 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
General lower bounds for interactive high-dimensional estimation under information constraints
Oct 20, 2020
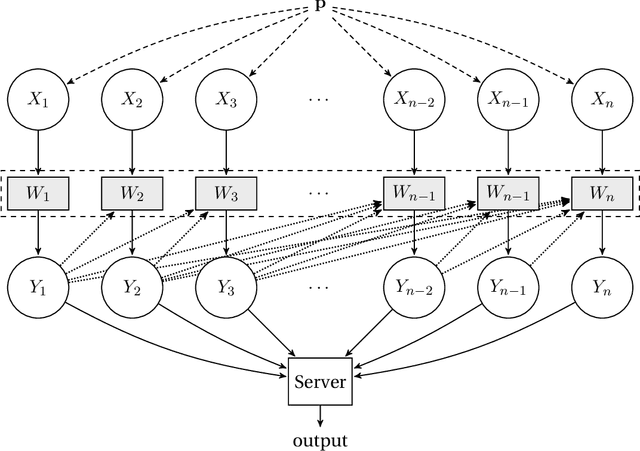


We consider the task of distributed parameter estimation using sequentially interactive protocols subject to local information constraints such as bandwidth limitations, local differential privacy, and restricted measurements. We provide a general framework enabling us to derive a variety of (tight) minimax lower bounds under different parametric families of distributions, both continuous and discrete, under any $\ell_p$ loss. Our lower bound framework is versatile, and yields "plug-and-play" bounds that are widely applicable to a large range of estimation problems. For the families considered, we further complement our lower bounds with matching upper bounds.
FAMLP: A Frequency-Aware MLP-Like Architecture For Domain Generalization
Mar 24, 2022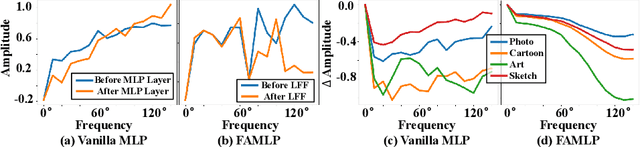
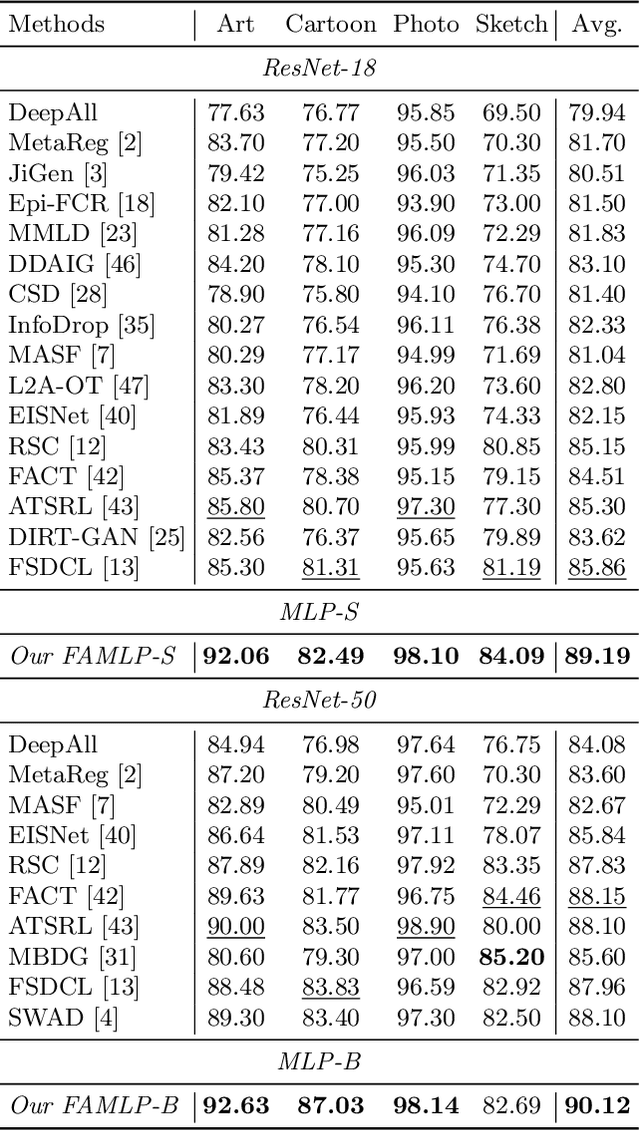
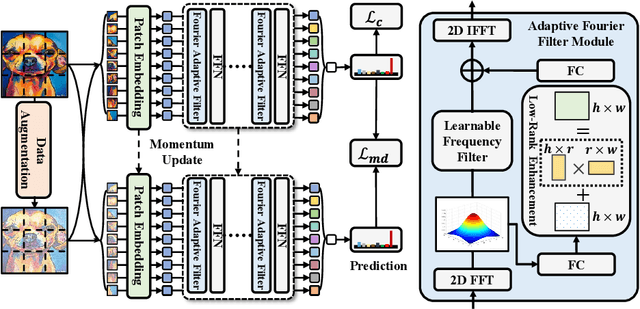
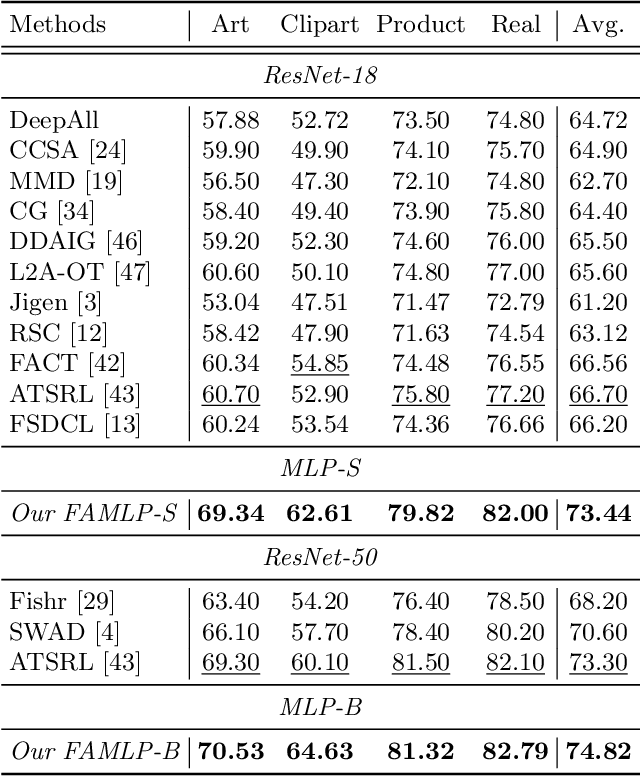
MLP-like models built entirely upon multi-layer perceptrons have recently been revisited, exhibiting the comparable performance with transformers. It is one of most promising architectures due to the excellent trade-off between network capability and efficiency in the large-scale recognition tasks. However, its generalization performance to heterogeneous tasks is inferior to other architectures (e.g., CNNs and transformers) due to the extensive retention of domain information. To address this problem, we propose a novel frequency-aware MLP architecture, in which the domain-specific features are filtered out in the transformed frequency domain, augmenting the invariant descriptor for label prediction. Specifically, we design an adaptive Fourier filter layer, in which a learnable frequency filter is utilized to adjust the amplitude distribution by optimizing both the real and imaginary parts. A low-rank enhancement module is further proposed to rectify the filtered features by adding the low-frequency components from SVD decomposition. Finally, a momentum update strategy is utilized to stabilize the optimization to fluctuation of model parameters and inputs by the output distillation with weighted historical states. To our best knowledge, we are the first to propose a MLP-like backbone for domain generalization. Extensive experiments on three benchmarks demonstrate significant generalization performance, outperforming the state-of-the-art methods by a margin of 3%, 4% and 9%, respectively.
