 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Two Wrongs Don't Make a Right: Combating Confirmation Bias in Learning with Label Noise
Dec 06, 2021
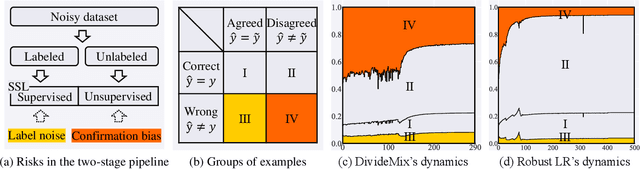
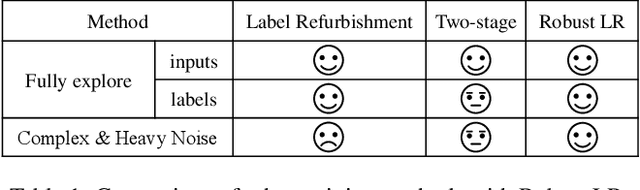
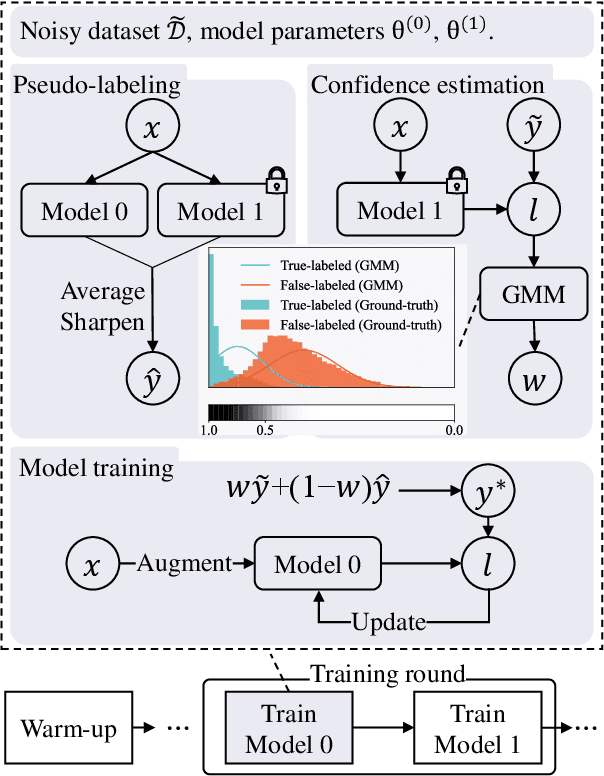
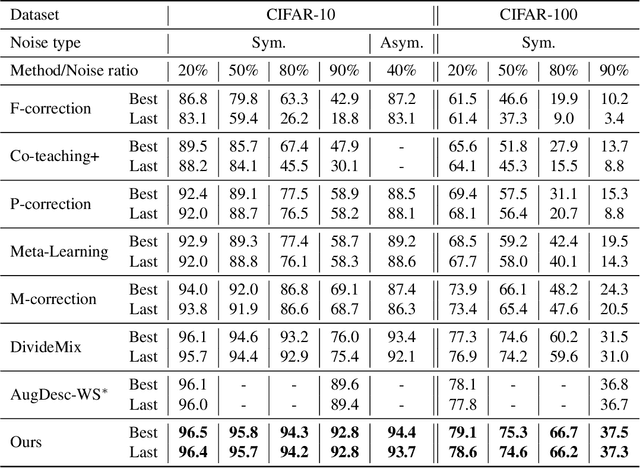
Noisy labels damage the performance of deep networks. For robust learning, a prominent two-stage pipeline alternates between eliminating possible incorrect labels and semi-supervised training. However, discarding part of observed labels could result in a loss of information, especially when the corruption is not completely random, e.g., class-dependent or instance-dependent. Moreover, from the training dynamics of a representative two-stage method DivideMix, we identify the domination of confirmation bias: Pseudo-labels fail to correct a considerable amount of noisy labels and consequently, the errors accumulate. To sufficiently exploit information from observed labels and mitigate wrong corrections, we propose Robust Label Refurbishment (Robust LR)-a new hybrid method that integrates pseudo-labeling and confidence estimation techniques to refurbish noisy labels. We show that our method successfully alleviates the damage of both label noise and confirmation bias. As a result, it achieves state-of-the-art results across datasets and noise types. For example, Robust LR achieves up to 4.5% absolute top-1 accuracy improvement over the previous best on the real-world noisy dataset WebVision.
