 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Distilling effective supervision for robust medical image segmentation with noisy labels
Jun 21, 2021
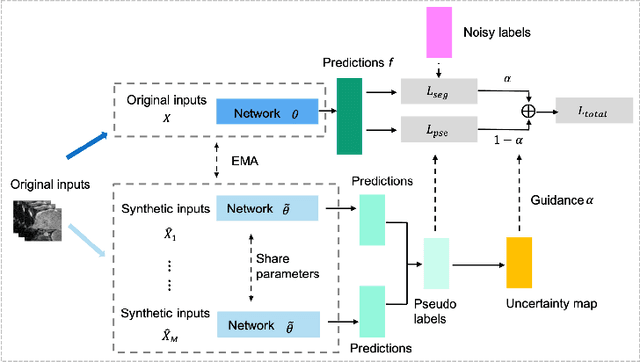
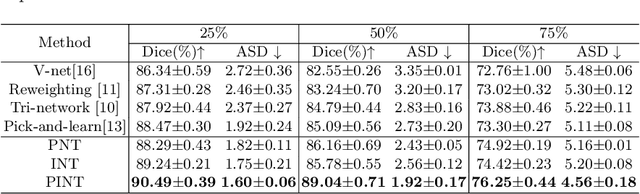
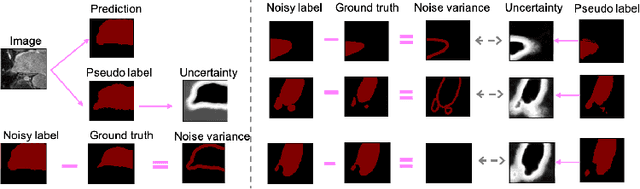
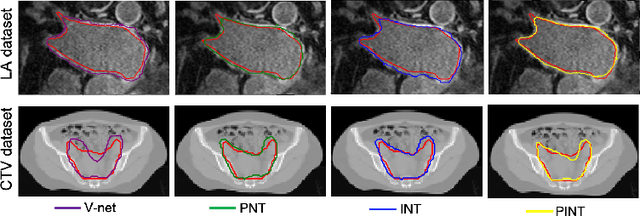
Despite the success of deep learning methods in medical image segmentation tasks, the human-level performance relies on massive training data with high-quality annotations, which are expensive and time-consuming to collect. The fact is that there exist low-quality annotations with label noise, which leads to suboptimal performance of learned models. Two prominent directions for segmentation learning with noisy labels include pixel-wise noise robust training and image-level noise robust training. In this work, we propose a novel framework to address segmenting with noisy labels by distilling effective supervision information from both pixel and image levels. In particular, we explicitly estimate the uncertainty of every pixel as pixel-wise noise estimation, and propose pixel-wise robust learning by using both the original labels and pseudo labels. Furthermore, we present an image-level robust learning method to accommodate more information as the complements to pixel-level learning. We conduct extensive experiments on both simulated and real-world noisy datasets. The results demonstrate the advantageous performance of our method compared to state-of-the-art baselines for medical image segmentation with noisy labels.
