 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVAMOS-OCTA: Vessel-Aware Multi-Axis Orthogonal Supervision for Inpainting Motion-Corrupted OCT Angiography Volumes
Feb 01, 2026Handheld Optical Coherence Tomography Angiography (OCTA) enables noninvasive retinal imaging in uncooperative or pediatric subjects, but is highly susceptible to motion artifacts that severely degrade volumetric image quality. Sudden motion during 3D acquisition can lead to unsampled retinal regions across entire B-scans (cross-sectional slices), resulting in blank bands in en face projections. We propose VAMOS-OCTA, a deep learning framework for inpainting motion-corrupted B-scans using vessel-aware multi-axis supervision. We employ a 2.5D U-Net architecture that takes a stack of neighboring B-scans as input to reconstruct a corrupted center B-scan, guided by a novel Vessel-Aware Multi-Axis Orthogonal Supervision (VAMOS) loss. This loss combines vessel-weighted intensity reconstruction with axial and lateral projection consistency, encouraging vascular continuity in native B-scans and across orthogonal planes. Unlike prior work that focuses primarily on restoring the en face MIP, VAMOS-OCTA jointly enhances both cross-sectional B-scan sharpness and volumetric projection accuracy, even under severe motion corruptions. We trained our model on both synthetic and real-world corrupted volumes and evaluated its performance using both perceptual quality and pixel-wise accuracy metrics. VAMOS-OCTA consistently outperforms prior methods, producing reconstructions with sharp capillaries, restored vessel continuity, and clean en face projections. These results demonstrate that multi-axis supervision offers a powerful constraint for restoring motion-degraded 3D OCTA data. Our source code is available at https://github.com/MedICL-VU/VAMOS-OCTA.
Retinal IPA: Iterative KeyPoints Alignment for Multimodal Retinal Imaging
Jul 25, 2024



We propose a novel framework for retinal feature point alignment, designed for learning cross-modality features to enhance matching and registration across multi-modality retinal images. Our model draws on the success of previous learning-based feature detection and description methods. To better leverage unlabeled data and constrain the model to reproduce relevant keypoints, we integrate a keypoint-based segmentation task. It is trained in a self-supervised manner by enforcing segmentation consistency between different augmentations of the same image. By incorporating a keypoint augmented self-supervised layer, we achieve robust feature extraction across modalities. Extensive evaluation on two public datasets and one in-house dataset demonstrates significant improvements in performance for modality-agnostic retinal feature alignment. Our code and model weights are publicly available at \url{https://github.com/MedICL-VU/RetinaIPA}.
Novel OCT mosaicking pipeline with Feature- and Pixel-based registration
Nov 21, 2023High-resolution Optical Coherence Tomography (OCT) images are crucial for ophthalmology studies but are limited by their relatively narrow field of view (FoV). Image mosaicking is a technique for aligning multiple overlapping images to obtain a larger FoV. Current mosaicking pipelines often struggle with substantial noise and considerable displacement between the input sub-fields. In this paper, we propose a versatile pipeline for stitching multi-view OCT/OCTA \textit{en face} projection images. Our method combines the strengths of learning-based feature matching and robust pixel-based registration to align multiple images effectively. Furthermore, we advance the application of a trained foundational model, Segment Anything Model (SAM), to validate mosaicking results in an unsupervised manner. The efficacy of our pipeline is validated using an in-house dataset and a large public dataset, where our method shows superior performance in terms of both accuracy and computational efficiency. We also made our evaluation tool for image mosaicking and the corresponding pipeline publicly available at \url{https://github.com/MedICL-VU/OCT-mosaicking}.
Deep Angiogram: Trivializing Retinal Vessel Segmentation
Jul 01, 2023Among the research efforts to segment the retinal vasculature from fundus images, deep learning models consistently achieve superior performance. However, this data-driven approach is very sensitive to domain shifts. For fundus images, such data distribution changes can easily be caused by variations in illumination conditions as well as the presence of disease-related features such as hemorrhages and drusen. Since the source domain may not include all possible types of pathological cases, a model that can robustly recognize vessels on unseen domains is desirable but remains elusive, despite many proposed segmentation networks of ever-increasing complexity. In this work, we propose a contrastive variational auto-encoder that can filter out irrelevant features and synthesize a latent image, named deep angiogram, representing only the retinal vessels. Then segmentation can be readily accomplished by thresholding the deep angiogram. The generalizability of the synthetic network is improved by the contrastive loss that makes the model less sensitive to variations of image contrast and noisy features. Compared to baseline deep segmentation networks, our model achieves higher segmentation performance via simple thresholding. Our experiments show that the model can generate stable angiograms on different target domains, providing excellent visualization of vessels and a non-invasive, safe alternative to fluorescein angiography.
