 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-supervised 6-DoF Robot Grasping by Demonstration via Augmented Reality Teleoperation System
Apr 03, 2024



Most existing 6-DoF robot grasping solutions depend on strong supervision on grasp pose to ensure satisfactory performance, which could be laborious and impractical when the robot works in some restricted area. To this end, we propose a self-supervised 6-DoF grasp pose detection framework via an Augmented Reality (AR) teleoperation system that can efficiently learn human demonstrations and provide 6-DoF grasp poses without grasp pose annotations. Specifically, the system collects the human demonstration from the AR environment and contrastively learns the grasping strategy from the demonstration. For the real-world experiment, the proposed system leads to satisfactory grasping abilities and learning to grasp unknown objects within three demonstrations.
Efficient Map Prediction via Low-Rank Matrix Completion
Oct 29, 2021
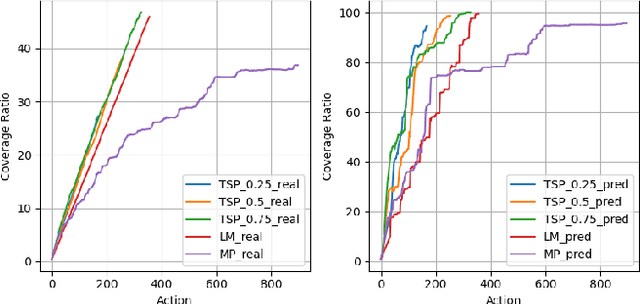
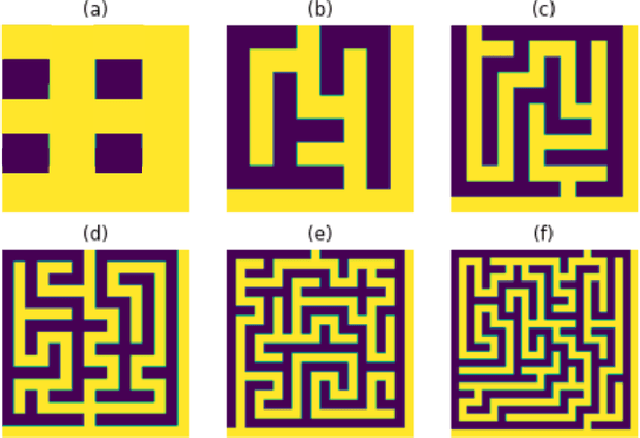

In many autonomous mapping tasks, the maps cannot be accurately constructed due to various reasons such as sparse, noisy, and partial sensor measurements. We propose a novel map prediction method built upon the recent success of Low-Rank Matrix Completion. The proposed map prediction is able to achieve both map interpolation and extrapolation on raw poor-quality maps with missing or noisy observations. We validate with extensive simulated experiments that the approach can achieve real-time computation for large maps, and the performance is superior to the state-of-the-art map prediction approach - Bayesian Hilbert Mapping in terms of mapping accuracy and computation time. Then we demonstrate that with the proposed real-time map prediction framework, the coverage convergence rate (per action step) for a set of representative coverage planning methods commonly used for environmental modeling and monitoring tasks can be significantly improved.
Multi-Objective Autonomous Exploration on Real-Time Continuous Occupancy Maps
Oct 29, 2021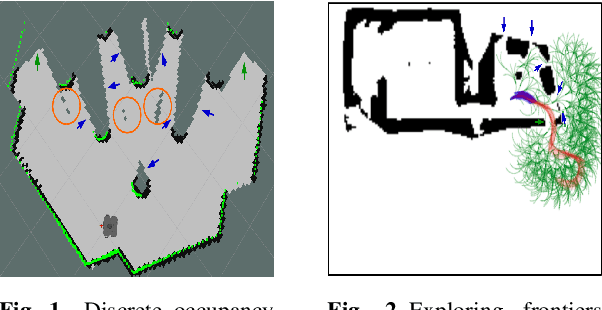
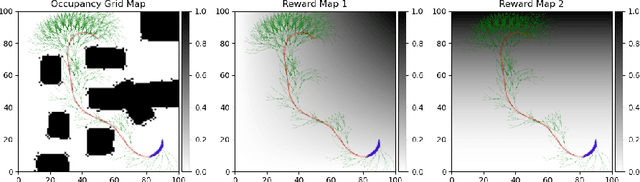


Autonomous exploration in unknown environments using mobile robots is the pillar of many robotic applications. Existing exploration frameworks either select the nearest geometric frontier or the nearest information-theoretic frontier. However, just because a frontier itself is informative does not necessarily mean that the robot will be in an informative area after reaching that frontier. To fill this gap, we propose to use a multi-objective variant of Monte-Carlo tree search that provides a non-myopic Pareto optimal action sequence leading the robot to a frontier with the greatest extent of unknown area uncovering. We also adopted Bayesian Hilbert Map (BHM) for continuous occupancy mapping and made it more applicable to real-time tasks.
Zero-Shot Reinforcement Learning on Graphs for Autonomous Exploration Under Uncertainty
May 11, 2021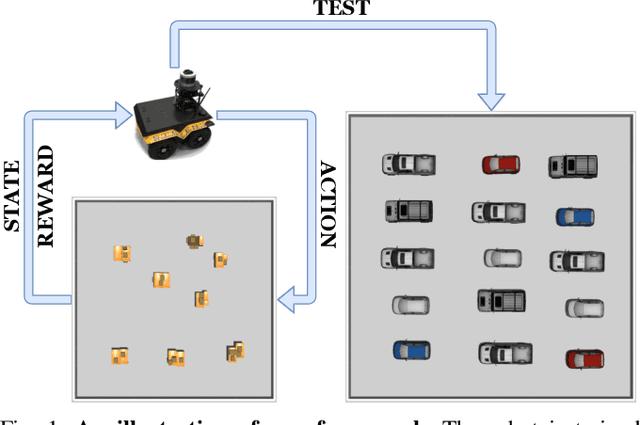


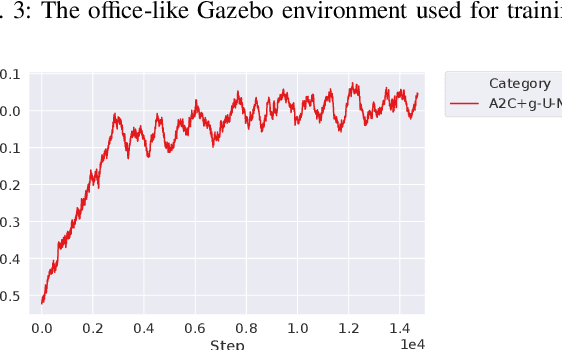
This paper studies the problem of autonomous exploration under localization uncertainty for a mobile robot with 3D range sensing. We present a framework for self-learning a high-performance exploration policy in a single simulation environment, and transferring it to other environments, which may be physical or virtual. Recent work in transfer learning achieves encouraging performance by domain adaptation and domain randomization to expose an agent to scenarios that fill the inherent gaps in sim2sim and sim2real approaches. However, it is inefficient to train an agent in environments with randomized conditions to learn the important features of its current state. An agent can use domain knowledge provided by human experts to learn efficiently. We propose a novel approach that uses graph neural networks in conjunction with deep reinforcement learning, enabling decision-making over graphs containing relevant exploration information provided by human experts to predict a robot's optimal sensing action in belief space. The policy, which is trained only in a single simulation environment, offers a real-time, scalable, and transferable decision-making strategy, resulting in zero-shot transfer to other simulation environments and even real-world environments.