 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Retinal OCT Denoising with Pseudo-Multimodal Fusion Network
Jul 09, 2021
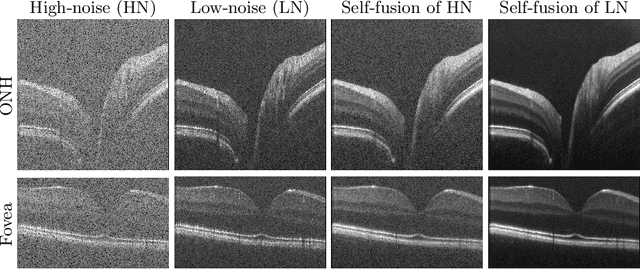
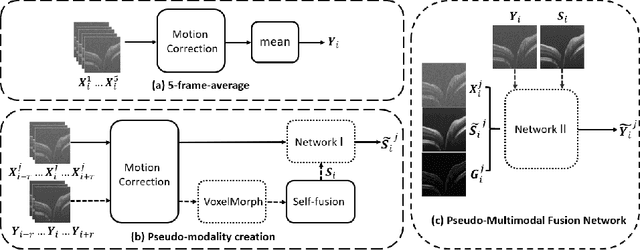
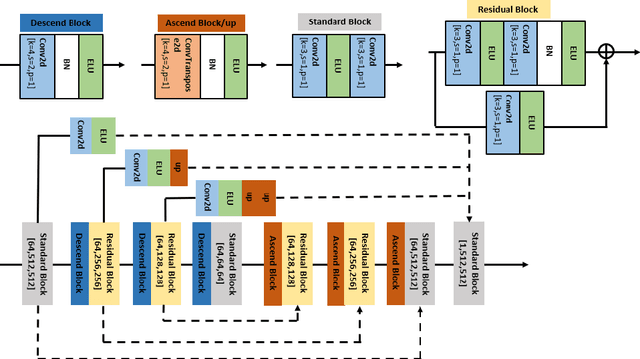
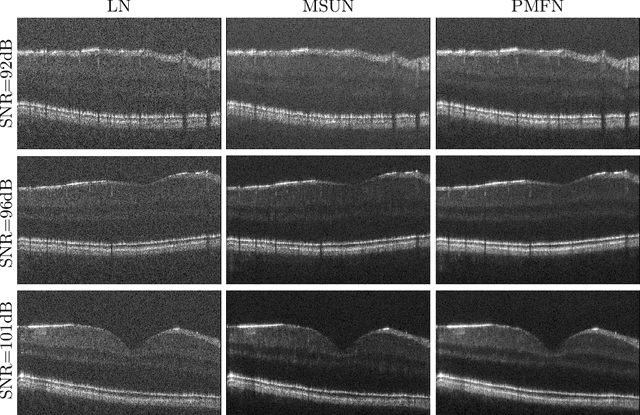
Optical coherence tomography (OCT) is a prevalent imaging technique for retina. However, it is affected by multiplicative speckle noise that can degrade the visibility of essential anatomical structures, including blood vessels and tissue layers. Although averaging repeated B-scan frames can significantly improve the signal-to-noise-ratio (SNR), this requires longer acquisition time, which can introduce motion artifacts and cause discomfort to patients. In this study, we propose a learning-based method that exploits information from the single-frame noisy B-scan and a pseudo-modality that is created with the aid of the self-fusion method. The pseudo-modality provides good SNR for layers that are barely perceptible in the noisy B-scan but can over-smooth fine features such as small vessels. By using a fusion network, desired features from each modality can be combined, and the weight of their contribution is adjustable. Evaluated by intensity-based and structural metrics, the result shows that our method can effectively suppress the speckle noise and enhance the contrast between retina layers while the overall structure and small blood vessels are preserved. Compared to the single modality network, our method improves the structural similarity with low noise B-scan from 0.559 +\- 0.033 to 0.576 +\- 0.031.
UrbanScene3D: A Large Scale Urban Scene Dataset and Simulator
Jul 09, 2021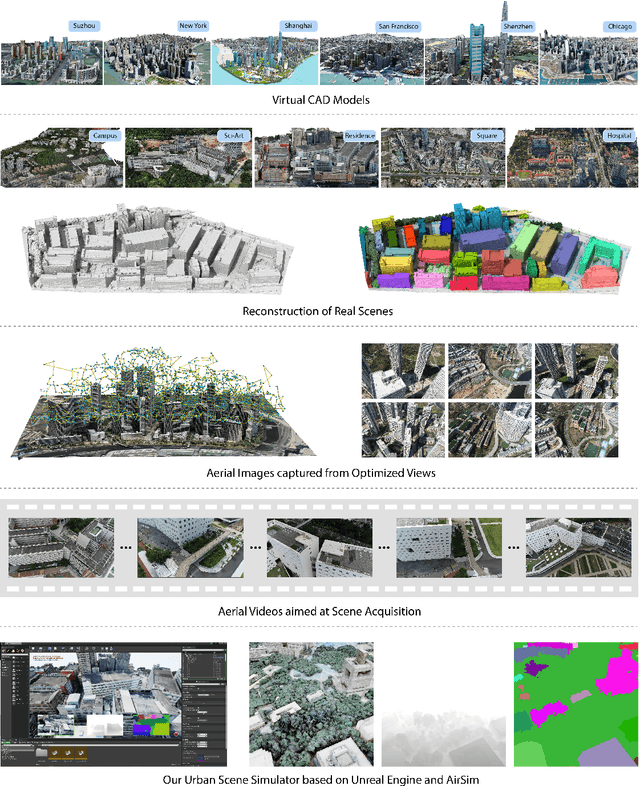
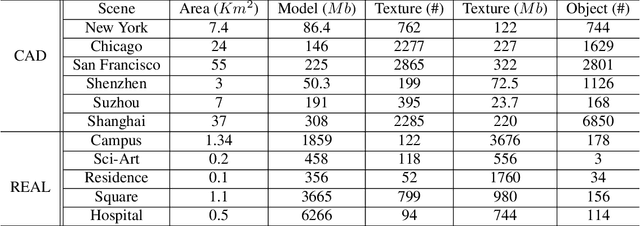
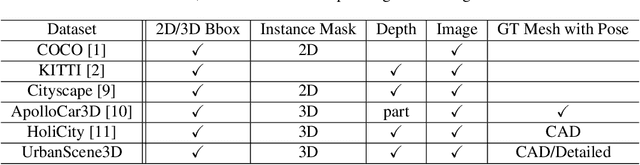
The ability to perceive the environments in different ways is essential to robotic research. This involves the analysis of both 2D and 3D data sources. We present a large scale urban scene dataset associated with a handy simulator based on Unreal Engine 4 and AirSim, which consists of both man-made and real-world reconstruction scenes in different scales, referred to as UrbanScene3D. Unlike previous works that purely based on 2D information or man-made 3D CAD models, UrbanScene3D contains