 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
A formal model for ledger management systems based on contracts and temporal logic
Sep 30, 2021
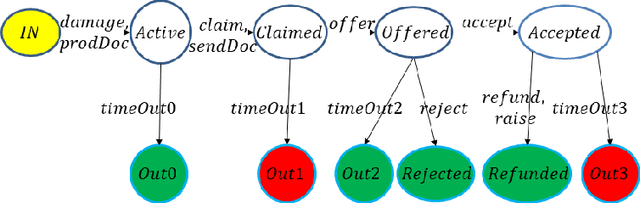
A key component of blockchain technology is the ledger, viz., a database that, unlike standard databases, keeps in memory the complete history of past transactions as in a notarial archive for the benefit of any future test. In second-generation blockchains such as Ethereum the ledger is coupled with smart contracts, which enable the automation of transactions associated with agreements between the parties of a financial or commercial nature. The coupling of smart contracts and ledgers provides the technological background for very innovative application areas, such as Decentralized Autonomous Organizations (DAOs), Initial Coin Offerings (ICOs) and Decentralized Finance (DeFi), which propelled blockchains beyond cryptocurrencies that were the only focus of first generation blockchains such as the Bitcoin. However, the currently used implementation of smart contracts as arbitrary programming constructs has made them susceptible to dangerous bugs that can be exploited maliciously and has moved their semantics away from that of legal contracts. We propose here to recompose the split and recover the reliability of databases by formalizing a notion of contract modelled as a finite-state automaton with well-defined computational characteristics derived from an encoding in terms of allocations of resources to actors, as an alternative to the approach based on programming. To complete the work, we use temporal logic as the basis for an abstract query language that is effectively suited to the historical nature of the information kept in the ledger.
Graph Pooling via Coarsened Graph Infomax
May 04, 2021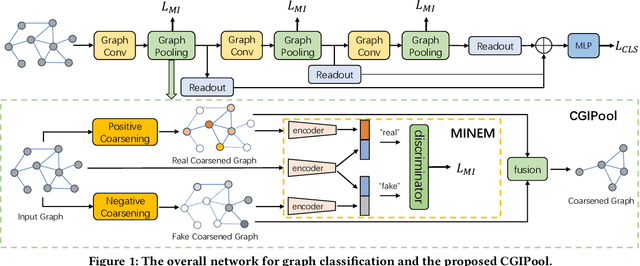
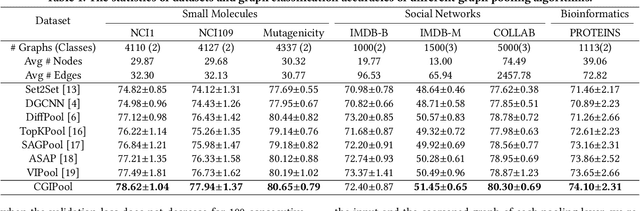
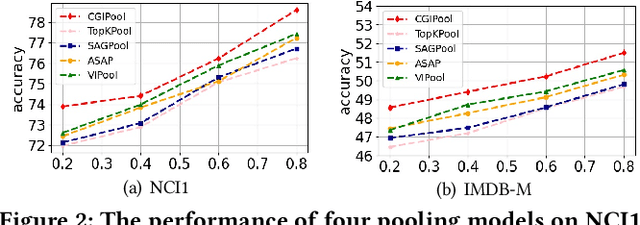
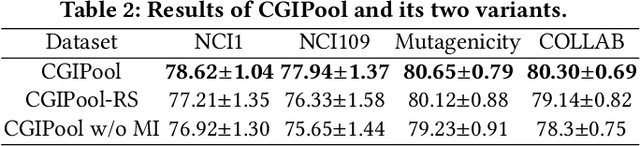
Graph pooling that summaries the information in a large graph into a compact form is essential in hierarchical graph representation learning. Existing graph pooling methods either suffer from high computational complexity or cannot capture the global dependencies between graphs before and after pooling. To address the problems of existing graph pooling methods, we propose Coarsened Graph Infomax Pooling (CGIPool) that maximizes the mutual information between the input and the coarsened graph of each pooling layer to preserve graph-level dependencies. To achieve mutual information neural maximization, we apply contrastive learning and propose a self-attention-based algorithm for learning positive and negative samples. Extensive experimental results on seven datasets illustrate the superiority of CGIPool comparing to the state-of-the-art methods.