Tracing Origins: Coref-aware Machine Reading Comprehension
Oct 15, 2021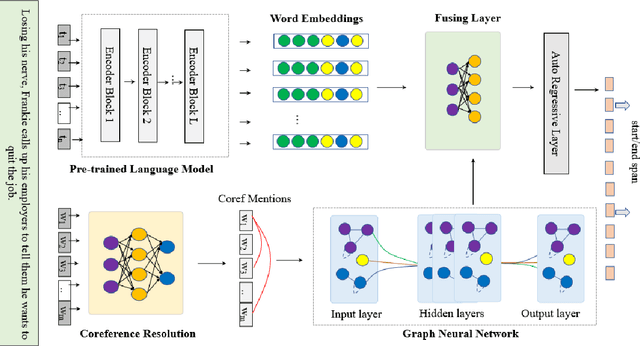

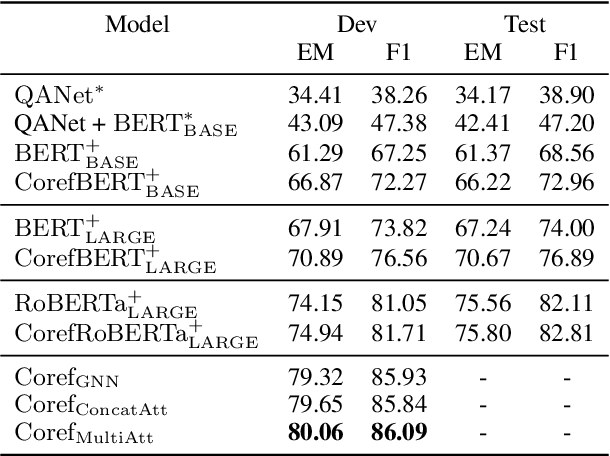
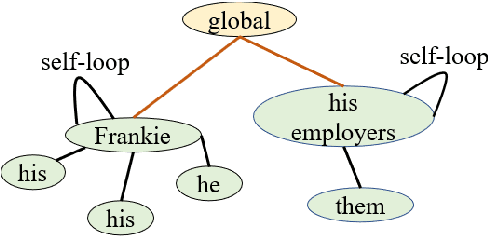
Machine reading comprehension is a heavily-studied research and test field for evaluating new pre-trained models and fine-tuning strategies, and recent studies have enriched the pre-trained models with syntactic, semantic and other linguistic information to improve the performance of the model. In this paper, we imitated the human's reading process in connecting the anaphoric expressions and explicitly leverage the coreference information to enhance the word embeddings from the pre-trained model, in order to highlight the coreference mentions that must be identified for coreference-intensive question answering in QUOREF, a relatively new dataset that is specifically designed to evaluate the coreference-related performance of a model. We used an additional BERT layer to focus on the coreference mentions, and a Relational Graph Convolutional Network to model the coreference relations. We demonstrated that the explicit incorporation of the coreference information in fine-tuning stage performed better than the incorporation of the coreference information in training a pre-trained language models.
MultiHead MultiModal Deep Interest Recommendation Network
Oct 19, 2021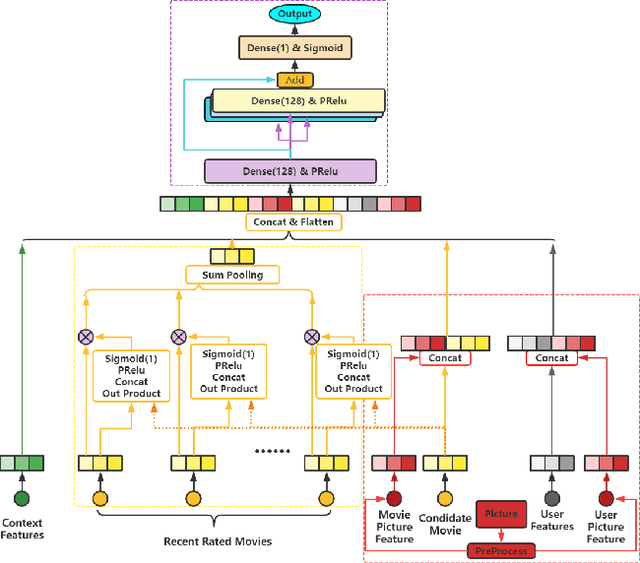
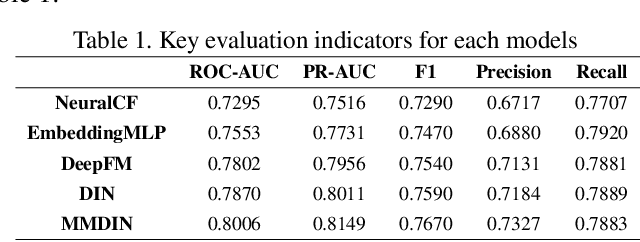
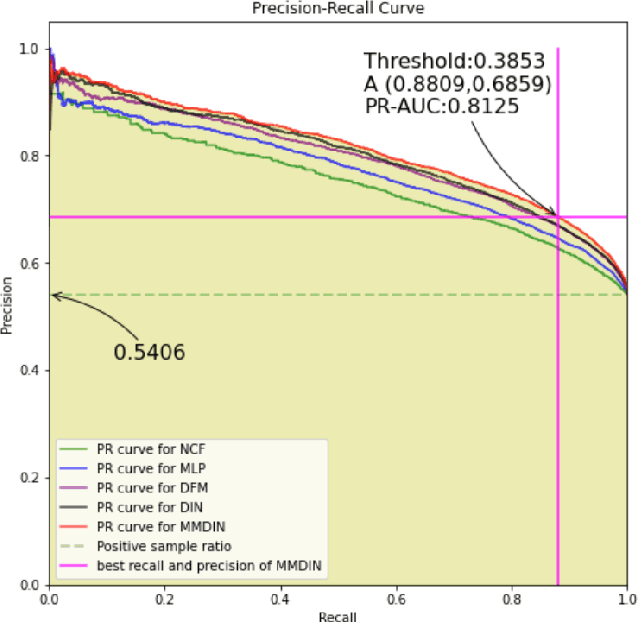
With the development of information technology, human beings are constantly producing a large amount of information at all times. How to obtain the information that users are interested in from the large amount of information has become an issue of great concern to users and even business managers. In order to solve this problem, from traditional machine learning to deep learning