both compact man-made models and detailed real-world models reconstructed by aerial images. Each building has been manually extracted from the entire scene model and then has been assigned with a unique label, forming an instance segmentation map. The provided 3D ground-truth textured models with instance segmentation labels in UrbanScene3D allow users to obtain all kinds of data they would like to have: instance segmentation map, depth map in arbitrary resolution, 3D point cloud/mesh in both visible and invisible places, etc. In addition, with the help of AirSim, users can also simulate the robots (cars/drones)to test a variety of autonomous tasks in the proposed city environment. Please refer to our paper and website(https://vcc.tech/UrbanScene3D/) for further details and applications.
Fast Pixel-Matching for Video Object Segmentation
Jul 09, 2021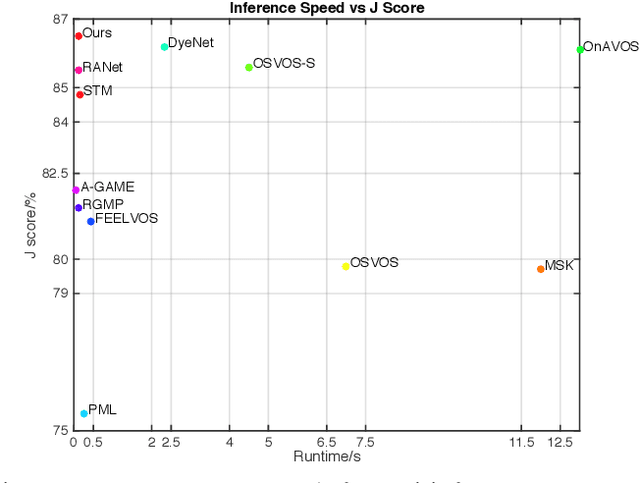
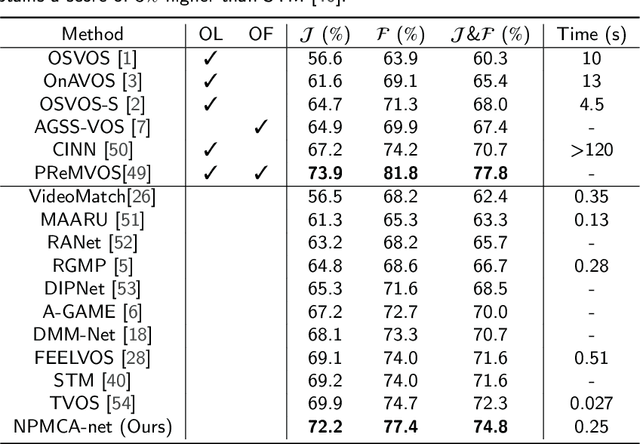
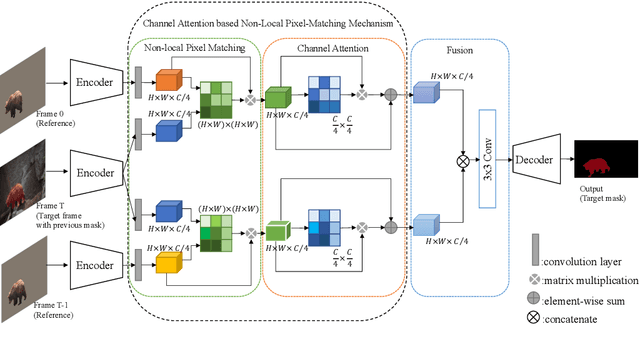
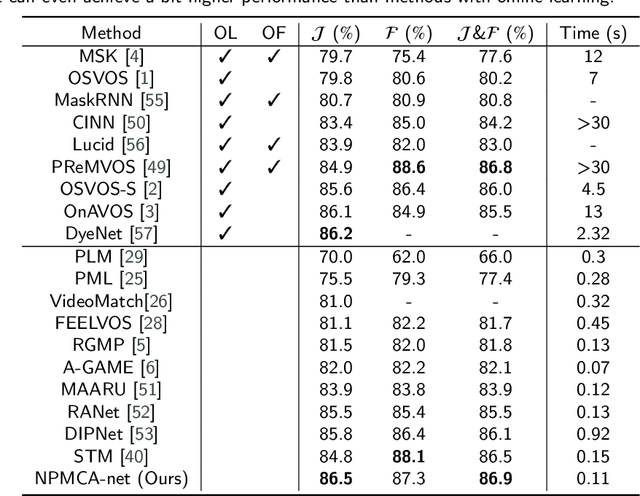
Video object segmentation, aiming to segment the foreground objects given the annotation of the first frame, has been attracting increasing attentions. Many state-of-the-art approaches have achieved great performance by relying on online model updating or mask-propagation techniques. However, most online models require high computational cost due to model fine-tuning during inference. Most mask-propagation based models are faster but with relatively low performance due to failure to adapt to object appearance variation. In this paper, we are aiming to design a new model to make a good balance between speed and performance. We propose a model, called NPMCA-net, which directly localizes foreground objects based on mask-propagation and non-local technique by matching pixels in reference and target frames. Since we bring in information of both first and previous frames, our network is robust to large object appearance variation, and can better adapt to occlusions. Extensive experiments show that our approach can achieve a new state-of-the-art performance with a fast speed at the same time (86.5% IoU on DAVIS-2016 and 72.2% IoU on DAVIS-2017, with speed of 0.11s per frame) under the same level comparison. Source code is available at https://github.com/siyueyu/NPMCA-net.
