 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
HyperTransformer: Model Generation for Supervised and Semi-Supervised Few-Shot Learning
Jan 15, 2022

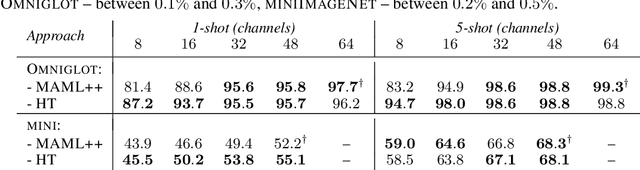
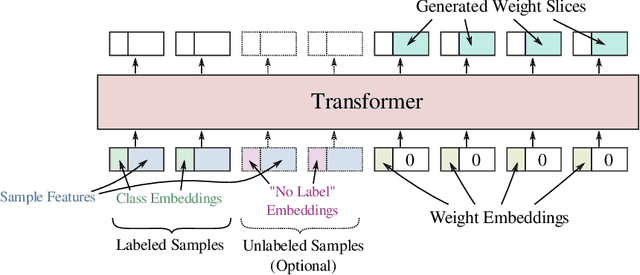
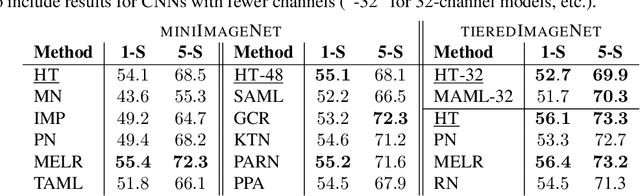
In this work we propose a HyperTransformer, a transformer-based model for few-shot learning that generates weights of a convolutional neural network (CNN) directly from support samples. Since the dependence of a small generated CNN model on a specific task is encoded by a high-capacity transformer model, we effectively decouple the complexity of the large task space from the complexity of individual tasks. Our method is particularly effective for small target CNN architectures where learning a fixed universal task-independent embedding is not optimal and better performance is attained when the information about the task can modulate all model parameters. For larger models we discover that generating the last layer alone allows us to produce competitive or better results than those obtained with state-of-the-art methods while being end-to-end differentiable. Finally, we extend our approach to a semi-supervised regime utilizing unlabeled samples in the support set and further improving few-shot performance.
FairEdit: Preserving Fairness in Graph Neural Networks through Greedy Graph Editing
Jan 12, 2022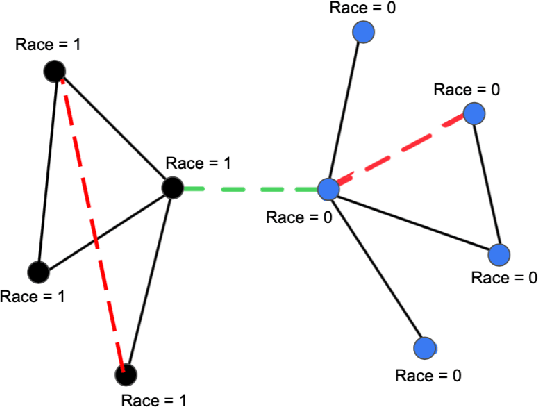
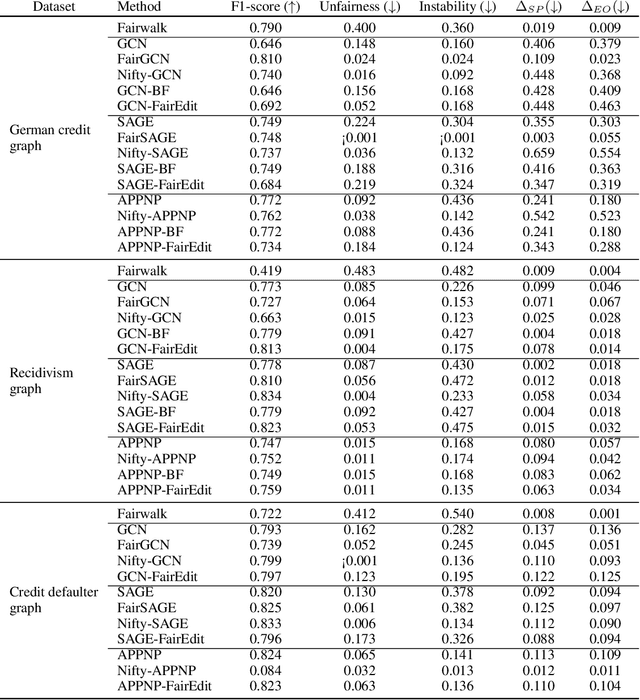
Graph Neural Networks (GNNs) have proven to excel in predictive modeling tasks where the underlying data is a graph. However, as GNNs are extensively used in human-centered applications, the issue of fairness has arisen. While edge deletion is a common method used to promote fairness in GNNs, it fails to consider when data is inherently missing fair connections. In this work we consider the unexplored method of edge addition, accompanied by deletion, to promote fairness. We