 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
A Statistical Model for Melody Reduction
May 12, 2021



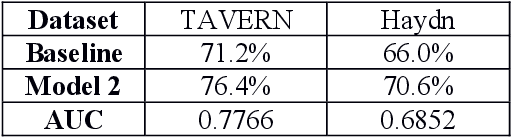
A commonly-cited reason for the poor performance of automatic chord estimation (ACE) systems within music information retrieval (MIR) is that non-chord tones (i.e., notes outside the supporting harmony) contribute to error during the labeling process. Despite the prevalence of machine learning approaches in MIR, there are cases where alternative approaches provide a simpler alternative while allowing for insights into musicological practices. In this project, we present a statistical model for predicting chord tones based on music theory rules. Our model is currently focused on predicting chord tones in classical music, since composition in this style is highly constrained, theoretically making the placement of chord tones highly predictable. Indeed, music theorists have labeling systems for every variety of non-chord tone, primarily classified by the note's metric position and intervals of approach and departure. Using metric position, duration, and melodic intervals as predictors, we build a statistical model for predicting chord tones using the TAVERN dataset. While our probabilistic approach is similar to other efforts in the domain of automatic harmonic analysis, our focus is on melodic reduction rather than predicting harmony. However, we hope to pursue applications for ACE in the future. Finally, we implement our melody reduction model using an existing symbolic visualization tool, to assist with melody reduction and non-chord tone identification for computational musicology researchers and music theorists.
LED2-Net: Monocular 360 Layout Estimation via Differentiable Depth Rendering
Apr 01, 2021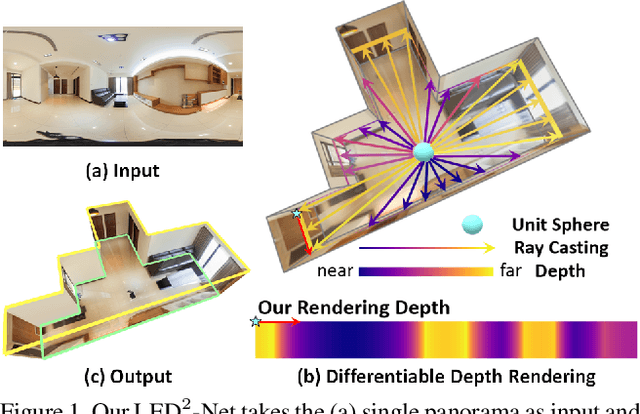
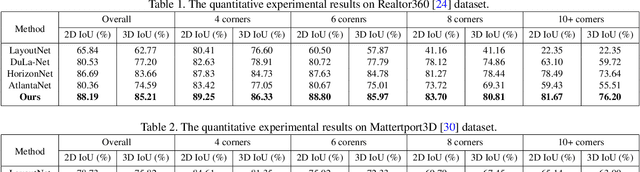


Although significant progress has been made in room layout estimation, most methods aim to reduce the loss in the 2D pixel coordinate rather than exploiting the room structure in the 3D space. Towards reconstructing the room layout in 3D, we formulate the task of 360 layout estimation as a problem of predicting depth on the horizon line of a panorama. Specifically, we propose the Differentiable Depth Rendering procedure to make the conversion from layout to depth prediction differentiable, thus making our proposed model end-to-end trainable while leveraging the 3D geometric information, without the need of providing the ground truth depth. Our method achieves state-of-the-art performance on numerous 360 layout benchmark datasets. Moreover, our formulation enables a pre-training step on the depth dataset, which further improves the generalizability of our layout estimation model.
