 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge$R_\text{dm}$: Re-conceptualizing Distribution Matching as a Reward for Diffusion Distillation
Mar 31, 2026Diffusion models achieve state-of-the-art generative performance but are fundamentally bottlenecked by their slow, iterative sampling process. While diffusion distillation techniques enable high-fidelity, few-step generation, traditional objectives often restrict the student's performance by anchoring it solely to the teacher. Recent approaches have attempted to break this ceiling by integrating Reinforcement Learning (RL), typically through a simple summation of distillation and RL objectives. In this work, we propose a novel paradigm by re-conceptualizing distribution matching as a reward, denoted as $R_\text{dm}$. This unified perspective bridges the algorithmic gap between Diffusion Matching Distillation (DMD) and RL, providing several primary benefits. (1) Enhanced Optimization Stability: We introduce Group Normalized Distribution Matching (GNDM), which adapts standard RL group normalization to stabilize $R_\text{dm}$ estimation. By leveraging group-mean statistics, GNDM establishes a more robust and effective optimization direction. (2) Seamless Reward Integration: Our reward-centric formulation inherently supports adaptive weighting mechanisms, allowing for the fluid combination of DMD with external reward models. (3) Improved Sampling Efficiency: By aligning with RL principles, the framework readily incorporates Importance Sampling (IS), leading to a significant boost in sampling efficiency. Extensive experiments demonstrate that GNDM outperforms vanilla DMD, reducing the FID by 1.87. Furthermore, our multi-reward variant, GNDMR, surpasses existing baselines by striking an optimal balance between aesthetic quality and fidelity, achieving a peak HPS of 30.37 and a low FID-SD of 12.21. Ultimately, $R_\text{dm}$ provides a flexible, stable, and efficient framework for real-time, high-fidelity synthesis. Codes are coming soon.
Kling-MotionControl Technical Report
Mar 03, 2026Character animation aims to generate lifelike videos by transferring motion dynamics from a driving video to a reference image. Recent strides in generative models have paved the way for high-fidelity character animation. In this work, we present Kling-MotionControl, a unified DiT-based framework engineered specifically for robust, precise, and expressive holistic character animation. Leveraging a divide-and-conquer strategy within a cohesive system, the model orchestrates heterogeneous motion representations tailored to the distinct characteristics of body, face, and hands, effectively reconciling large-scale structural stability with fine-grained articulatory expressiveness. To ensure robust cross-identity generalization, we incorporate adaptive identity-agnostic learning, facilitating natural motion retargeting for diverse characters ranging from realistic humans to stylized cartoons. Simultaneously, we guarantee faithful appearance preservation through meticulous identity injection and fusion designs, further supported by a subject library mechanism that leverages comprehensive reference contexts. To ensure practical utility, we implement an advanced acceleration framework utilizing multi-stage distillation, boosting inference speed by over 10x. Kling-MotionControl distinguishes itself through intelligent semantic motion understanding and precise text responsiveness, allowing for flexible control beyond visual inputs. Human preference evaluations demonstrate that Kling-MotionControl delivers superior performance compared to leading commercial and open-source solutions, achieving exceptional fidelity in holistic motion control, open domain generalization, and visual quality and coherence. These results establish Kling-MotionControl as a robust solution for high-quality, controllable, and lifelike character animation.
Kling-Omni Technical Report
Dec 18, 2025



We present Kling-Omni, a generalist generative framework designed to synthesize high-fidelity videos directly from multimodal visual language inputs. Adopting an end-to-end perspective, Kling-Omni bridges the functional separation among diverse video generation, editing, and intelligent reasoning tasks, integrating them into a holistic system. Unlike disjointed pipeline approaches, Kling-Omni supports a diverse range of user inputs, including text instructions, reference images, and video contexts, processing them into a unified multimodal representation to deliver cinematic-quality and highly-intelligent video content creation. To support these capabilities, we constructed a comprehensive data system that serves as the foundation for multimodal video creation. The framework is further empowered by efficient large-scale pre-training strategies and infrastructure optimizations for inference. Comprehensive evaluations reveal that Kling-Omni demonstrates exceptional capabilities in in-context generation, reasoning-based editing, and multimodal instruction following. Moving beyond a content creation tool, we believe Kling-Omni is a pivotal advancement toward multimodal world simulators capable of perceiving, reasoning, generating and interacting with the dynamic and complex worlds.