propose two model-agnostic algorithms to perform edge editing: a brute force approach and a continuous approximation approach, FairEdit. FairEdit performs efficient edge editing by leveraging gradient information of a fairness loss to find edges that improve fairness. We find that FairEdit outperforms standard training for many data sets and GNN methods, while performing comparably to many state-of-the-art methods, demonstrating FairEdit's ability to improve fairness across many domains and models.
MIRA: Leveraging Multi-Intention Co-click Information in Web-scale Document Retrieval using Deep Neural Networks
Jul 03, 2020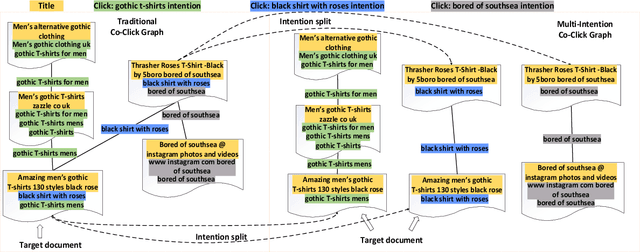
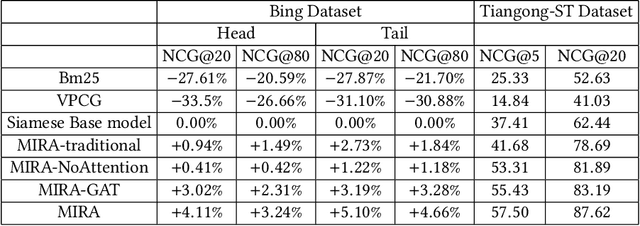
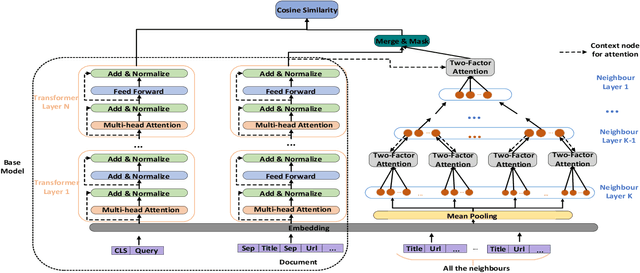
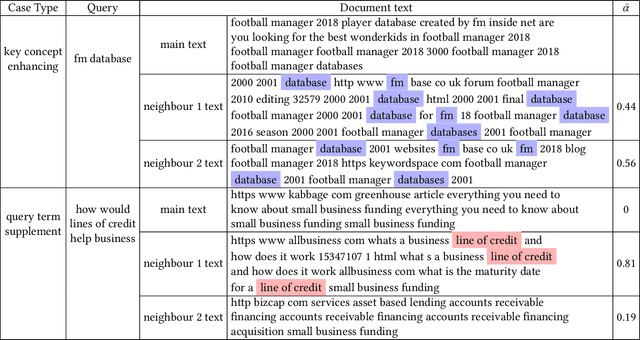
We study the problem of deep recall model in industrial web search, which is, given a user query, retrieve hundreds of most relevance documents from billions of candidates. The common framework is to train two encoding models based on neural embedding which learn the distributed representations of queries and documents separately and match them in the latent semantic space. However, all the exiting encoding models only leverage the information of the document itself, which is often not sufficient in practice when matching with query terms, especially for the hard tail queries. In this work we aim to leverage the additional information for each document from its co-click neighbour to help document retrieval. The challenges include how to effectively extract information and eliminate noise when involving co-click information in deep model while meet the demands of billion-scale data size for real time online inference. To handle the noise in co-click relations, we firstly propose a web-scale Multi-Intention Co-click document Graph(MICG) which builds the co-click connections between documents on click intention level but not on document level. Then