Compressing Neural Networks using the Variational Information Bottleneck
Apr 19, 2018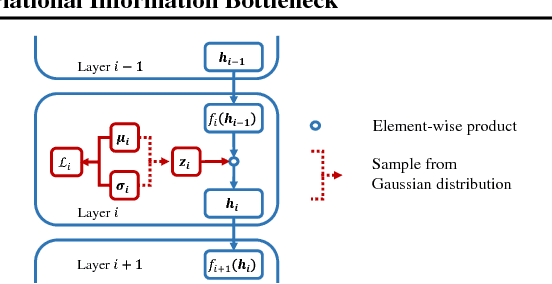
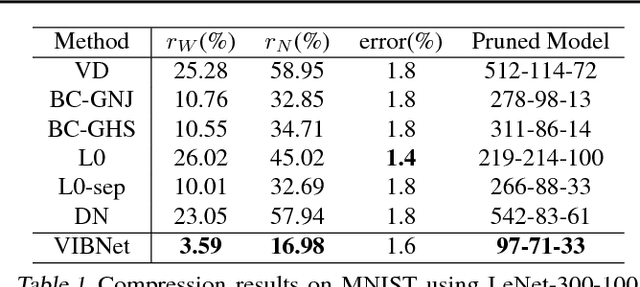
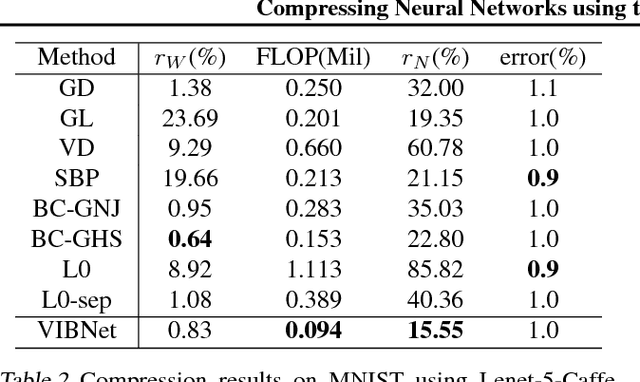
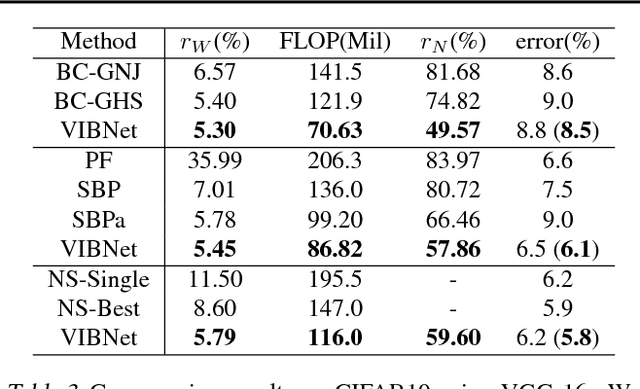
Neural networks can be compressed to reduce memory and computational requirements, or to increase accuracy by facilitating the use of a larger base architecture. In this paper we focus on pruning individual neurons, which can simultaneously trim model size, FLOPs, and run-time memory. To improve upon the performance of existing compression algorithms we utilize the information bottleneck principle instantiated via a tractable variational bound. Minimization of this information theoretic bound reduces the redundancy between adjacent layers by aggregating useful information into a subset of neurons that can be preserved. In contrast, the activations of disposable neurons are shut off via an attractive form of sparse regularization that emerges naturally from this framework, providing tangible advantages over traditional sparsity penalties without contributing additional tuning parameters to the energy landscape. We demonstrate state-of-the-art compression rates across an array of datasets and network architectures.
