 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Benchmarking AutoML Frameworks for Disease Prediction Using Medical Claims
Jul 22, 2021
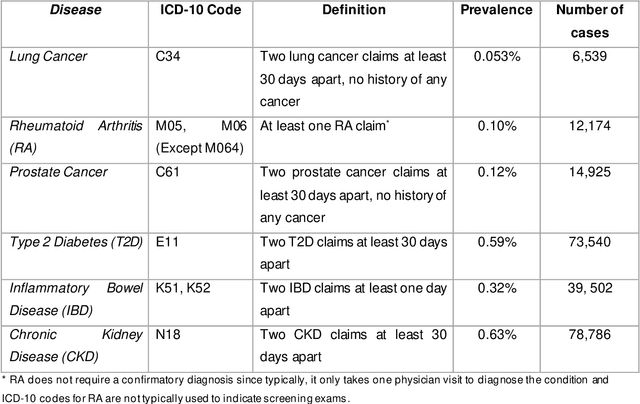
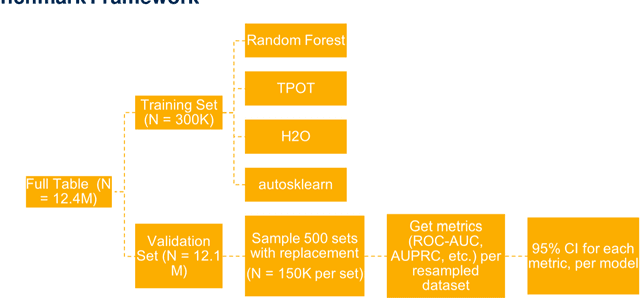
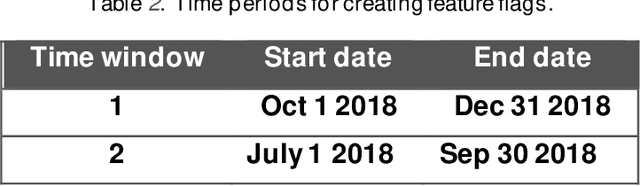
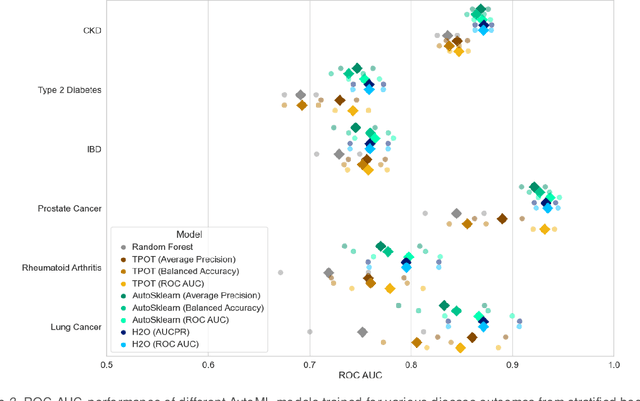
We ascertain and compare the performances of AutoML tools on large, highly imbalanced healthcare datasets. We generated a large dataset using historical administrative claims including demographic information and flags for disease codes in four different time windows prior to 2019. We then trained three AutoML tools on this dataset to predict six different disease outcomes in 2019 and evaluated model performances on several metrics. The AutoML tools showed improvement from the baseline random forest model but did not differ significantly from each other. All models recorded low area under the precision-recall curve and failed to predict true positives while keeping the true negative rate high. Model performance was not directly related to prevalence. We provide a specific use-case to illustrate how to select a threshold that gives the best balance between true and false positive rates, as this is an important consideration in medical applications. Healthcare datasets present several challenges for AutoML tools, including large sample size, high imbalance, and limitations in the available features types. Improvements in scalability, combinations of imbalance-learning resampling and ensemble approaches, and curated feature selection are possible next steps to achieve better performance. Among the three explored, no AutoML tool consistently outperforms the rest in terms of predictive performance. The performances of the models in this study suggest that there may be room for improvement in handling medical claims data. Finally, selection of the optimal prediction threshold should be guided by the specific practical application.
