 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTuneAhead: Predicting Fine-tuning Performance Before Full Training Begins
Jun 16, 2026Fine-tuning large language models (LLMs) is compute-intensive and error-prone: model performance depends sensitively on data quality and hyperparameter choices, and naïve runs can even degrade model performance. This raises a practical question:can we predict fine-tuning performance before committing to a full training run? We present TUNEAHEAD, a lightweight framework for pre-hoc prediction of fine-tuning performance. TUNEAHEAD encodes each candidate run as a meta-feature vector that combines static dataset descriptors with dynamic probe features from a short standardized probe. A predictor maps these features to performance estimates, while SHAP-based attributions provide interpretable diagnostics that reveal which specific features drive the prediction. Across 1,300+ fine-tuning runs on Qwen2.5-7B-Instruct, TUNEAHEAD consistently outperforms strong baselines such as Early-Stop Extrapolation and ProxyLM. On a held-out test set of 370 runs, TUNEAHEAD achieves an RMSE of 1.47 percentage points and places 95.1% of predictions within +3/-3 percentage points of the true score. These accurate continuous predictions support practical go/no-go screening policies that can reduce unnecessary full fine-tuning while retaining most promising runs.
A Risk Decomposition Framework for Pre-Hoc Fine-Tuning Prediction
Jun 16, 2026The high cost of fine-tuning LLMs poses a significant economic barrier; pre-hoc performance prediction offers a critical solution to substantially reduce this expense. However, the theoretical limits of pre-hoc performance prediction remain unexplored. We formulate it as a stochastic estimation problem under information constraints, decomposing prediction risk into two components: an intrinsic limit (static data-model compatibility) and a reducible optimization variance. We prove that optimization variance admits a necessary lower bound on its decay rate, implying fundamental constraints on how quickly uncertainty dissipates, regardless of the predictor used. Based on these dynamics, we derive a budget-optimal probing principle and introduce a predictability phase diagram that organizes tasks into three distinct regimes: Static-Sufficient, Dynamic-Critical, and Noise-Dominant. Extensive experiments on synthetic and real-world benchmarks validate these theoretical regimes and demonstrate the efficiency of our probing strategy.
Co-PLNet: A Collaborative Point-Line Network for Prompt-Guided Wireframe Parsing
Jan 26, 2026Wireframe parsing aims to recover line segments and their junctions to form a structured geometric representation useful for downstream tasks such as Simultaneous Localization and Mapping (SLAM). Existing methods predict lines and junctions separately and reconcile them post-hoc, causing mismatches and reduced robustness. We present Co-PLNet, a point-line collaborative framework that exchanges spatial cues between the two tasks, where early detections are converted into spatial prompts via a Point-Line Prompt Encoder (PLP-Encoder), which encodes geometric attributes into compact and spatially aligned maps. A Cross-Guidance Line Decoder (CGL-Decoder) then refines predictions with sparse attention conditioned on complementary prompts, enforcing point-line consistency and efficiency. Experiments on Wireframe and YorkUrban show consistent improvements in accuracy and robustness, together with favorable real-time efficiency, demonstrating our effectiveness for structured geometry perception.
LapFM: A Laparoscopic Segmentation Foundation Model via Hierarchical Concept Evolving Pre-training
Dec 09, 2025Surgical segmentation is pivotal for scene understanding yet remains hindered by annotation scarcity and semantic inconsistency across diverse procedures. Existing approaches typically fine-tune natural foundation models (e.g., SAM) with limited supervision, functioning merely as domain adapters rather than surgical foundation models. Consequently, they struggle to generalize across the vast variability of surgical targets. To bridge this gap, we present LapFM, a foundation model designed to evolve robust segmentation capabilities from massive unlabeled surgical images. Distinct from medical foundation models relying on inefficient self-supervised proxy tasks, LapFM leverages a Hierarchical Concept Evolving Pre-training paradigm. First, we establish a Laparoscopic Concept Hierarchy (LCH) via a hierarchical mask decoder with parent-child query embeddings, unifying diverse entities (i.e., Anatomy, Tissue, and Instrument) into a scalable knowledge structure with cross-granularity semantic consistency. Second, we propose a Confidence-driven Evolving Labeling that iteratively generates and filters pseudo-labels based on hierarchical consistency, progressively incorporating reliable samples from unlabeled images into training. This process yields LapBench-114K, a large-scale benchmark comprising 114K image-mask pairs. Extensive experiments demonstrate that LapFM significantly outperforms state-of-the-art methods, establishing new standards for granularity-adaptive generalization in universal laparoscopic segmentation. The source code is available at https://github.com/xq141839/LapFM.
TM-UNet: Token-Memory Enhanced Sequential Modeling for Efficient Medical Image Segmentation
Nov 15, 2025Medical image segmentation is essential for clinical diagnosis and treatment planning. Although transformer-based methods have achieved remarkable results, their high computational cost hinders clinical deployment. To address this issue, we propose TM-UNet, a novel lightweight framework that integrates token sequence modeling with an efficient memory mechanism for efficient medical segmentation. Specifically, we introduce a multi-scale token-memory (MSTM) block that transforms 2D spatial features into token sequences through strategic spatial scanning, leveraging matrix memory cells to selectively retain and propagate discriminative contextual information across tokens. This novel token-memory mechanism acts as a dynamic knowledge store that captures long-range dependencies with linear complexity, enabling efficient global reasoning without redundant computation. Our MSTM block further incorporates exponential gating to identify token effectiveness and multi-scale contextual extraction via parallel pooling operations, enabling hierarchical representation learning without computational overhead. Extensive experiments demonstrate that TM-UNet outperforms state-of-the-art methods across diverse medical segmentation tasks with substantially reduced computation cost. The code is available at https://github.com/xq141839/TM-UNet.