Weight-Based Exploration for Unmanned Aerial Teams Searching for Multiple Survivors
Dec 21, 2020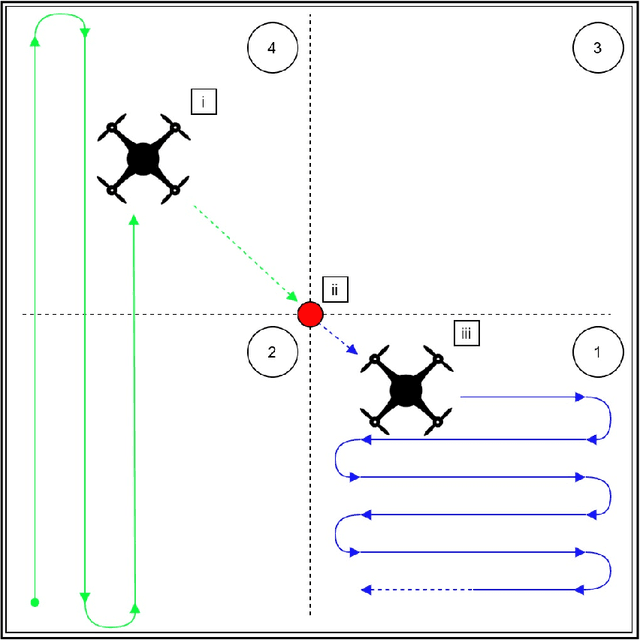
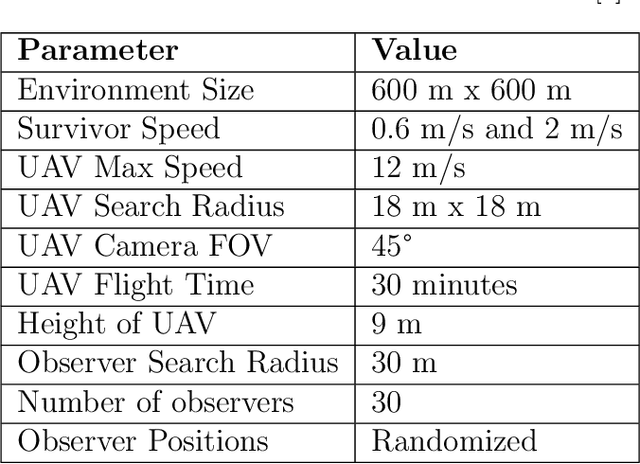
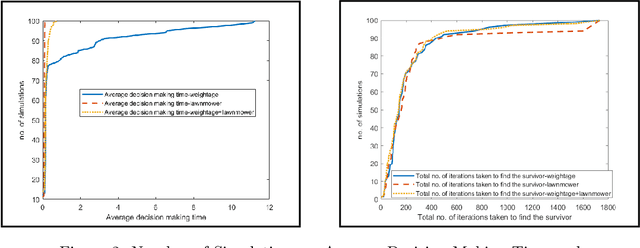
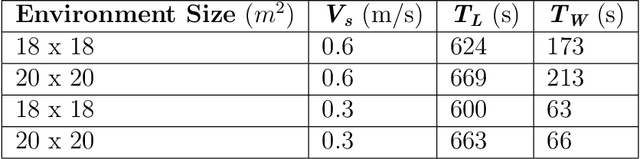
During floods, reaching survivors in the shortest possible time is a priority for rescue teams. Given their ability to explore difficult terrain in short spans of time, Unmanned Aerial Vehicles (UAVs) have become an increasingly valuable aid to search and rescue operations. Traditionally, UAVs utilize exhaustive lawnmower exploration patterns to locate stranded survivors, without any information regarding the survivor's whereabouts. In real life disaster scenarios however, on-ground observers provide valuable information to the rescue effort, such as the survivor's last known location and heading. In earlier work, a Weight Based Exploration (WBE) model, which utilizes this information to generate a prioritized list of waypoints to aid the UAV in its search mission, was proposed. This approach was shown to be effective for a single UAV locating a single survivor. In this paper, we extend the WBE model to a team of UAVs locating multiple survivors. The model initially partitions the search environment amongst the UAVs using Voronoi cells. The UAVs then utilize the WBE model to locate survivors in their partitions. We test this model with varying survivor locations and headings. We demonstrate the scalability of the model developed by testing the model with aerial teams comprising several UAVs.
ConTNet: Why not use convolution and transformer at the same time?