KlingAvatar 2.0 Technical Report
Dec 15, 2025Avatar video generation models have achieved remarkable progress in recent years. However, prior work exhibits limited efficiency in generating long-duration high-resolution videos, suffering from temporal drifting, quality degradation, and weak prompt following as video length increases. To address these challenges, we propose KlingAvatar 2.0, a spatio-temporal cascade framework that performs upscaling in both spatial resolution and temporal dimension. The framework first generates low-resolution blueprint video keyframes that capture global semantics and motion, and then refines them into high-resolution, temporally coherent sub-clips using a first-last frame strategy, while retaining smooth temporal transitions in long-form videos. To enhance cross-modal instruction fusion and alignment in extended videos, we introduce a Co-Reasoning Director composed of three modality-specific large language model (LLM) experts. These experts reason about modality priorities and infer underlying user intent, converting inputs into detailed storylines through multi-turn dialogue. A Negative Director further refines negative prompts to improve instruction alignment. Building on these components, we extend the framework to support ID-specific multi-character control. Extensive experiments demonstrate that our model effectively addresses the challenges of efficient, multimodally aligned long-form high-resolution video generation, delivering enhanced visual clarity, realistic lip-teeth rendering with accurate lip synchronization, strong identity preservation, and coherent multimodal instruction following.
Three Guidelines You Should Know for Universally Slimmable Self-Supervised Learning
Mar 13, 2023



We propose universally slimmable self-supervised learning (dubbed as US3L) to achieve better accuracy-efficiency trade-offs for deploying self-supervised models across different devices. We observe that direct adaptation of self-supervised learning (SSL) to universally slimmable networks misbehaves as the training process frequently collapses. We then discover that temporal consistent guidance is the key to the success of SSL for universally slimmable networks, and we propose three guidelines for the loss design to ensure this temporal consistency from a unified gradient perspective. Moreover, we propose dynamic sampling and group regularization strategies to simultaneously improve training efficiency and accuracy. Our US3L method has been empirically validated on both convolutional neural networks and vision transformers. With only once training and one copy of weights, our method outperforms various state-of-the-art methods (individually trained or not) on benchmarks including recognition, object detection and instance segmentation. Our code is available at https://github.com/megvii-research/US3L-CVPR2023.
Synergistic Self-supervised and Quantization Learning
Jul 12, 2022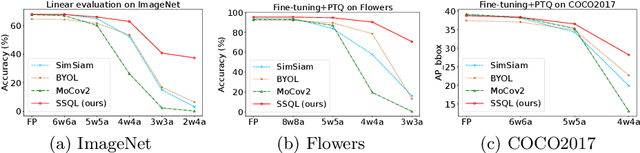
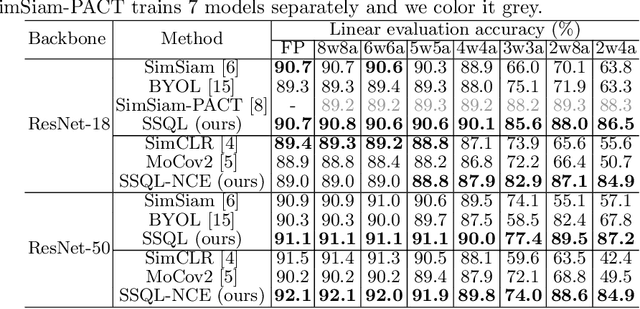
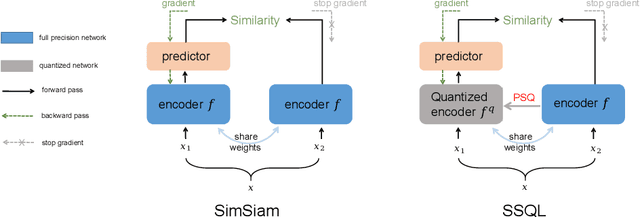
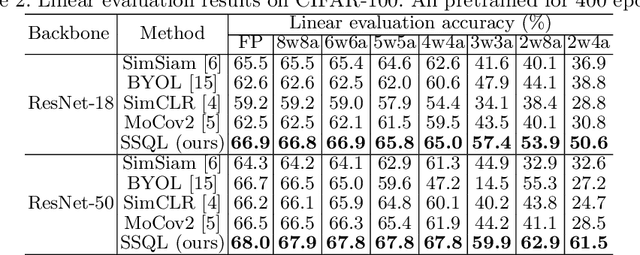
With the success of self-supervised learning (SSL), it has become a mainstream paradigm to fine-tune from self-supervised pretrained models to boost the performance on downstream tasks. However, we find that current SSL models suffer severe accuracy drops when performing low-bit quantization, prohibiting their deployment in resource-constrained applications. In this paper, we propose a method called synergistic self-supervised and quantization learning (SSQL) to pretrain quantization-friendly self-supervised models facilitating downstream deployment. SSQL contrasts the features of the quantized and full precision models in a self-supervised fashion, where the bit-width for the quantized model is randomly selected in each step. SSQL not only significantly improves the accuracy when quantized to lower bit-widths, but also boosts the accuracy of full precision models in most cases. By only training once, SSQL can then benefit various downstream tasks at different bit-widths simultaneously. Moreover, the bit-width flexibility is achieved without additional storage overhead, requiring only one copy of weights during training and inference. We theoretically analyze the optimization process of SSQL, and conduct exhaustive experiments on various benchmarks to further demonstrate the effectiveness of our method. Our code is available at https://github.com/megvii-research/SSQL-ECCV2022.