we present an encoding framework MIRA based on Bert and graph attention networks which leverages a two-factor attention mechanism to aggregate neighbours. To meet the online latency requirements, we only involve neighbour information in document side, which can save the time-consuming query neighbor search in real time serving. We conduct extensive offline experiments on both public dataset and private web-scale dataset from two major commercial search engines demonstrating the effectiveness and scalability of the proposed method compared with several baselines. And a further case study reveals that co-click relations mainly help improve web search quality from two aspects: key concept enhancing and query term complementary.
Contrastively Disentangled Sequential Variational Autoencoder
Oct 22, 2021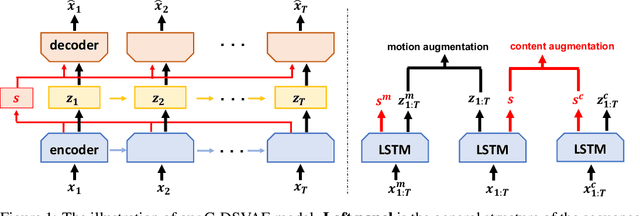

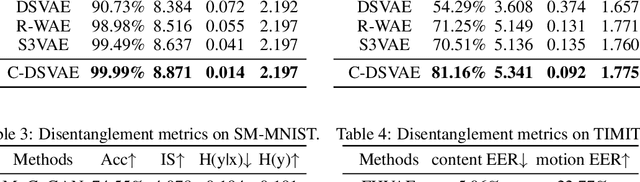
Self-supervised disentangled representation learning is a critical task in sequence modeling. The learnt representations contribute to better model interpretability as well as the data generation, and improve the sample efficiency for downstream tasks. We propose a novel sequence representation learning method, named Contrastively Disentangled Sequential Variational Autoencoder (C-DSVAE), to extract and separate the static (time-invariant) and dynamic (time-variant) factors in the latent space. Different from previous sequential variational autoencoder methods, we use a novel evidence lower bound which maximizes the mutual information between the input and the latent factors, while penalizes the mutual information between the static and dynamic factors. We leverage contrastive estimations of the mutual information terms in training, together with simple yet effective augmentation techniques, to introduce additional inductive biases. Our experiments show that C-DSVAE significantly outperforms the previous state-of-the-art methods on multiple metrics.