SGD with Coordinate Sampling: Theory and Practice
May 25, 2021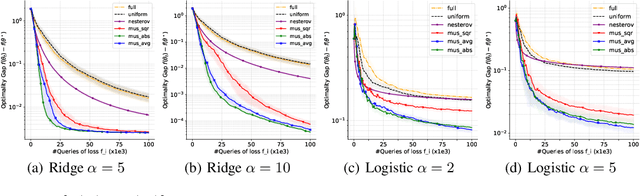

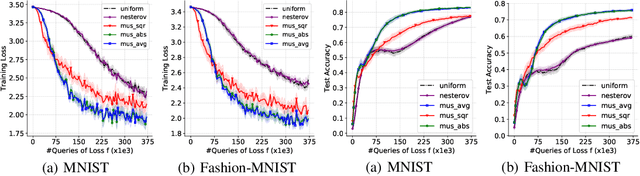
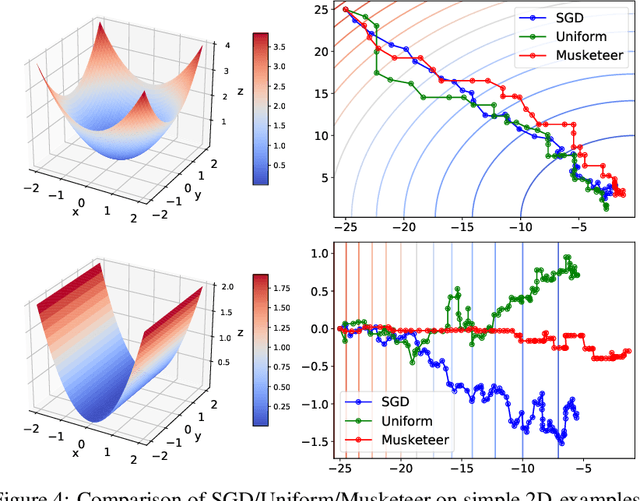
While classical forms of stochastic gradient descent algorithm treat the different coordinates in the same way, a framework allowing for adaptive (non uniform) coordinate sampling is developed to leverage structure in data. In a non-convex setting and including zeroth order gradient estimate, almost sure convergence as well as non-asymptotic bounds are established. Within the proposed framework, we develop an algorithm, MUSKETEER, based on a reinforcement strategy: after collecting information on the noisy gradients, it samples the most promising coordinate (all for one); then it moves along the one direction yielding an important decrease of the objective (one for all). Numerical experiments on both synthetic and real data examples confirm the effectiveness of MUSKETEER in large scale problems.
Graph-Embedded Multi-Agent Learning for Smart Reconfigurable THz MIMO-NOMA Networks
Jul 15, 2021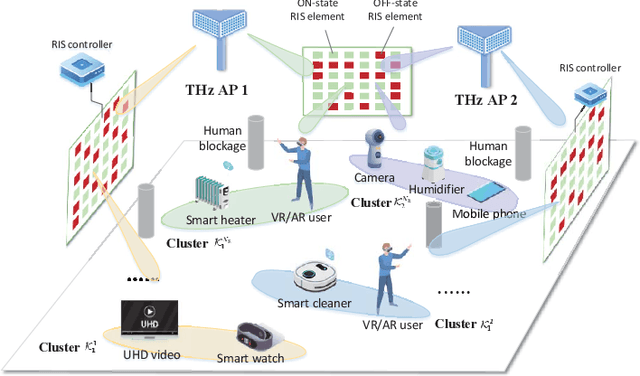
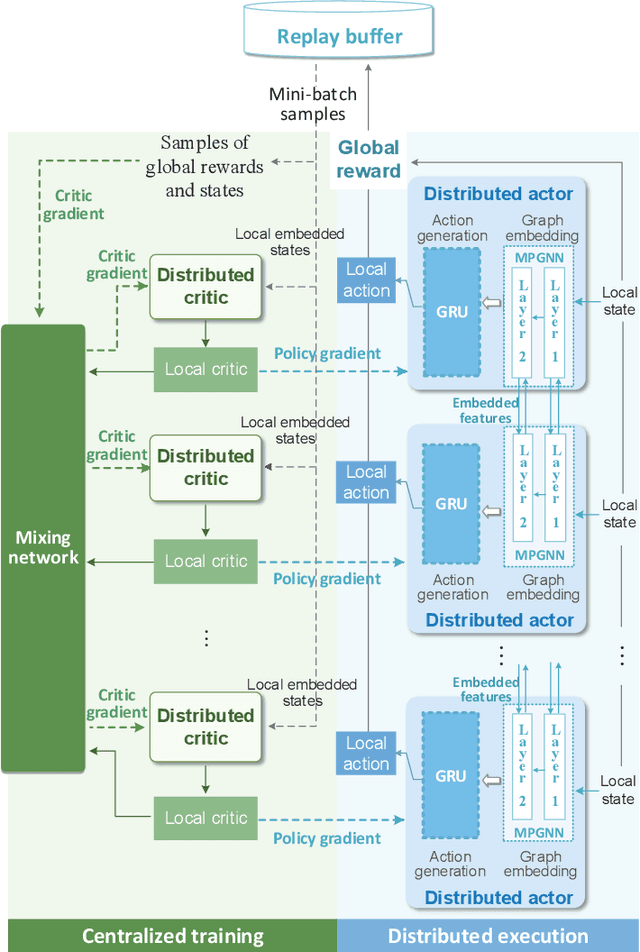
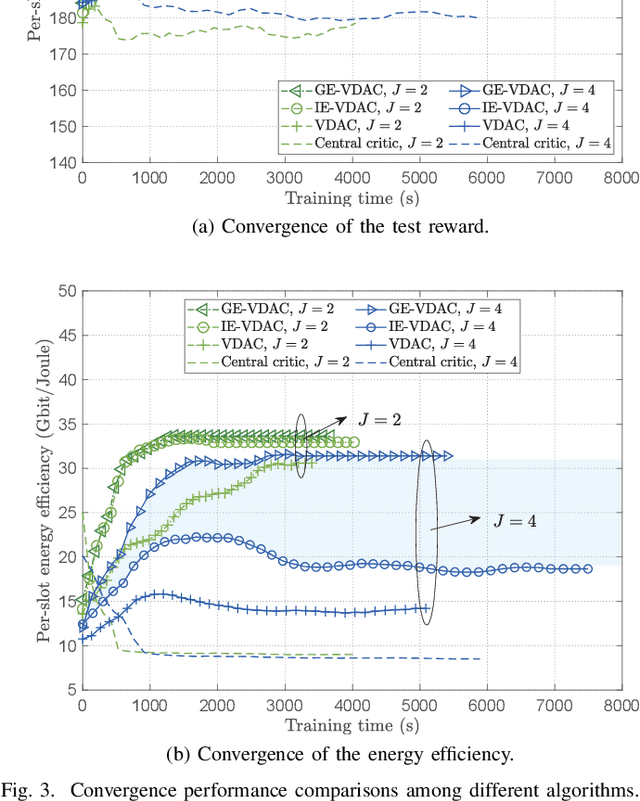
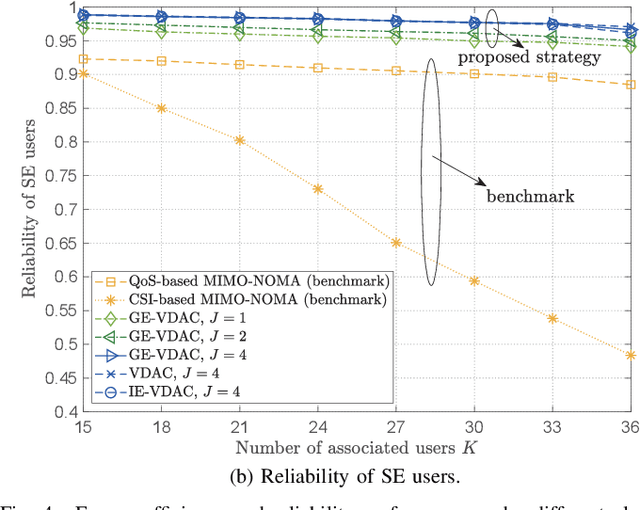