* 5 pages, 4 figures, SPIE 2023
Unsupervised Denoising of Retinal OCT with Diffusion Probabilistic Model
Jan 27, 2022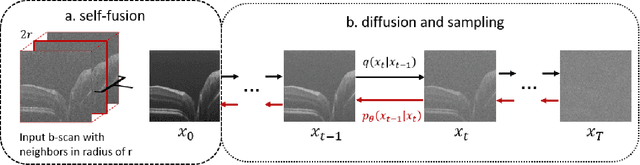

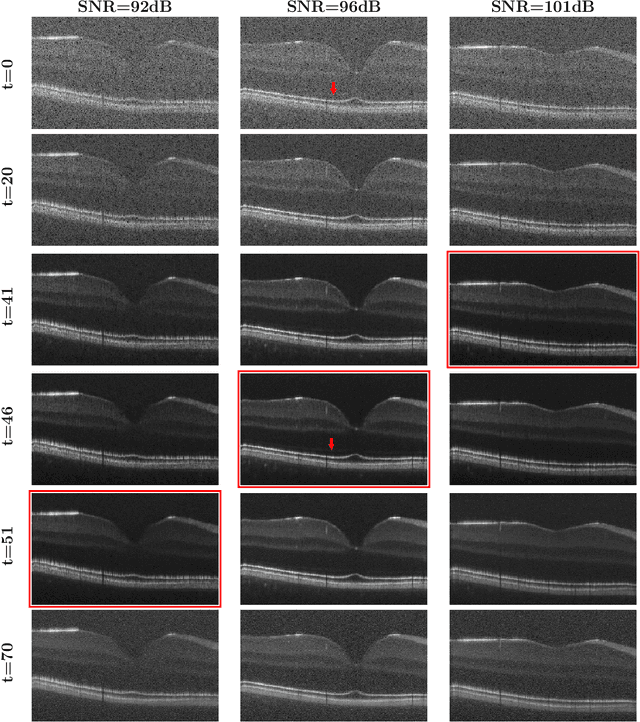
Optical coherence tomography (OCT) is a prevalent non-invasive imaging method which provides high resolution volumetric visualization of retina. However, its inherent defect, the speckle noise, can seriously deteriorate the tissue visibility in OCT. Deep learning based approaches have been widely used for image restoration, but most of these require a noise-free reference image for supervision. In this study, we present a diffusion probabilistic model that is fully unsupervised to learn from noise instead of signal. A diffusion process is defined by adding a sequence of Gaussian noise to self-fused OCT b-scans. Then the reverse process of diffusion, modeled by a Markov chain, provides an adjustable level of denoising. Our experiment results demonstrate that our method can significantly improve the image quality with a simple working pipeline and a small amount of training data.
Retinal OCT Denoising with Pseudo-Multimodal Fusion Network
Jul 09, 2021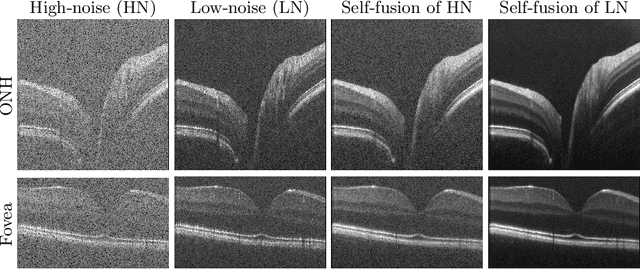
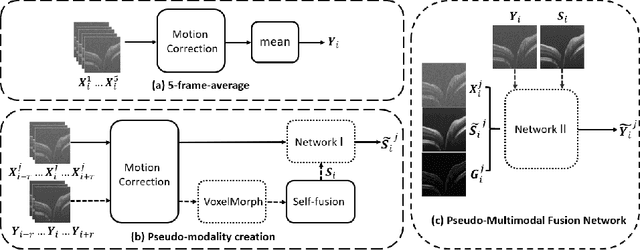
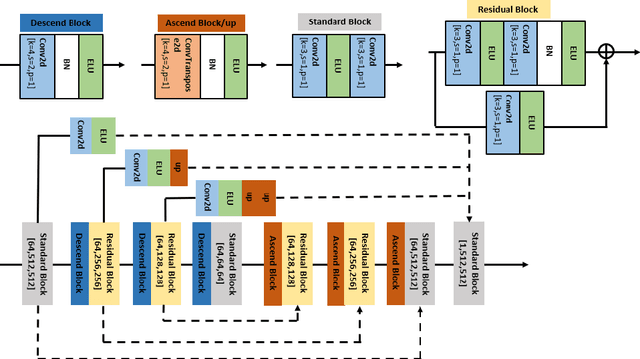
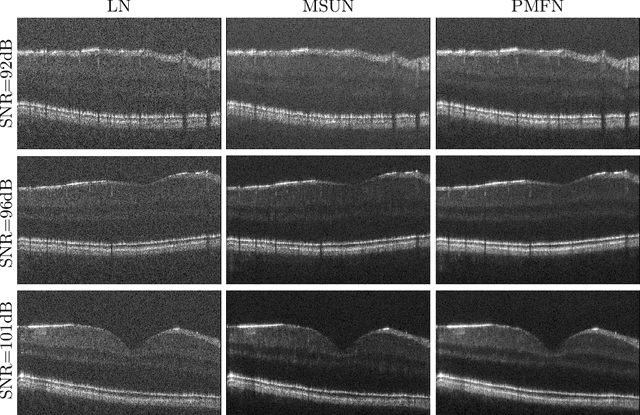
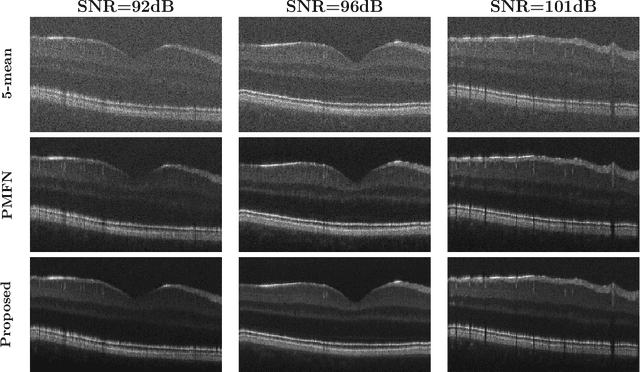
Optical coherence tomography (OCT) is a prevalent imaging technique for retina. However, it is affected by multiplicative speckle noise that can degrade the visibility of essential anatomical structures, including blood vessels and tissue layers. Although averaging repeated B-scan frames can significantly improve the signal-to-noise-ratio (SNR), this requires longer acquisition time, which can introduce motion artifacts and cause discomfort to patients. In this study, we propose a learning-based method that exploits information from the single-frame noisy B-scan and a pseudo-modality that is created with the aid of the self-fusion method. The pseudo-modality provides good SNR for layers that