 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
From the Periphery to the Center: Information Brokerage in an Evolving Network
May 02, 2018
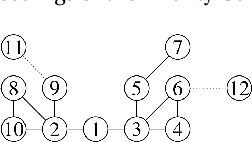
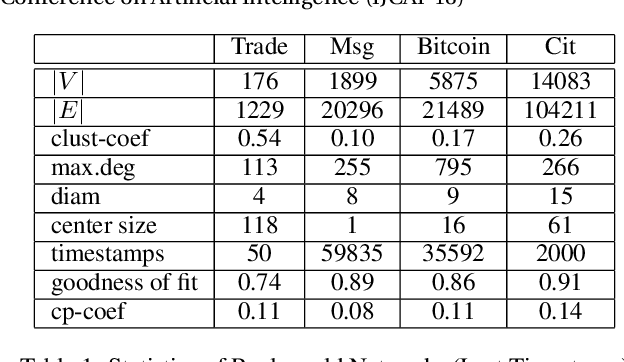
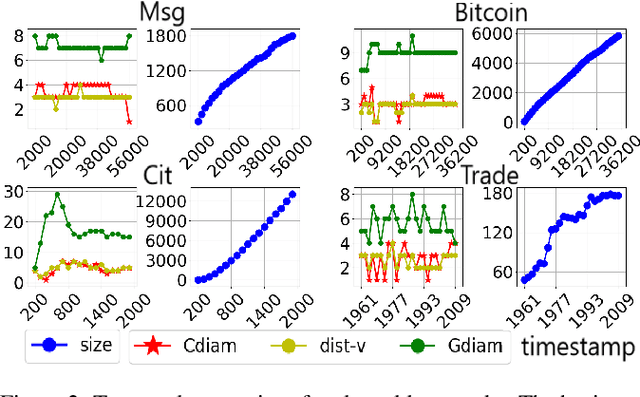
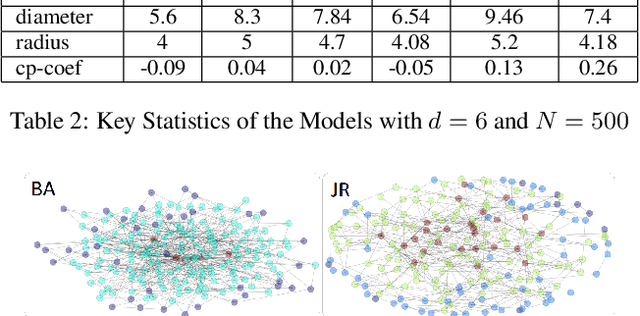
Interpersonal ties are pivotal to individual efficacy, status and performance in an agent society. This paper explores three important and interrelated themes in social network theory: the center/periphery partition of the network; network dynamics; and social integration of newcomers. We tackle the question: How would a newcomer harness information brokerage to integrate into a dynamic network going from periphery to center? We model integration as the interplay between the newcomer and the dynamics network and capture information brokerage using a process of relationship building. We analyze theoretical guarantees for the newcomer to reach the center through tactics; proving that a winning tactic always exists for certain types of network dynamics. We then propose three tactics and show their superior performance over alternative methods on four real-world datasets and four network models. In general, our tactics place the newcomer to the center by adding very few new edges on dynamic networks with approximately 14000 nodes.