FQ-ViT: Fully Quantized Vision Transformer without Retraining
Nov 27, 2021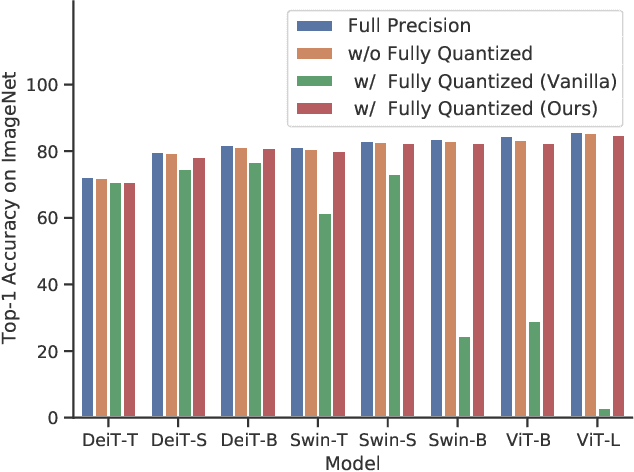

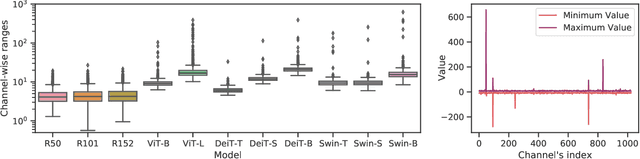
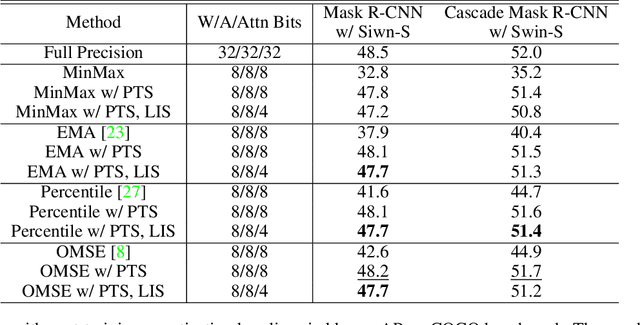
Network quantization significantly reduces model inference complexity and has been widely used in real-world deployments. However, most existing quantization methods have been developed and tested mainly on Convolutional Neural Networks (CNN), and suffer severe degradation when applied to Transformer-based architectures. In this work, we present a systematic method to reduce the performance degradation and inference complexity of Quantized Transformers. In particular, we propose Powers-of-Two Scale (PTS) to deal with the serious inter-channel variation of LayerNorm inputs in a hardware-friendly way. In addition, we propose Log-Int-Softmax (LIS) that can sustain the extreme non-uniform distribution of the attention maps while simplifying inference by using 4-bit quantization and the BitShift operator. Comprehensive experiments on various Transformer-based architectures and benchmarks show that our methods outperform previous works in performance while using even lower bit-width in attention maps. For instance, we reach 85.17% Top-1 accuracy with ViT-L on ImageNet and 51.4 mAP with Cascade Mask R-CNN (Swin-S) on COCO. To our knowledge, we are the first to achieve comparable accuracy degradation (~1%) on fully quantized Vision Transformers. Code is available at https://github.com/linyang-zhh/FQ-ViT.
Optimal Quantization for Batch Normalization in Neural Network Deployments and Beyond
Aug 30, 2020

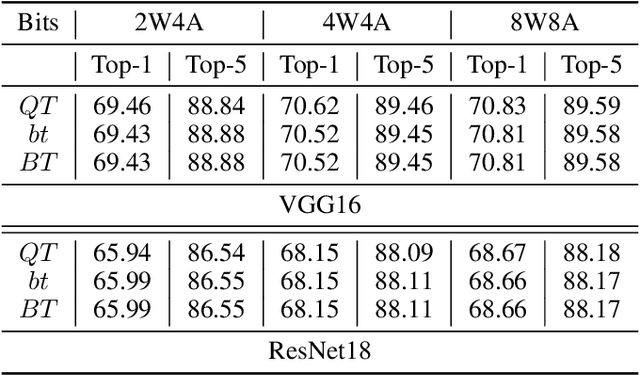
Quantized Neural Networks (QNNs) use low bit-width fixed-point numbers for representing weight parameters and activations, and are often used in real-world applications due to their saving of computation resources and reproducibility of results. Batch Normalization (BN) poses a challenge for QNNs for requiring floating points in reciprocal operations, and previous QNNs either require computing BN at high precision or revise BN to some variants in heuristic ways. In this work, we propose a novel method to quantize BN by converting an affine transformation of two floating points to a fixed-point operation with shared quantized scale, which is friendly for hardware acceleration and model deployment. We confirm that our method maintains same outputs through rigorous theoretical analysis and numerical analysis. Accuracy and efficiency of our quantization method are verified by experiments at layer level on CIFAR and ImageNet datasets. We also believe that our method is potentially useful in other problems involving quantization.