Symmetry meets AI
Mar 10, 2021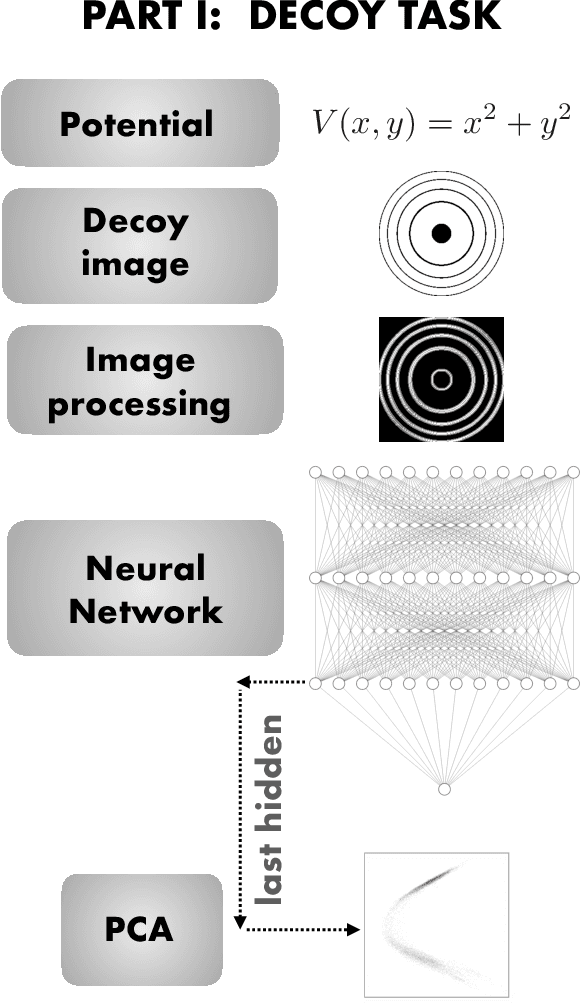

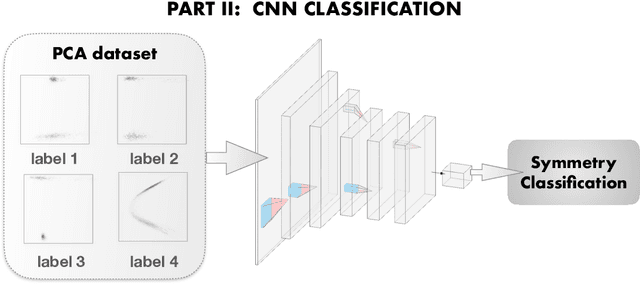
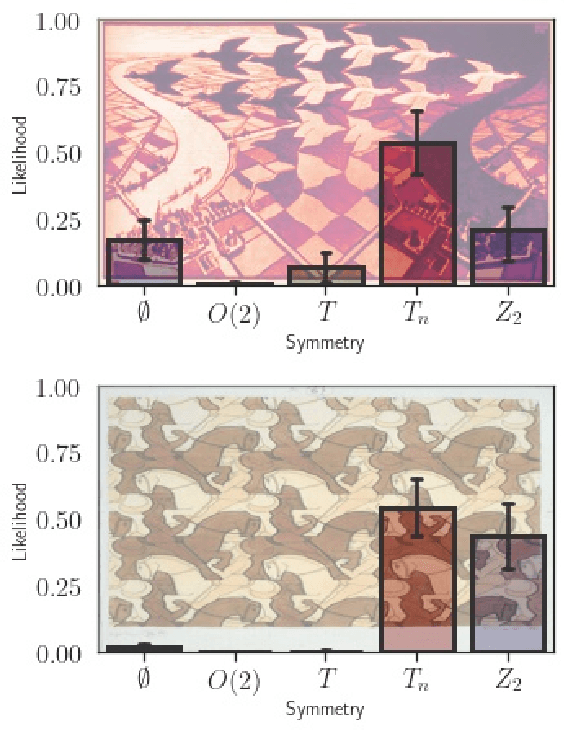
We explore whether Neural Networks (NNs) can {\it discover} the presence of symmetries as they learn to perform a task. For this, we train hundreds of NNs on a {\it decoy task} based on well-controlled Physics templates, where no information on symmetry is provided. We use the output from the last hidden layer of all these NNs, projected to fewer dimensions, as the input for a symmetry classification task, and show that information on symmetry had indeed been identified by the original NN without guidance. As an interdisciplinary application of this procedure, we identify the presence and level of symmetry in artistic paintings from different styles such as those of Picasso, Pollock and Van Gogh.