SelfDoc: Self-Supervised Document Representation Learning
Jun 07, 2021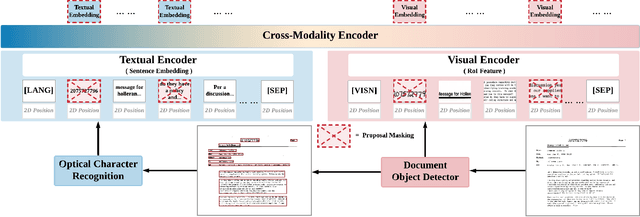
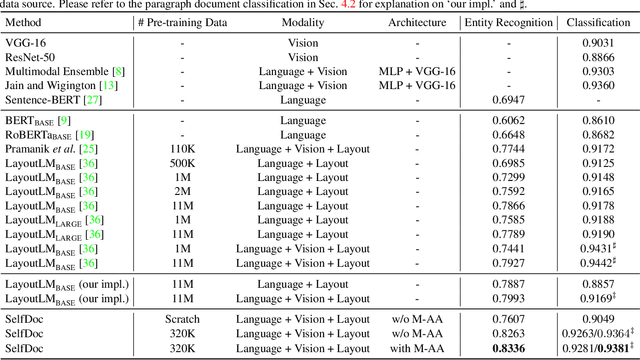
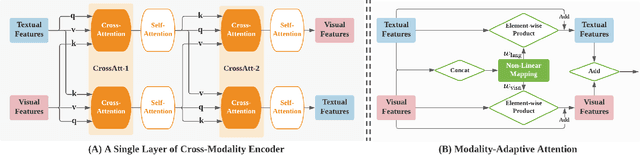

We propose SelfDoc, a task-agnostic pre-training framework for document image understanding. Because documents are multimodal and are intended for sequential reading, our framework exploits the positional, textual, and visual information of every semantically meaningful component in a document, and it models the contextualization between each block of content. Unlike existing document pre-training models, our model is coarse-grained instead of treating individual words as input, therefore avoiding an overly fine-grained with excessive contextualization. Beyond that, we introduce cross-modal learning in the model pre-training phase to fully leverage multimodal information from unlabeled documents. For downstream usage, we propose a novel modality-adaptive attention mechanism for multimodal feature fusion by adaptively emphasizing language and vision signals. Our framework benefits from self-supervised pre-training on documents without requiring annotations by a feature masking training strategy. It achieves superior performance on multiple downstream tasks with significantly fewer document images used in the pre-training stage compared to previous works.
Imitation Learning for Object Manipulation Based on Position/Force Information Using Bilateral Control
Nov 09, 2018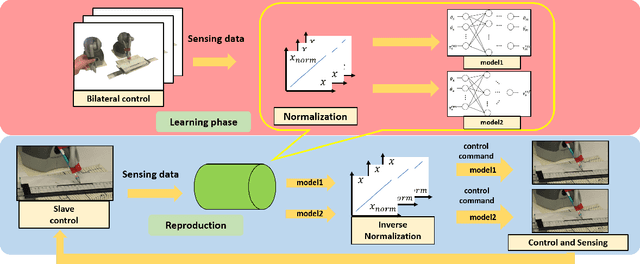

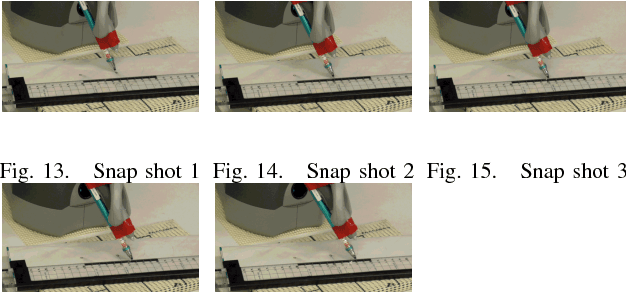
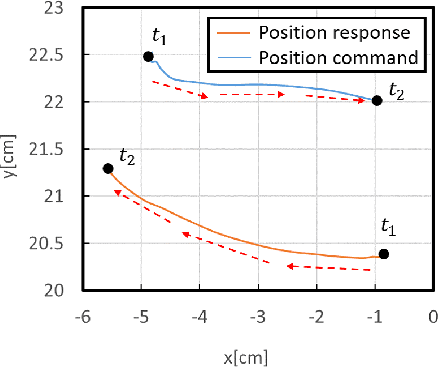
This study proposes an imitation learning method based on force and position information. Force information is required for precise object manipulation but is difficult to obtain because the acting and reaction forces cannnot be separated. To separate the forces, we proposed to introduce bilateral control, in which the acting and reaction forces are divided using two robots. In the proposed method, two models of neural networks learn a task; to draw a line along a ruler. We verify the possibility that force information is essential to imitate the human skill of object manipulation.