recommendation systems, researchers continue to improve optimization models and explore solutions. Because researchers have optimized more on the recommendation model network structure, they have less research on enriching recommendation model features, and there is still room for in-depth recommendation model optimization. Based on the DIN\cite{Authors01} model, this paper adds multi-head and multi-modal modules, which enriches the feature sets that the model can use, and at the same time strengthens the cross-combination and fitting capabilities of the model. Experiments show that the multi-head multi-modal DIN improves the recommendation prediction effect, and outperforms current state-of-the-art methods on various comprehensive indicators.
Audio-visual Representation Learning for Anomaly Events Detection in Crowds
Oct 28, 2021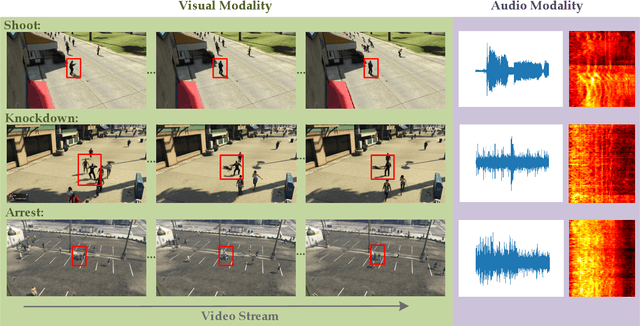
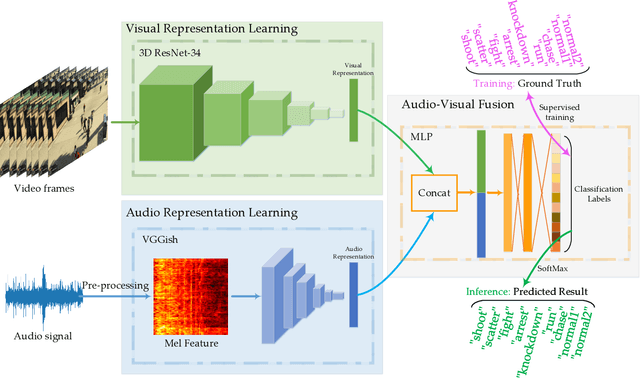
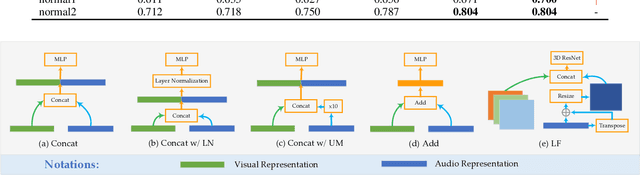
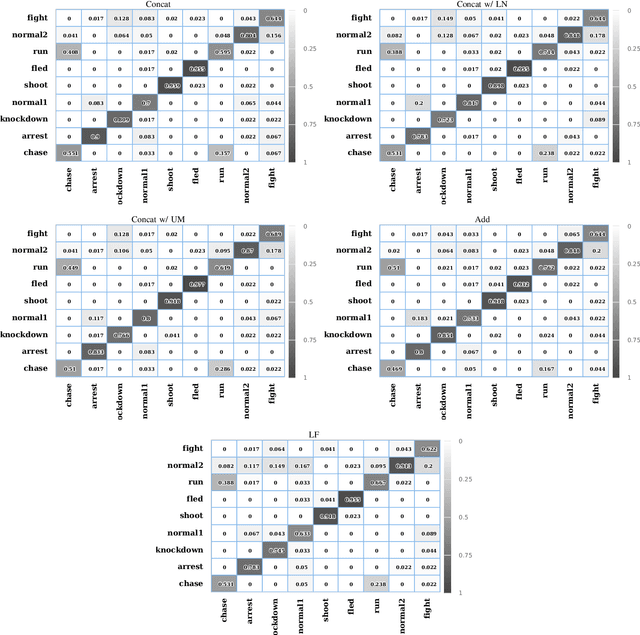
In recent years, anomaly events detection in crowd scenes attracts many researchers' attention, because of its importance to public safety. Existing methods usually exploit visual information to analyze whether any abnormal events have occurred due to only visual sensors are generally equipped in public places. However, when an abnormal event in crowds occurs, sound information may be discriminative to assist the crowd analysis system to determine whether there is an abnormality. Compare with vision information that is easily occluded, audio signals have a certain degree of penetration. Thus, this paper attempt to exploit multi-modal learning for modeling the audio and visual signals simultaneously. To be specific, we design a two-branch network to model different types of information. The first is a typical 3D CNN model to extract temporal appearance features from video