 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBenchmarking AutoML Frameworks for Disease Prediction Using Medical Claims
Jul 22, 2021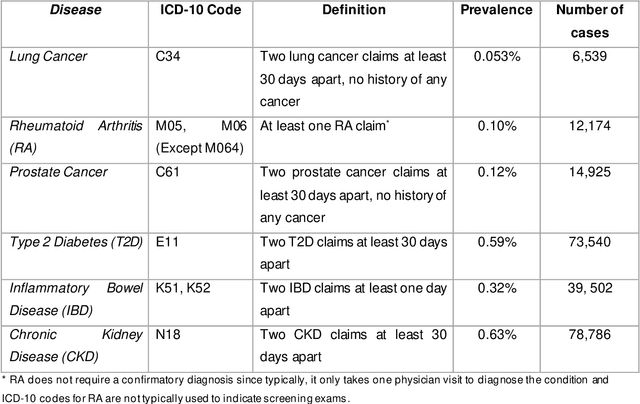
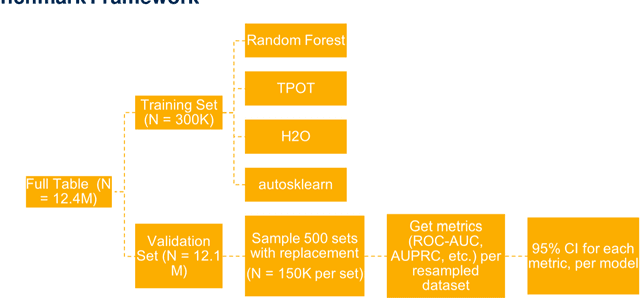
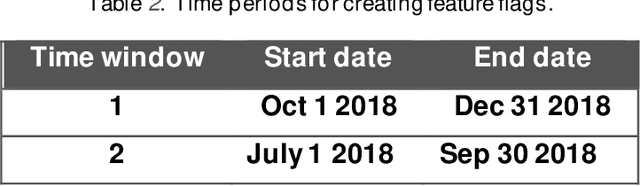
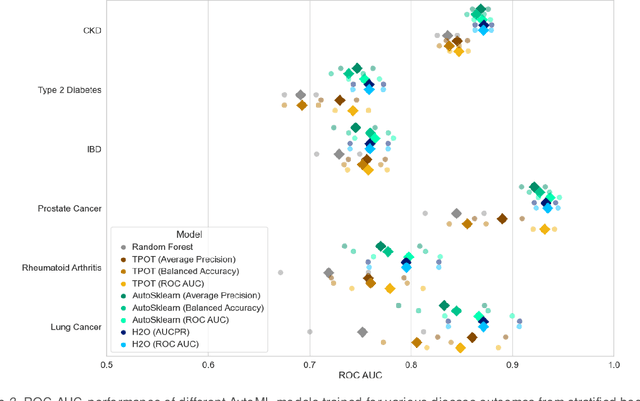
We ascertain and compare the performances of AutoML tools on large, highly imbalanced healthcare datasets. We generated a large dataset using historical administrative claims including demographic information and flags for disease codes in four different time windows prior to 2019. We then trained three AutoML tools on this dataset to predict six different disease outcomes in 2019 and evaluated model performances on several metrics. The AutoML tools showed improvement from the baseline random forest model but did not differ significantly from each other. All models recorded low area under the precision-recall curve and failed to predict true positives while keeping the true negative rate high. Model performance was not directly related to prevalence. We provide a specific use-case to illustrate how to select a threshold that gives the best balance between true and false positive rates, as this is an important consideration in medical applications. Healthcare datasets present several challenges for AutoML tools, including large sample size, high imbalance, and limitations in the available features types. Improvements in scalability, combinations of imbalance-learning resampling and ensemble approaches, and curated feature selection are possible next steps to achieve better performance. Among the three explored, no AutoML tool consistently outperforms the rest in terms of predictive performance. The performances of the models in this study suggest that there may be room for improvement in handling medical claims data. Finally, selection of the optimal prediction threshold should be guided by the specific practical application.
Modeling differential rates of aging using routine laboratory data; Implications for morbidity and health care expenditure
Mar 17, 2021
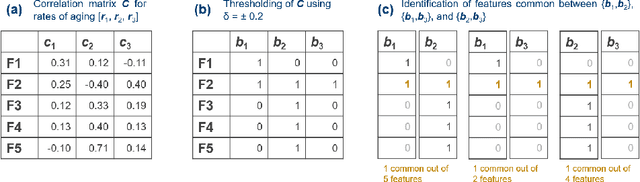
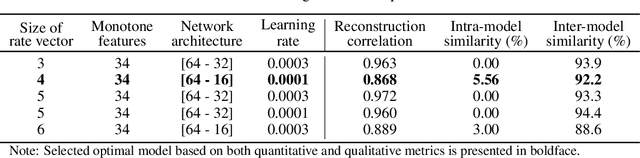
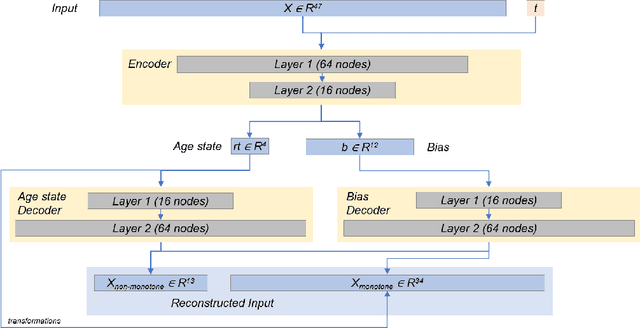
Aging is a multidimensional process where phenotypes change at varying rates. Longitudinal studies of aging typically involve following a cohort of individuals over the course of several years. This design is hindered by cost, attrition, and subsequently small sample size. Alternative methodologies are therefore warranted. In this study, we used a variational autoencoder to estimate rates of aging from cross-sectional data from routine laboratory tests of 1.4 million individuals collected from 2016 to 2019. By incorporating metrics that would ensure model's stability and distinctness of the dimensions, we uncovered four aging dimensions that represent the following bodily functions: 1) kidney, 2) thyroid, 3) white blood cells, and 4) liver and heart. We then examined the relationship between rates of aging on morbidity and health care expenditure. In general, faster agers along these dimensions are more likely to develop chronic diseases that are related to these bodily functions. They also had higher health care expenditures compared to the slower agers. K-means clustering of individuals based on rate of aging revealed that clusters with higher odds of developing morbidity had the highest cost across all types of health care services. Results suggest that cross-sectional laboratory data can be leveraged as an alternative methodology to understand age along the different dimensions. Moreover, rates of aging are differentially related to future costs, which can aid in the development of interventions to delay disease progression.