* 6 psges, 20 figures
Exploring Periodicity and Interactivity in Multi-Interest Framework for Sequential Recommendation
Jun 07, 2021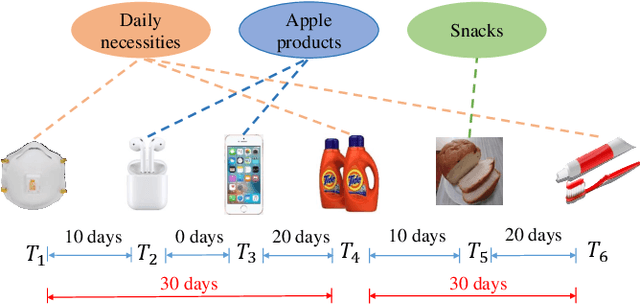

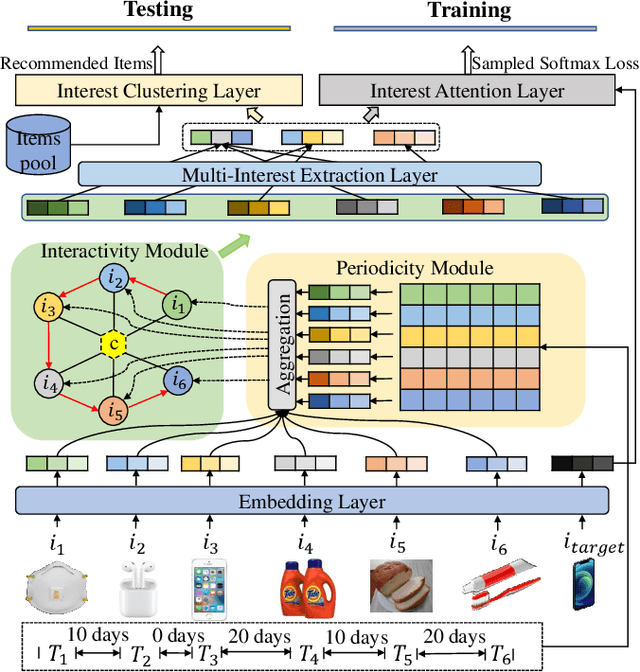

Sequential recommendation systems alleviate the problem of information overload, and have attracted increasing attention in the literature. Most prior works usually obtain an overall representation based on the user's behavior sequence, which can not sufficiently reflect the multiple interests of the user. To this end, we propose a novel method called PIMI to mitigate this issue. PIMI can model the user's multi-interest representation effectively by considering both the periodicity and interactivity in the item sequence. Specifically, we design a periodicity-aware module to utilize the time interval information between user's behaviors. Meanwhile, an ingenious graph is proposed to enhance the interactivity between items in user's behavior sequence, which can capture both global and local item features. Finally, a multi-interest extraction module is applied to describe user's multiple interests based on the obtained item representation. Extensive experiments on two real-world datasets Amazon and Taobao show that PIMI outperforms state-of-the-art methods consistently.
Video Salient Object Detection via Adaptive Local-Global Refinement
May 12, 2021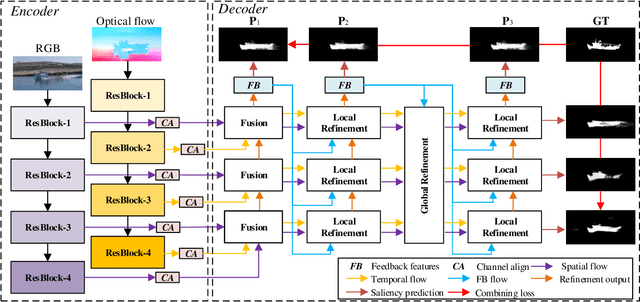
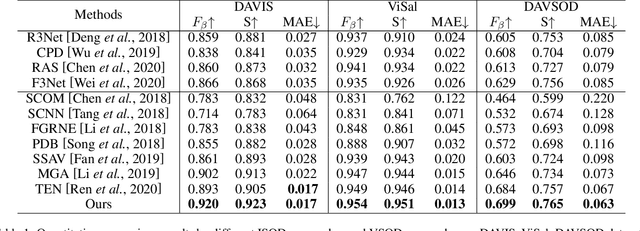
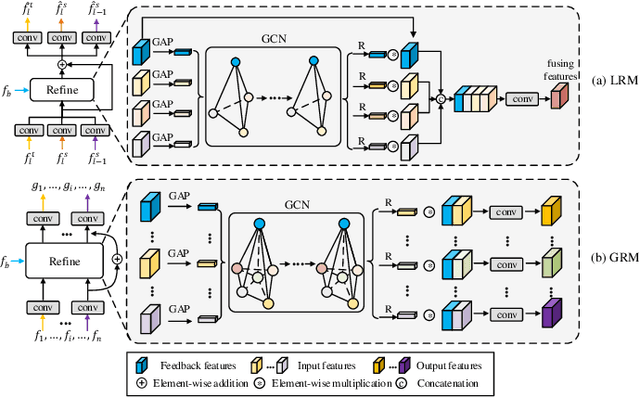

Video salient object detection (VSOD) is an important task in many vision applications. Reliable VSOD requires to simultaneously exploit the information from both the spatial domain and the temporal domain. Most of the existing algorithms merely utilize simple fusion strategies, such as addition and concatenation, to merge the information from different domains. Despite their simplicity, such fusion strategies may introduce feature redundancy, and also fail to fully exploit the relationship between multi-level features extracted from both spatial and temporal domains. In this paper, we suggest an adaptive local-global refinement framework for VSOD. Different from previous approaches, we propose a local refinement architecture and a global one to refine the simply fused features with different scopes, which can fully explore the local dependence and the global dependence of multi-level features. In addition, to emphasize the effective information and suppress the useless one, an adaptive weighting mechanism is designed based on graph convolutional neural network (GCN). We show that our weighting methodology can further exploit the feature correlations, thus driving the network to learn more discriminative feature representation. Extensive experimental results on public video datasets demonstrate the superiority of our method over the existing ones.
