 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
ShufaNet: Classification method for calligraphers who have reached the professional level
Nov 22, 2021

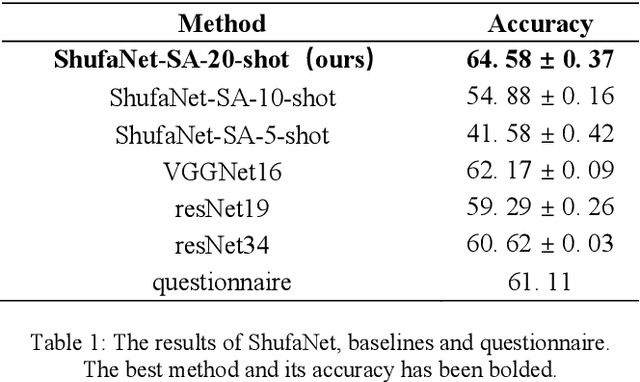

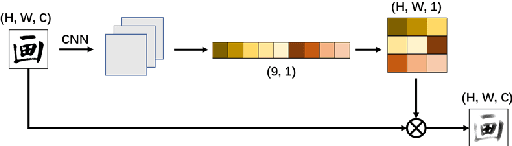
The authenticity of calligraphy is significant but difficult task in the realm of art, where the key problem is the few-shot classification of calligraphy. We propose a novel method, ShufaNet ("Shufa" is the pinyin of Chinese calligraphy), to classify Chinese calligraphers' styles based on metric learning in the case of few-shot, whose classification accuracy exceeds the level of students majoring in calligraphy. We present a new network architecture, including the unique expression of the style of handwriting fonts called ShufaLoss and the calligraphy category information as prior knowledge. Meanwhile, we modify the spatial attention module and create ShufaAttention for handwriting fonts based on the traditional Chinese nine Palace thought. For the training of the model, we build a calligraphers' data set. Our method achieved 65% accuracy rate in our data set for few-shot learning, surpassing resNet and other mainstream CNNs. Meanwhile, we conducted battle for calligraphy major students, and finally surpassed them. This is the first attempt of deep learning in the field of calligrapher classification, and we expect to provide ideas for subsequent research.
ProxyFL: Decentralized Federated Learning through Proxy Model Sharing
Nov 22, 2021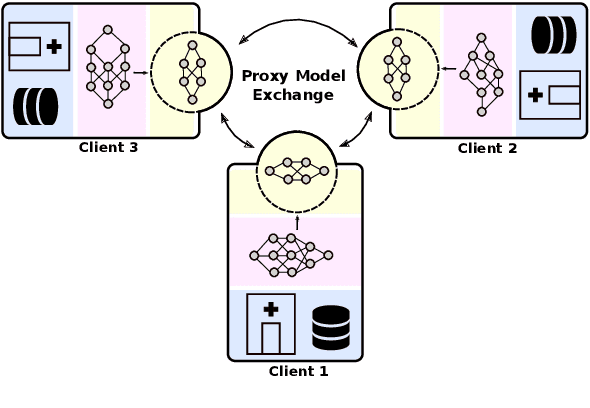
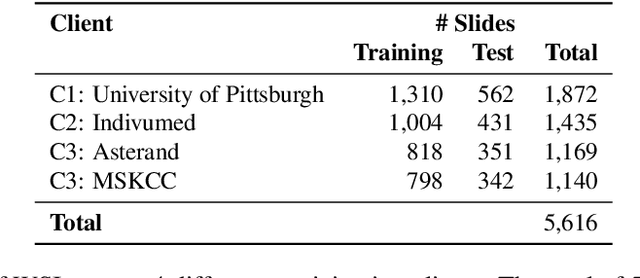
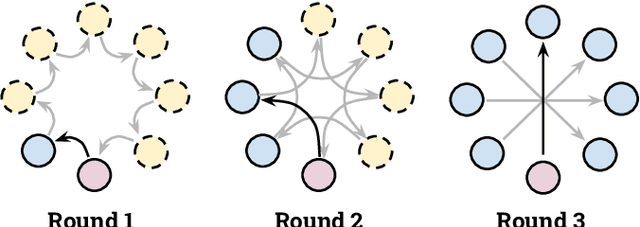
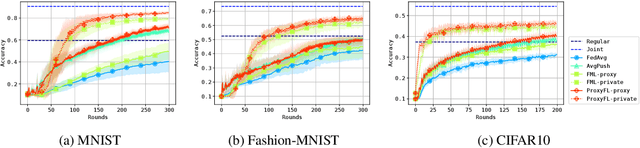
Institutions in highly regulated domains such as finance and healthcare often have restrictive rules around data sharing. Federated learning is a distributed learning framework that enables multi-institutional collaborations on decentralized data with improved protection for each collaborator's data privacy. In this paper, we propose a communication-efficient scheme for decentralized federated learning called ProxyFL, or proxy-based federated learning. Each participant in ProxyFL maintains two models, a private model, and a publicly shared proxy model designed to protect the participant's privacy. Proxy models allow efficient information exchange among participants using the PushSum method without the need of a centralized server. The proposed method eliminates a significant limitation of canonical federated learning by allowing model heterogeneity; each participant can have a private model with any architecture. Furthermore, our protocol for communication by proxy leads to stronger privacy guarantees using differential privacy analysis. Experiments on popular image datasets, and a pan-cancer diagnostic problem using over 30,000 high-quality gigapixel histology whole slide images, show that ProxyFL can outperform existing alternatives with much less communication overhead and stronger privacy.
