 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLATA: A Tool for LLM-Assisted Translation Annotation
Feb 11, 2026The construction of high-quality parallel corpora for translation research has increasingly evolved from simple sentence alignment to complex, multi-layered annotation tasks. This methodological shift presents significant challenges for structurally divergent language pairs, such as Arabic--English, where standard automated tools frequently fail to capture deep linguistic shifts or semantic nuances. This paper introduces a novel, LLM-assisted interactive tool designed to reduce the gap between scalable automation and the rigorous precision required for expert human judgment. Unlike traditional statistical aligners, our system employs a template-based Prompt Manager that leverages large language models (LLMs) for sentence segmentation and alignment under strict JSON output constraints. In this tool, automated preprocessing integrates into a human-in-the-loop workflow, allowing researchers to refine alignments and apply custom translation technique annotations through a stand-off architecture. By leveraging LLM-assisted processing, the tool balances annotation efficiency with the linguistic precision required to analyze complex translation phenomena in specialized domains.
AlignAR: Generative Sentence Alignment for Arabic-English Parallel Corpora of Legal and Literary Texts
Dec 26, 2025High-quality parallel corpora are essential for Machine Translation (MT) research and translation teaching. However, Arabic-English resources remain scarce and existing datasets mainly consist of simple one-to-one mappings. In this paper, we present AlignAR, a generative sentence alignment method, and a new Arabic-English dataset comprising complex legal and literary texts. Our evaluation demonstrates that "Easy" datasets lack the discriminatory power to fully assess alignment methods. By reducing one-to-one mappings in our "Hard" subset, we exposed the limitations of traditional alignment methods. In contrast, LLM-based approaches demonstrated superior robustness, achieving an overall F1-score of 85.5%, a 9% improvement over previous methods. Our datasets and codes are open-sourced at https://github.com/XXX.
Tracing Origins: Coref-aware Machine Reading Comprehension
Oct 15, 2021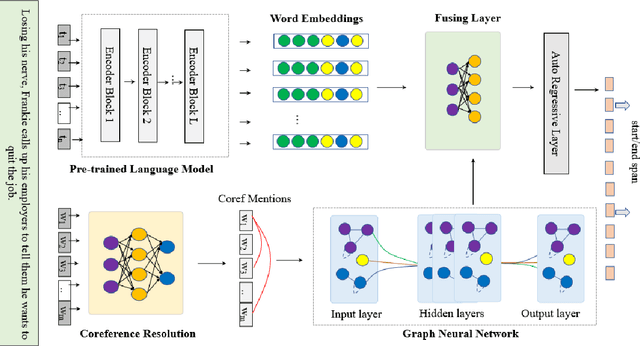

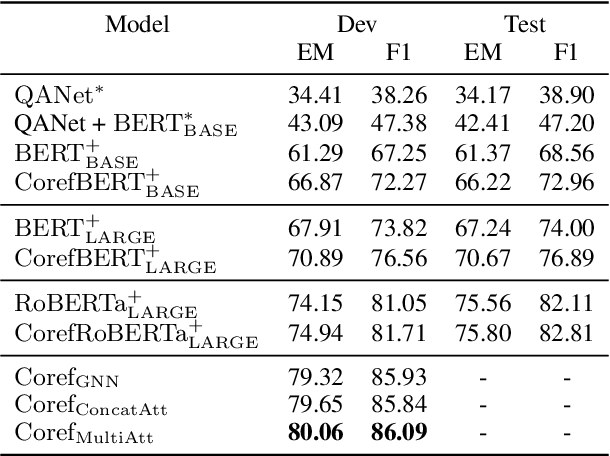
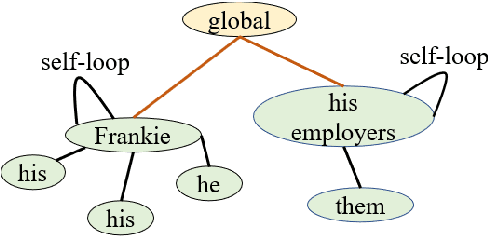
Machine reading comprehension is a heavily-studied research and test field for evaluating new pre-trained models and fine-tuning strategies, and recent studies have enriched the pre-trained models with syntactic, semantic and other linguistic information to improve the performance of the model. In this paper, we imitated the human's reading process in connecting the anaphoric expressions and explicitly leverage the coreference information to enhance the word embeddings from the pre-trained model, in order to highlight the coreference mentions that must be identified for coreference-intensive question answering in QUOREF, a relatively new dataset that is specifically designed to evaluate the coreference-related performance of a model. We used an additional BERT layer to focus on the coreference mentions, and a Relational Graph Convolutional Network to model the coreference relations. We demonstrated that the explicit incorporation of the coreference information in fine-tuning stage performed better than the incorporation of the coreference information in training a pre-trained language models.