Learning Complex Users' Preferences for Recommender Systems
Jul 04, 2021Recommender systems (RSs) have emerged as very useful tools to help customers with their decision-making process, find items of their interest, and alleviate the information overload problem. There are two different lines of approaches in RSs: (1) general recommenders with the main goal of discovering long-term users' preferences, and (2) sequential recommenders with the main focus of capturing short-term users' preferences in a session of user-item interaction (here, a session refers to a record of purchasing multiple items in one shopping event). While considering short-term users' preferences may satisfy their current needs and interests, long-term users' preferences provide users with the items that they may interact with, eventually. In this thesis, we first focus on improving the performance of general RSs. Most of the existing general RSs tend to exploit the users' rating patterns on common items to detect similar users. The data sparsity problem (i.e. the lack of available information) is one of the major challenges for the current general RSs, and they may fail to have any recommendations when there are no common items of interest among users. We call this problem data sparsity with no feedback on common items (DSW-n-FCI). To overcome this problem, we propose a personality-based RS in which similar users are identified based on the similarity of their personality traits.
SplitGuard: Detecting and Mitigating Training-Hijacking Attacks in Split Learning
Aug 23, 2021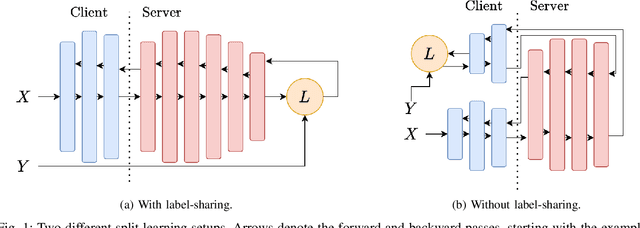
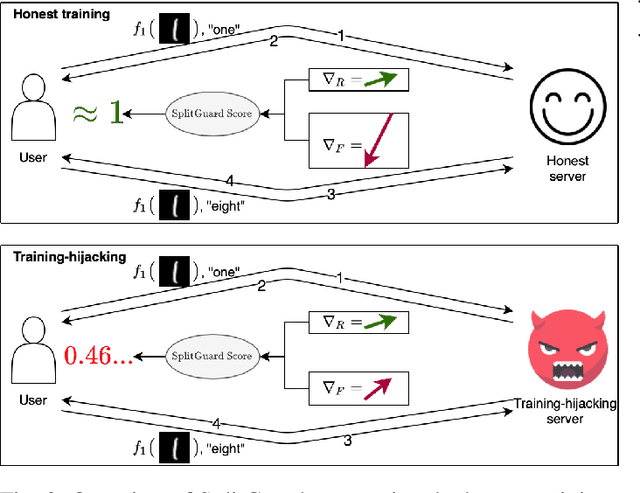
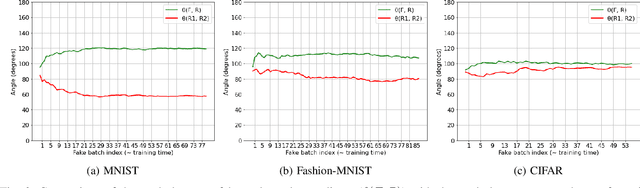
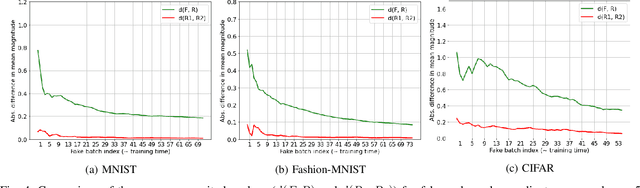
Distributed deep learning frameworks, such as split learning, have recently been proposed to enable a group of participants to collaboratively train a deep neural network without sharing their raw data. Split learning in particular achieves this goal by dividing a neural network between a client and a server so that the client computes the initial set of layers, and the server computes the rest. However, this method introduces a unique attack vector for a malicious server attempting to steal the client's private data: the server can direct the client model towards learning a task of its choice. With a concrete example already proposed, such training-hijacking attacks present