A Reinforcement Learning Approach for Scheduling in mmWave Networks
Aug 01, 2021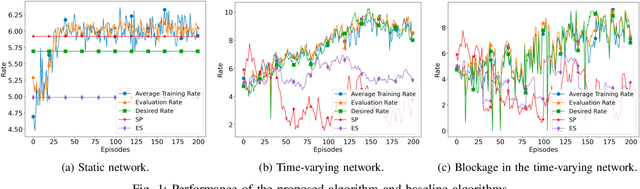
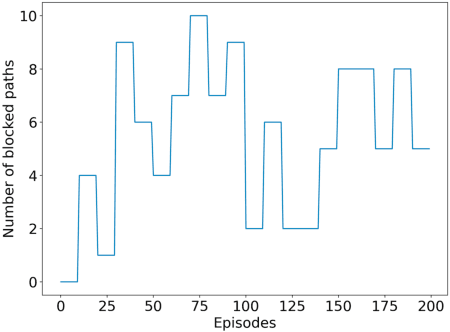
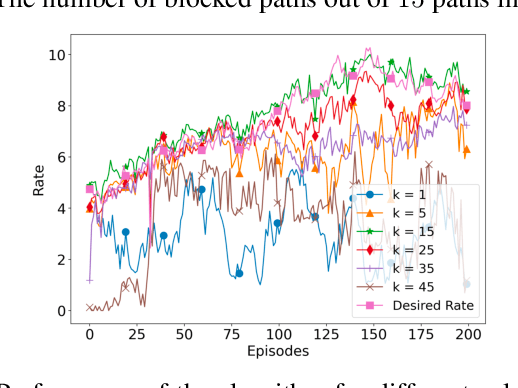
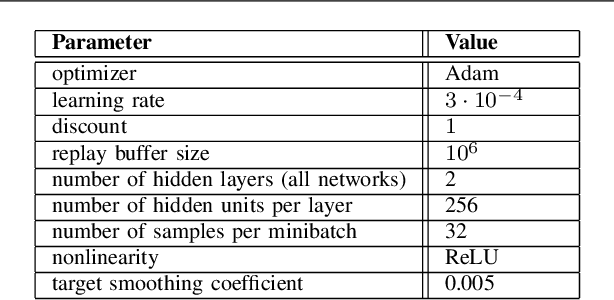
We consider a source that wishes to communicate with a destination at a desired rate, over a mmWave network where links are subject to blockage and nodes to failure (e.g., in a hostile military environment). To achieve resilience to link and node failures, we here explore a state-of-the-art Soft Actor-Critic (SAC) deep reinforcement learning algorithm, that adapts the information flow through the network, without using knowledge of the link capacities or network topology. Numerical evaluations show that our algorithm can achieve the desired rate even in dynamic environments and it is robust against blockage.
Incorporating Lambertian Priors into Surface Normals Measurement
Jul 15, 2021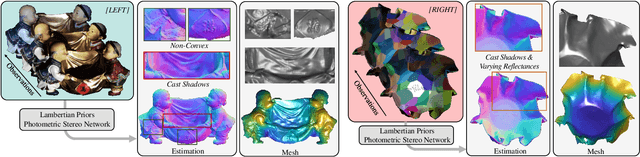
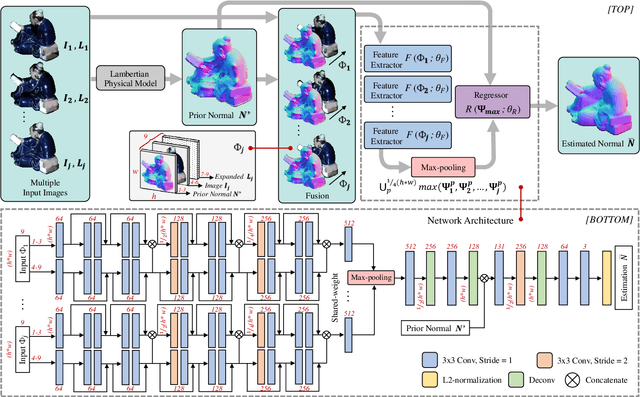
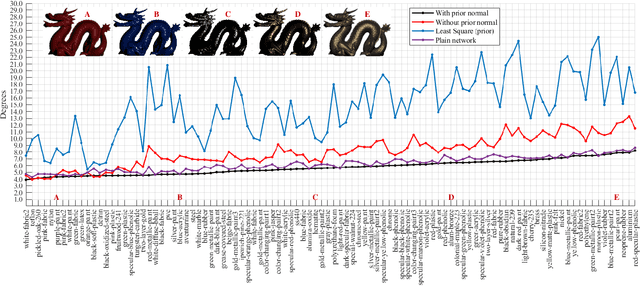
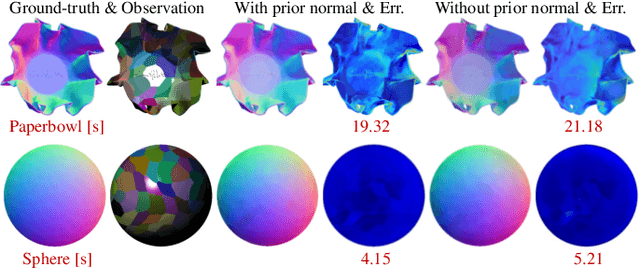
The goal of photometric stereo is to measure the precise surface normal of a 3D object from observations with various shading cues. However, non-Lambertian surfaces influence the measurement accuracy due to irregular shading cues. Despite deep neural networks have been employed to simulate the performance of non-Lambertian surfaces, the error in specularities, shadows, and crinkle regions is hard to be reduced. In order to address this challenge, we here propose a photometric stereo network that incorporates Lambertian priors to better measure the surface normal. In this paper, we use the initial normal under the Lambertian assumption as the prior information to refine the normal measurement, instead of solely applying the observed shading cues to deriving the surface normal. Our method utilizes the Lambertian information to reparameterize the network weights and the powerful fitting ability of deep neural networks to correct these errors caused by general