Variable-rate discrete representation learning
Mar 10, 2021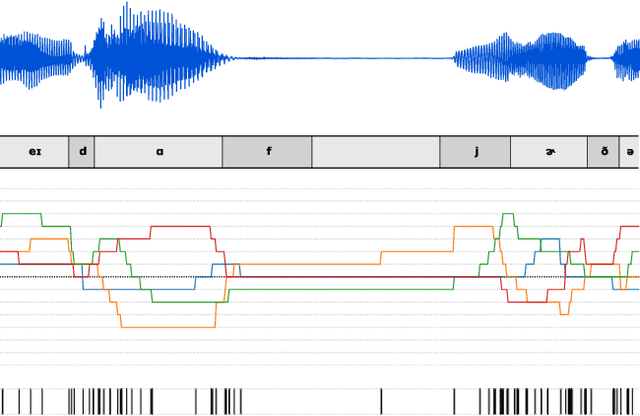

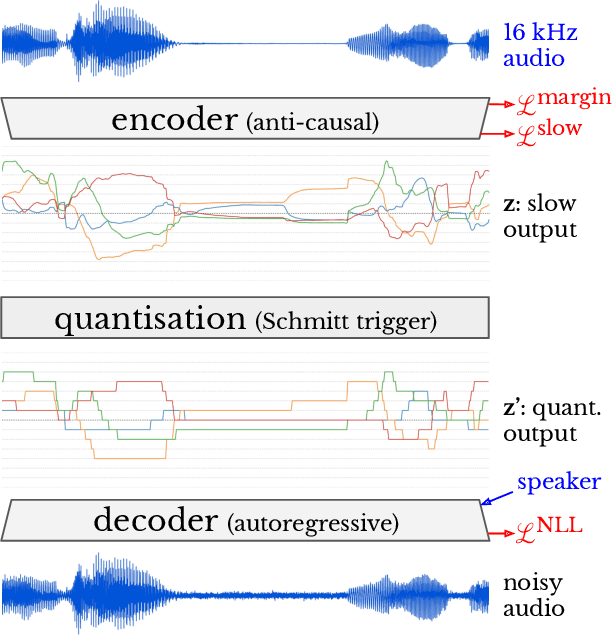

Semantically meaningful information content in perceptual signals is usually unevenly distributed. In speech signals for example, there are often many silences, and the speed of pronunciation can vary considerably. In this work, we propose slow autoencoders (SlowAEs) for unsupervised learning of high-level variable-rate discrete representations of sequences, and apply them to speech. We show that the resulting event-based representations automatically grow or shrink depending on the density of salient information in the input signals, while still allowing for faithful signal reconstruction. We develop run-length Transformers (RLTs) for event-based representation modelling and use them to construct language models in the speech domain, which are able to generate grammatical and semantically coherent utterances and continuations.
