 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
A Novel Wireless Communication Paradigm for Intelligent Reflecting Surface Based Symbiotic Radio Systems
Apr 19, 2021
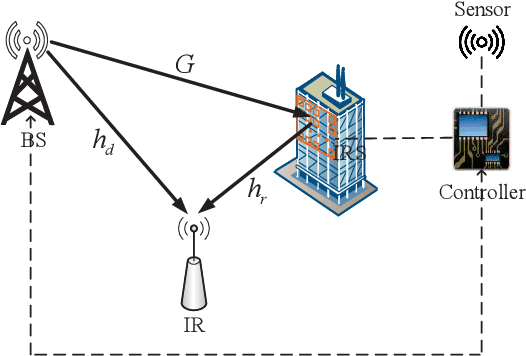
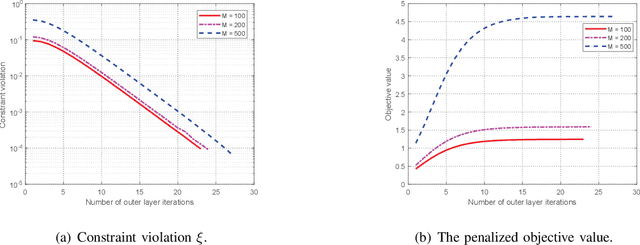
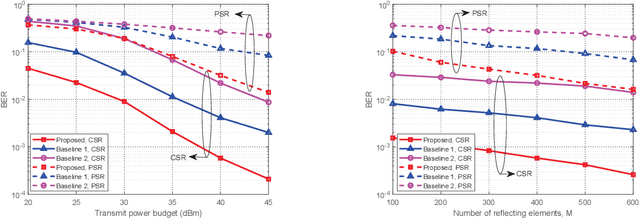
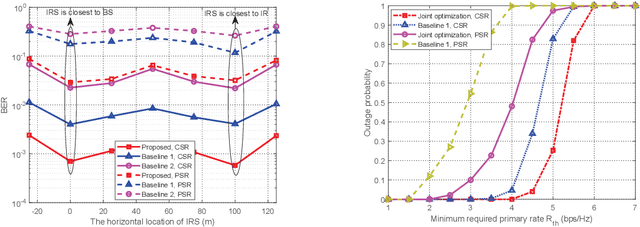
This paper investigates a novel intelligent reflecting surface (IRS)-based symbiotic radio (SR) system architecture consisting of a transmitter, an IRS, and an information receiver (IR). The primary transmitter communicates with the IR and at the same time assists the IRS in forwarding information to the IR. Based on the IRS's symbol period, we distinguish two scenarios, namely, commensal SR (CSR) and parasitic SR (PSR), where two different techniques for decoding the IRS signals at the IR are employed. We formulate bit error rate (BER) minimization problems for both scenarios by jointly optimizing the active beamformer at the base station and the phase shifts at the IRS, subject to a minimum primary rate requirement. Specifically, for the CSR scenario, a penalty-based algorithm is proposed to obtain a high-quality solution, where semi-closed-form solutions for the active beamformer and the IRS phase shifts are derived based on Lagrange duality and Majorization-Minimization methods, respectively. For the PSR scenario, we apply a bisection search-based method, successive convex approximation, and difference of convex programming to develop a computationally efficient algorithm, which converges to a locally optimal solution. Simulation results demonstrate the effectiveness of the proposed algorithms and show that the proposed SR techniques are able to achieve a lower BER than benchmark schemes.
Non-Stochastic Multi-Player Multi-Armed Bandits: Optimal Rate With Collision Information, Sublinear Without
May 01, 2019We consider the non-stochastic version of the (cooperative) multi-player multi-armed bandit problem. The model assumes no communication at all between the players, and furthermore when two (or more) players select the same action this results in a maximal loss. We prove the first $\sqrt{T}$-type regret guarantee for this problem, under the feedback model where collisions are announced to the colliding players. Such a bound was not known even for the simpler stochastic version. We also prove the first sublinear guarantee for the feedback model where collision information is not available, namely $T^{1-\frac{1}{2m}}$ where $m$ is the number of players.