reflectance properties. Our explorations include: the Lambertian priors (1) reduce the learning hypothesis space, making our method learn the mapping in the same surface normal space and improving the accuracy of learning, and (2) provides the differential features learning, improving the surfaces reconstruction of details. Extensive experiments verify the effectiveness of the proposed Lambertian prior photometric stereo network in accurate surface normal measurement, on the challenging benchmark dataset.
Logic-level Evidence Retrieval and Graph-based Verification Network for Table-based Fact Verification
Sep 14, 2021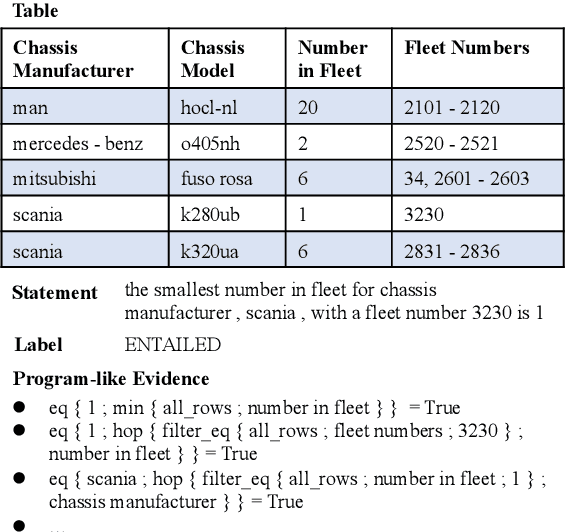
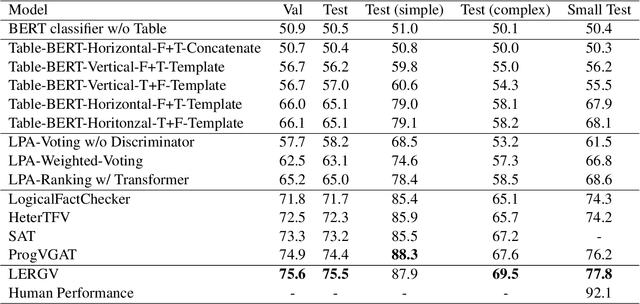
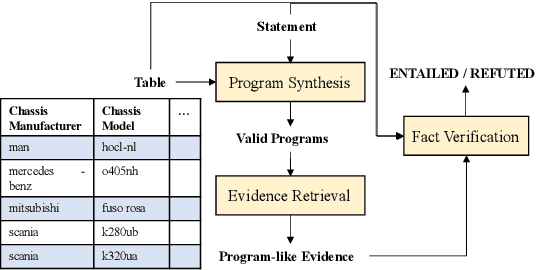

Table-based fact verification task aims to verify whether the given statement is supported by the given semi-structured table. Symbolic reasoning with logical operations plays a crucial role in this task. Existing methods leverage programs that contain rich logical information to enhance the verification process. However, due to the lack of fully supervised signals in the program generation process, spurious programs can be derived and employed, which leads to the inability of the model to catch helpful logical operations. To address the aforementioned problems, in this work, we formulate the table-based fact verification task as an evidence retrieval and reasoning framework, proposing the Logic-level Evidence Retrieval and Graph-based Verification network (LERGV). Specifically, we first retrieve logic-level program-like evidence from the given table and statement as supplementary evidence for the table. After that, we construct a logic-level graph to capture the logical relations between entities and functions in the retrieved evidence, and design a graph-based verification network to perform logic-level graph-based reasoning based on the constructed graph to classify the final entailment relation. Experimental results on the large-scale benchmark TABFACT show the effectiveness of the proposed approach.