A Global to Local Double Embedding Method for Multi-person Pose Estimation
Feb 16, 2021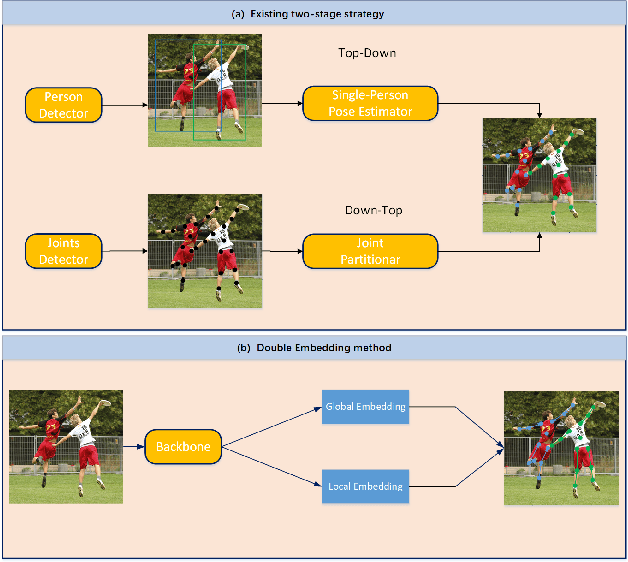
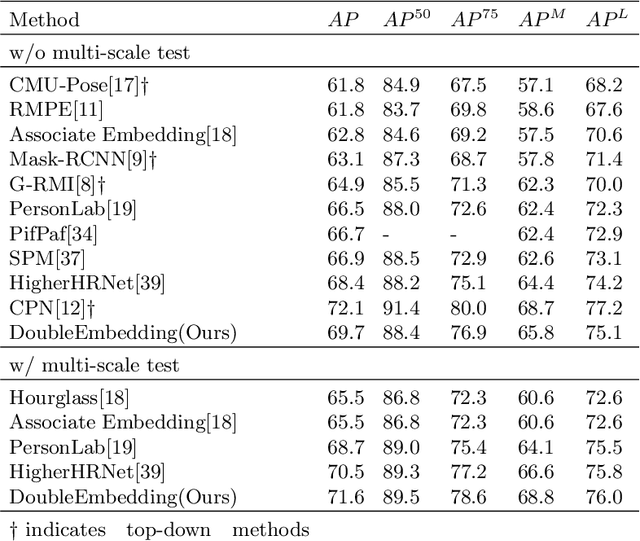
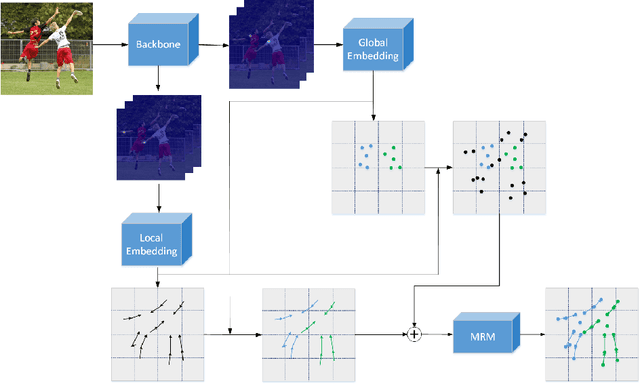
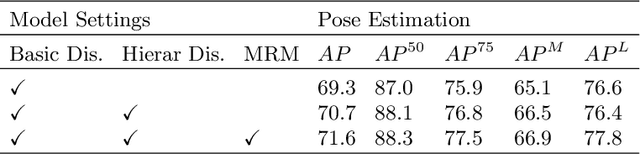
Multi-person pose estimation is a fundamental and challenging problem to many computer vision tasks. Most existing methods can be broadly categorized into two classes: top-down and bottom-up methods. Both of the two types of methods involve two stages, namely, person detection and joints detection. Conventionally, the two stages are implemented separately without considering their interactions between them, and this may inevitably cause some issue intrinsically. In this paper, we present a novel method to simplify the pipeline by implementing person detection and joints detection simultaneously. We propose a Double Embedding (DE) method to complete the multi-person pose estimation task in a global-to-local way. DE consists of Global Embedding (GE) and Local Embedding (LE). GE encodes different person instances and processes information covering the whole image and LE encodes the local limbs information. GE functions for the person detection in top-down strategy while LE connects the rest joints sequentially which functions for joint grouping and information processing in A bottom-up strategy. Based on LE, we design the Mutual Refine Machine (MRM) to reduce the prediction difficulty in complex scenarios. MRM can effectively realize the information communicating between keypoints and further improve the accuracy. We achieve the competitive results on benchmarks MSCOCO, MPII and CrowdPose, demonstrating the effectiveness and generalization ability of our method.