Apr 27, 2021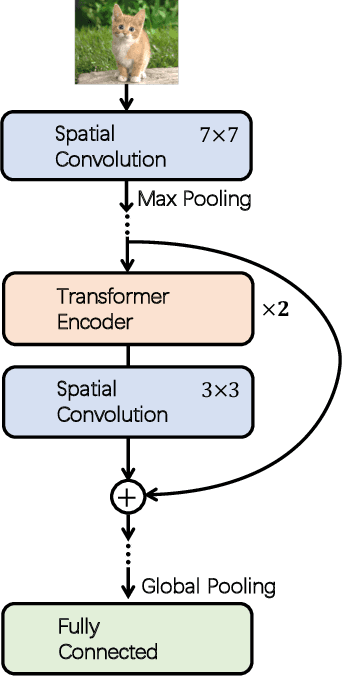
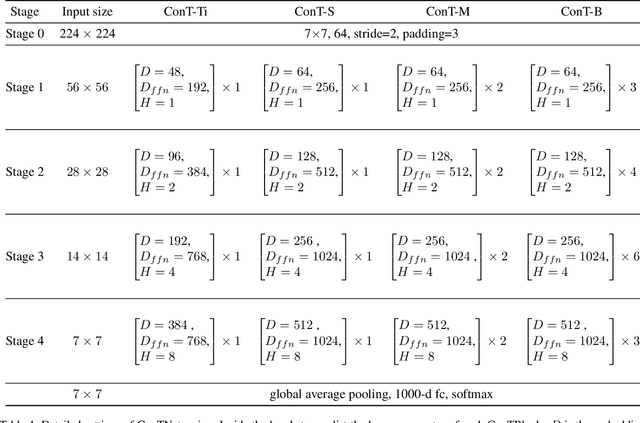

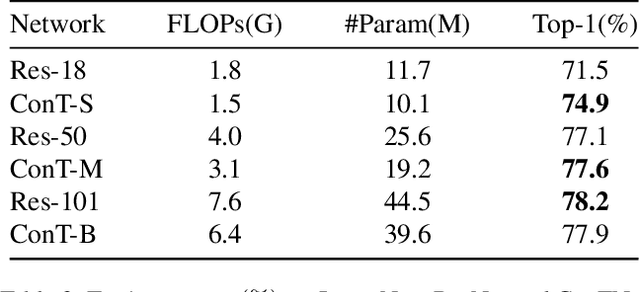
Although convolutional networks (ConvNets) have enjoyed great success in computer vision (CV), it suffers from capturing global information crucial to dense prediction tasks such as object detection and segmentation. In this work, we innovatively propose ConTNet (ConvolutionTransformer Network), combining transformer with ConvNet architectures to provide large receptive fields. Unlike the recently-proposed transformer-based models (e.g., ViT, DeiT) that are sensitive to hyper-parameters and extremely dependent on a pile of data augmentations when trained from scratch on a midsize dataset (e.g., ImageNet1k), ConTNet can be optimized like normal ConvNets (e.g., ResNet) and preserve an outstanding robustness. It is also worth pointing that, given identical strong data augmentations, the performance improvement of ConTNet is more remarkable than that of ResNet. We present its superiority and effectiveness on image classification and downstream tasks. For example, our ConTNet achieves 81.8% top-1 accuracy on ImageNet which is the same as DeiT-B with less than 40% computational complexity. ConTNet-M also outperforms ResNet50 as the backbone of both Faster-RCNN (by 2.6%) and Mask-RCNN (by 3.2%) on COCO2017 dataset. We hope that ConTNet could serve as a useful backbone for CV tasks and bring new ideas for model design
