 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIs Image-to-Image Translation the Panacea for Multimodal Image Registration? A Comparative Study
Paper and Code
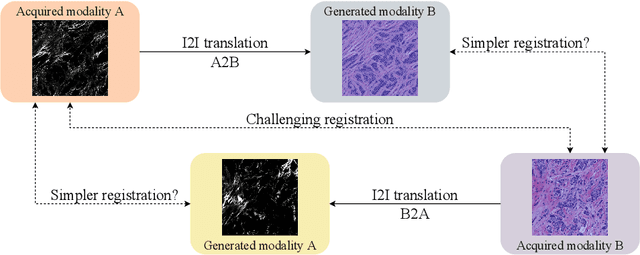
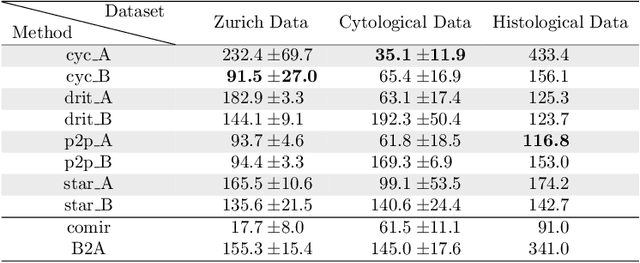

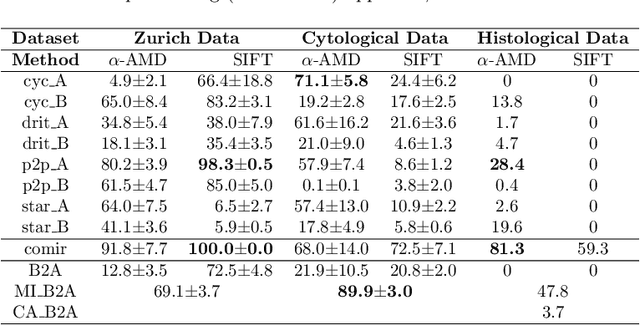
Despite current advancement in the field of biomedical image processing, propelled by the deep learning revolution, multimodal image registration, due to its several challenges, is still often performed manually by specialists. The recent success of image-to-image (I2I) translation in computer vision applications and its growing use in biomedical areas provide a tempting possibility of transforming the multimodal registration problem into a, potentially easier, monomodal one. We conduct an empirical study of the applicability of modern I2I translation methods for the task of multimodal biomedical image registration. We compare the performance of four Generative Adversarial Network (GAN)-based methods and one contrastive representation learning method, subsequently combined with two representative monomodal registration methods, to judge the effectiveness of modality translation for multimodal image registration. We evaluate these method combinations on three publicly available multimodal datasets of increasing difficulty, and compare with the performance of registration by Mutual Information maximisation and one modern data-specific multimodal registration method. Our results suggest that, although I2I translation may be helpful when the modalities to register are clearly correlated, registration of modalities which express distinctly different properties of the sample are not well handled by the I2I translation approach. When less information is shared between the modalities, the I2I translation methods struggle to provide good predictions, which impairs the registration performance. The evaluated representation learning method, which aims to find an in-between representation, manages better, and so does the Mutual Information maximisation approach. We share our complete experimental setup as open-source (https://github.com/Noodles-321/Registration).