clips. The second is an audio CNN for encoding Log Mel-Spectrogram of audio signals. Finally, by fusing the above features, a more accurate prediction will be produced. We conduct the experiments on SHADE dataset, a synthetic audio-visual dataset in surveillance scenes, and find introducing audio signals effectively improves the performance of anomaly events detection and outperforms other state-of-the-art methods. Furthermore, we will release the code and the pre-trained models as soon as possible.
Intent Contrastive Learning for Sequential Recommendation
Feb 05, 2022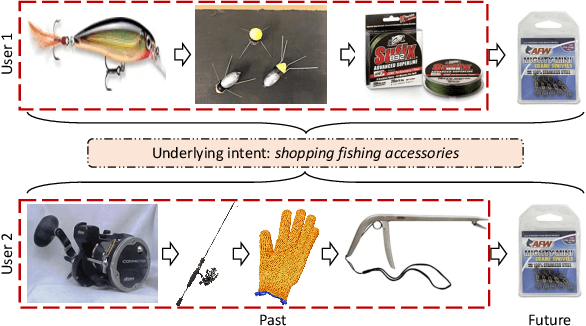
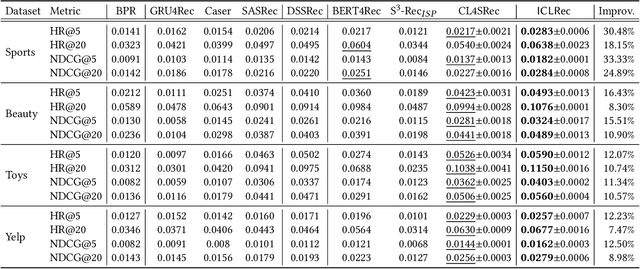
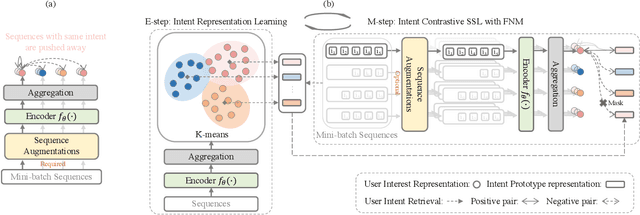
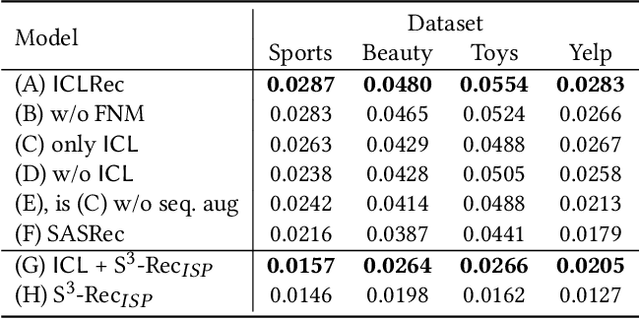
Users' interactions with items are driven by various intents (e.g., preparing for holiday gifts, shopping for fishing equipment, etc.).However, users' underlying intents are often unobserved/latent, making it challenging to leverage such latent intents forSequentialrecommendation(SR). To investigate the benefits of latent intents and leverage them effectively for recommendation, we proposeIntentContrastiveLearning(ICL), a general learning paradigm that leverages a latent intent variable into SR. The core idea is to learn users' intent distribution functions from unlabeled user behavior sequences and optimize SR models with contrastive self-supervised learning (SSL) by considering the learned intents to improve recommendation. Specifically, we introduce a latent variable to represent users' intents and learn the distribution function of the latent variable via clustering. We propose to leverage the learned intents into SR models via contrastive SSL, which maximizes the agreement between a view of sequence and its corresponding intent. The training is alternated between intent representation learning and the SR model optimization