HUMAP: Hierarchical Uniform Manifold Approximation and Projection
Jun 14, 2021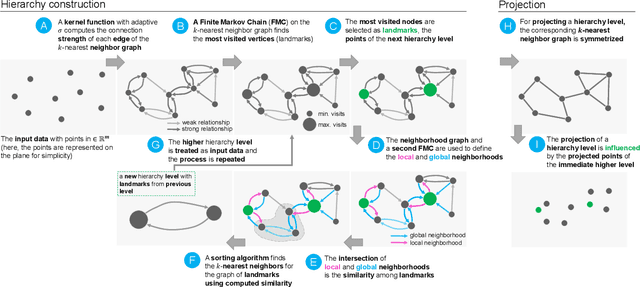

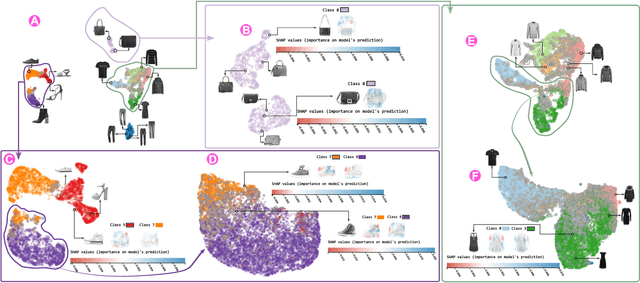
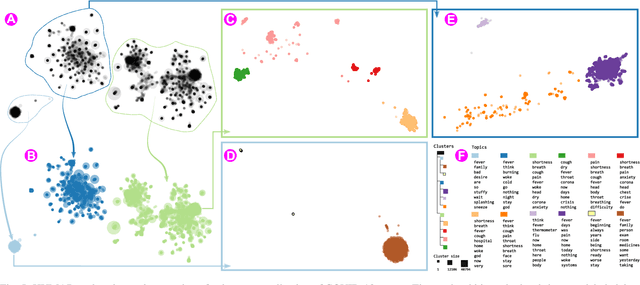
Dimensionality reduction (DR) techniques help analysts to understand patterns in high-dimensional spaces. These techniques, often represented by scatter plots, are employed in diverse science domains and facilitate similarity analysis among clusters and data samples. For datasets containing many granularities or when analysis follows the information visualization mantra, hierarchical DR techniques are the most suitable approach since they present major structures beforehand and details on demand. However, current hierarchical DR techniques are not fully capable of addressing literature problems because they do not preserve the projection mental map across hierarchical levels or are not suitable for most data types. This work presents HUMAP, a novel hierarchical dimensionality reduction technique designed to be flexible on preserving local and global structures and preserve the mental map throughout hierarchical exploration. We provide empirical evidence of our technique's superiority compared with current hierarchical approaches and show two case studies to demonstrate its strengths.