Learning Q-network for Active Information Acquisition
Oct 23, 2019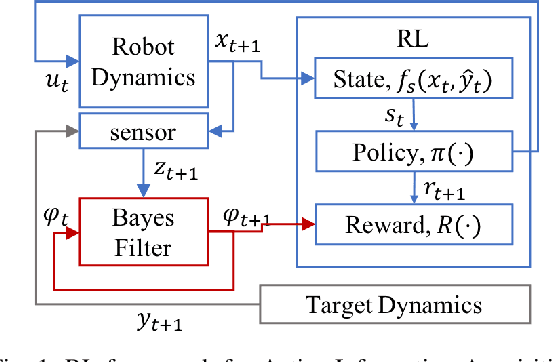
In this paper, we propose a novel Reinforcement Learning approach for solving the Active Information Acquisition problem, which requires an agent to choose a sequence of actions in order to acquire information about a process of interest using on-board sensors. The classic challenges in the information acquisition problem are the dependence of a planning algorithm on known models and the difficulty of computing information-theoretic cost functions over arbitrary distributions. In contrast, the proposed framework of reinforcement learning does not require any knowledge on models and alleviates the problems during an extended training stage. It results in policies that are efficient to execute online and applicable for real-time control of robotic systems. Furthermore, the state-of-the-art planning methods are typically restricted to short horizons, which may become problematic with local minima. Reinforcement learning naturally handles the issue of planning horizon in information problems as it maximizes a discounted sum of rewards over a long finite or infinite time horizon. We discuss the potential benefits of the proposed framework and compare the performance of the novel algorithm to an existing information acquisition method for multi-target tracking scenarios.
* IROS 2019, Video https://youtu.be/0ZFyOWJ2ulo
RGB-D SLAM Using Attention Guided Frame Association
Jan 28, 2022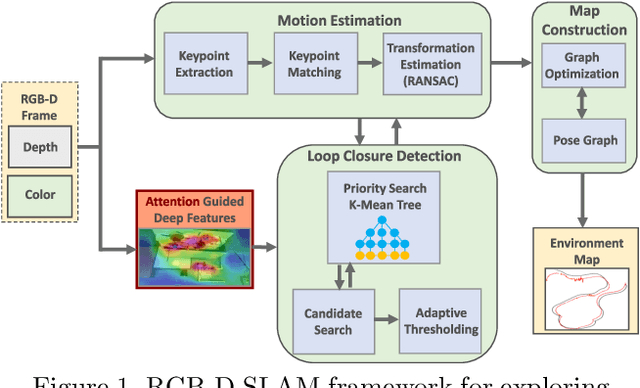
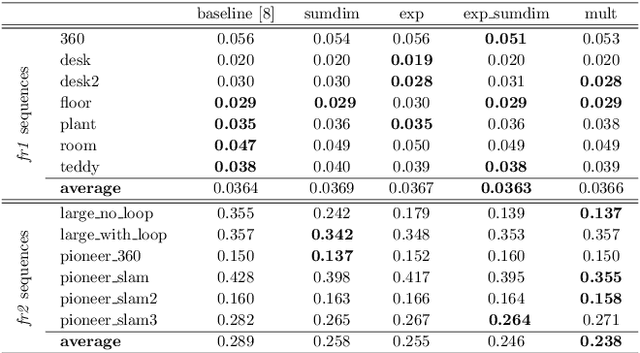
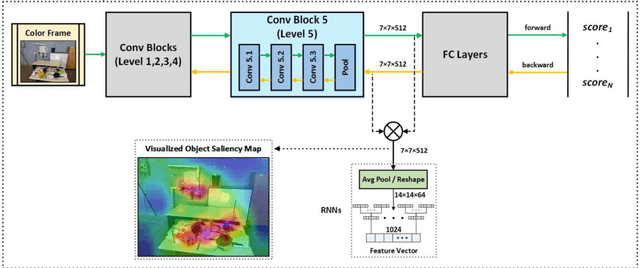
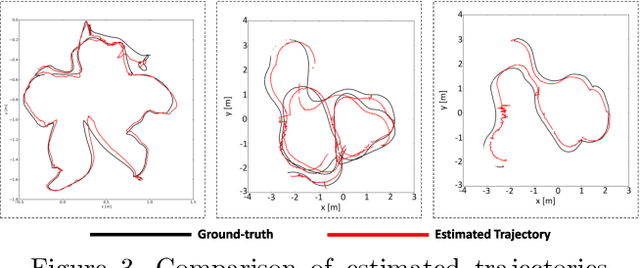
Deep learning models as an emerging topic have shown great progress in various fields. Especially, visualization tools such as class activation mapping methods provided visual explanation on the reasoning of convolutional neural networks (CNNs). By using the gradients of the network layers, it is possible to demonstrate where the networks pay attention during a specific image recognition task. Moreover, these gradients can be integrated with CNN features for localizing more generalized task dependent attentive (salient) objects in scenes. Despite this progress, there is not much explicit usage of this gradient (network attention) information to integrate with CNN representations for object semantics. This can be very useful for visual tasks such as simultaneous localization and mapping (SLAM) where CNN representations of spatially attentive object locations may lead to improved performance. Therefore, in this work, we propose the use of task specific network attention for RGB-D indoor SLAM. To do so, we integrate layer-wise object attention information (layer gradients) with CNN layer representations to improve frame association performance in a state-of-the-art RGB-D indoor SLAM method. Experiments show promising initial results with improved performance.