steps within the generalized expectation-maximization (EM) framework. Fusing user intent information into SR also improves model robustness. Experiments conducted on four real-world datasets demonstrate the superiority of the proposed learning paradigm, which improves performance, and robustness against data sparsity and noisy interaction issues.
Information Freshness-Aware Task Offloading in Air-Ground Integrated Edge Computing Systems
Jul 15, 2020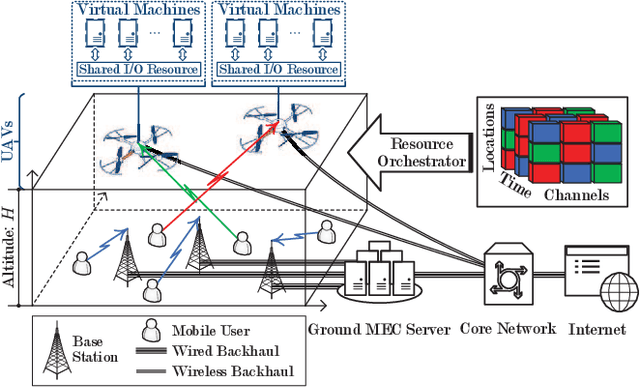
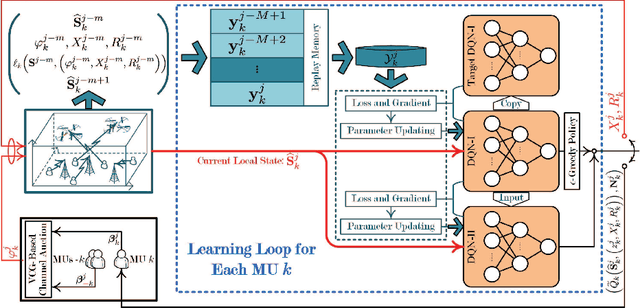


This paper studies the problem of information freshness-aware task offloading in an air-ground integrated multi-access edge computing system, which is deployed by an infrastructure provider (InP). A third-party real-time application service provider provides computing services to the subscribed mobile users (MUs) with the limited communication and computation resources from the InP based on a long-term business agreement. Due to the dynamic characteristics, the interactions among the MUs are modelled by a non-cooperative stochastic game, in which the control policies are coupled and each MU aims to selfishly maximize its own expected long-term payoff. To address the Nash equilibrium solutions, we propose that each MU behaves in accordance with the local system states and conjectures, based on which the stochastic game is transformed into a single-agent Markov decision process. Moreover, we derive a novel online deep reinforcement learning (RL) scheme that adopts two separate double deep Q-networks for each MU to approximate the Q-factor and the post-decision Q-factor. Using the proposed deep RL scheme, each MU in the system is able to make decisions without a priori statistical knowledge of dynamics. Numerical experiments examine the potentials of the proposed scheme in balancing the age of information and the energy consumption.