Measuring Model Fairness under Noisy Covariates: A Theoretical Perspective
May 20, 2021
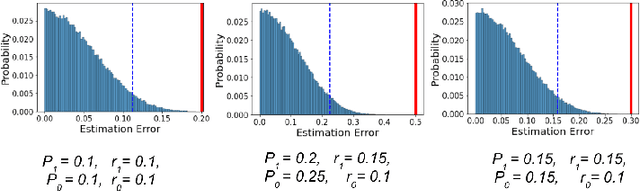
In this work we study the problem of measuring the fairness of a machine learning model under noisy information. Focusing on group fairness metrics, we investigate the particular but common situation when the evaluation requires controlling for the confounding effect of covariate variables. In a practical setting, we might not be able to jointly observe the covariate and group information, and a standard workaround is to then use proxies for one or more of these variables. Prior works have demonstrated the challenges with using a proxy for sensitive attributes, and strong independence assumptions are needed to provide guarantees on the accuracy of the noisy estimates. In contrast, in this work we study using a proxy for the covariate variable and present a theoretical analysis that aims to characterize weaker conditions under which accurate fairness evaluation is possible. Furthermore, our theory identifies potential sources of errors and decouples them into two interpretable parts $\gamma$ and $\epsilon$. The first part $\gamma$ depends solely on the performance of the proxy such as precision and recall, whereas the second part $\epsilon$ captures correlations between all the variables of interest. We show that in many scenarios the error in the estimates is dominated by $\gamma$ via a linear dependence, whereas the dependence on the correlations $\epsilon$ only constitutes a lower order term. As a result we expand the understanding of scenarios where measuring model fairness via proxies can be an effective approach. Finally, we compare, via simulations, the theoretical upper-bounds to the distribution of simulated estimation errors and show that assuming some structure on the data, even weak, is key to significantly improve both theoretical guarantees and empirical results.
Learning Deep Morphological Networks with Neural Architecture Search
Jun 14, 2021

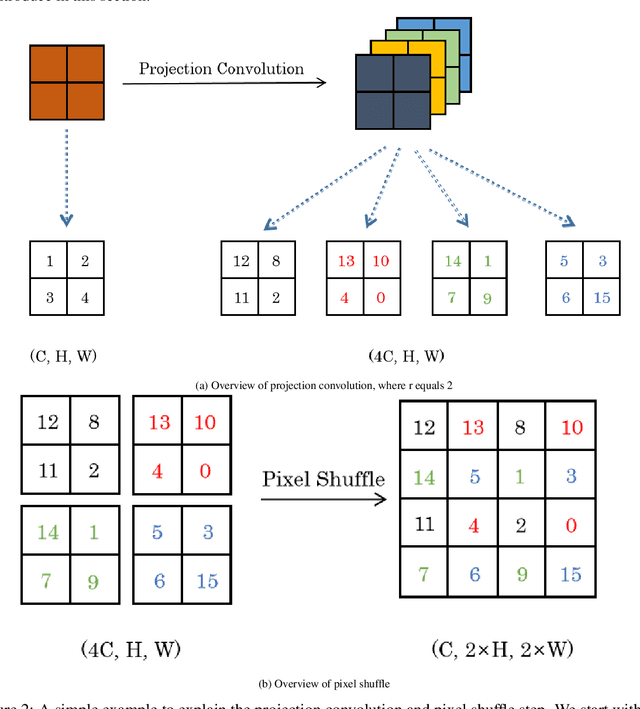

Deep Neural Networks (DNNs) are generated by sequentially performing linear and non-linear processes. Using a combination of linear and non-linear procedures is critical for generating a sufficiently deep feature space. The majority of non-linear operators are derivations of activation functions or pooling functions. Mathematical morphology is a branch of mathematics that provides non-linear operators for a variety of image processing problems. We investigate the utility of integrating these operations in an end-to-end deep learning framework in this paper. DNNs are designed to acquire a realistic representation for a particular job. Morphological operators give topological descriptors that convey salient information about the shapes of objects depicted in images. We propose a method based on meta-learning to incorporate morphological operators into DNNs. The learned architecture demonstrates how our novel morphological operations significantly increase DNN performance on various tasks, including picture classification and edge detection.