Modelling the Influence of Cultural Information on Vision-Based Human Home Activity Recognition
Mar 21, 2018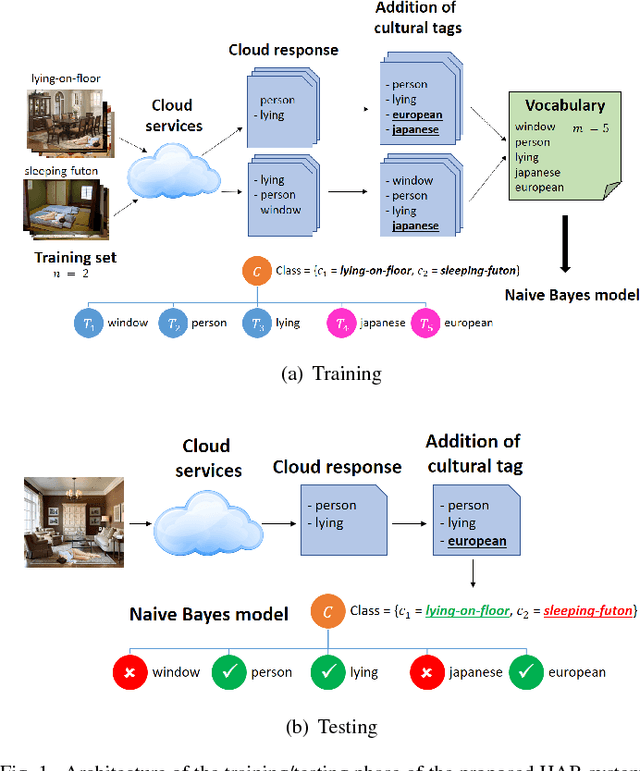
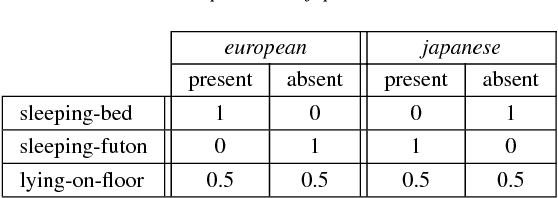

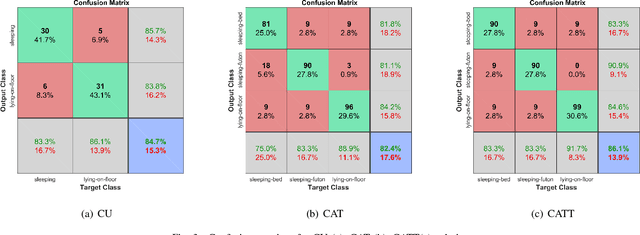
Daily life activities, such as eating and sleeping, are deeply influenced by a person's culture, hence generating differences in the way a same activity is performed by individuals belonging to different cultures. We argue that taking cultural information into account can improve the performance of systems for the automated recognition of human activities. We propose four different solutions to the problem and present a system which uses a Naive Bayes model to associate cultural information with semantic information extracted from still images. Preliminary experiments with a dataset of images of individuals lying on the floor, sleeping on a futon and sleeping on a bed suggest that: i) solutions explicitly taking cultural information into account are more accurate than culture-unaware solutions; and ii) the proposed system is a promising starting point for the development of culture-aware Human Activity Recognition methods.