Hidden Agenda: a Social Deduction Game with Diverse Learned Equilibria
Jan 05, 2022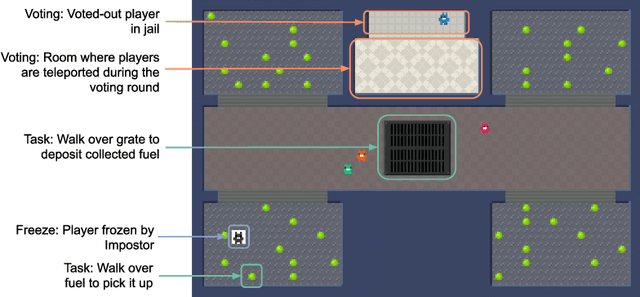

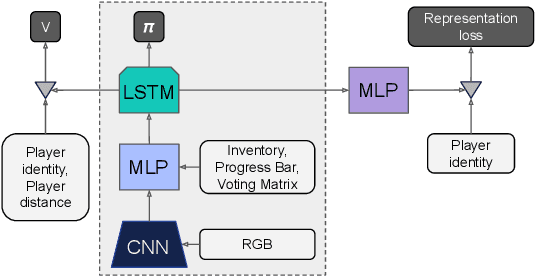
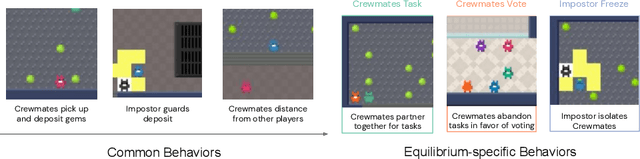
A key challenge in the study of multiagent cooperation is the need for individual agents not only to cooperate effectively, but to decide with whom to cooperate. This is particularly critical in situations when other agents have hidden, possibly misaligned motivations and goals. Social deduction games offer an avenue to study how individuals might learn to synthesize potentially unreliable information about others, and elucidate their true motivations. In this work, we present Hidden Agenda, a two-team social deduction game that provides a 2D environment for studying learning agents in scenarios of unknown team alignment. The environment admits a rich set of strategies for both teams. Reinforcement learning agents trained in Hidden Agenda show that agents can learn a variety of behaviors, including partnering and voting without need for communication in natural language.
Fed2: Feature-Aligned Federated Learning
Nov 28, 2021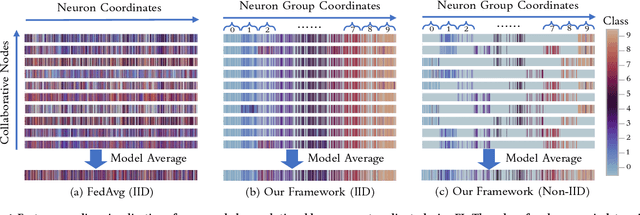
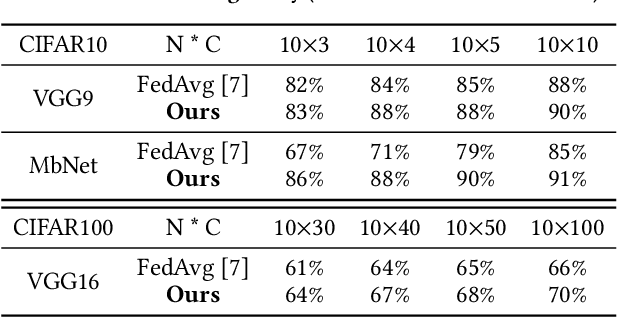
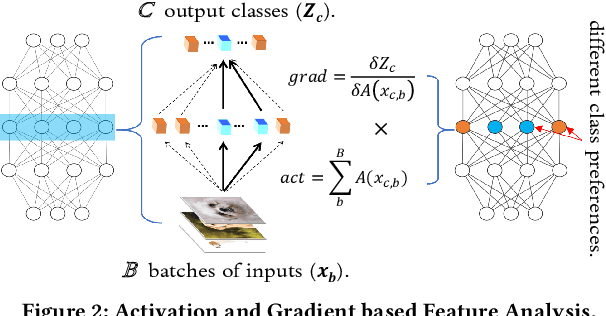
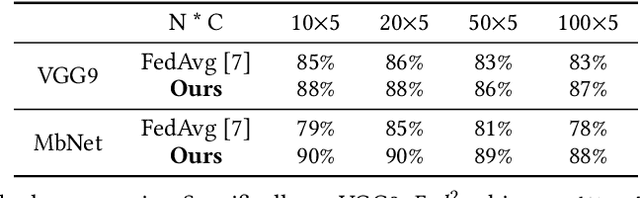
Federated learning learns from scattered data by fusing collaborative models from local nodes. However, the conventional coordinate-based model averaging by FedAvg ignored the random information encoded per parameter and may suffer from structural feature misalignment. In this work, we propose Fed2, a feature-aligned federated learning framework to resolve this issue by establishing a firm structure-feature alignment across the collaborative models. Fed2 is composed of two major designs: First, we design a feature-oriented model structure adaptation method to ensure explicit feature allocation in different neural network structures. Applying the structure adaptation to collaborative models, matchable structures with similar feature information can be initialized at the very early training stage. During the federated learning process, we then propose a feature paired averaging scheme to guarantee aligned feature distribution and maintain no feature fusion conflicts under either IID or non-IID scenarios. Eventually, Fed2 could effectively enhance the federated learning convergence performance under extensive homo- and heterogeneous settings, providing excellent convergence speed, accuracy, and computation/communication efficiency.