a significant risk for the data privacy of split learning clients. In this paper, we propose SplitGuard, a method by which a split learning client can detect whether it is being targeted by a training-hijacking attack or not. We experimentally evaluate its effectiveness, and discuss in detail various points related to its use. We conclude that SplitGuard can effectively detect training-hijacking attacks while minimizing the amount of information recovered by the adversaries.
Multi-behavior Graph Contextual Aware Network for Session-based Recommendation
Sep 24, 2021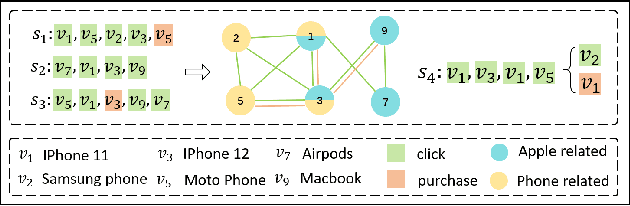
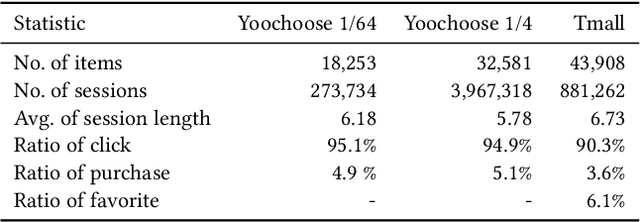
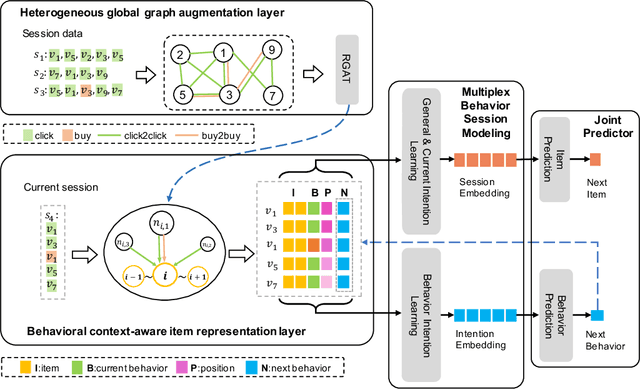
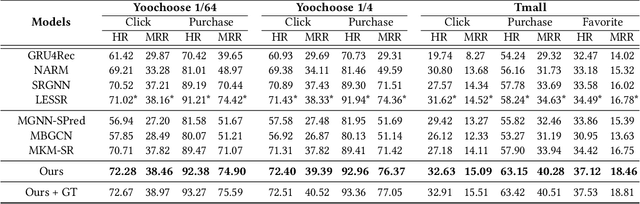
Predicting the next interaction of a short-term sequence is a challenging task in session-based recommendation (SBR).Multi-behavior session recommendation considers session sequence with multiple interaction types, such as click and purchase, to capture more effective user intention representation sufficiently.Despite the superior performance of existing multi-behavior based methods for SBR, there are still several severe limitations:(i) Almost all existing works concentrate on single target type of next behavior and fail to model multiplex behavior sessions uniformly.(ii) Previous methods also ignore the semantic relations between various next behavior and historical behavior sequence, which are significant signals to obtain current latent intention for SBR.(iii) The global cross-session item-item graph established by some existing models may incorporate semantics and context level noise for multi-behavior session-based recommendation. To overcome the limitations (i) and (ii), we propose two novel tasks for SBR, which require the incorporation of both historical behaviors and next behaviors into unified multi-behavior recommendation modeling. To this end, we design a Multi-behavior Graph Contextual Aware Network (MGCNet) for multi-behavior session-based recommendation for the two proposed tasks. Specifically, we build a multi-behavior global item transition graph based on all sessions involving all interaction types. Based on the global graph, MGCNet attaches the global interest representation to final item representation based on local contextual intention to address the limitation (iii). In the end, we utilize the next behavior information explicitly to guide the learning of general interest and current intention for SBR. Experiments on three public benchmark datasets show that MGCNet can outperform state-of-the-art models for multi-behavior session-based recommendation.