are barely perceptible in the noisy B-scan but can over-smooth fine features such as small vessels. By using a fusion network, desired features from each modality can be combined, and the weight of their contribution is adjustable. Evaluated by intensity-based and structural metrics, the result shows that our method can effectively suppress the speckle noise and enhance the contrast between retina layers while the overall structure and small blood vessels are preserved. Compared to the single modality network, our method improves the structural similarity with low noise B-scan from 0.559 +\- 0.033 to 0.576 +\- 0.031.
LIFE: A Generalizable Autodidactic Pipeline for 3D OCT-A Vessel Segmentation
Jul 09, 2021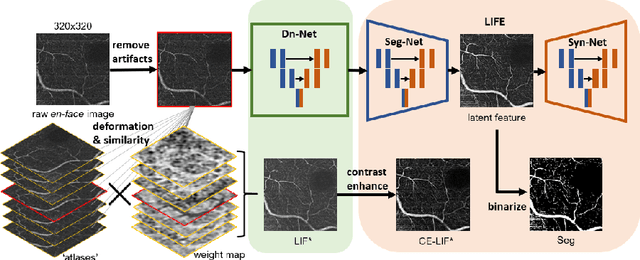
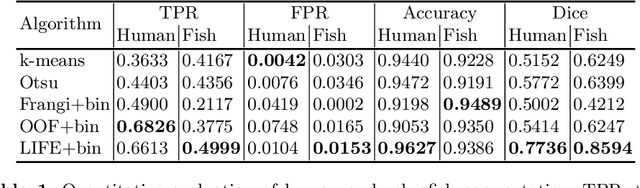
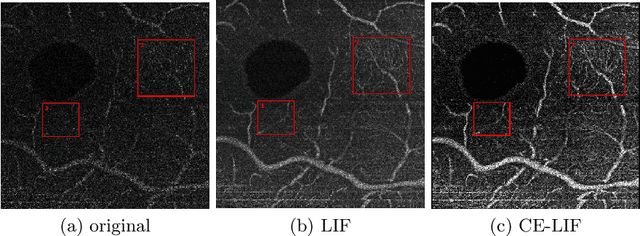
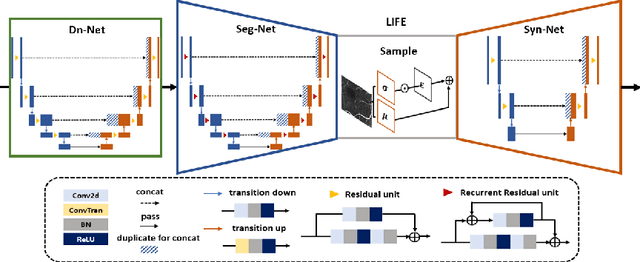
Optical coherence tomography (OCT) is a non-invasive imaging technique widely used for ophthalmology. It can be extended to OCT angiography (OCT-A), which reveals the retinal vasculature with improved contrast. Recent deep learning algorithms produced promising vascular segmentation results; however, 3D retinal vessel segmentation remains difficult due to the lack of manually annotated training data. We propose a learning-based method that is only supervised by a self-synthesized modality named local intensity fusion (LIF). LIF is a capillary-enhanced volume computed directly from the input OCT-A. We then construct the local intensity fusion encoder (LIFE) to map a given OCT-A volume and its LIF counterpart to a shared latent space. The latent space of LIFE has the same dimensions as the input data and it contains features common to both modalities. By binarizing this latent space, we obtain a volumetric vessel segmentation. Our method is evaluated in a human fovea OCT-A and three zebrafish OCT-A volumes with manual labels. It yields a Dice score of 0.7736 on human data and 0.8594 +/- 0.0275 on zebrafish data, a dramatic improvement over existing unsupervised algorithms.