* 7 pages, 4 figures, Proc. URAI2017, International Conference on Ubiquitous Robots and Ambient Intelligence, Maison Glad Jeju, Jeju, Korea from June 28-July 2017
Longer Version for "Deep Context-Encoding Network for Retinal Image Captioning"
May 30, 2021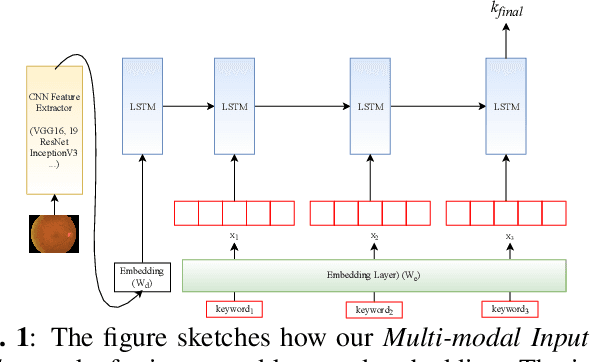
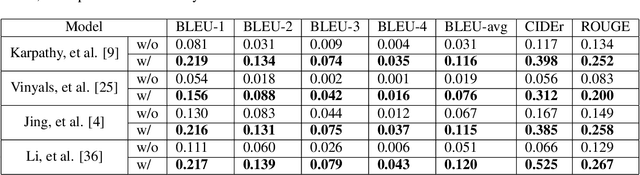
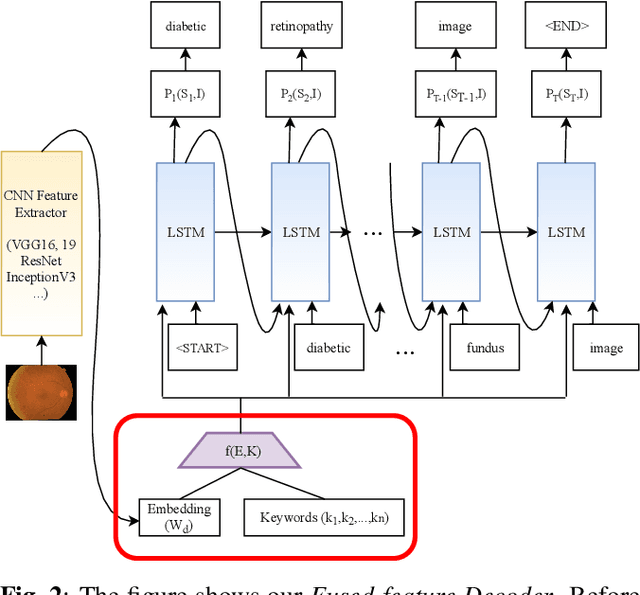

Automatically generating medical reports for retinal images is one of the promising ways to help ophthalmologists reduce their workload and improve work efficiency. In this work, we propose a new context-driven encoding network to automatically generate medical reports for retinal images. The proposed model is mainly composed of a multi-modal input encoder and a fused-feature decoder. Our experimental results show that our proposed method is capable of effectively leveraging the interactive information between the input image and context, i.e., keywords in our case. The proposed method creates more accurate and meaningful reports for retinal images than baseline models and achieves state-of-the-art performance. This performance is shown in several commonly used metrics for the medical report generation task: BLEU-avg (+16%), CIDEr (+10.2%), and ROUGE (+8.6%).
Short-term forecasting of global solar irradiance with incomplete data
Jun 12, 2021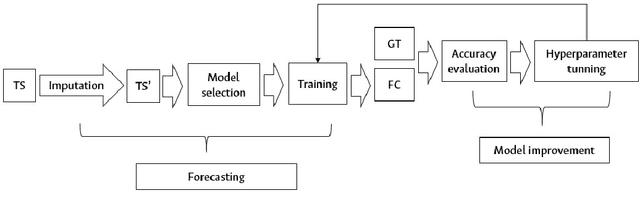

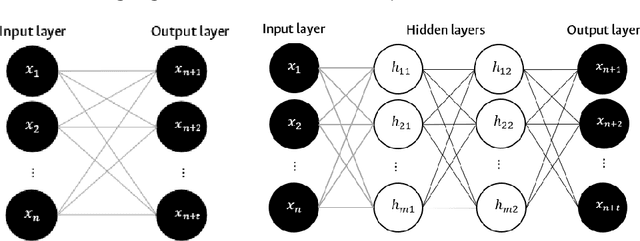
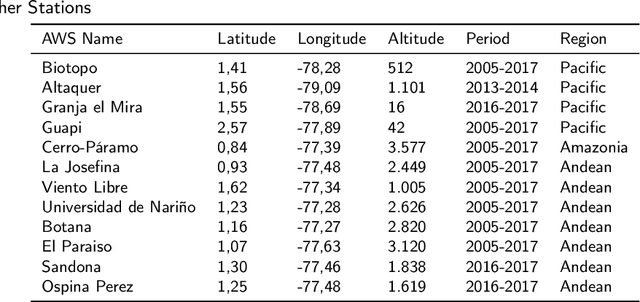
Accurate mechanisms for forecasting solar irradiance and insolation provide important information for the planning of renewable energy and agriculture projects as well as for environmental and socio-economical studies. This research introduces a pipeline for the one-day ahead forecasting of solar irradiance and insolation that only requires solar irradiance historical data for training. Furthermore, our approach is able to deal with missing data since it includes a data imputation state. In the prediction stage, we consider four data-driven approaches: Autoregressive Integrated Moving Average (ARIMA), Single Layer Feed Forward Network (SL-FNN), Multiple Layer Feed Forward Network (FL-FNN), and Long Short-Term Memory (LSTM). The experiments are performed in a real-world dataset collected with 12 Automatic Weather Stations (AWS) located in the Nari\~no - Colombia. The results show that the neural network-based models outperform ARIMA in most cases. Furthermore, LSTM exhibits better performance in cloudy environments (where more randomness is expected).