PSGAN++: Robust Detail-Preserving Makeup Transfer and Removal
May 26, 2021
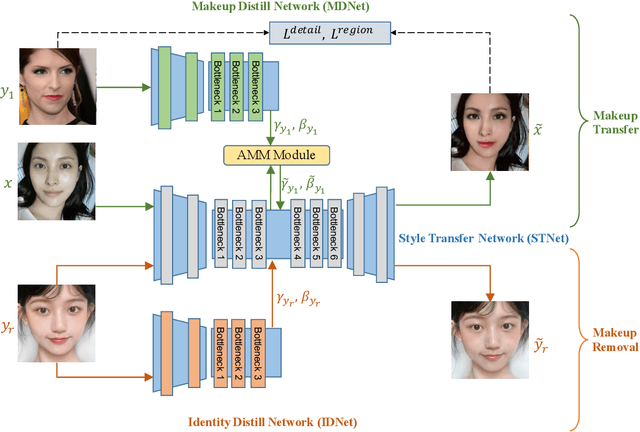
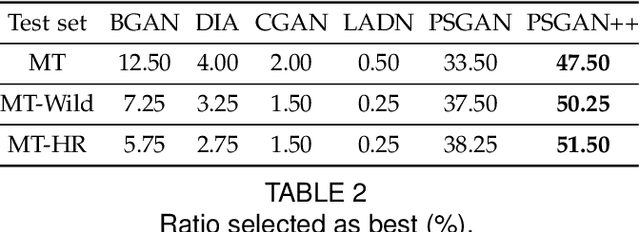
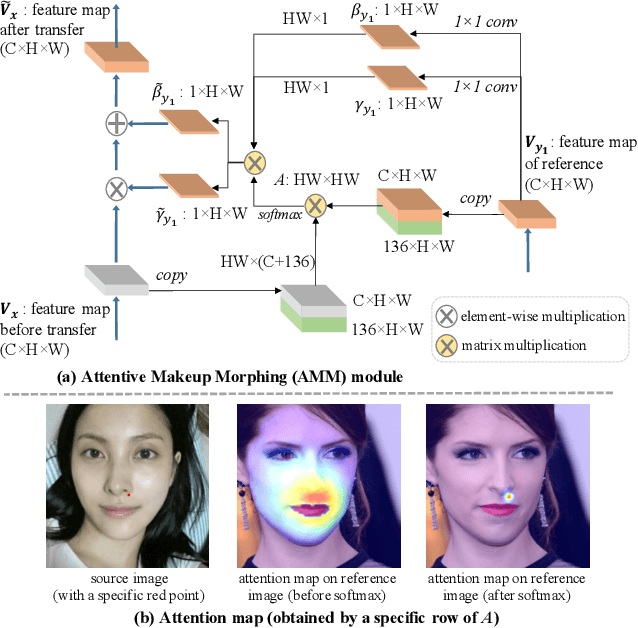
In this paper, we address the makeup transfer and removal tasks simultaneously, which aim to transfer the makeup from a reference image to a source image and remove the makeup from the with-makeup image respectively. Existing methods have achieved much advancement in constrained scenarios, but it is still very challenging for them to transfer makeup between images with large pose and expression differences, or handle makeup details like blush on cheeks or highlight on the nose. In addition, they are hardly able to control the degree of makeup during transferring or to transfer a specified part in the input face. In this work, we propose the PSGAN++, which is capable of performing both detail-preserving makeup transfer and effective makeup removal. For makeup transfer, PSGAN++ uses a Makeup Distill Network to extract makeup information, which is embedded into spatial-aware makeup matrices. We also devise an Attentive Makeup Morphing module that specifies how the makeup in the source image is morphed from the reference image, and a makeup detail loss to supervise the model within the selected makeup detail area. On the other hand, for makeup removal, PSGAN++ applies an Identity Distill Network to embed the identity information from with-makeup images into identity matrices. Finally, the obtained makeup/identity matrices are fed to a Style Transfer Network that is able to edit the feature maps to achieve makeup transfer or removal. To evaluate the effectiveness of our PSGAN++, we collect a Makeup Transfer In the Wild dataset that contains images with diverse poses and expressions and a Makeup Transfer High-Resolution dataset that contains high-resolution images. Experiments demonstrate that PSGAN++ not only achieves state-of-the-art results with fine makeup details even in cases of large pose/expression differences but also can perform partial or degree-controllable makeup transfer.