Automated Timeline Length Selection for Flexible Timeline Summarization
May 29, 2021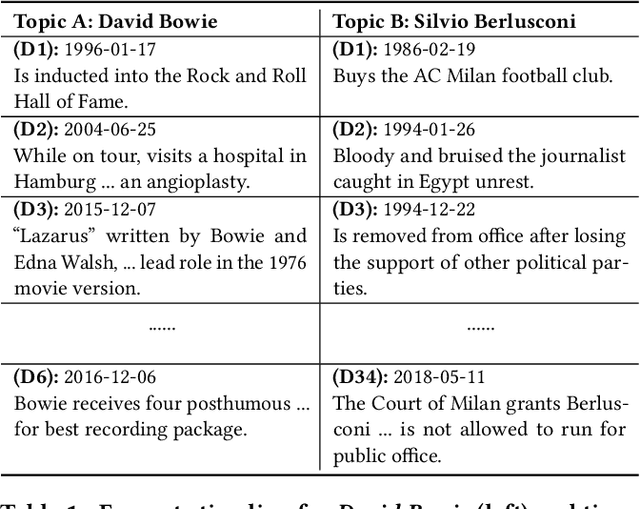
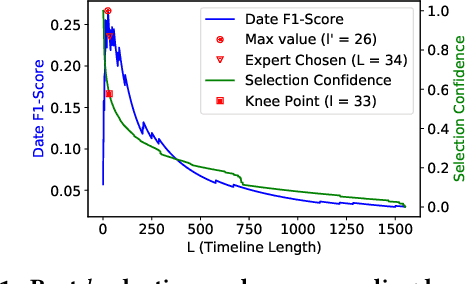
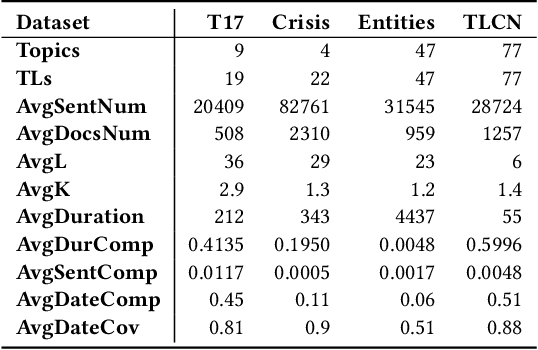
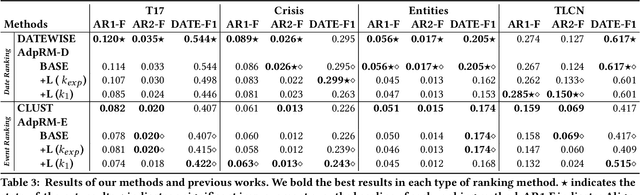
By producing summaries for long-running events, timeline summarization (TLS) underpins many information retrieval tasks. Successful TLS requires identifying an appropriate set of key dates (the timeline length) to cover. However, doing so is challenging as the right length can change from one topic to another. Existing TLS solutions either rely on an event-agnostic fixed length or an expert-supplied setting. Neither of the strategies is desired for real-life TLS scenarios. A fixed, event-agnostic setting ignores the diversity of events and their development and hence can lead to low-quality TLS. Relying on expert-crafted settings is neither scalable nor sustainable for processing many dynamically changing events. This paper presents a better TLS approach for automatically and dynamically determining the TLS timeline length. We achieve this by employing the established elbow method from the machine learning community to automatically find the minimum number of dates within the time series to generate concise and informative summaries. We applied our approach to four TLS datasets of English and Chinese and compared them against three prior methods. Experimental results show that our approach delivers comparable or even better summaries over state-of-art TLS methods, but it achieves this without expert involvement.