Unsupervised Domain-Specific Deblurring using Scale-Specific Attention
Dec 12, 2021
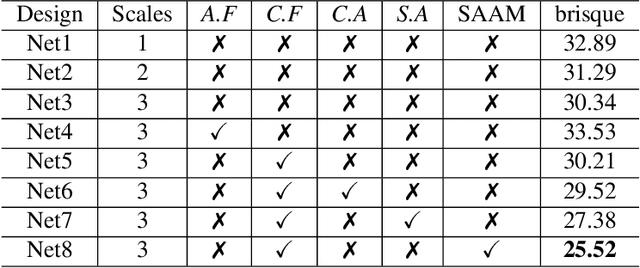
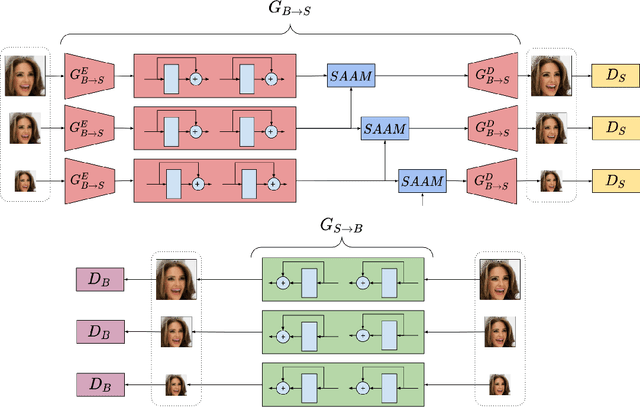
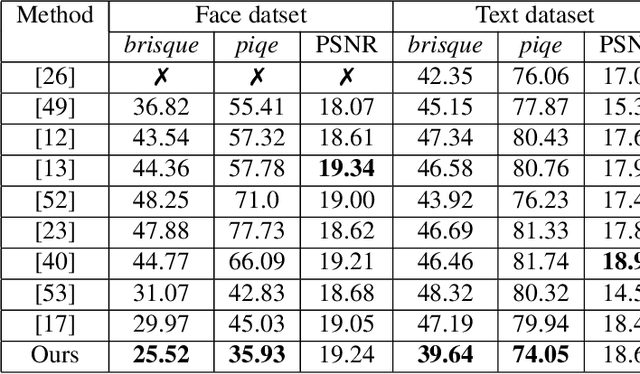
In the literature, coarse-to-fine or scale-recurrent approach i.e. progressively restoring a clean image from its low-resolution versions has been successfully employed for single image deblurring. However, a major disadvantage of existing methods is the need for paired data; i.e. sharpblur image pairs of the same scene, which is a complicated and cumbersome acquisition procedure. Additionally, due to strong supervision on loss functions, pre-trained models of such networks are strongly biased towards the blur experienced during training and tend to give sub-optimal performance when confronted by new blur kernels during inference time. To address the above issues, we propose unsupervised domain-specific deblurring using a scale-adaptive attention module (SAAM). Our network does not require supervised pairs for training, and the deblurring mechanism is primarily guided by adversarial loss, thus making our network suitable for a distribution of blur functions. Given a blurred input image, different resolutions of the same image are used in our model during training and SAAM allows for effective flow of information across the resolutions. For network training at a specific scale, SAAM attends to lower scale features as a function of the current scale. Different ablation studies show that our coarse-to-fine mechanism outperforms end-to-end unsupervised models and SAAM is able to attend better compared to attention models used in literature. Qualitative and quantitative comparisons (on no-reference metrics) show that our method outperforms prior unsupervised methods.