Can Language Models Encode Perceptual Structure Without Grounding? A Case Study in Color
Sep 14, 2021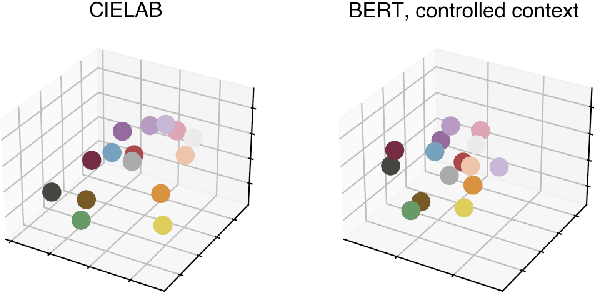

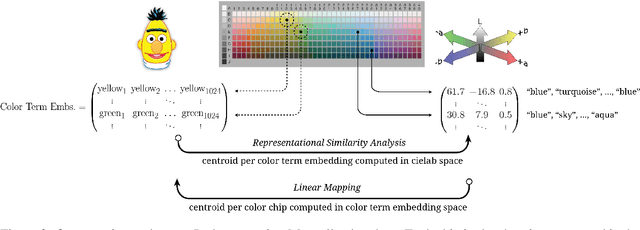
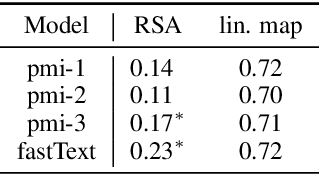
Pretrained language models have been shown to encode relational information, such as the relations between entities or concepts in knowledge-bases -- (Paris, Capital, France). However, simple relations of this type can often be recovered heuristically and the extent to which models implicitly reflect topological structure that is grounded in world, such as perceptual structure, is unknown. To explore this question, we conduct a thorough case study on color. Namely, we employ a dataset of monolexemic color terms and color chips represented in CIELAB, a color space with a perceptually meaningful distance metric. Using two methods of evaluating the structural alignment of colors in this space with text-derived color term representations, we find significant correspondence. Analyzing the differences in alignment across the color spectrum, we find that warmer colors are, on average, better aligned to the perceptual color space than cooler ones, suggesting an intriguing connection to findings from recent work on efficient communication in color naming. Further analysis suggests that differences in alignment are, in part, mediated by collocationality and differences in syntactic usage, posing questions as to the relationship between color perception and usage and context.