Yes-Net: An effective Detector Based on Global Information
Jun 30, 2017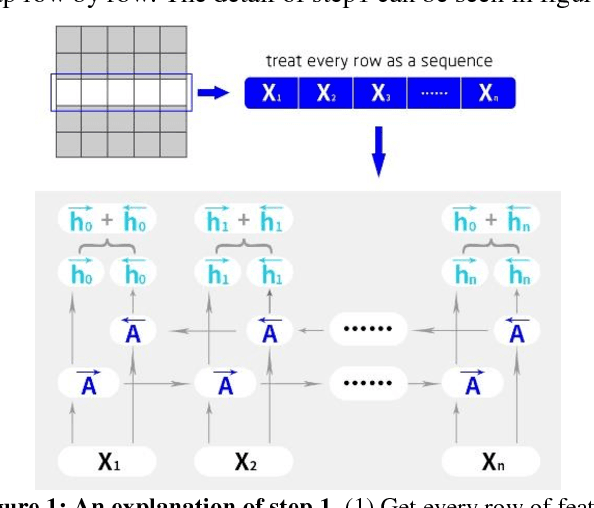
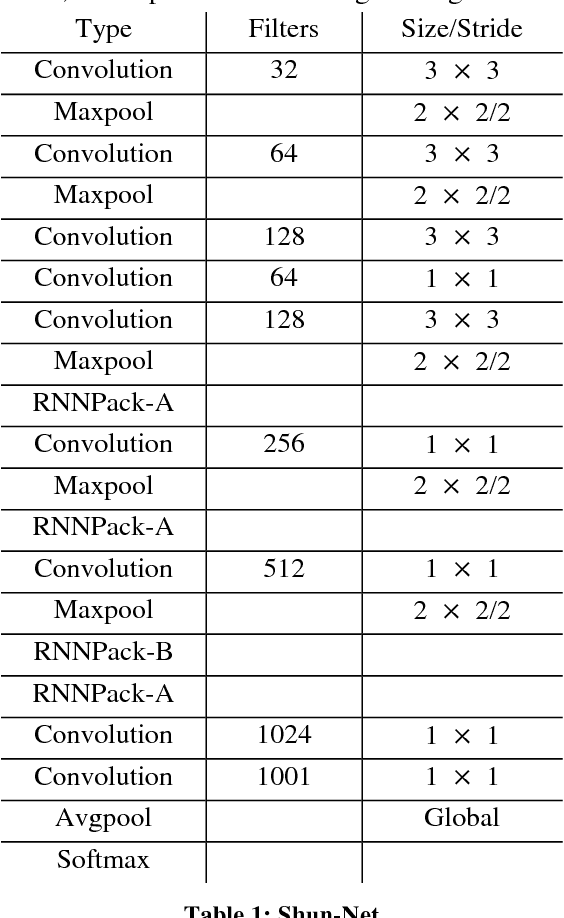
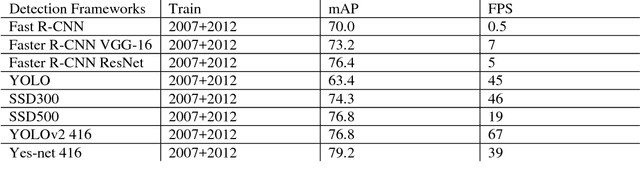
This paper introduces a new real-time object detection approach named Yes-Net. It realizes the prediction of bounding boxes and class via single neural network like YOLOv2 and SSD, but owns more efficient and outstanding features. It combines local information with global information by adding the RNN architecture as a packed unit in CNN model to form the basic feature extractor. Independent anchor boxes coming from full-dimension k-means is also applied in Yes-Net, it brings better average IOU than grid anchor box. In addition, instead of NMS, Yes-Net uses RNN as a filter to get the final boxes, which is more efficient. For 416 x 416 input, Yes-Net achieves 79.2% mAP on VOC2007 test at 39 FPS on an Nvidia Titan X Pascal.