Indexability and Rollout Policy for Multi-State Partially Observable Restless Bandits
Jul 30, 2021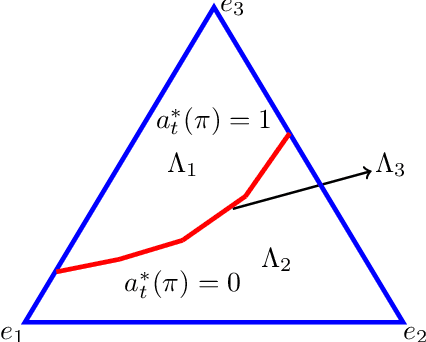
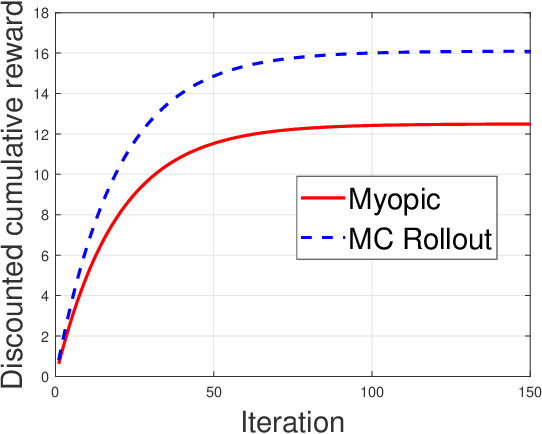
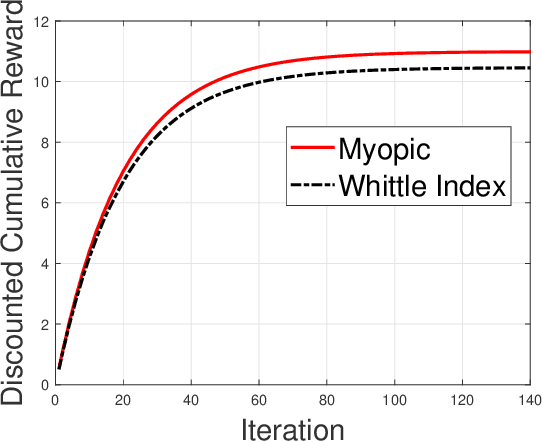
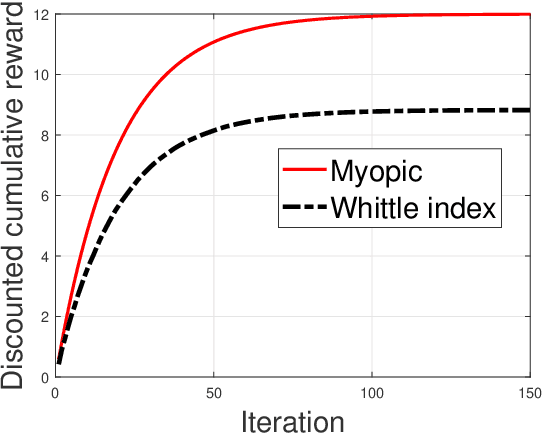
Restless multi-armed bandits with partially observable states has applications in communication systems, age of information and recommendation systems. In this paper, we study multi-state partially observable restless bandit models. We consider three different models based on information observable to decision maker -- 1) no information is observable from actions of a bandit 2) perfect information from bandit is observable only for one action on bandit, there is a fixed restart state, i.e., transition occurs from all other states to that state 3) perfect state information is available to decision maker for both actions on a bandit and there are two restart state for two actions. We develop the structural properties. We also show a threshold type policy and indexability for model 2 and 3. We present Monte Carlo (MC) rollout policy. We use it for whittle index computation in case of model 2. We obtain the concentration bound on value function in terms of horizon length and number of trajectories for MC rollout policy. We derive explicit index formula for model 3. We finally describe Monte Carlo rollout policy for model 1 when it is difficult to show indexability. We demonstrate the numerical examples using myopic policy, Monte Carlo rollout policy and Whittle index policy. We observe that Monte Carlo rollout policy is good competitive policy to myopic.