A Systematic Investigation of KB-Text Embedding Alignment at Scale
Jun 03, 2021
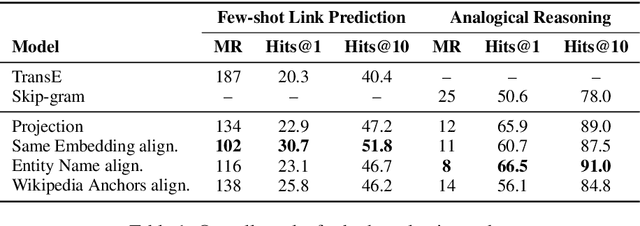
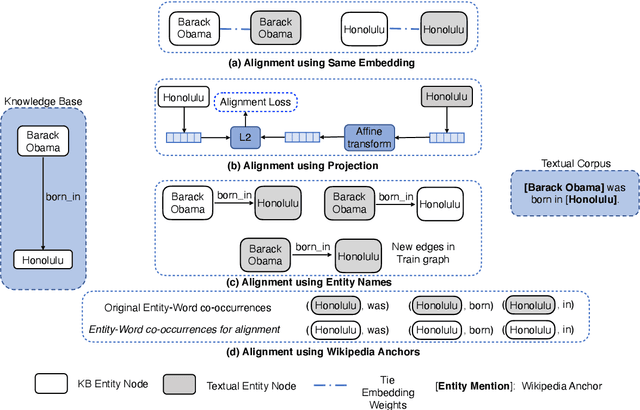
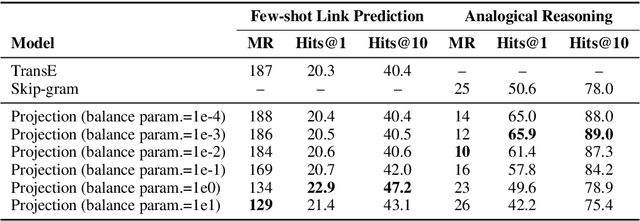
Knowledge bases (KBs) and text often contain complementary knowledge: KBs store structured knowledge that can support long range reasoning, while text stores more comprehensive and timely knowledge in an unstructured way. Separately embedding the individual knowledge sources into vector spaces has demonstrated tremendous successes in encoding the respective knowledge, but how to jointly embed and reason with both knowledge sources to fully leverage the complementary information is still largely an open problem. We conduct a large-scale, systematic investigation of aligning KB and text embeddings for joint reasoning. We set up a novel evaluation framework with two evaluation tasks, few-shot link prediction and analogical reasoning, and evaluate an array of KB-text embedding alignment methods. We also demonstrate how such alignment can infuse textual information into KB embeddings for more accurate link prediction on emerging entities and events, using COVID-19 as a case study.