Yes-Net: An effective Detector Based on Global Information
Jun 30, 2017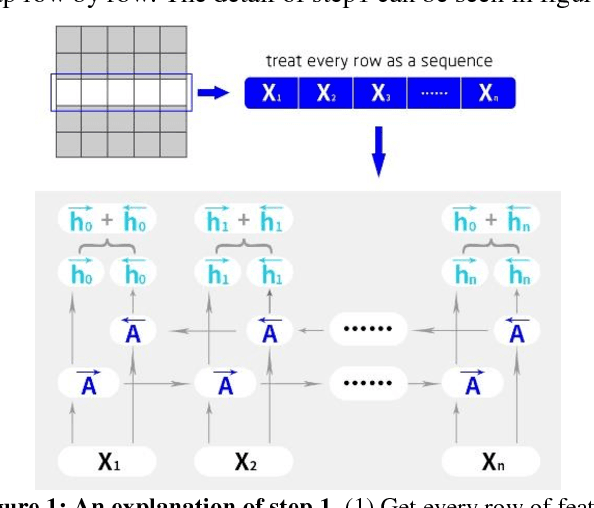
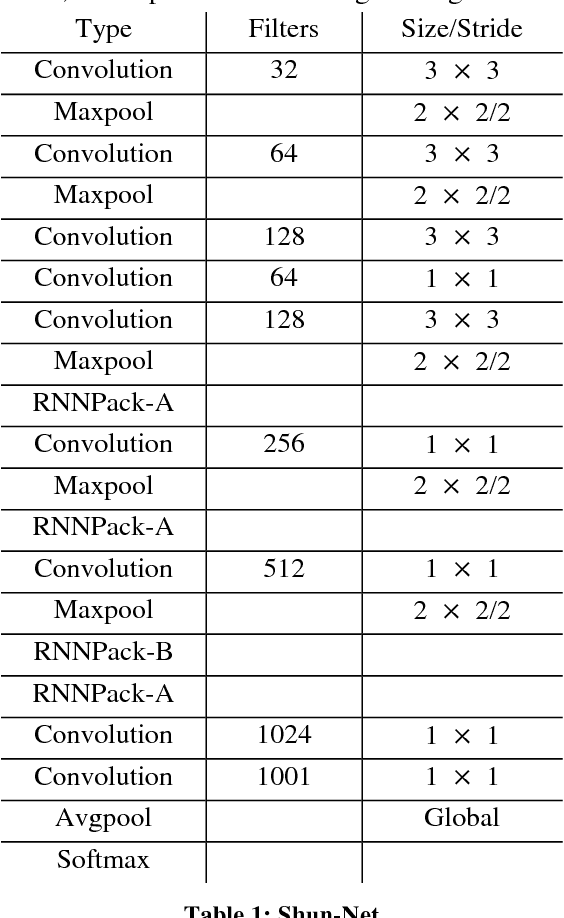
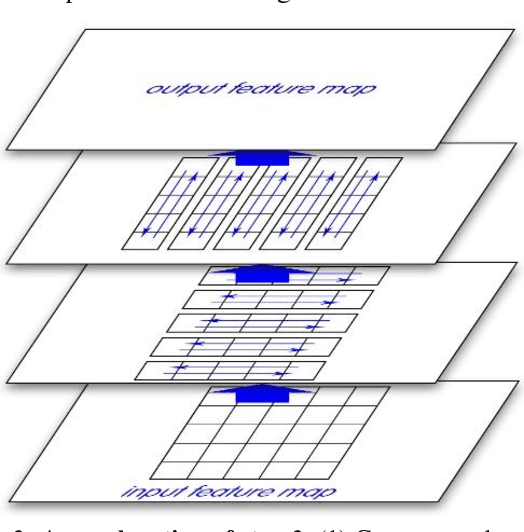
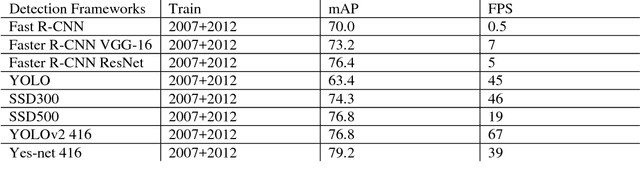
This paper introduces a new real-time object detection approach named Yes-Net. It realizes the prediction of bounding boxes and class via single neural network like YOLOv2 and SSD, but owns more efficient and outstanding features. It combines local information with global information by adding the RNN architecture as a packed unit in CNN model to form the basic feature extractor. Independent anchor boxes coming from full-dimension k-means is also applied in Yes-Net, it brings better average IOU than grid anchor box. In addition, instead of NMS, Yes-Net uses RNN as a filter to get the final boxes, which is more efficient. For 416 x 416 input, Yes-Net achieves 79.2% mAP on VOC2007 test at 39 FPS on an Nvidia Titan X Pascal.