Multi-Objective Autonomous Exploration on Real-Time Continuous Occupancy Maps
Oct 29, 2021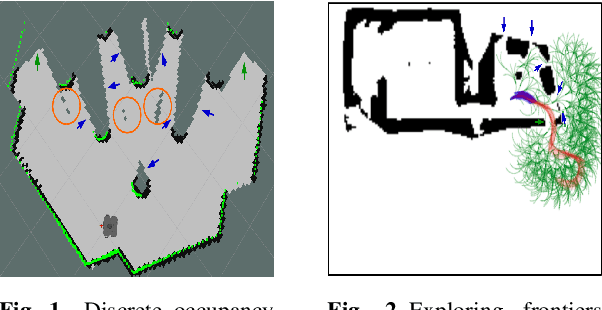
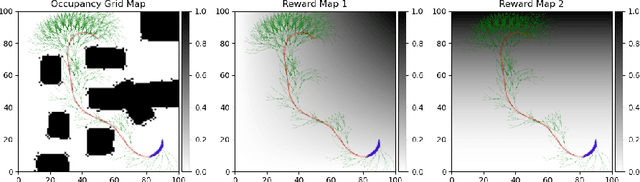


Autonomous exploration in unknown environments using mobile robots is the pillar of many robotic applications. Existing exploration frameworks either select the nearest geometric frontier or the nearest information-theoretic frontier. However, just because a frontier itself is informative does not necessarily mean that the robot will be in an informative area after reaching that frontier. To fill this gap, we propose to use a multi-objective variant of Monte-Carlo tree search that provides a non-myopic Pareto optimal action sequence leading the robot to a frontier with the greatest extent of unknown area uncovering. We also adopted Bayesian Hilbert Map (BHM) for continuous occupancy mapping and made it more applicable to real-time tasks.
Hierarchical transfer learning with applications for electricity load forecasting
Nov 16, 2021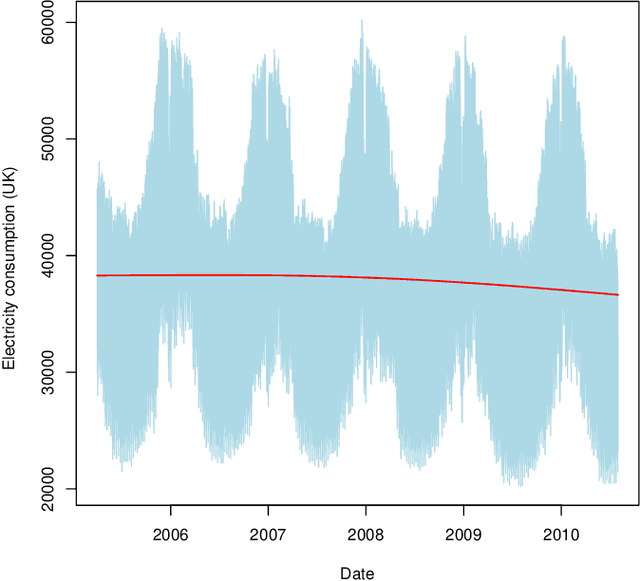

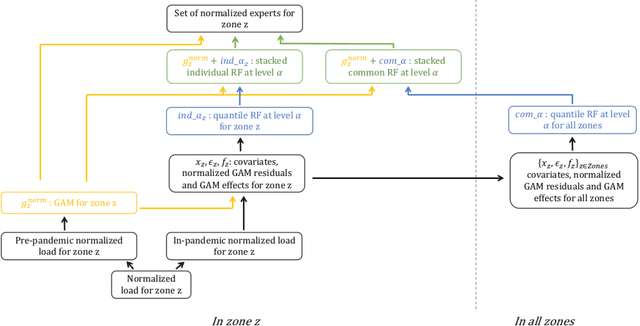

The recent abundance of data on electricity consumption at different scales opens new challenges and highlights the need for new techniques to leverage information present at finer scales in order to improve forecasts at wider scales. In this work, we take advantage of the similarity between this hierarchical prediction problem and multi-scale transfer learning. We develop two methods for hierarchical transfer learning, based respectively on the stacking of generalized additive models and random forests, and on the use of aggregation of experts. We apply these methods to two problems of electricity load forecasting at national scale, using smart meter data in the first case, and regional data in the second case. For these two usecases, we compare the performances of our methods to that of benchmark algorithms, and we investigate their behaviour using variable importance analysis. Our results demonstrate the interest of both methods, which lead to a significant improvement of the predictions.