New Projection-free Algorithms for Online Convex Optimization with Adaptive Regret Guarantees
Feb 09, 2022
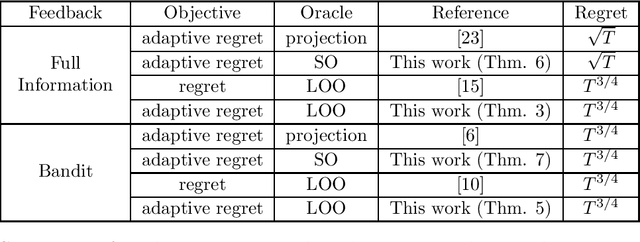
We present new efficient \textit{projection-free} algorithms for online convex optimization (OCO), where by projection-free we refer to algorithms that avoid computing orthogonal projections onto the feasible set, and instead relay on different and potentially much more efficient oracles. While most state-of-the-art projection-free algorithms are based on the \textit{follow-the-leader} framework, our algorithms are fundamentally different and are based on the \textit{online gradient descent} algorithm with a novel and efficient approach to computing so-called \textit{infeasible projections}. As a consequence, we obtain the first projection-free algorithms which naturally yield \textit{adaptive regret} guarantees, i.e., regret bounds that hold w.r.t. any sub-interval of the sequence. Concretely, when assuming the availability of a linear optimization oracle (LOO) for the feasible set, on a sequence of length $T$, our algorithms guarantee $O(T^{3/4})$ adaptive regret and $O(T^{3/4})$ adaptive expected regret, for the full-information and bandit settings, respectively, using only $O(T)$ calls to the LOO. These bounds match the current state-of-the-art regret bounds for LOO-based projection-free OCO, which are \textit{not adaptive}. We also consider a new natural setting in which the feasible set is accessible through a separation oracle. We present algorithms which, using overall $O(T)$ calls to the separation oracle, guarantee $O(\sqrt{T})$ adaptive regret and $O(T^{3/4})$ adaptive expected regret for the full-information and bandit settings, respectively.