Is Image-to-Image Translation the Panacea for Multimodal Image Registration? A Comparative Study
Mar 30, 2021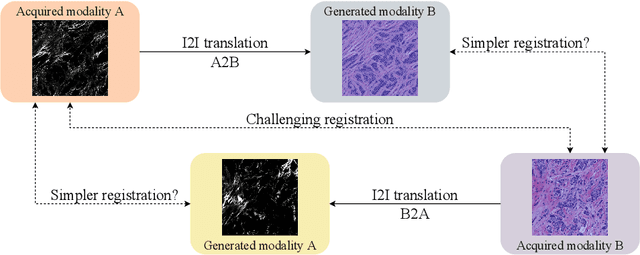
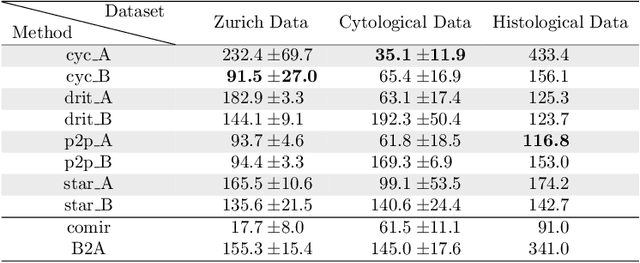

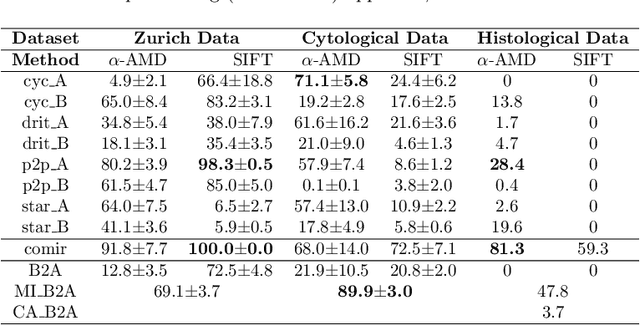
Despite current advancement in the field of biomedical image processing, propelled by the deep learning revolution, multimodal image registration, due to its several challenges, is still often performed manually by specialists. The recent success of image-to-image (I2I) translation in computer vision applications and its growing use in biomedical areas provide a tempting possibility of transforming the multimodal registration problem into a, potentially easier, monomodal one. We conduct an empirical study of the applicability of modern I2I translation methods for the task of multimodal biomedical image registration. We compare the performance of four Generative Adversarial Network (GAN)-based methods and one contrastive representation learning method, subsequently combined with two representative monomodal registration methods, to judge the effectiveness of modality translation for multimodal image registration. We evaluate these method combinations on three publicly available multimodal datasets of increasing difficulty, and compare with the performance of registration by Mutual Information maximisation and one modern data-specific multimodal registration method. Our results suggest that, although I2I translation may be helpful when the modalities to register are clearly correlated, registration of modalities which express distinctly different properties of the sample are not well handled by the I2I translation approach. When less information is shared between the modalities, the I2I translation methods struggle to provide good predictions, which impairs the registration performance. The evaluated representation learning method, which aims to find an in-between representation, manages better, and so does the Mutual Information maximisation approach. We share our complete experimental setup as open-source (https://github.com/Noodles-321/Registration).
Exploration and Incentives in Reinforcement Learning
Feb 28, 2021How do you incentivize self-interested agents to $\textit{explore}$ when they prefer to $\textit{exploit}$ ? We consider complex exploration problems, where each agent faces the same (but unknown) MDP. In contrast with traditional formulations of reinforcement learning, agents control the choice of policies, whereas an algorithm can only issue recommendations. However, the algorithm controls the flow of information, and can incentivize the agents to explore via information asymmetry. We design an algorithm which explores all reachable states in the MDP. We achieve provable guarantees similar to those for incentivizing exploration in static, stateless exploration problems studied previously.