Auxiliary Learning for Self-Supervised Video Representation via Similarity-based Knowledge Distillation
Dec 07, 2021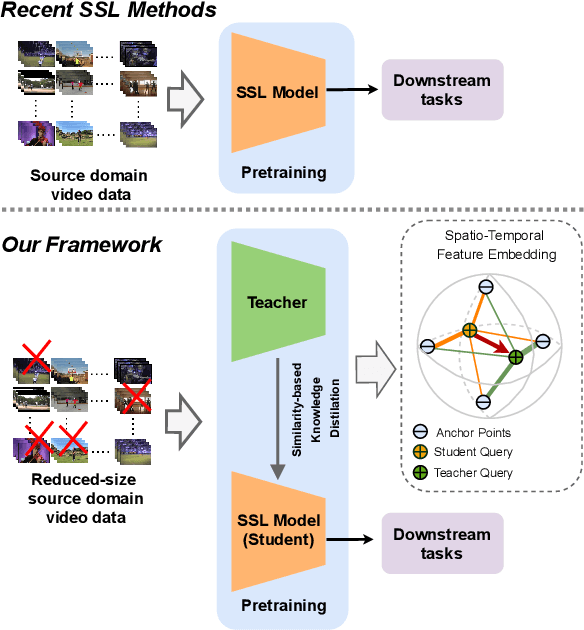
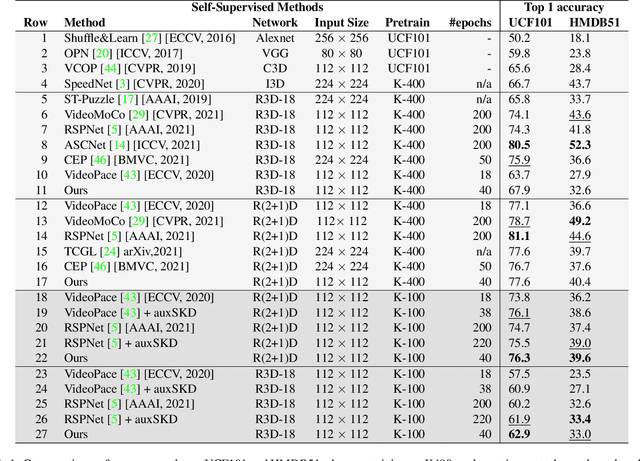
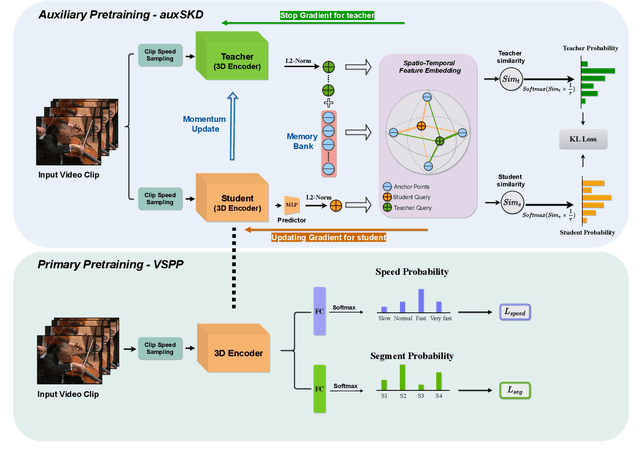
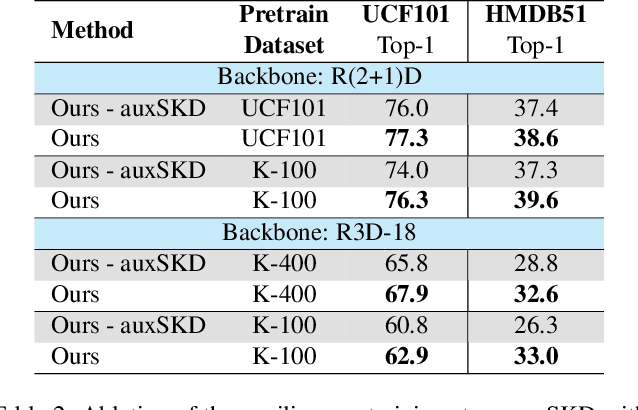
Despite the outstanding success of self-supervised pretraining methods for video representation learning, they generalise poorly when the unlabeled dataset for pretraining is small or the domain difference between unlabelled data in source task (pretraining) and labeled data in target task (finetuning) is significant. To mitigate these issues, we propose a novel approach to complement self-supervised pretraining via an auxiliary pretraining phase, based on knowledge similarity distillation, auxSKD, for better generalisation with a significantly smaller amount of video data, e.g. Kinetics-100 rather than Kinetics-400. Our method deploys a teacher network that iteratively distils its knowledge to the student model by capturing the similarity information between segments of unlabelled video data. The student model then solves a pretext task by exploiting this prior knowledge. We also introduce a novel pretext task, Video Segment Pace Prediction or VSPP, which requires our model to predict the playback speed of a randomly selected segment of the input video to provide more reliable self-supervised representations. Our experimental results show superior results to the state of the art on both UCF101 and HMDB51 datasets when pretraining on K100. Additionally, we show that our auxiliary pertaining, auxSKD, when added as an extra pretraining phase to recent state of the art self-supervised methods (e.g. VideoPace and RSPNet), improves their results on UCF101 and HMDB51. Our code will be released soon.