Improving Image Captioning by Leveraging Intra- and Inter-layer Global Representation in Transformer Network
Dec 13, 2020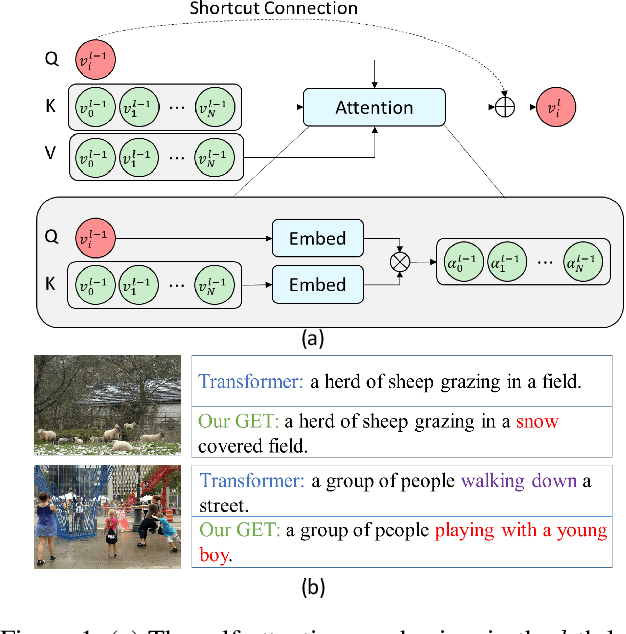
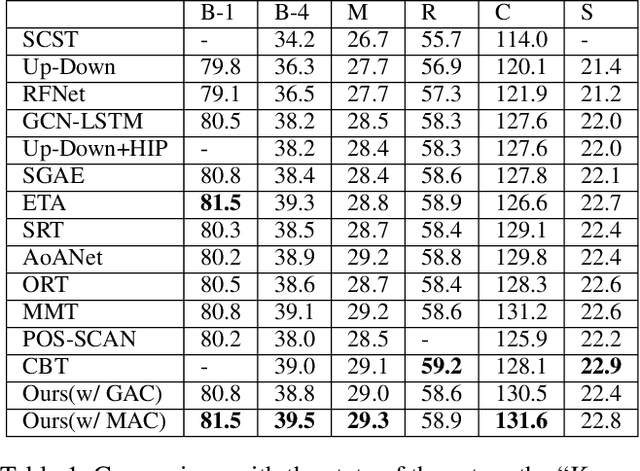
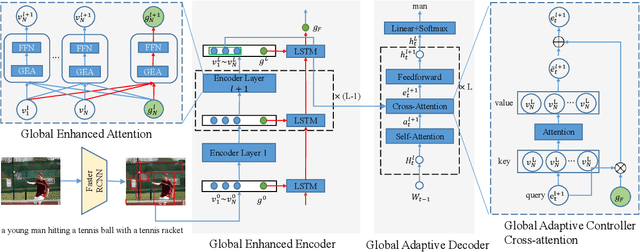
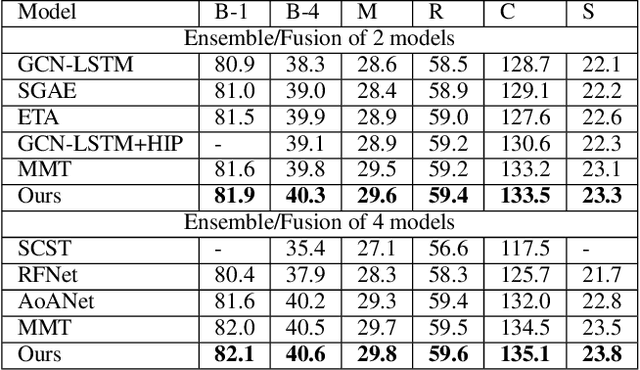
Transformer-based architectures have shown great success in image captioning, where object regions are encoded and then attended into the vectorial representations to guide the caption decoding. However, such vectorial representations only contain region-level information without considering the global information reflecting the entire image, which fails to expand the capability of complex multi-modal reasoning in image captioning. In this paper, we introduce a Global Enhanced Transformer (termed GET) to enable the extraction of a more comprehensive global representation, and then adaptively guide the decoder to generate high-quality captions. In GET, a Global Enhanced Encoder is designed for the embedding of the global feature, and a Global Adaptive Decoder are designed for the guidance of the caption generation. The former models intra- and inter-layer global representation by taking advantage of the proposed Global Enhanced Attention and a layer-wise fusion module. The latter contains a Global Adaptive Controller that can adaptively fuse the global information into the decoder to guide the caption generation. Extensive experiments on MS COCO dataset demonstrate the superiority of our GET over many state-of-the-arts.