Identity Conversion for Emotional Speakers: A Study for Disentanglement of Emotion Style and Speaker Identity
Oct 20, 2021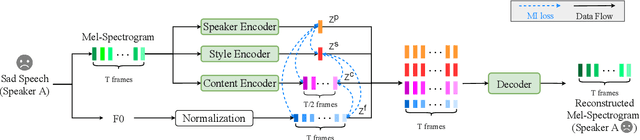
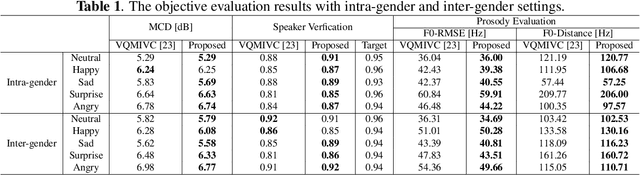

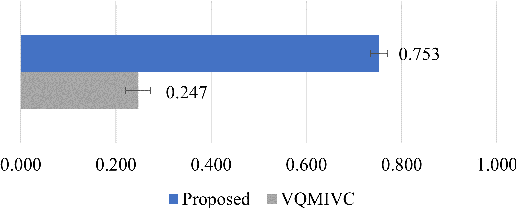
Expressive voice conversion performs identity conversion for emotional speakers by jointly converting speaker identity and speaker-dependent emotion style. Due to the hierarchical structure of speech emotion, it is challenging to disentangle the speaker-dependent emotional style for expressive voice conversion. Motivated by the recent success on speaker disentanglement with variational autoencoder (VAE), we propose an expressive voice conversion framework which can effectively disentangle linguistic content, speaker identity, pitch, and emotional style information. We study the use of emotion encoder to model emotional style explicitly, and introduce mutual information (MI) losses to reduce the irrelevant information from the disentangled emotion representations. At run-time, our proposed framework can convert both speaker identity and speaker-dependent emotional style without the need for parallel data. Experimental results validate the effectiveness of our proposed framework in both objective and subjective evaluations.