DelightfulTTS: The Microsoft Speech Synthesis System for Blizzard Challenge 2021
Oct 25, 2021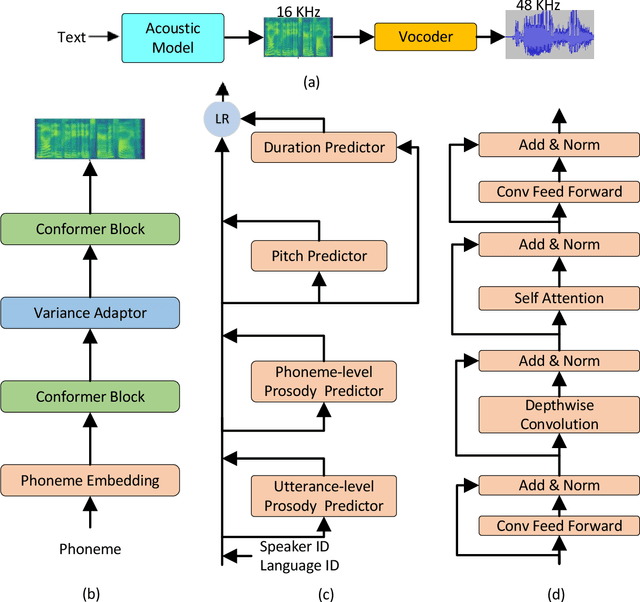
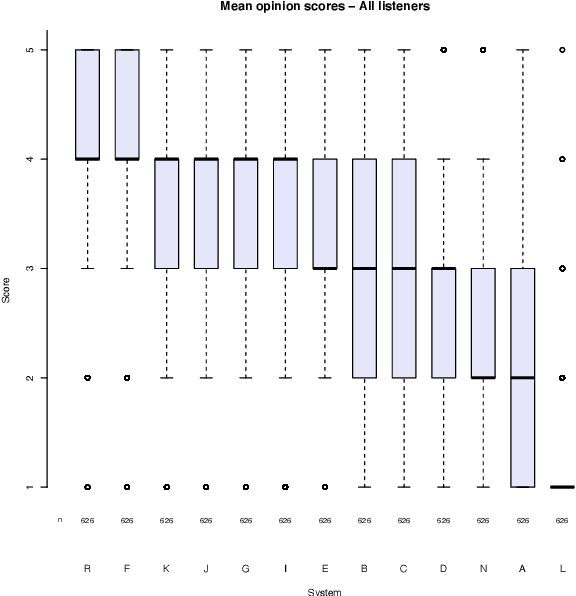
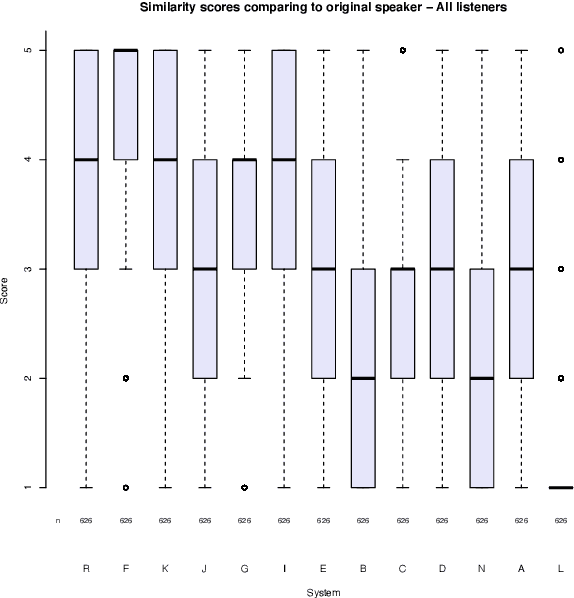
This paper describes the Microsoft end-to-end neural text to speech (TTS) system: DelightfulTTS for Blizzard Challenge 2021. The goal of this challenge is to synthesize natural and high-quality speech from text, and we approach this goal in two perspectives: The first is to directly model and generate waveform in 48 kHz sampling rate, which brings higher perception quality than previous systems with 16 kHz or 24 kHz sampling rate; The second is to model the variation information in speech through a systematic design, which improves the prosody and naturalness. Specifically, for 48 kHz modeling, we predict 16 kHz mel-spectrogram in acoustic model, and propose a vocoder called HiFiNet to directly generate 48 kHz waveform from predicted 16 kHz mel-spectrogram, which can better trade off training efficiency, modelling stability and voice quality. We model variation information systematically from both explicit (speaker ID, language ID, pitch and duration) and implicit (utterance-level and phoneme-level prosody) perspectives: 1) For speaker and language ID, we use lookup embedding in training and inference; 2) For pitch and duration, we extract the values from paired text-speech data in training and use two predictors to predict the values in inference; 3) For utterance-level and phoneme-level prosody, we use two reference encoders to extract the values in training, and use two separate predictors to predict the values in inference. Additionally, we introduce an improved Conformer block to better model the local and global dependency in acoustic model. For task SH1, DelightfulTTS achieves 4.17 mean score in MOS test and 4.35 in SMOS test, which indicates the effectiveness of our proposed system