Virtual Normal: Enforcing Geometric Constraints for Accurate and Robust Depth Prediction
Mar 09, 2021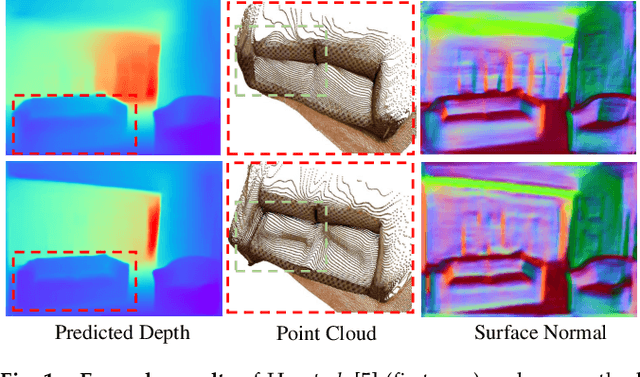
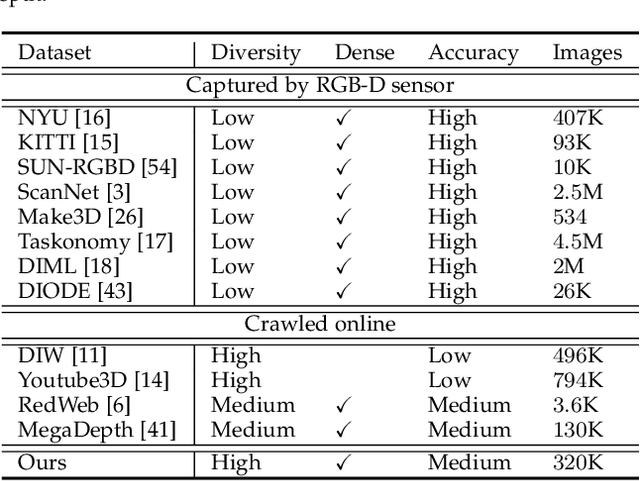
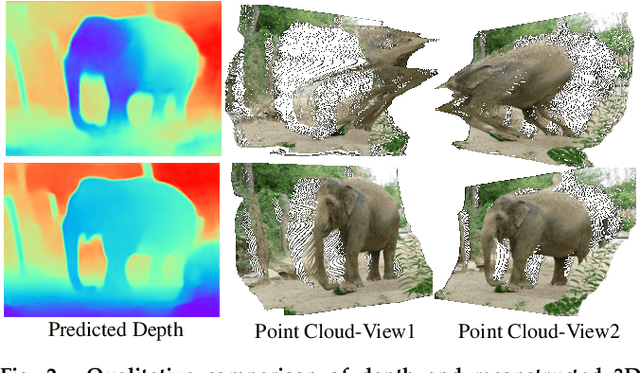
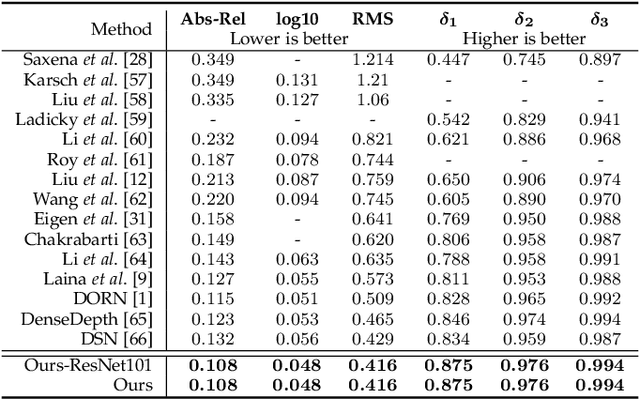
Monocular depth prediction plays a crucial role in understanding 3D scene geometry. Although recent methods have achieved impressive progress in terms of evaluation metrics such as the pixel-wise relative error, most methods neglect the geometric constraints in the 3D space. In this work, we show the importance of the high-order 3D geometric constraints for depth prediction. By designing a loss term that enforces a simple geometric constraint, namely, virtual normal directions determined by randomly sampled three points in the reconstructed 3D space, we significantly improve the accuracy and robustness of monocular depth estimation. Significantly, the virtual normal loss can not only improve the performance of learning metric depth, but also disentangle the scale information and enrich the model with better shape information. Therefore, when not having access to absolute metric depth training data, we can use virtual normal to learn a robust affine-invariant depth generated on diverse scenes. In experiments, We show state-of-the-art results of learning metric depth on NYU Depth-V2 and KITTI. From the high-quality predicted depth, we are now able to recover