With the accelerated development of immersive applications and the explosive increment of internet-of-things (IoT) terminals, 6G would introduce terahertz (THz) massive multiple-input multiple-output non-orthogonal multiple access (MIMO-NOMA) technologies to meet the ultra-high-speed transmission and massive connectivity requirements. Nevertheless, the unreliability of THz transmissions and the extreme heterogeneity of device requirements pose critical challenges for practical applications. To address these challenges, we propose a novel smart reconfigurable THz MIMO-NOMA framework, which can realize customizable and intelligent communications by flexibly and coordinately reconfiguring hybrid beams through the cooperation between access points (APs) and reconfigurable intelligent surfaces (RISs). The optimization problem is formulated as a decentralized partially-observable Markov decision process (Dec-POMDP) to maximize the network energy efficiency, while guaranteeing the diversified users' performance, via a joint RIS element selection, coordinated discrete phase-shift control, and power allocation strategy. To solve the above non-convex, strongly coupled, and highly complex mixed integer nonlinear programming (MINLP) problem, we propose a novel multi-agent deep reinforcement learning (MADRL) algorithm, namely graph-embedded value-decomposition actor-critic (GE-VDAC), that embeds the interaction information of agents, and learns a locally optimal solution through a distributed policy. Numerical results demonstrate that the proposed algorithm achieves highly customized communications and outperforms traditional MADRL algorithms.