LMR-CBT: Learning Modality-fused Representations with CB-Transformer for Multimodal Emotion Recognition from Unaligned Multimodal Sequences
Dec 03, 2021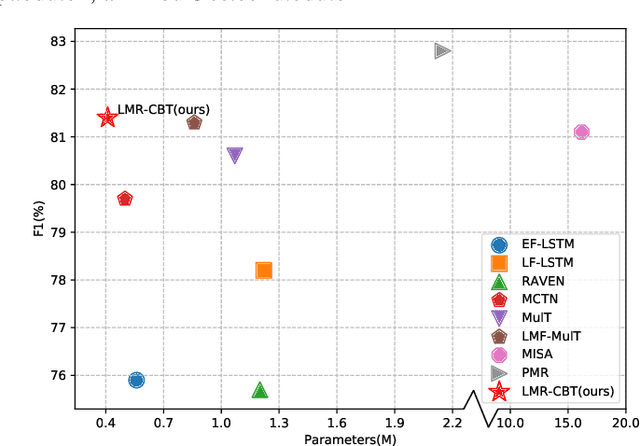
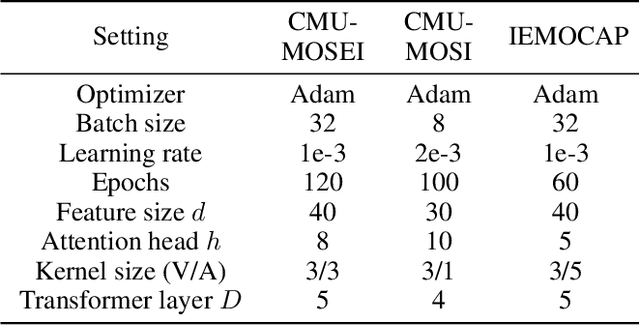
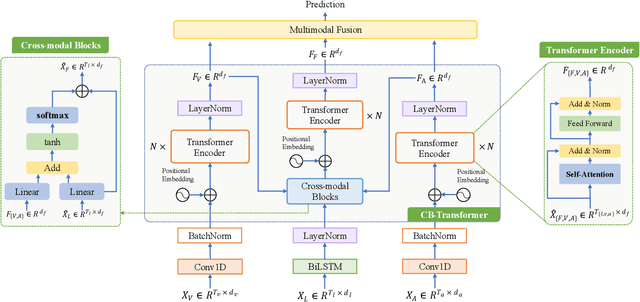
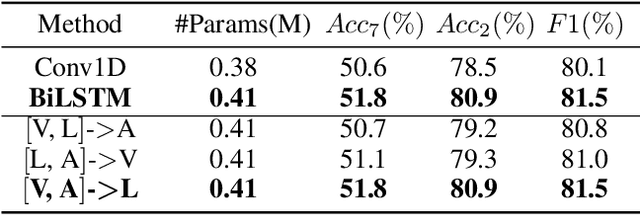
Learning modality-fused representations and processing unaligned multimodal sequences are meaningful and challenging in multimodal emotion recognition. Existing approaches use directional pairwise attention or a message hub to fuse language, visual, and audio modalities. However, those approaches introduce information redundancy when fusing features and are inefficient without considering the complementarity of modalities. In this paper, we propose an efficient neural network to learn modality-fused representations with CB-Transformer (LMR-CBT) for multimodal emotion recognition from unaligned multimodal sequences. Specifically, we first perform feature extraction for the three modalities respectively to obtain the local structure of the sequences. Then, we design a novel transformer with cross-modal blocks (CB-Transformer) that enables complementary learning of different modalities, mainly divided into local temporal learning,cross-modal feature fusion and global self-attention representations. In addition, we splice the fused features with the original features to classify the emotions of the sequences. Finally, we conduct word-aligned and unaligned experiments on three challenging datasets, IEMOCAP, CMU-MOSI, and CMU-MOSEI. The experimental results show the superiority and efficiency of our proposed method in both settings. Compared with the mainstream methods, our approach reaches the state-of-the-art with a minimum number of parameters.