good 3D structures of the scene such as the point cloud and surface normal directly, eliminating the necessity of relying on additional models as was previously done. To demonstrate the excellent generalizability of learning affine-invariant depth on diverse data with the virtual normal loss, we construct a large-scale and diverse dataset for training affine-invariant depth, termed Diverse Scene Depth dataset (DiverseDepth), and test on five datasets with the zero-shot test setting. Code is available at: https://git.io/Depth
Path-based vs. Distributional Information in Recognizing Lexical Semantic Relations
Nov 02, 2016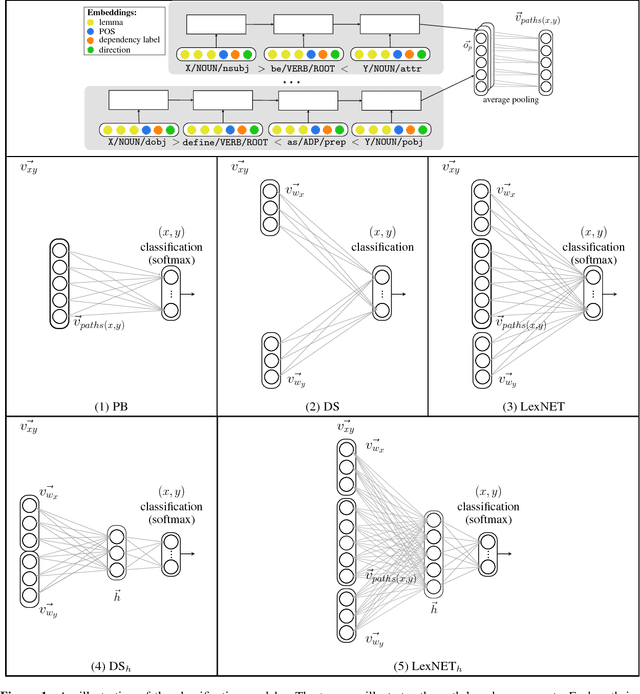


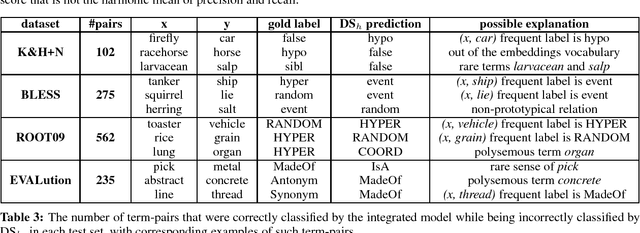
Recognizing various semantic relations between terms is beneficial for many NLP tasks. While path-based and distributional information sources are considered complementary for this task, the superior results the latter showed recently suggested that the former's contribution might have become obsolete. We follow the recent success of an integrated neural method for hypernymy detection (Shwartz et al., 2016) and extend it to recognize multiple relations. The empirical results show that this method is effective in the multiclass setting as well. We further show that the path-based information source always contributes to the classification, and analyze the cases in which it mostly complements the distributional information.