STformer: A Noise-Aware Efficient Spatio-Temporal Transformer Architecture for Traffic Forecasting
Dec 06, 2021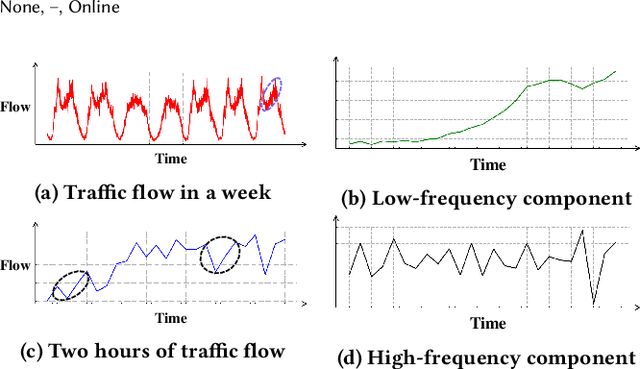
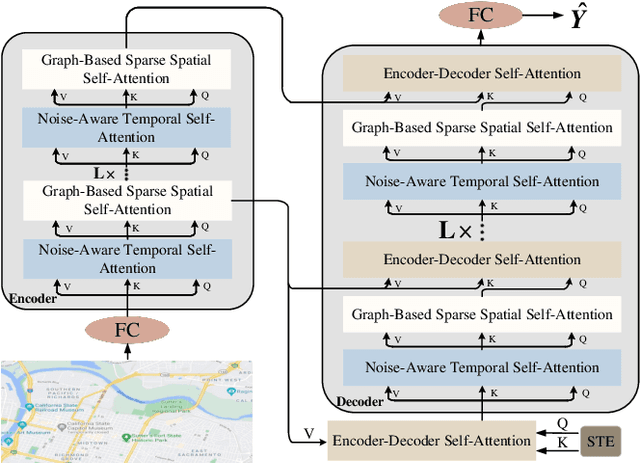
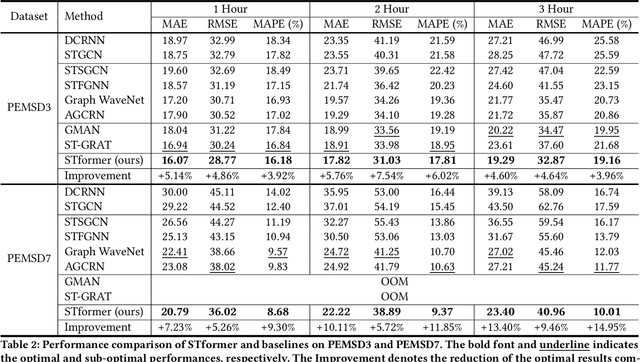
Traffic forecasting plays an indispensable role in the intelligent transportation system, which makes daily travel more convenient and safer. However, the dynamic evolution of spatio-temporal correlations makes accurate traffic forecasting very difficult. Existing work mainly employs graph neural netwroks (GNNs) and deep time series models (e.g., recurrent neural networks) to capture complex spatio-temporal patterns in the dynamic traffic system. For the spatial patterns, it is difficult for GNNs to extract the global spatial information, i.e., remote sensors information in road networks. Although we can use the self-attention to extract global spatial information as in the previous work, it is also accompanied by huge resource consumption. For the temporal patterns, traffic data have not only easy-to-recognize daily and weekly trends but also difficult-to-recognize short-term noise caused by accidents (e.g., car accidents and thunderstorms). Prior traffic models are difficult to distinguish intricate temporal patterns in time series and thus hard to get accurate temporal dependence. To address above issues, we propose a novel noise-aware efficient spatio-temporal Transformer architecture for accurate traffic forecasting, named STformer. STformer consists of two components, which are the noise-aware temporal self-attention (NATSA) and the graph-based sparse spatial self-attention (GBS3A). NATSA separates the high-frequency component and the low-frequency component from the time series to remove noise and capture stable temporal dependence by the learnable filter and the temporal self-attention, respectively. GBS3A replaces the full query in vanilla self-attention with the graph-based sparse query to decrease the time and memory usage. Experiments on four real-world traffic datasets show that STformer outperforms state-of-the-art baselines with lower computational cost.