Robust Image Reconstruction with Misaligned Structural Information
Apr 01, 2020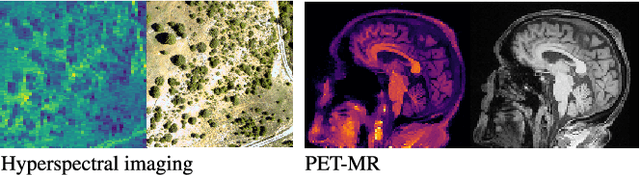
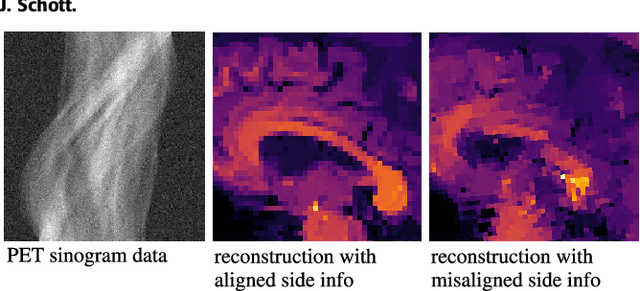
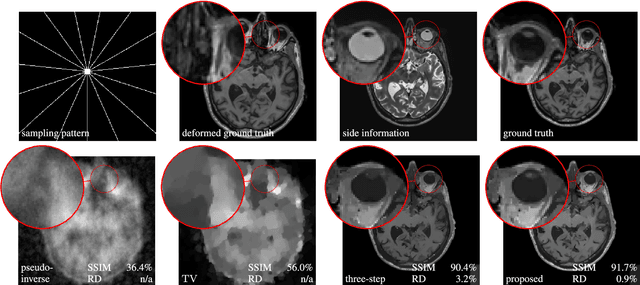
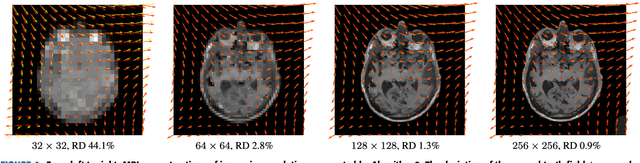
Multi-modality (or multi-channel) imaging is becoming increasingly important and more widely available, e.g. hyperspectral imaging in remote sensing, spectral CT in material sciences as well as multi-contrast MRI and PET-MR in medicine. Research in the last decades resulted in a plethora of mathematical methods to combine data from several modalities. State-of-the-art methods, often formulated as variational regularization, have shown to significantly improve image reconstruction both quantitatively and qualitatively. Almost all of these models rely on the assumption that the modalities are perfectly registered, which is not the case in most real world applications. We propose a variational framework which jointly performs reconstruction and registration, thereby overcoming this hurdle. Numerical results show the potential of the proposed strategy for various applications for hyperspectral imaging, PET-MR and multi-contrast MRI: typical misalignments between modalities such as rotations, translations, zooms can be effectively corrected during the reconstruction process. Therefore the proposed framework allows the robust exploitation of shared information across multiple modalities under real conditions.
Source Mixing and Separation Robust Audio Steganography
Oct 11, 2021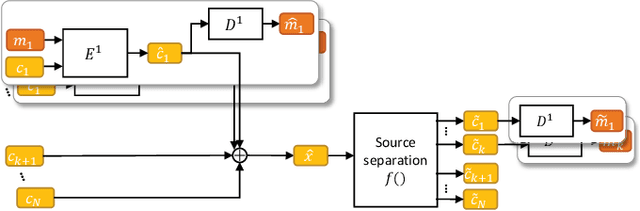

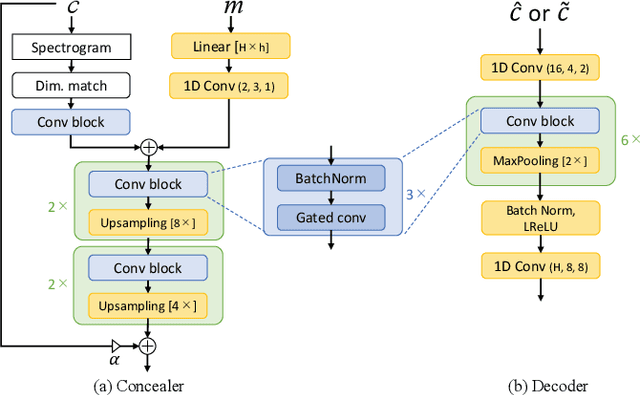
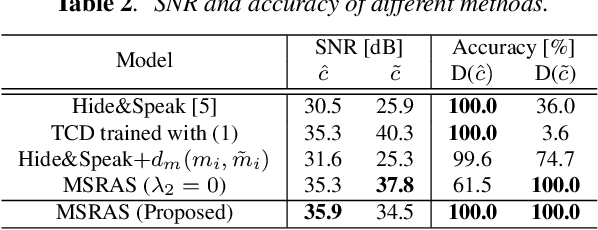
Audio steganography aims at concealing secret information in carrier audio with imperceptible modification on the carrier. Although previous works addressed the robustness of concealed message recovery against distortions introduced during transmission, they do not address the robustness against aggressive editing such as mixing of other audio sources and source separation. In this work, we propose for the first time a steganography method that can embed information into individual sound sources in a mixture such as instrumental tracks in music. To this end, we propose a time-domain model and curriculum learning essential to learn to decode the concealed message from the separated sources. Experimental results show that the proposed method successfully conceals the information in an imperceptible perturbation and that the information can be correctly recovered even after mixing of other sources and separation by a source separation algorithm. Furthermore, we show that the proposed method can be applied to multiple sources simultaneously without interfering with the decoder for other sources even after the sources are mixed and separated.