Application of Opportunistic Bit to Multilevel Codes
May 25, 2021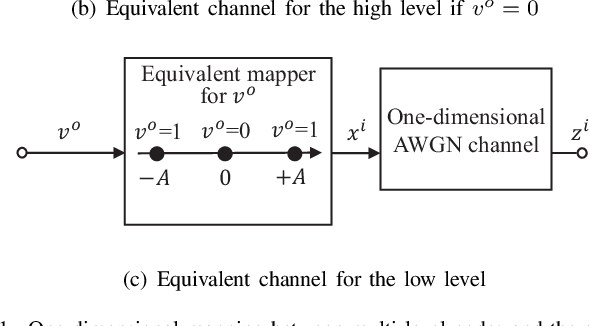
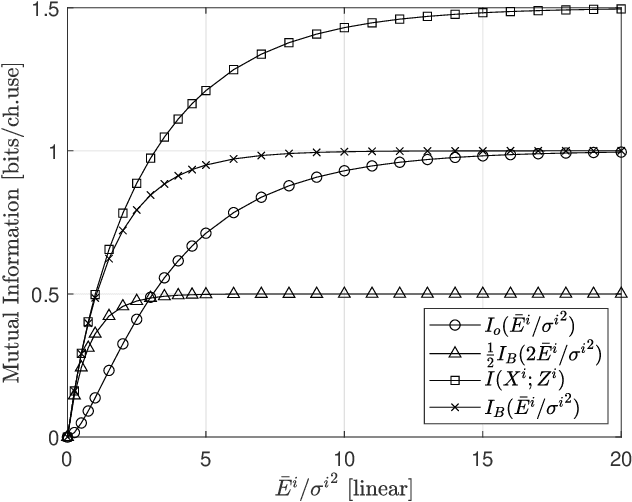
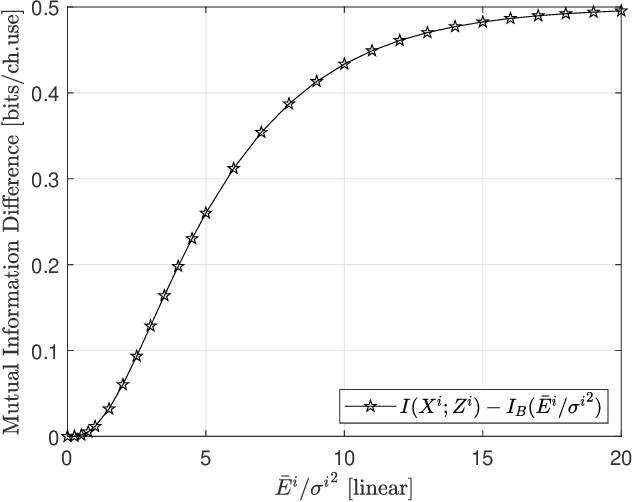
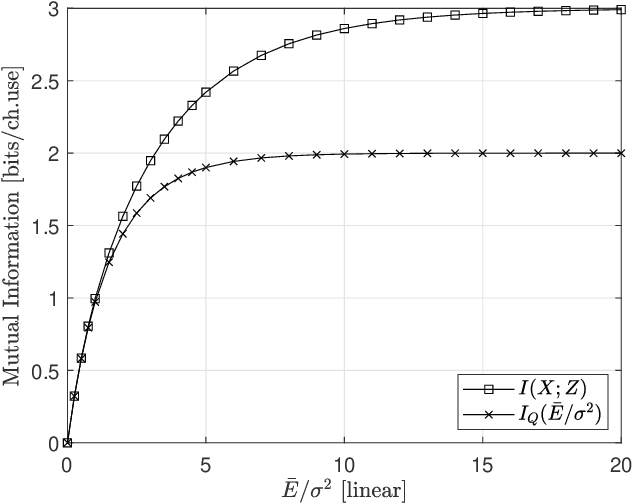
In this paper, we propose a new signal organization method to work in the structure of the multi level coding (MLC). The transmit bits are divided into opportunistic bit (OB) and conventional bit (CB), which are mapped to the lower level- and higher level signal in parallel to the MLC, respectively. Because the OB's mapping does not require signal power explicitly, the energy of the CB modulated symbol can be doubled. As the result, the overall mutual information of the proposed method is found higher than that of the conventional BPSK in one dimensional case. Moreover, the extension of the method to the two-complex-dimension shows the better performance over the QPSK. The numerical results confirm this approach.