Disentangling Semantics and Syntax in Sentence Embeddings with Pre-trained Language Models
Apr 11, 2021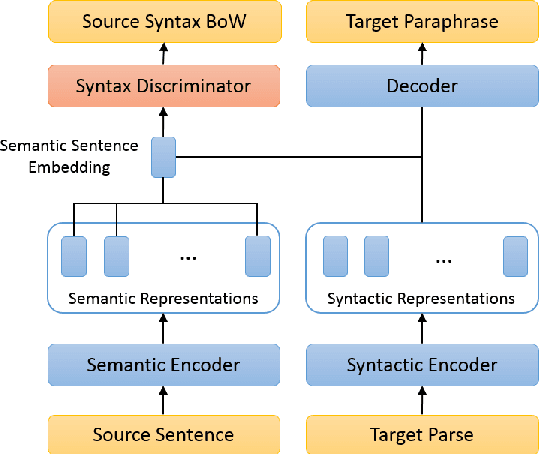
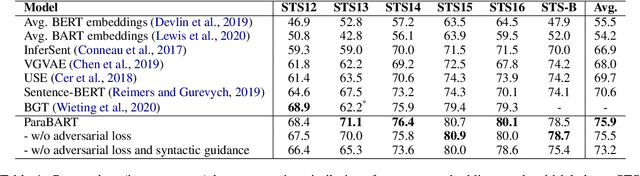
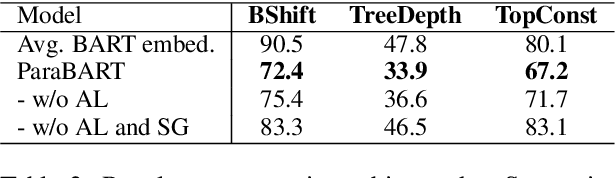

Pre-trained language models have achieved huge success on a wide range of NLP tasks. However, contextual representations from pre-trained models contain entangled semantic and syntactic information, and therefore cannot be directly used to derive useful semantic sentence embeddings for some tasks. Paraphrase pairs offer an effective way of learning the distinction between semantics and syntax, as they naturally share semantics and often vary in syntax. In this work, we present ParaBART, a semantic sentence embedding model that learns to disentangle semantics and syntax in sentence embeddings obtained by pre-trained language models. ParaBART is trained to perform syntax-guided paraphrasing, based on a source sentence that shares semantics with the target paraphrase, and a parse tree that specifies the target syntax. In this way, ParaBART learns disentangled semantic and syntactic representations from their respective inputs with separate encoders. Experiments in English show that ParaBART outperforms state-of-the-art sentence embedding models on unsupervised semantic similarity tasks. Additionally, we show that our approach can effectively remove syntactic information from semantic sentence embeddings, leading to better robustness against syntactic variation on downstream semantic tasks.