Information-Theoretic Representation Learning for Positive-Unlabeled Classification
Feb 12, 2018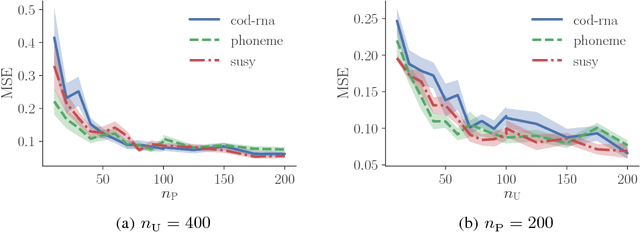
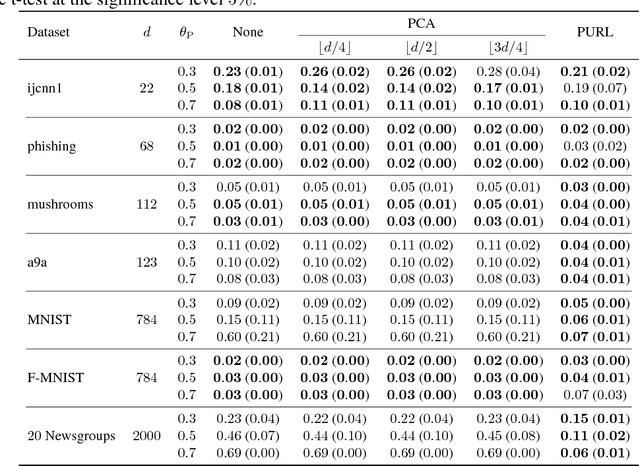
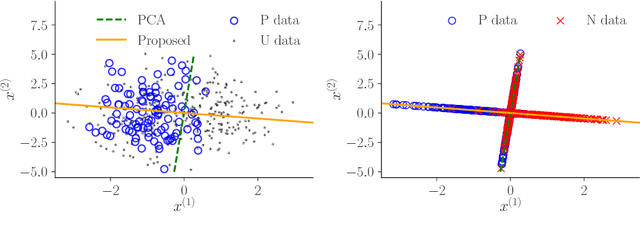
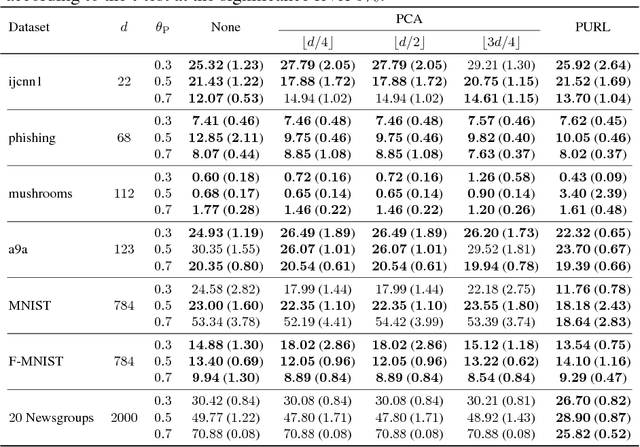
Recent advances in weakly supervised classification allow us to train a classifier only from positive and unlabeled (PU) data. However, existing PU classification methods typically require an accurate estimate of the class-prior probability, which is a critical bottleneck particularly for high-dimensional data. This problem has been commonly addressed by applying principal component analysis in advance, but such unsupervised dimension reduction can collapse underlying class structure. In this paper, we propose a novel representation learning method from PU data based on the information-maximization principle. Our method does not require class-prior estimation and thus can be used as a preprocessing method for PU classification. Through experiments, we demonstrate that our method combined with deep neural networks highly improves the accuracy of PU class-prior estimation, leading to state-of-the-art PU classification performance.