Structured Sentiment Analysis as Dependency Graph Parsing
May 30, 2021
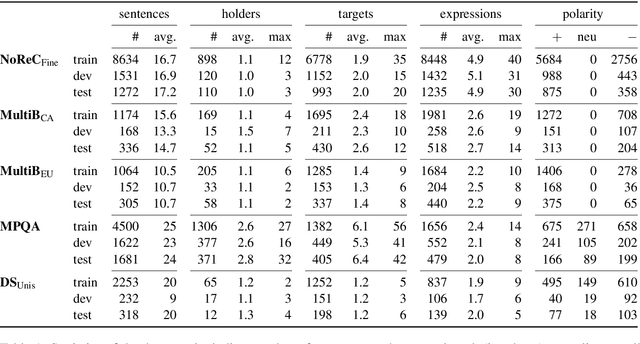
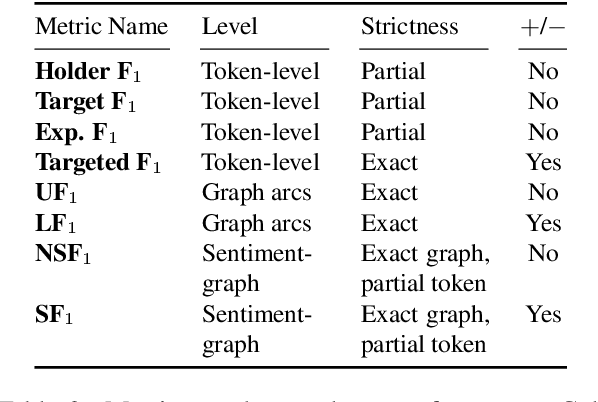
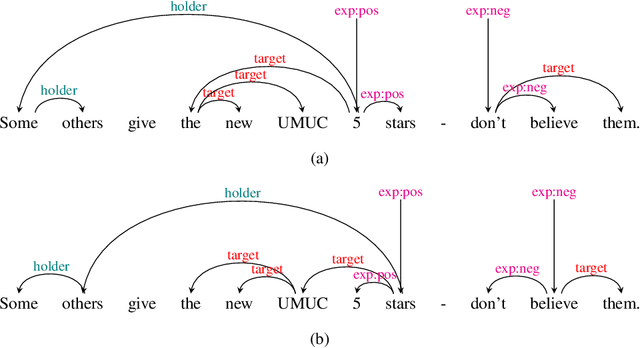
Structured sentiment analysis attempts to extract full opinion tuples from a text, but over time this task has been subdivided into smaller and smaller sub-tasks, e,g,, target extraction or targeted polarity classification. We argue that this division has become counterproductive and propose a new unified framework to remedy the situation. We cast the structured sentiment problem as dependency graph parsing, where the nodes are spans of sentiment holders, targets and expressions, and the arcs are the relations between them. We perform experiments on five datasets in four languages (English, Norwegian, Basque, and Catalan) and show that this approach leads to strong improvements over state-of-the-art baselines. Our analysis shows that refining the sentiment graphs with syntactic dependency information further improves results.
Deep Triplet Hashing Network for Case-based Medical Image Retrieval
Jan 29, 2021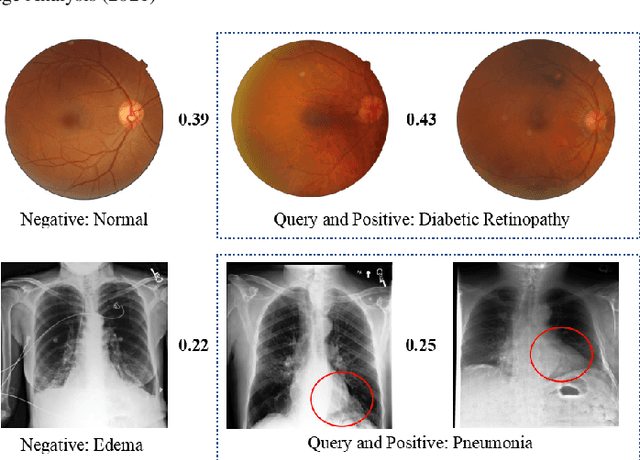
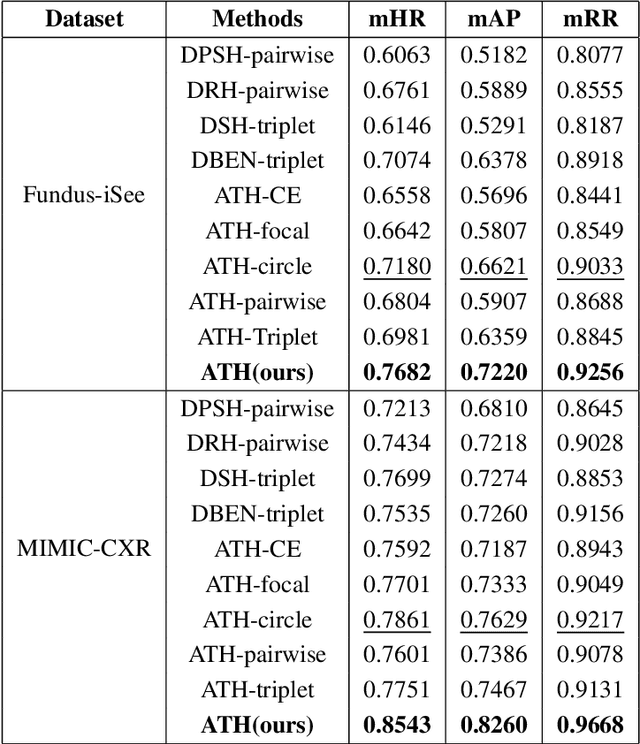
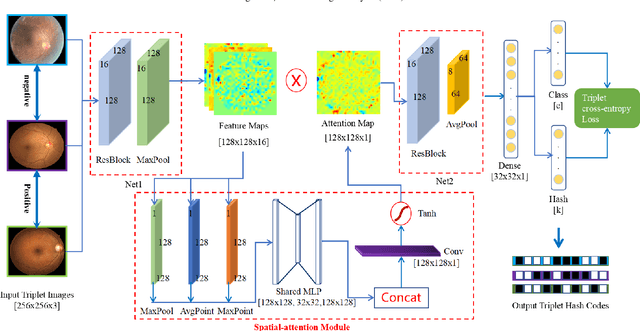
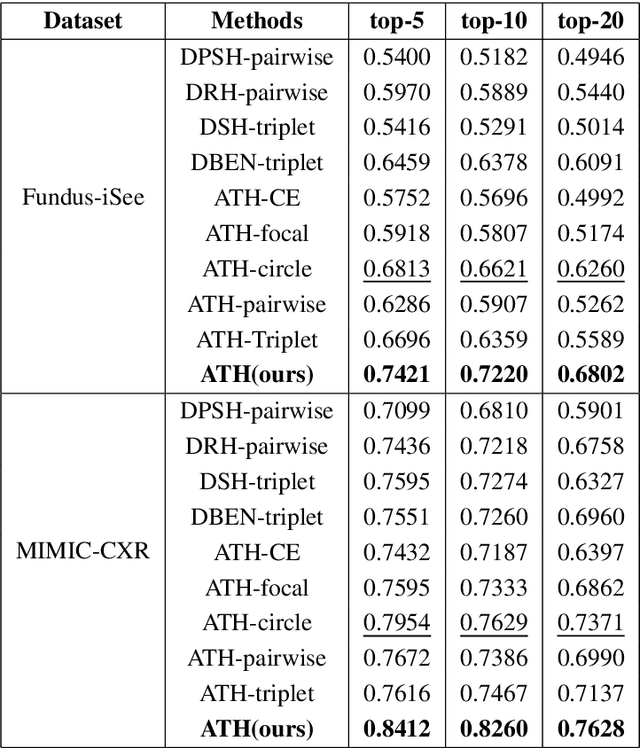
Deep hashing methods have been shown to be the most efficient approximate nearest neighbor search techniques for large-scale image retrieval. However, existing deep hashing methods have a poor small-sample ranking performance for case-based medical image retrieval. The top-ranked images in the returned query results may be as a different class than the query image. This ranking problem is caused by classification, regions of interest (ROI), and small-sample information loss in the hashing space. To address the ranking problem, we propose an end-to-end framework, called Attention-based Triplet Hashing (ATH) network, to learn low-dimensional hash codes that preserve the classification, ROI, and small-sample information. We embed a spatial-attention module into the network structure of our ATH to focus on ROI information. The spatial-attention module aggregates the spatial