What's in a Name? -- Gender Classification of Names with Character Based Machine Learning Models
Feb 07, 2021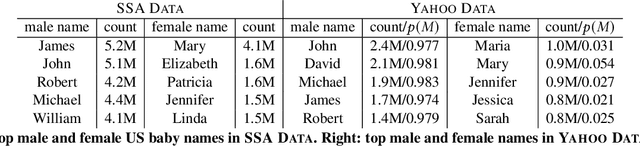
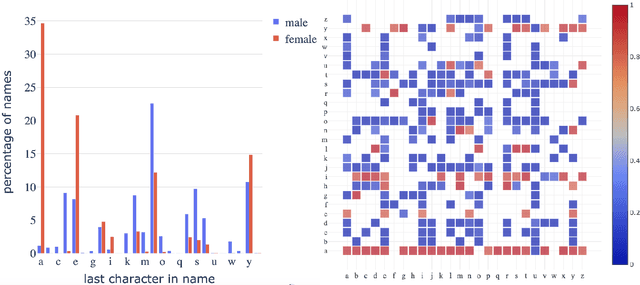
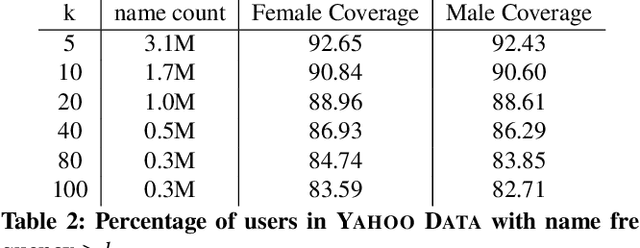
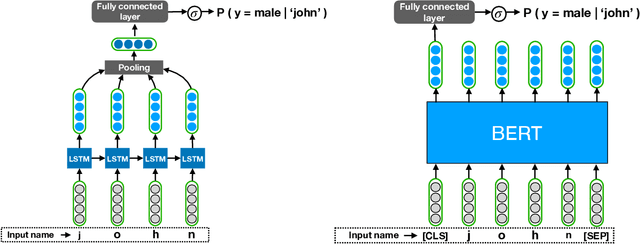
Gender information is no longer a mandatory input when registering for an account at many leading Internet companies. However, prediction of demographic information such as gender and age remains an important task, especially in intervention of unintentional gender/age bias in recommender systems. Therefore it is necessary to infer the gender of those users who did not to provide this information during registration. We consider the problem of predicting the gender of registered users based on their declared name. By analyzing the first names of 100M+ users, we found that genders can be very effectively classified using the composition of the name strings. We propose a number of character based machine learning models, and demonstrate that our models are able to infer the gender of users with much higher accuracy than baseline models. Moreover, we show that using the last names in addition to the first names improves classification performance further.
Discrete-Valued Neural Communication
Jul 10, 2021

Deep learning has advanced from fully connected architectures to structured models organized into components, e.g., the transformer composed of positional elements, modular architectures divided into slots, and graph neural nets made up of nodes. In structured models, an interesting question is how to conduct dynamic and possibly sparse communication among the separate components. Here, we explore the hypothesis that restricting the transmitted information among components to discrete representations is a beneficial bottleneck. The motivating intuition is human language in which communication occurs through discrete symbols. Even though individuals have different understandings of what a "cat" is based on their specific experiences, the shared discrete token makes it possible for communication among individuals to be unimpeded by individual differences in internal representation. To discretize the values of concepts dynamically communicated among specialist components, we extend the quantization mechanism from the Vector-Quantized Variational Autoencoder to multi-headed discretization with shared codebooks and use it for discrete-valued neural communication (DVNC). Our experiments show that DVNC substantially improves systematic generalization in a variety of architectures -- transformers, modular architectures, and graph neural networks. We also show that the DVNC is robust to the choice of hyperparameters, making the method very useful in practice. Moreover, we establish a theoretical justification of our discretization process, proving that it has the ability to increase noise robustness and reduce the underlying dimensionality of the model.
Information Perspective to Probabilistic Modeling: Boltzmann Machines versus Born Machines
Dec 12, 2017
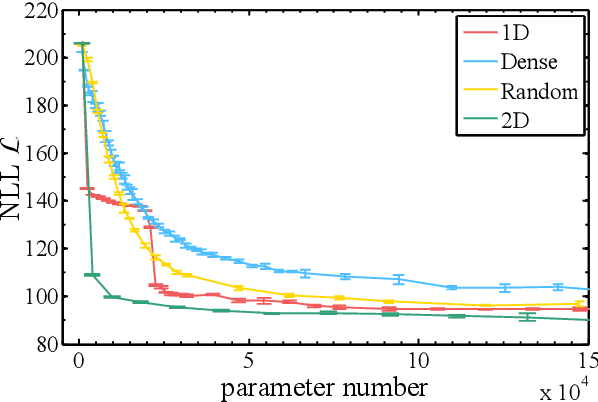
We compare and contrast the statistical physics and quantum physics inspired approaches for unsupervised generative modeling of classical data. The two approaches represent probabilities of observed data using energy-based models and quantum states respectively.Classical and quantum information patterns of the target datasets therefore provide principled guidelines for structural design and learning in these two approaches. Taking the restricted Boltzmann machines (RBM) as an example, we analyze the information theoretical bounds of the two approaches. We verify our reasonings by comparing the performance of RBMs of various architectures on the standard MNIST datasets.