MG-GCN: Fast and Effective Learning with Mix-grained Aggregators for Training Large Graph Convolutional Networks
Nov 17, 2020
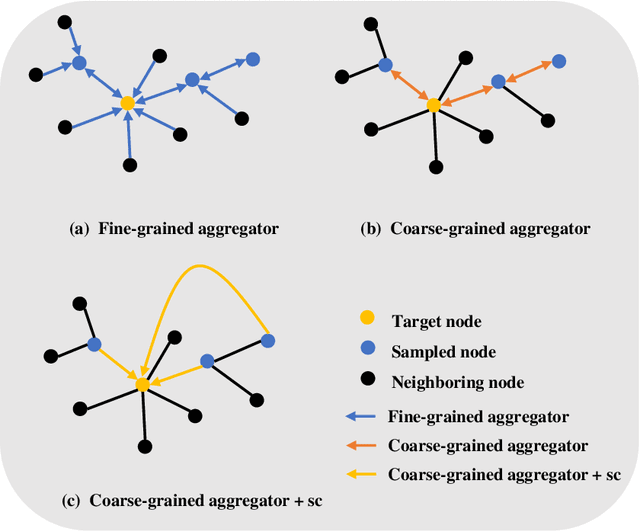
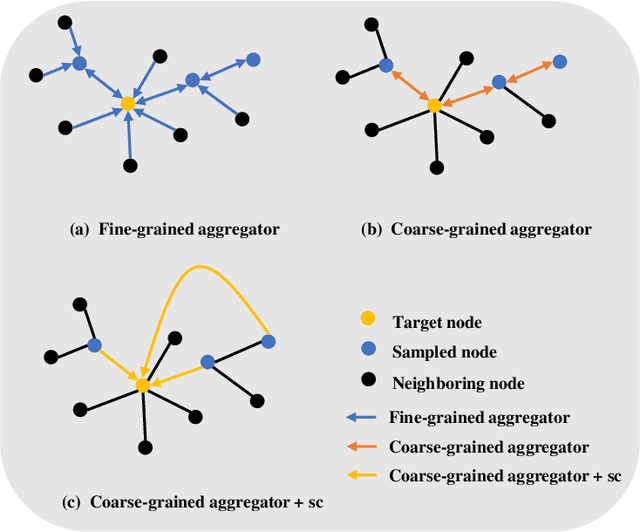
Graph convolutional networks (GCNs) have been employed as a kind of significant tool on many graph-based applications recently. Inspired by convolutional neural networks (CNNs), GCNs generate the embeddings of nodes by aggregating the information of their neighbors layer by layer. However, the high computational and memory cost of GCNs due to the recursive neighborhood expansion across GCN layers makes it infeasible for training on large graphs. To tackle this issue, several sampling methods during the process of information aggregation have been proposed to train GCNs in a mini-batch Stochastic Gradient Descent (SGD) manner. Nevertheless, these sampling strategies sometimes bring concerns about insufficient information collection, which may hinder the learning performance in terms of accuracy and convergence. To tackle the dilemma between accuracy and efficiency, we propose to use aggregators with different granularities to gather neighborhood information in different layers. Then, a degree-based sampling strategy, which avoids the exponential complexity, is constructed for sampling a fixed number of nodes. Combining the above two mechanisms, the proposed model, named Mix-grained GCN (MG-GCN) achieves state-of-the-art performance in terms of accuracy, training speed, convergence speed, and memory cost through a comprehensive set of experiments on four commonly used benchmark datasets and a new Ethereum dataset.
SpikE: spike-based embeddings for multi-relational graph data
Apr 27, 2021
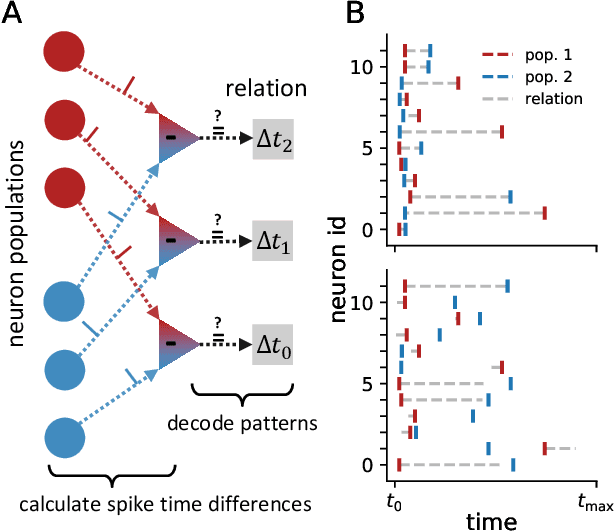
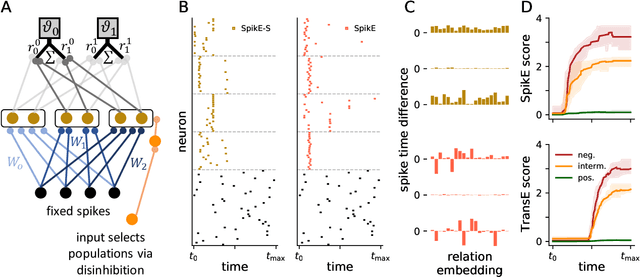
Despite the recent success of reconciling spike-based coding with the error backpropagation algorithm, spiking neural networks are still mostly applied to tasks stemming from sensory processing, operating on traditional data structures like visual or auditory data. A rich data representation that finds wide application in industry and research is the so-called knowledge graph - a graph-based structure where entities are depicted as nodes and relations between them as edges. Complex systems like molecules, social networks and industrial factory systems can be described using the common language of knowledge graphs, allowing the usage of graph embedding algorithms to make context-aware predictions in these information-packed environments. We propose a spike-based algorithm where nodes in a graph are represented by single spike times of neuron populations and relations as spike time differences between populations. Learning such spike-based embeddings only requires knowledge about spike times and spike time differences, compatible with recently proposed frameworks for training spiking neural networks. The presented model is easily mapped to current neuromorphic hardware systems and thereby moves inference on knowledge graphs into a domain where these architectures thrive, unlocking a promising industrial application area for this technology.