information of feature maps by utilizing max-pooling, element-wise maximum, and element-wise mean operations jointly along the channel axis. The triplet cross-entropy loss can help to map the classification information of images and similarity between images into the hash codes. Extensive experiments on two case-based medical datasets demonstrate that our proposed ATH can further improve the retrieval performance compared to the state-of-the-art deep hashing methods and boost the ranking performance for small samples. Compared to the other loss methods, the triplet cross-entropy loss can enhance the classification performance and hash code-discriminability
LAMPRET: Layout-Aware Multimodal PreTraining for Document Understanding
Apr 16, 2021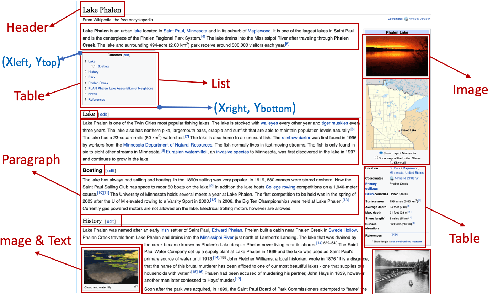
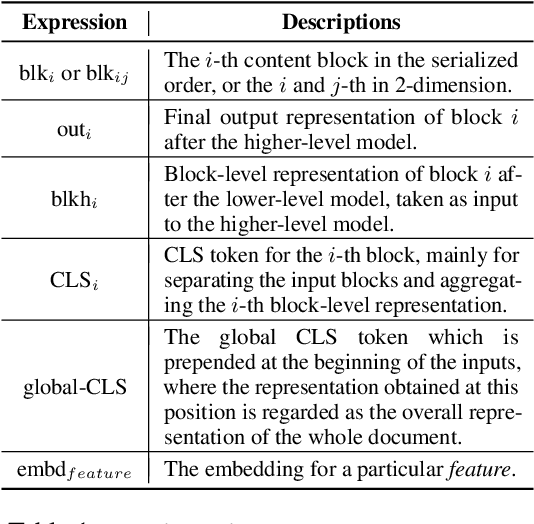
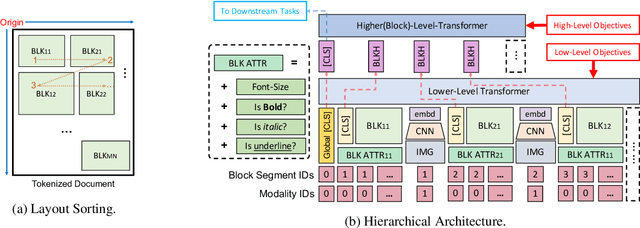
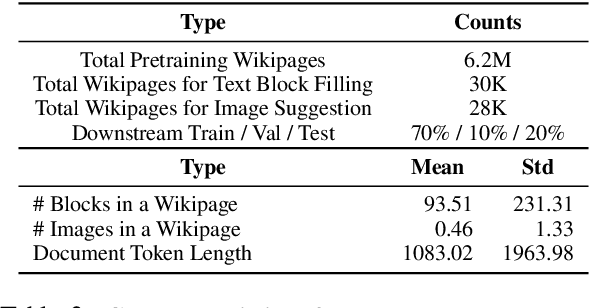
Document layout comprises both structural and visual (eg. font-sizes) information that is vital but often ignored by machine learning models. The few existing models which do use layout information only consider textual contents, and overlook the existence of contents in other modalities such as images. Additionally, spatial interactions of presented contents in a layout were never really fully exploited. To bridge this gap, we parse a document into content blocks (eg. text, table, image) and propose a novel layout-aware multimodal hierarchical framework, LAMPreT, to model the blocks and the whole document. Our LAMPreT encodes each block with a multimodal transformer in the lower-level and aggregates the block-level representations and connections utilizing a specifically designed transformer at the higher-level. We design hierarchical pretraining objectives where the lower-level model is trained similarly to multimodal grounding models, and the higher-level model is trained with our proposed novel layout-aware objectives. We evaluate the proposed model on two layout-aware tasks -- text block filling and image suggestion and show the effectiveness of our proposed hierarchical architecture as well as pretraining techniques.