* 7 pages, 4 figures
Review on Indoor RGB-D Semantic Segmentation with Deep Convolutional Neural Networks
May 25, 2021
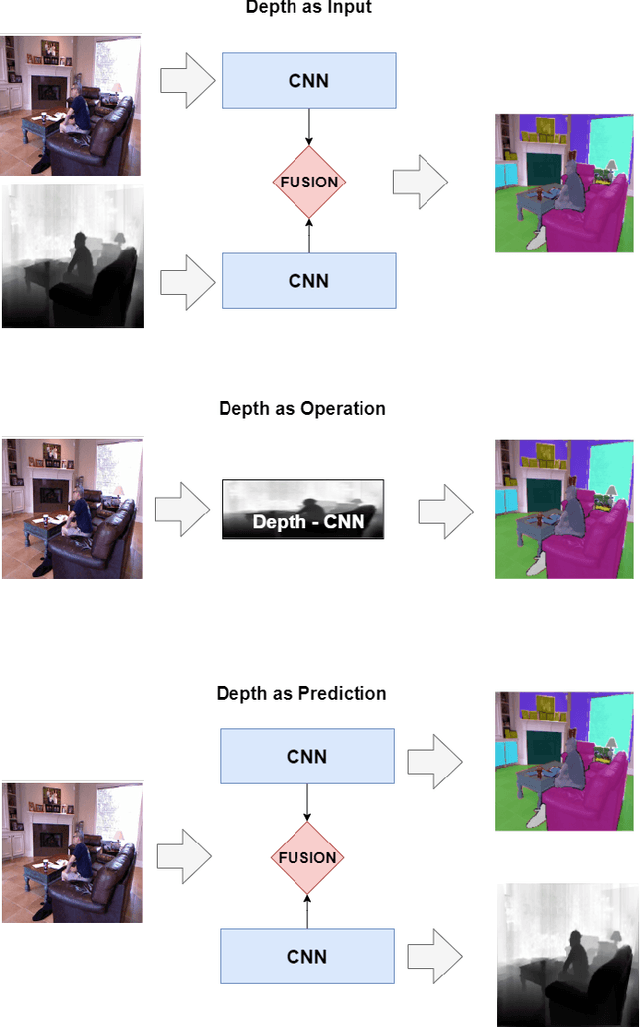
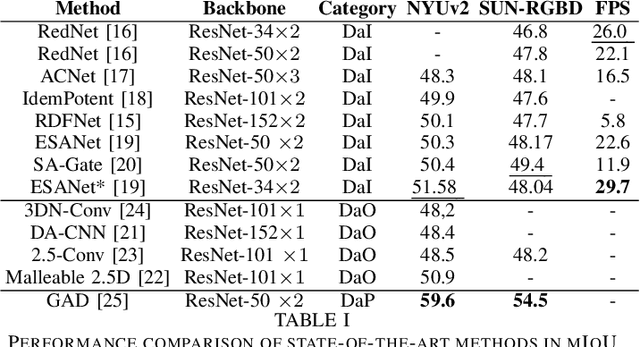
Many research works focus on leveraging the complementary geometric information of indoor depth sensors in vision tasks performed by deep convolutional neural networks, notably semantic segmentation. These works deal with a specific vision task known as "RGB-D Indoor Semantic Segmentation". The challenges and resulting solutions of this task differ from its standard RGB counterpart. This results in a new active research topic. The objective of this paper is to introduce the field of Deep Convolutional Neural Networks for RGB-D Indoor Semantic Segmentation. This review presents the most popular public datasets, proposes a categorization of the strategies employed by recent contributions, evaluates the performance of the current state-of-the-art, and discusses the remaining challenges and promising directions for future works.