Pythia: A Customizable Hardware Prefetching Framework Using Online Reinforcement Learning
Oct 19, 2021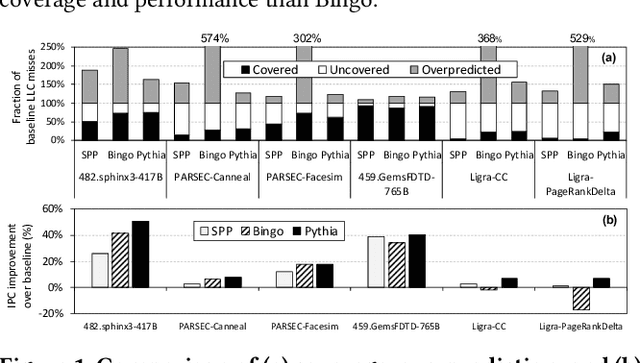
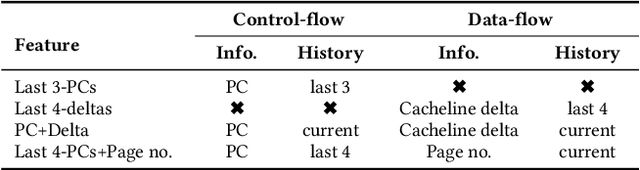
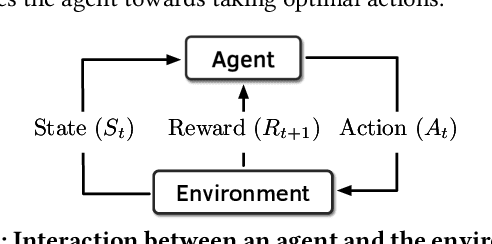

Past research has proposed numerous hardware prefetching techniques, most of which rely on exploiting one specific type of program context information (e.g., program counter, cacheline address) to predict future memory accesses. These techniques either completely neglect a prefetcher's undesirable effects (e.g., memory bandwidth usage) on the overall system, or incorporate system-level feedback as an afterthought to a system-unaware prefetch algorithm. We show that prior prefetchers often lose their performance benefit over a wide range of workloads and system configurations due to their inherent inability to take multiple different types of program context and system-level feedback information into account while prefetching. In this paper, we make a case for designing a holistic prefetch algorithm that learns to prefetch using multiple different types of program context and system-level feedback information inherent to its design. To this end, we propose Pythia, which formulates the prefetcher as a reinforcement learning agent. For every demand request, Pythia observes multiple different types of program context information to make a prefetch decision. For every prefetch decision, Pythia receives a numerical reward that evaluates prefetch quality under the current memory bandwidth usage. Pythia uses this reward to reinforce the correlation between program context information and prefetch decision to generate highly accurate, timely, and system-aware prefetch requests in the future. Our extensive evaluations using simulation and hardware synthesis show that Pythia outperforms multiple state-of-the-art prefetchers over a wide range of workloads and system configurations, while incurring only 1.03% area overhead over a desktop-class processor and no software changes in workloads. The source code of Pythia can be freely downloaded from https://github.com/CMU-SAFARI/Pythia.