Physical-Layer Security via Distributed Beamforming in the Presence of Adversaries with Unknown Locations
Feb 28, 2021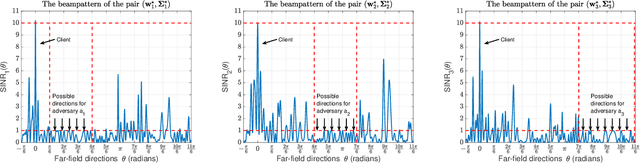
We study the problem of securely communicating a sequence of information bits with a client in the presence of multiple adversaries at unknown locations in the environment. We assume that the client and the adversaries are located in the far-field region, and all possible directions for each adversary can be expressed as a continuous interval of directions. In such a setting, we develop a periodic transmission strategy, i.e., a sequence of joint beamforming gain and artificial noise pairs, that prevents the adversaries from decreasing their uncertainty on the information sequence by eavesdropping on the transmission. We formulate a series of nonconvex semi-infinite optimization problems to synthesize the transmission strategy. We show that the semi-definite program (SDP) relaxations of these nonconvex problems are exact under an efficiently verifiable sufficient condition. We approximate the SDP relaxations, which are subject to infinitely many constraints, by randomly sampling a finite subset of the constraints and establish the probability with which optimal solutions to the obtained finite SDPs and the semi-infinite SDPs coincide. We demonstrate with numerical simulations that the proposed periodic strategy can ensure the security of communication in scenarios in which all stationary strategies fail to guarantee security.
STOPPAGE: Spatio-temporal Data Driven Cloud-Fog-Edge Computing Framework for Pandemic Monitoring and Management
Apr 04, 2021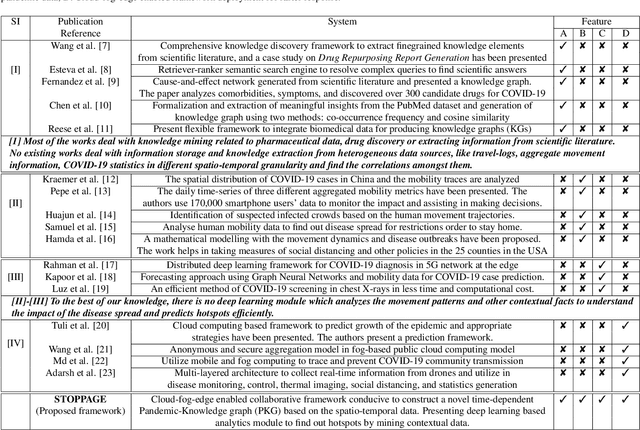
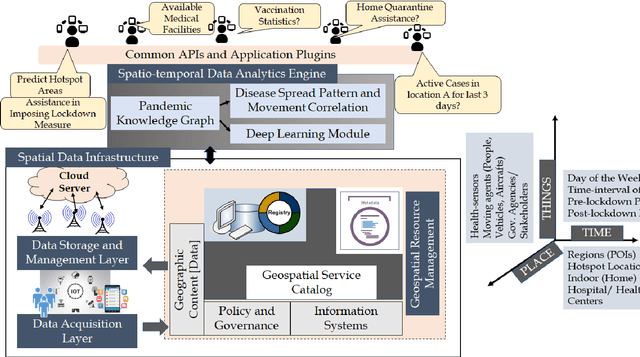
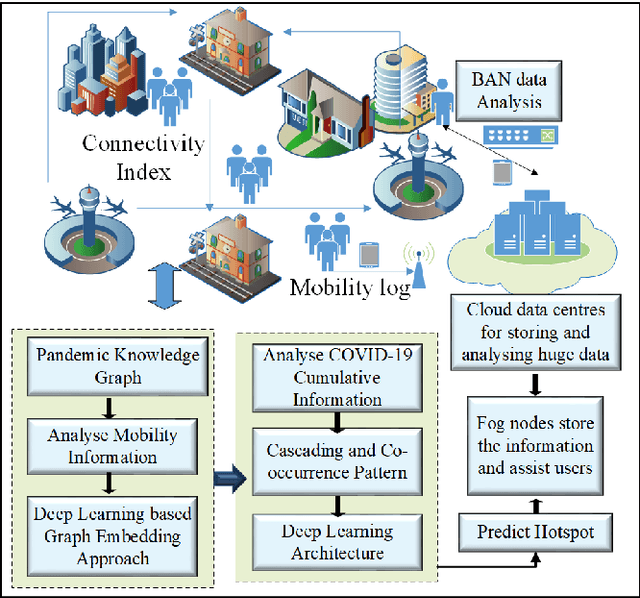
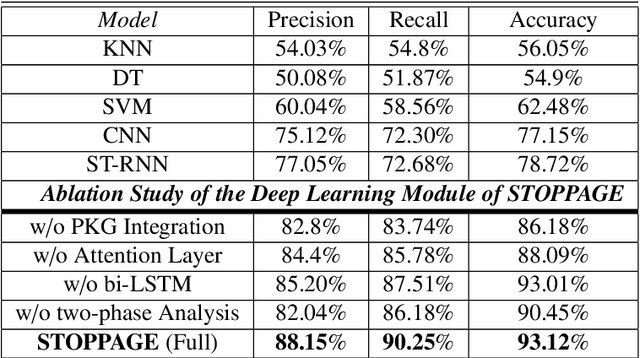
Several researches and evidence show the increasing likelihood of pandemics (large-scale outbreaks of infectious disease) which has far reaching sequels in all aspects of human lives ranging from rapid mortality rates to economic and social disruption across the world. In the recent time, COVID-19 (Coronavirus Disease 2019) pandemic disrupted normal human lives, and motivated by the urgent need of combating COVID-19, researchers have put significant efforts in modelling and analysing the disease spread patterns for effective preventive measures (in addition to developing pharmaceutical solutions, like vaccine). In this regards, it is absolutely necessary to develop an analytics framework by extracting and incorporating the knowledge of heterogeneous datasources to deliver insights in improving administrative policy and enhance the preparedness to combat the pandemic. Specifically, human mobility, travel history and other transport statistics have significant