MobTCast: Leveraging Auxiliary Trajectory Forecasting for Human Mobility Prediction
Sep 30, 2021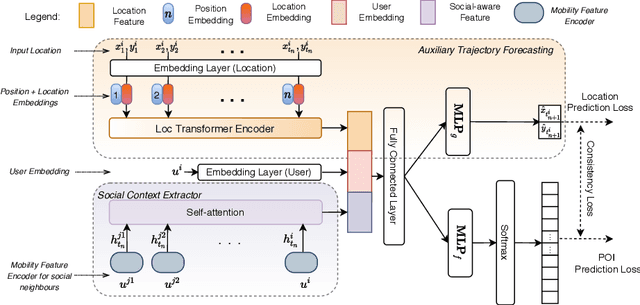
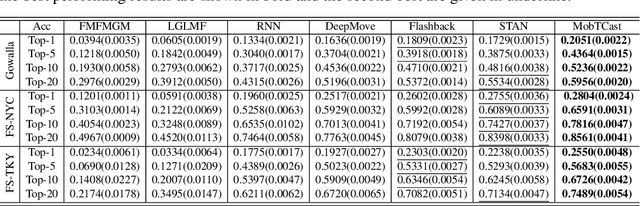
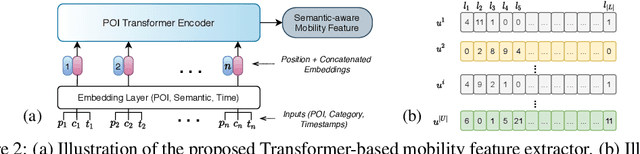
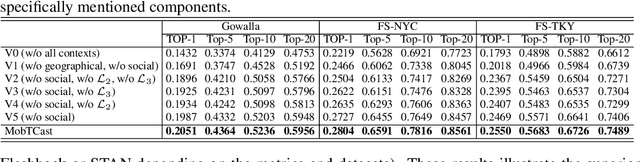
Human mobility prediction is a core functionality in many location-based services and applications. However, due to the sparsity of mobility data, it is not an easy task to predict future POIs (place-of-interests) that are going to be visited. In this paper, we propose MobTCast, a Transformer-based context-aware network for mobility prediction. Specifically, we explore the influence of four types of context in the mobility prediction: temporal, semantic, social and geographical contexts. We first design a base mobility feature extractor using the Transformer architecture, which takes both the history POI sequence and the semantic information as input. It handles both the temporal and semantic contexts. Based on the base extractor and the social connections of a user, we employ a self-attention module to model the influence of the social context. Furthermore, unlike existing methods, we introduce a location prediction branch in MobTCast as an auxiliary task to model the geographical context and predict the next location. Intuitively, the geographical distance between the location of the predicted POI and the predicted location from the auxiliary branch should be as close as possible. To reflect this relation, we design a consistency loss to further improve the POI prediction performance. In our experimental results, MobTCast outperforms other state-of-the-art next POI prediction methods. Our approach illustrates the value of including different types of context in next POI prediction.
DocOIE: A Document-level Context-Aware Dataset for OpenIE
May 11, 2021
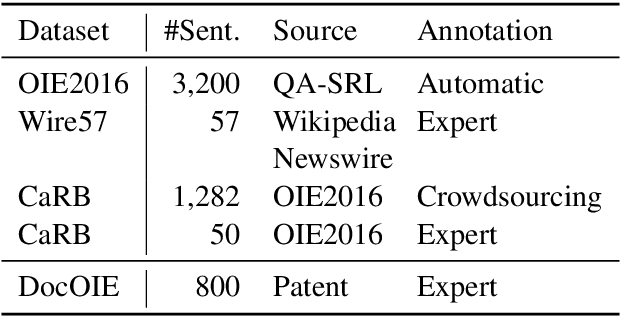
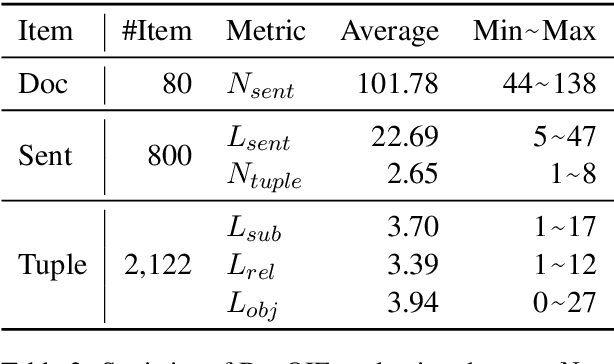
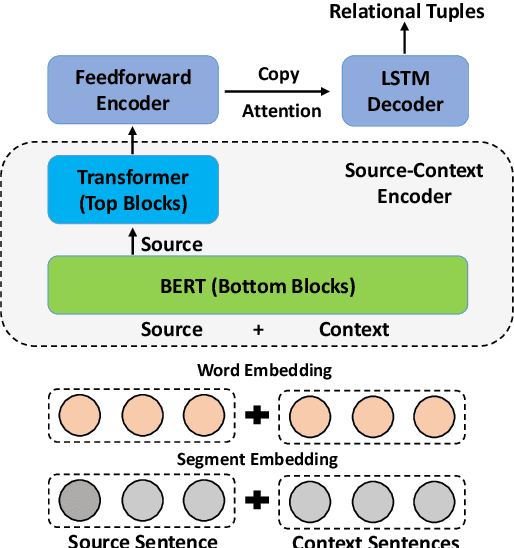
Open Information Extraction (OpenIE) aims to extract structured relational tuples (subject, relation, object) from sentences and plays critical roles for many downstream NLP applications. Existing solutions perform extraction at sentence level, without referring to any additional contextual information. In reality, however, a sentence typically exists as part of a document rather than standalone; we often need to access relevant contextual information around the sentence before we can accurately interpret it. As there is no document-level context-aware OpenIE dataset available, we manually annotate 800 sentences from 80 documents in two domains (Healthcare and Transportation) to form a DocOIE dataset for evaluation. In addition, we propose DocIE, a novel document-level context-aware OpenIE model. Our experimental results based on DocIE demonstrate that incorporating document-level context is helpful in improving OpenIE performance. Both DocOIE dataset and DocIE model are released for public.