Analyzing the Granularity and Cost of Annotation in Clinical Sequence Labeling
Aug 23, 2021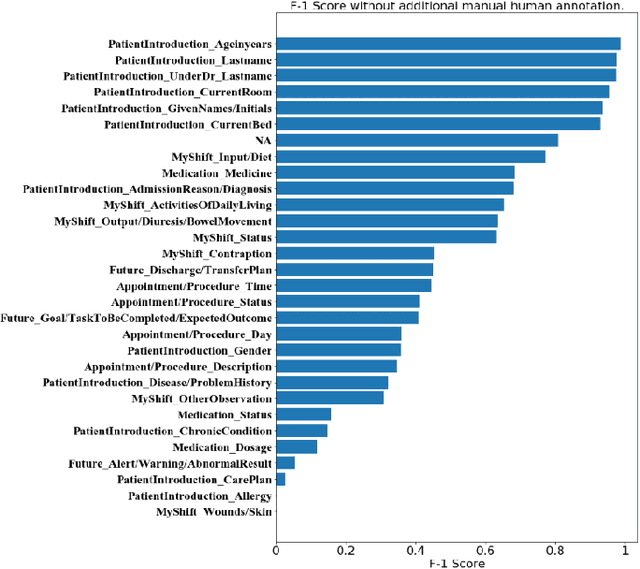
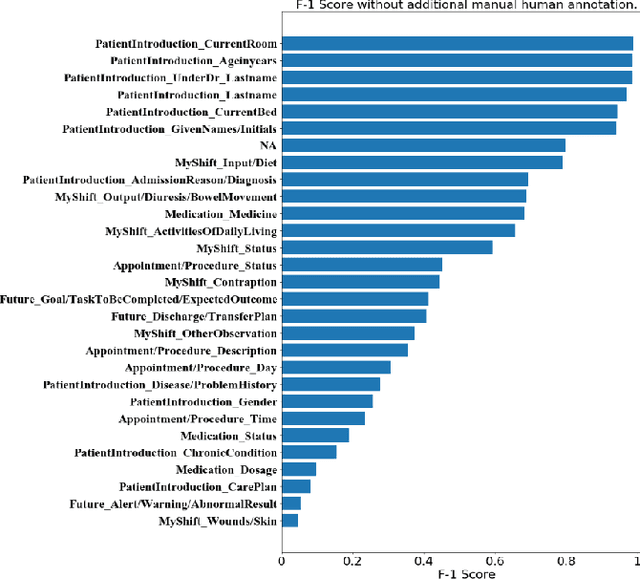
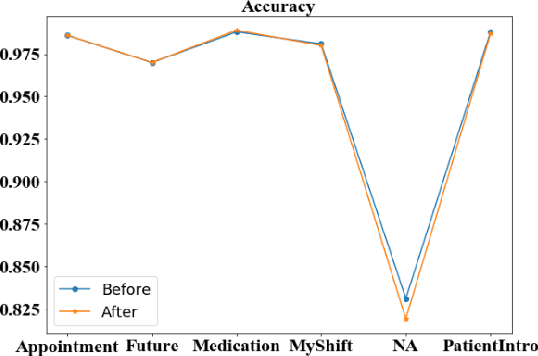
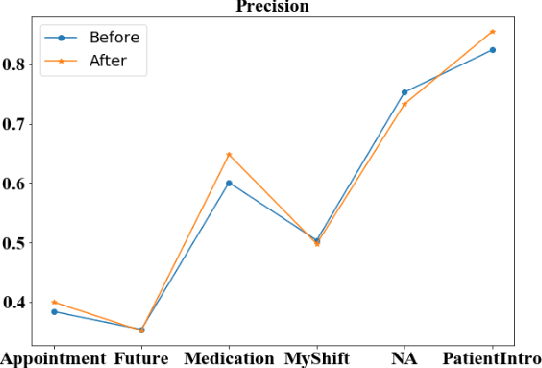
Well-annotated datasets, as shown in recent top studies, are becoming more important for researchers than ever before in supervised machine learning (ML). However, the dataset annotation process and its related human labor costs remain overlooked. In this work, we analyze the relationship between the annotation granularity and ML performance in sequence labeling, using clinical records from nursing shift-change handover. We first study a model derived from textual language features alone, without additional information based on nursing knowledge. We find that this sequence tagger performs well in most categories under this granularity. Then, we further include the additional manual annotations by a nurse, and find the sequence tagging performance remaining nearly the same. Finally, we give a guideline and reference to the community arguing it is not necessary and even not recommended to annotate in detailed granularity because of a low Return on Investment. Therefore we recommend emphasizing other features, like textual knowledge, for researchers and practitioners as a cost-effective source for increasing the sequence labeling performance.