impacts on the spread of any infectious disease. In this direction, this paper proposes a spatio-temporal knowledge mining framework, named STOPPAGE to model the impact of human mobility and other contextual information over large geographic area in different temporal scales. The framework has two major modules: (i) Spatio-temporal data and computing infrastructure using fog/edge based architecture; and (ii) Spatio-temporal data analytics module to efficiently extract knowledge from heterogeneous data sources. Typically, we develop a Pandemic-knowledge graph to discover correlations among mobility information and disease spread, a deep learning architecture to predict the next hot-spot zones; and provide necessary support in home-health monitoring utilizing Femtolet and fog/edge based solutions. The experimental evaluations on real-life datasets related to COVID-19 in India illustrate the efficacy of the proposed methods.
SemEval-2021 Task 11: NLPContributionGraph -- Structuring Scholarly NLP Contributions for a Research Knowledge Graph
Jun 10, 2021

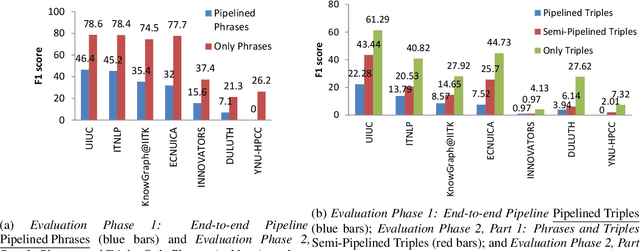

There is currently a gap between the natural language expression of scholarly publications and their structured semantic content modeling to enable intelligent content search. With the volume of research growing exponentially every year, a search feature operating over semantically structured content is compelling. The SemEval-2021 Shared Task NLPContributionGraph (a.k.a. 'the NCG task') tasks participants to develop automated systems that structure contributions from NLP scholarly articles in the English language. Being the first-of-its-kind in the SemEval series, the task released structured data from NLP scholarly articles at three levels of information granularity, i.e. at sentence-level, phrase-level, and phrases organized as triples toward Knowledge Graph (KG) building. The sentence-level annotations comprised the few sentences about the article's contribution. The phrase-level annotations were scientific term and predicate phrases from the contribution sentences. Finally, the triples constituted the research overview KG. For the Shared Task, participating systems were then expected to automatically classify contribution sentences, extract scientific terms and relations from the sentences, and organize them as KG triples. Overall, the task drew a strong participation demographic of seven teams and 27 participants. The best end-to-end task system classified contribution sentences at 57.27% F1, phrases at 46.41% F1, and triples at 22.28% F1. While the absolute performance to generate triples remains low, in the conclusion of this article, the difficulty of producing such data and as a consequence of modeling it is highlighted.