Indian Language Wordnets and their Linkages with Princeton WordNet
Jan 09, 2022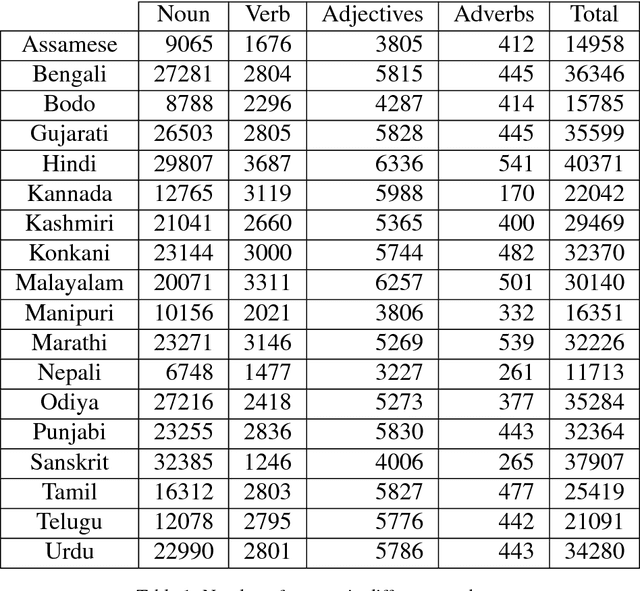
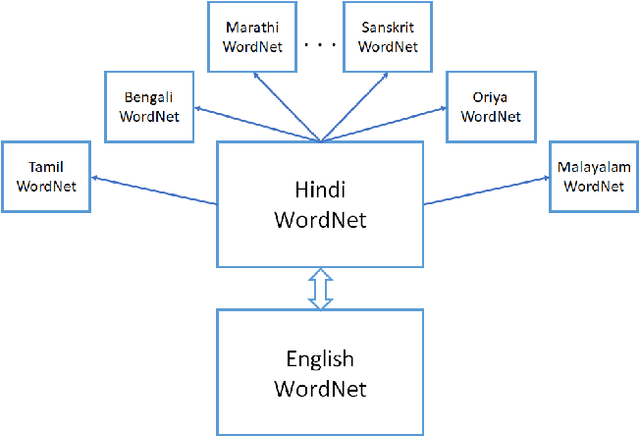
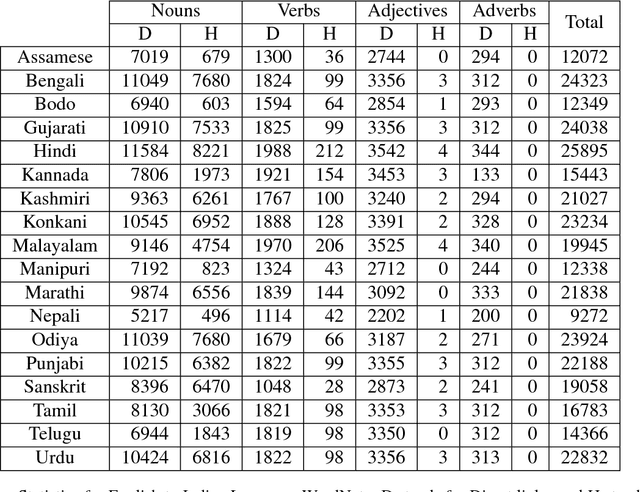
Wordnets are rich lexico-semantic resources. Linked wordnets are extensions of wordnets, which link similar concepts in wordnets of different languages. Such resources are extremely useful in many Natural Language Processing (NLP) applications, primarily those based on knowledge-based approaches. In such approaches, these resources are considered as gold standard/oracle. Thus, it is crucial that these resources hold correct information. Thereby, they are created by human experts. However, human experts in multiple languages are hard to come by. Thus, the community would benefit from sharing of such manually created resources. In this paper, we release mappings of 18 Indian language wordnets linked with Princeton WordNet. We believe that availability of such resources will have a direct impact on the progress in NLP for these languages.
Contrastive Representation Learning with Trainable Augmentation Channel
Nov 15, 2021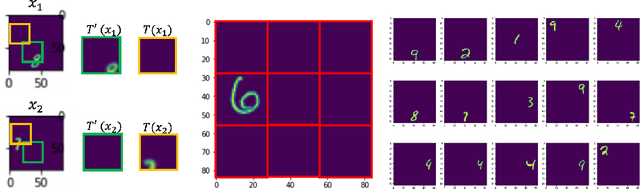

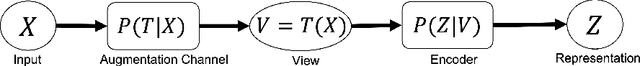

In contrastive representation learning, data representation is trained so that it can classify the image instances even when the images are altered by augmentations. However, depending on the datasets, some augmentations can damage the information of the images beyond recognition, and such augmentations can result in collapsed representations. We present a partial solution to this problem by formalizing a stochastic encoding process in which there exist a tug-of-war between the data corruption introduced by the augmentations and the information preserved by the encoder. We show that, with the infoMax objective based on this framework, we can learn a data-dependent distribution of augmentations to avoid the collapse of the representation.