DeepSeek-V3 Technical Report
Dec 27, 2024



We present DeepSeek-V3, a strong Mixture-of-Experts (MoE) language model with 671B total parameters with 37B activated for each token. To achieve efficient inference and cost-effective training, DeepSeek-V3 adopts Multi-head Latent Attention (MLA) and DeepSeekMoE architectures, which were thoroughly validated in DeepSeek-V2. Furthermore, DeepSeek-V3 pioneers an auxiliary-loss-free strategy for load balancing and sets a multi-token prediction training objective for stronger performance. We pre-train DeepSeek-V3 on 14.8 trillion diverse and high-quality tokens, followed by Supervised Fine-Tuning and Reinforcement Learning stages to fully harness its capabilities. Comprehensive evaluations reveal that DeepSeek-V3 outperforms other open-source models and achieves performance comparable to leading closed-source models. Despite its excellent performance, DeepSeek-V3 requires only 2.788M H800 GPU hours for its full training. In addition, its training process is remarkably stable. Throughout the entire training process, we did not experience any irrecoverable loss spikes or perform any rollbacks. The model checkpoints are available at https://github.com/deepseek-ai/DeepSeek-V3.
MIRA: Leveraging Multi-Intention Co-click Information in Web-scale Document Retrieval using Deep Neural Networks
Jul 03, 2020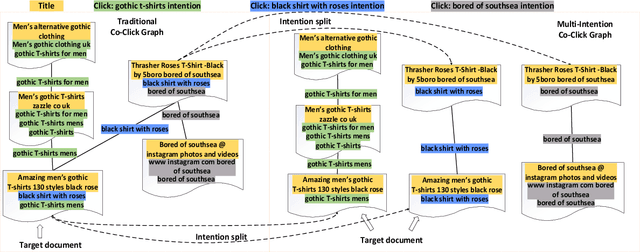
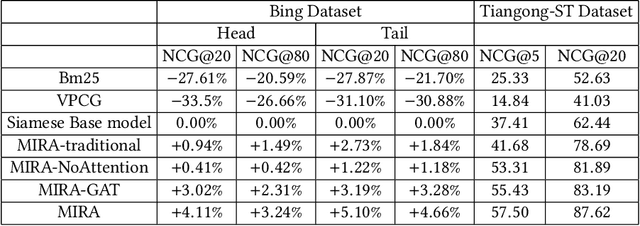
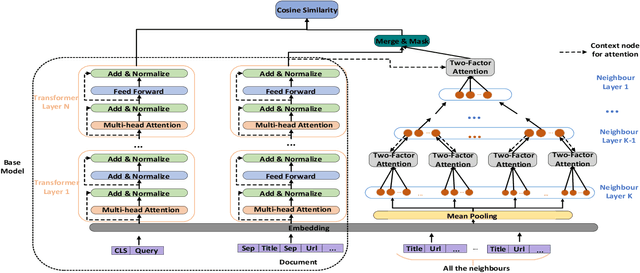
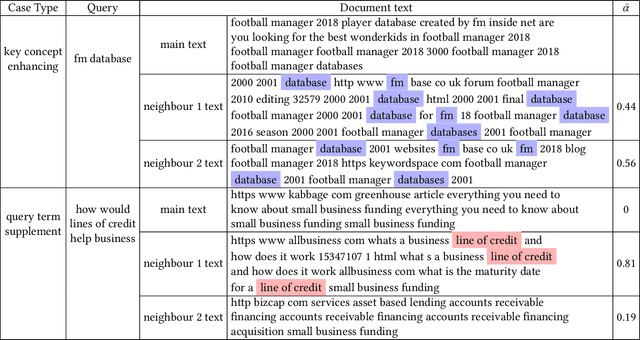
We study the problem of deep recall model in industrial web search, which is, given a user query, retrieve hundreds of most relevance documents from billions of candidates. The common framework is to train two encoding models based on neural embedding which learn the distributed representations of queries and documents separately and match them in the latent semantic space. However, all the exiting encoding models only leverage the information of the document itself, which is often not sufficient in practice when matching with query terms, especially for the hard tail queries. In this work we aim to leverage the additional information for each document from its co-click neighbour to help document retrieval. The challenges include how to effectively extract information and eliminate noise when involving co-click information in deep model while meet the demands of billion-scale data size for real time online inference. To handle the noise in co-click relations, we firstly propose a web-scale Multi-Intention Co-click document Graph(MICG) which builds the co-click connections between documents on click intention level but not on document level. Then we present an encoding framework MIRA based on Bert and graph attention networks which leverages a two-factor attention mechanism to aggregate neighbours. To meet the online latency requirements, we only involve neighbour information in document side, which can save the time-consuming query neighbor search in real time serving. We conduct extensive offline experiments on both public dataset and private web-scale dataset from two major commercial search engines demonstrating the effectiveness and scalability of the proposed method compared with several baselines. And a further case study reveals that co-click relations mainly help improve web search quality from two aspects: key concept enhancing and query term complementary.