Multi-feature driven active contour segmentation model for infrared image with intensity inhomogeneity
Nov 25, 2020Infrared (IR) image segmentation is essential in many urban defence applications, such as pedestrian surveillance, vehicle counting, security monitoring, etc. Active contour model (ACM) is one of the most widely used image segmentation tools at present, but the existing methods only utilize the local or global single feature information of image to minimize the energy function, which is easy to cause false segmentations in IR images. In this paper, we propose a multi-feature driven active contour segmentation model to handle IR images with intensity inhomogeneity. Firstly, an especially-designed signed pressure force (SPF) function is constructed by combining the global information calculated by global average gray information and the local multi-feature information calculated by local entropy, local standard deviation and gradient information. Then, we draw upon adaptive weight coefficient calculated by local range to adjust the afore-mentioned global term and local term. Next, the SPF function is substituted into the level set formulation (LSF) for further evolution. Finally, the LSF converges after a finite number of iterations, and the IR image segmentation result is obtained from the corresponding convergence result. Experimental results demonstrate that the presented method outperforms the state-of-the-art models in terms of precision rate and overlapping rate in IR test images.
Marginal Utility Diminishes: Exploring the Minimum Knowledge for BERT Knowledge Distillation
Jun 10, 2021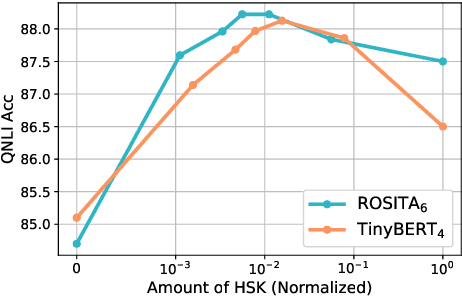

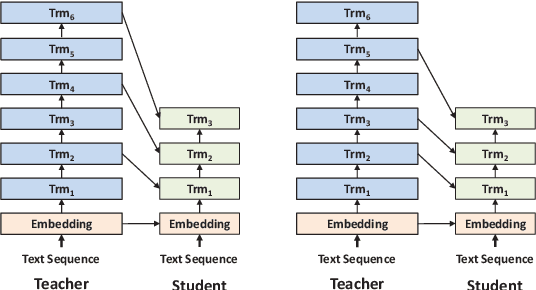
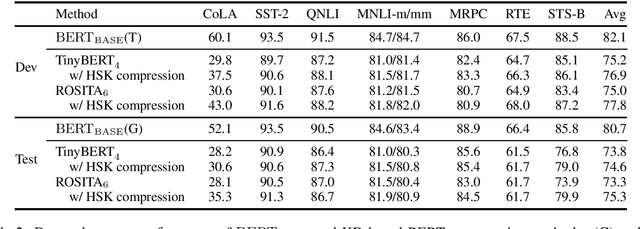
Recently, knowledge distillation (KD) has shown great success in BERT compression. Instead of only learning from the teacher's soft label as in conventional KD, researchers find that the rich information contained in the hidden layers of BERT is conducive to the student's performance. To better exploit the hidden knowledge, a common practice is to force the student to deeply mimic the teacher's hidden states of all the tokens in a layer-wise manner. In this paper, however, we observe that although distilling the teacher's hidden state knowledge (HSK) is helpful, the performance gain (marginal utility) diminishes quickly as more HSK is distilled. To understand this effect, we conduct a series of analysis. Specifically, we divide the HSK of BERT into three dimensions, namely depth, length and width. We first investigate a variety of strategies to extract crucial knowledge for each single dimension and then jointly compress the three dimensions. In this way, we show that 1) the student's performance can be improved by extracting and distilling the crucial HSK, and 2) using a tiny fraction of HSK can achieve the same performance as extensive HSK distillation. Based on the second finding, we further propose an efficient KD paradigm to compress BERT, which does not require loading the teacher during the training of student. For two kinds of student models and computing devices, the proposed KD paradigm gives rise to training speedup of 2.7x ~ 3.4x.