Unsupervised Anomaly Detection in MR Images using Multi-Contrast Information
May 02, 2021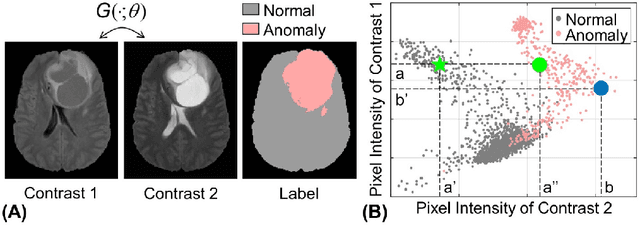
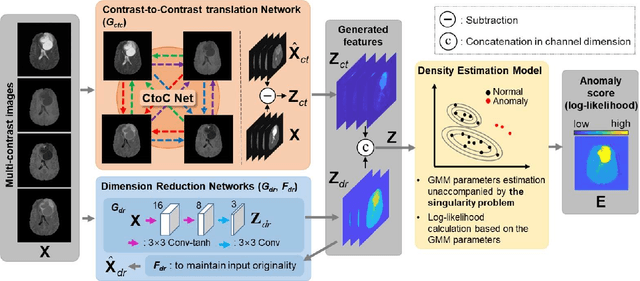
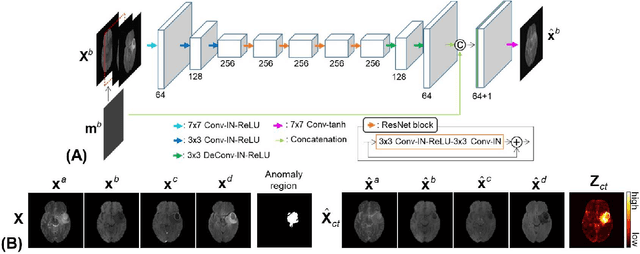
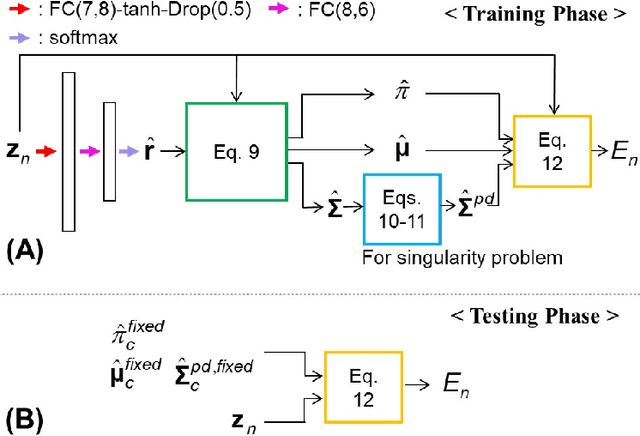
Anomaly detection in medical imaging is to distinguish the relevant biomarkers of diseases from those of normal tissues. Deep supervised learning methods have shown potentials in various detection tasks, but its performances would be limited in medical imaging fields where collecting annotated anomaly data is limited and labor-intensive. Therefore, unsupervised anomaly detection can be an effective tool for clinical practices, which uses only unlabeled normal images as training data. In this paper, we developed an unsupervised learning framework for pixel-wise anomaly detection in multi-contrast magnetic resonance imaging (MRI). The framework has two steps of feature generation and density estimation with Gaussian mixture model (GMM). A feature is derived through the learning of contrast-to-contrast translation that effectively captures the normal tissue characteristics in multi-contrast MRI. The feature is collaboratively used with another feature that is the low-dimensional representation of multi-contrast images. In density estimation using GMM, a simple but efficient way is introduced to handle the singularity problem which interrupts the joint learning process. The proposed method outperforms previous anomaly detection approaches. Quantitative and qualitative analyses demonstrate the effectiveness of the proposed method in anomaly detection for multi-contrast MRI.