Online POMDP Planning via Simplification
May 11, 2021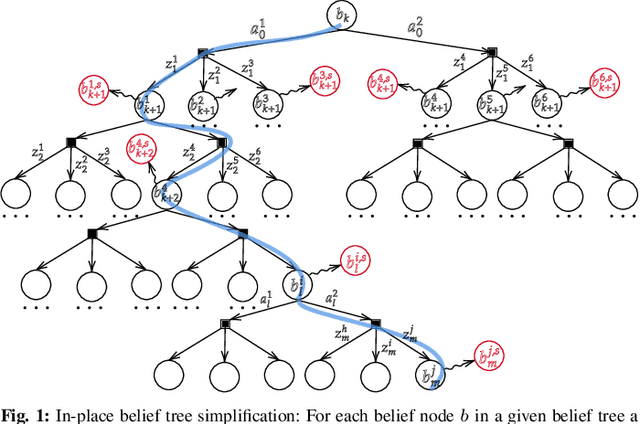
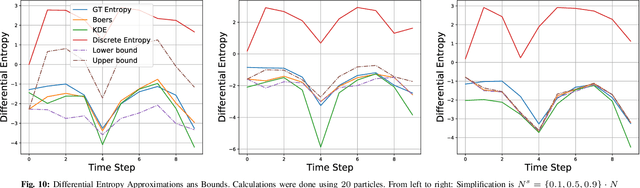

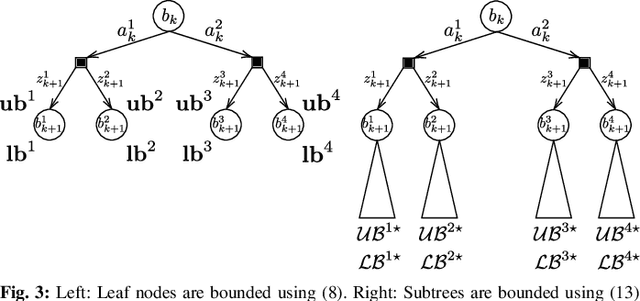
In this paper, we consider online planning in partially observable domains. Solving the corresponding POMDP problem is a very challenging task, particularly in an online setting. Our key contribution is a novel algorithmic approach, Simplified Information Theoretic Belief Space Planning (SITH-BSP), which aims to speed-up POMDP planning considering belief-dependent rewards, without compromising on the solution's accuracy. We do so by mathematically relating the simplified elements of the problem to the corresponding counterparts of the original problem. Specifically, we focus on belief simplification and use it to formulate bounds on the corresponding original belief-dependent rewards. These bounds in turn are used to perform branch pruning over the belief tree, in the process of calculating the optimal policy. We further introduce the notion of adaptive simplification, while re-using calculations between different simplification levels and exploit it to prune, at each level in the belief tree, all branches but one. Therefore, our approach is guaranteed to find the optimal solution of the original problem but with substantial speedup. As a second key contribution, we derive novel analytical bounds for differential entropy, considering a sampling-based belief representation, which we believe are of interest on their own. We validate our approach in simulation using these bounds and where simplification corresponds to reducing the number of samples, exhibiting a significant computational speedup while yielding the optimal solution.