On Deep Learning with Label Differential Privacy
Feb 11, 2021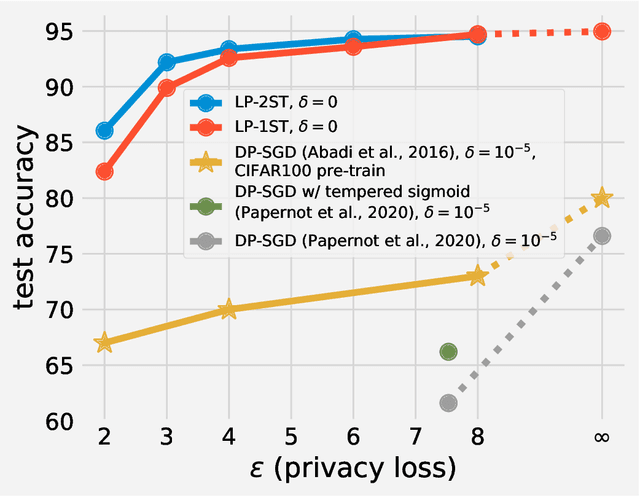
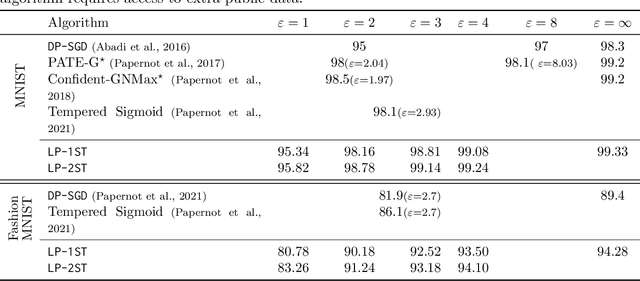

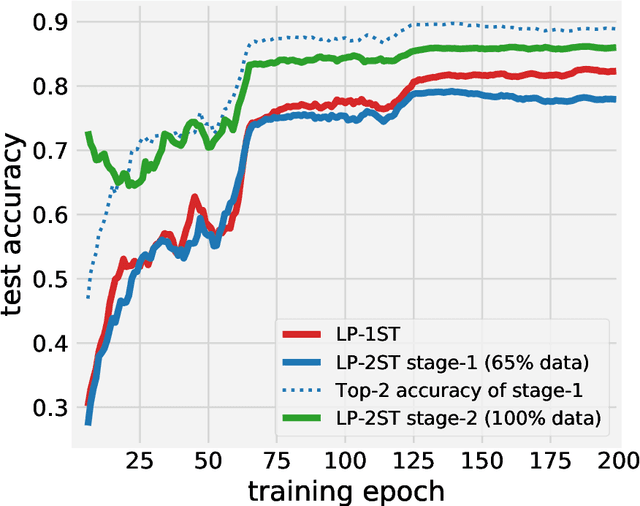
In many machine learning applications, the training data can contain highly sensitive personal information. Training large-scale deep models that are guaranteed not to leak sensitive information while not compromising their accuracy has been a significant challenge. In this work, we study the multi-class classification setting where the labels are considered sensitive and ought to be protected. We propose a new algorithm for training deep neural networks with label differential privacy, and run evaluations on several datasets. For Fashion MNIST and CIFAR-10, we demonstrate that our algorithm achieves significantly higher accuracy than the state-of-the-art, and in some regimes comes close to the non-private baselines. We also provide non-trivial training results for the the challenging CIFAR-100 dataset. We complement our algorithm with theoretical findings showing that in the setting of convex empirical risk minimization, the sample complexity of training with label differential privacy is dimension-independent, which is in contrast to vanilla differential privacy.