 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLAMPRET: Layout-Aware Multimodal PreTraining for Document Understanding
Paper and Code
Apr 16, 2021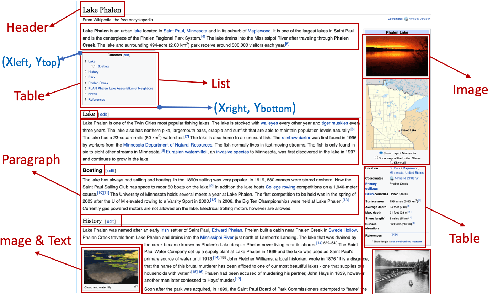
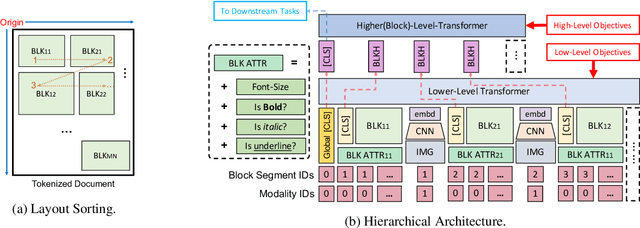
Document layout comprises both structural and visual (eg. font-sizes) information that is vital but often ignored by machine learning models. The few existing models which do use layout information only consider textual contents, and overlook the existence of contents in other modalities such as images. Additionally, spatial interactions of presented contents in a layout were never really fully exploited. To bridge this gap, we parse a document into content blocks (eg. text, table, image) and propose a novel layout-aware multimodal hierarchical framework, LAMPreT, to model the blocks and the whole document. Our LAMPreT encodes each block with a multimodal transformer in the lower-level and aggregates the block-level representations and connections utilizing a specifically designed transformer at the higher-level. We design hierarchical pretraining objectives where the lower-level model is trained similarly to multimodal grounding models, and the higher-level model is trained with our proposed novel layout-aware objectives. We evaluate the proposed model on two layout-aware tasks -- text block filling and image suggestion and show the effectiveness of our proposed hierarchical architecture as well as pretraining techniques.