the minority class and ignore the vast information provided by the majority class. They also often do not perform well for extremely imbalanced data as the fewer the minority instances, the less information to generate synthetic instances. Moreover, existing methods that generate synthetic instances using distributional information of the majority class cannot perform effectively when the majority class has a multi-modal distribution. We propose a new method to generate diverse and adaptable synthetic instances using Synthetic Over-sampling with the Minority and Majority classes (SOMM). SOMM generates synthetic instances diversely within the minority data space. It updates the generated instances adaptively to the neighbourhood including both classes. Thus, SOMM performs well for both binary and multiclass imbalance problems. We examine the performance of SOMM for binary and multiclass problems using benchmark data sets for different imbalance levels. The empirical results show the superiority of SOMM compared to other existing methods.