A life-long SLAM approach using adaptable local maps based on rasterized LIDAR images
Jul 15, 2021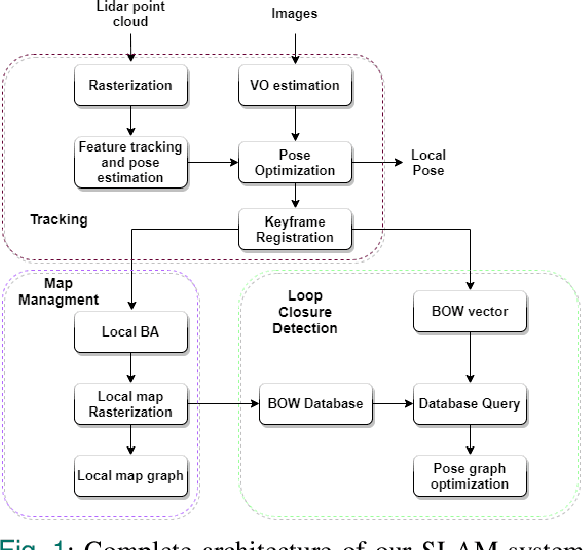
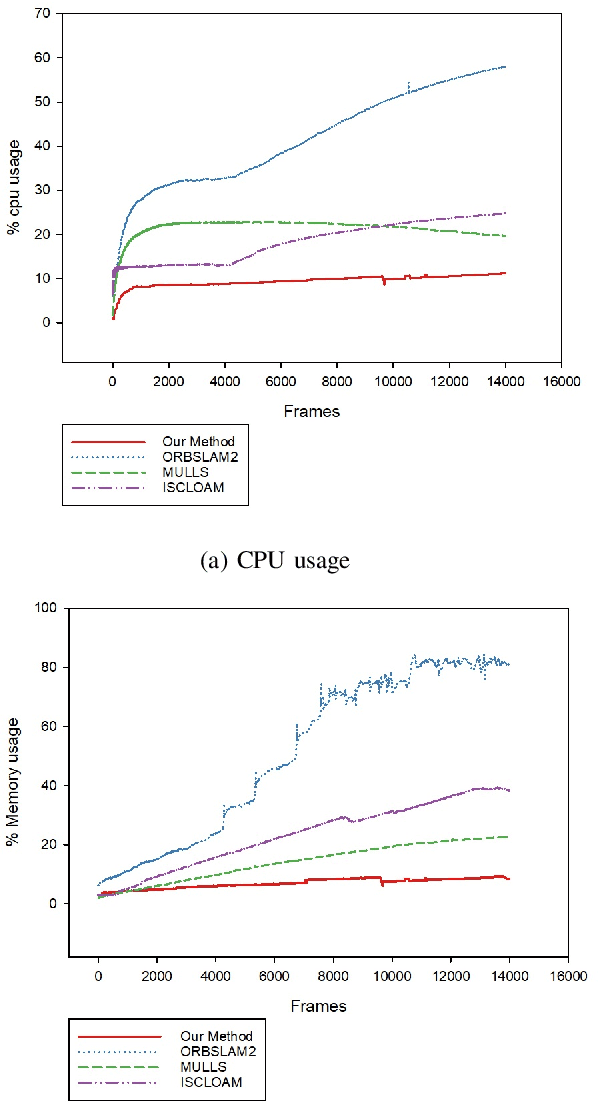
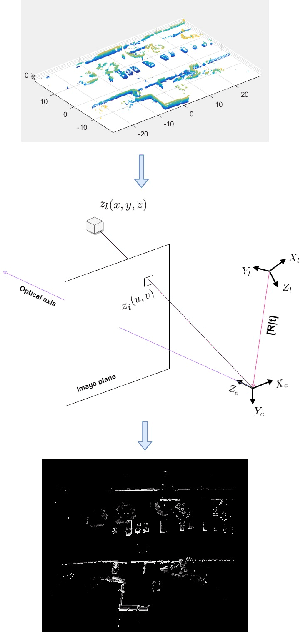
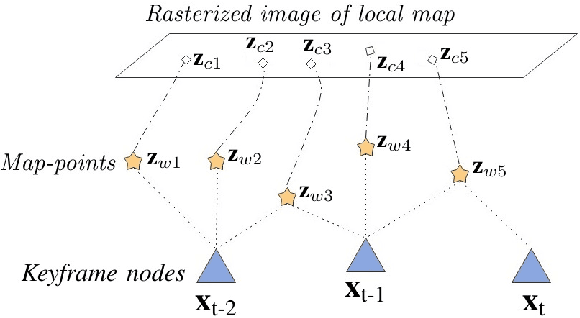
Most real-time autonomous robot applications require a robot to traverse through a dynamic space for a long time. In some cases, a robot needs to work in the same environment. Such applications give rise to the problem of a life-long SLAM system. Life-long SLAM presents two main challenges i.e. the tracking should not fail in a dynamic environment and the need for a robust and efficient mapping strategy. The system should update maps with new information; while also keeping track of older observations. But, mapping for a long time can require higher computational requirements. In this paper, we propose a solution to the problem of life-long SLAM. We represent the global map as a set of rasterized images of local maps along with a map management system responsible for updating local maps and keeping track of older values. We also present an efficient approach of using the bag of visual words method for loop closure detection and relocalization. We evaluate the performance of our system on the KITTI dataset and an indoor dataset. Our loop closure system reported recall and precision of above 90 percent. The computational cost of our system is much lower as compared to state-of-the-art methods. Our method reports lower computational requirements even for long-term operation.