Grounding Psychological Shape Space in Convolutional Neural Networks
Nov 16, 2021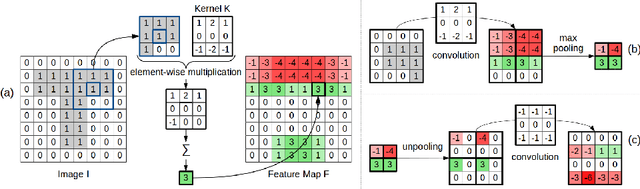
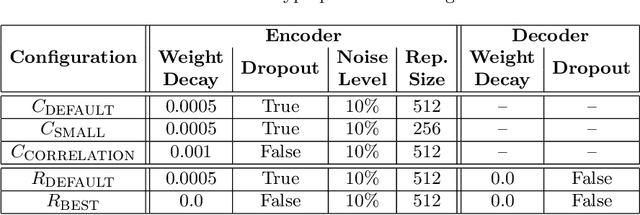
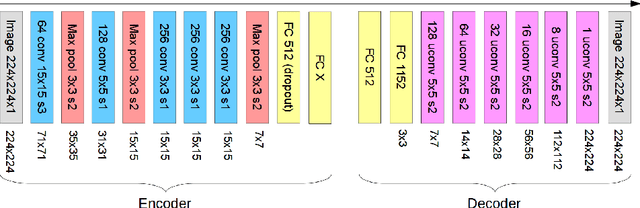
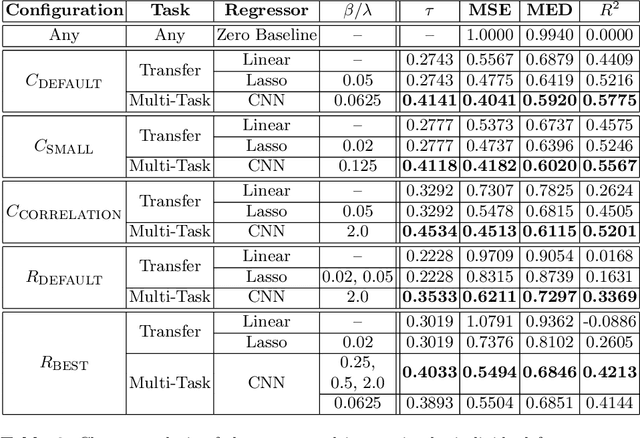
Shape information is crucial for human perception and cognition, and should therefore also play a role in cognitive AI systems. We employ the interdisciplinary framework of conceptual spaces, which proposes a geometric representation of conceptual knowledge through low-dimensional interpretable similarity spaces. These similarity spaces are often based on psychological dissimilarity ratings for a small set of stimuli, which are then transformed into a spatial representation by a technique called multidimensional scaling. Unfortunately, this approach is incapable of generalizing to novel stimuli. In this paper, we use convolutional neural networks to learn a generalizable mapping between perceptual inputs (pixels of grayscale line drawings) and a recently proposed psychological similarity space for the shape domain. We investigate different network architectures (classification network vs. autoencoder) and different training regimes (transfer learning vs. multi-task learning). Our results indicate that a classification-based multi-task learning scenario yields the best results, but that its performance is relatively sensitive to the dimensionality of the similarity space.