RoR: Read-over-Read for Long Document Machine Reading Comprehension
Sep 14, 2021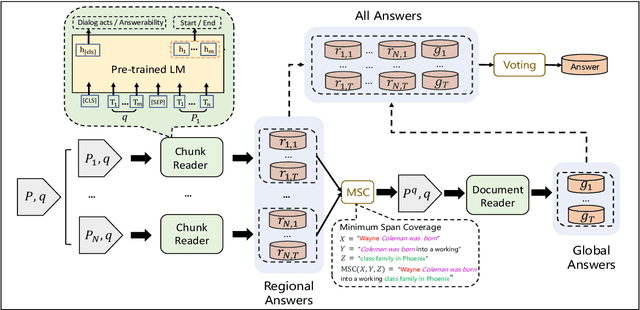
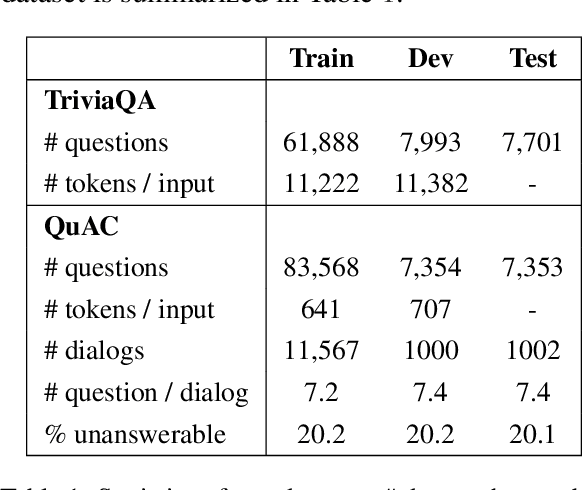
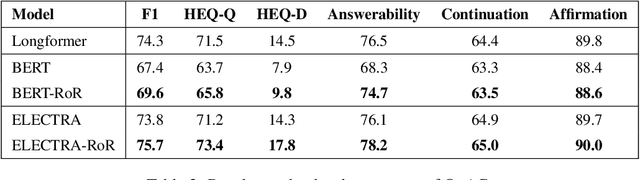
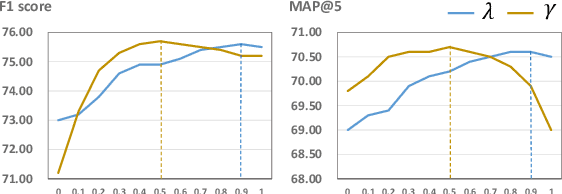
Transformer-based pre-trained models, such as BERT, have achieved remarkable results on machine reading comprehension. However, due to the constraint of encoding length (e.g., 512 WordPiece tokens), a long document is usually split into multiple chunks that are independently read. It results in the reading field being limited to individual chunks without information collaboration for long document machine reading comprehension. To address this problem, we propose RoR, a read-over-read method, which expands the reading field from chunk to document. Specifically, RoR includes a chunk reader and a document reader. The former first predicts a set of regional answers for each chunk, which are then compacted into a highly-condensed version of the original document, guaranteeing to be encoded once. The latter further predicts the global answers from this condensed document. Eventually, a voting strategy is utilized to aggregate and rerank the regional and global answers for final prediction. Extensive experiments on two benchmarks QuAC and TriviaQA demonstrate the effectiveness of RoR for long document reading. Notably, RoR ranks 1st place on the QuAC leaderboard (https://quac.ai/) at the time of submission (May 17th, 2021).