Text is no more Enough! A Benchmark for Profile-based Spoken Language Understanding
Dec 22, 2021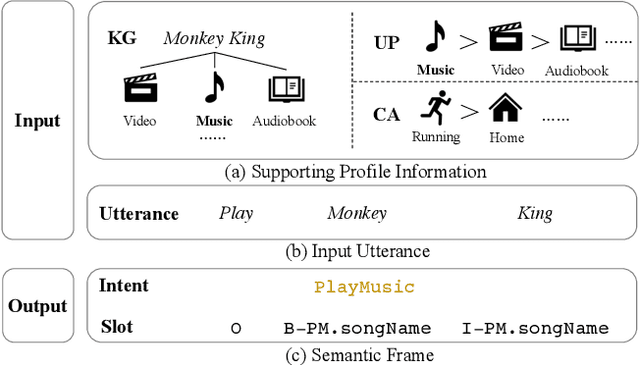
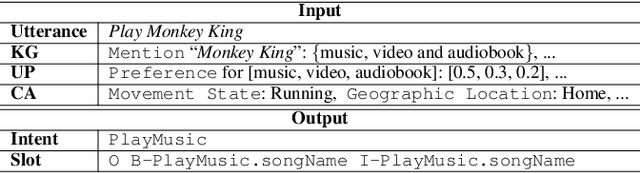
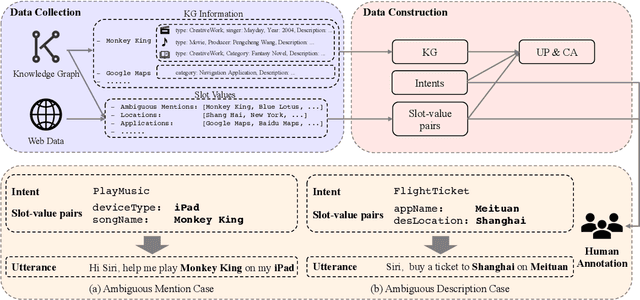
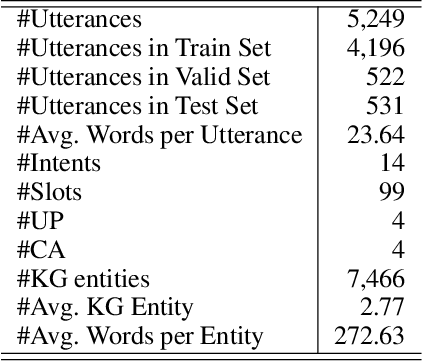
Current researches on spoken language understanding (SLU) heavily are limited to a simple setting: the plain text-based SLU that takes the user utterance as input and generates its corresponding semantic frames (e.g., intent and slots). Unfortunately, such a simple setting may fail to work in complex real-world scenarios when an utterance is semantically ambiguous, which cannot be achieved by the text-based SLU models. In this paper, we first introduce a new and important task, Profile-based Spoken Language Understanding (ProSLU), which requires the model that not only relies on the plain text but also the supporting profile information to predict the correct intents and slots. To this end, we further introduce a large-scale human-annotated Chinese dataset with over 5K utterances and their corresponding supporting profile information (Knowledge Graph (KG), User Profile (UP), Context Awareness (CA)). In addition, we evaluate several state-of-the-art baseline models and explore a multi-level knowledge adapter to effectively incorporate profile information. Experimental results reveal that all existing text-based SLU models fail to work when the utterances are semantically ambiguous and our proposed framework can effectively fuse the supporting information for sentence-level intent detection and token-level slot filling. Finally, we summarize key challenges and provide new points for future directions, which hopes to facilitate the research.
An Exploratory Study on Code Attention in BERT
Apr 05, 2022
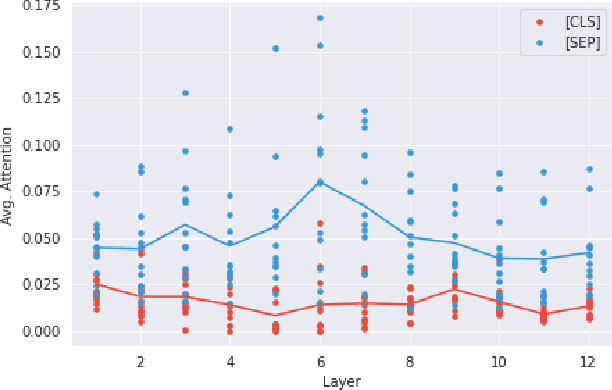

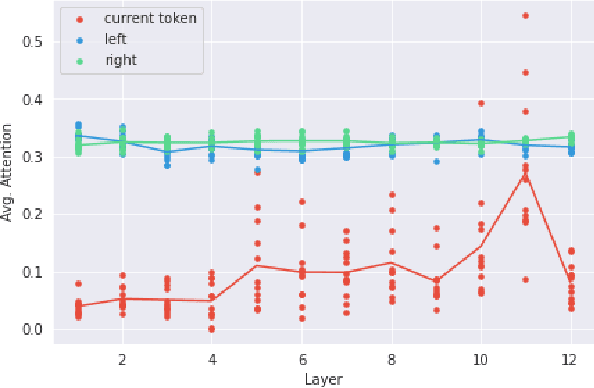
Many recent models in software engineering introduced deep neural models based on the Transformer architecture or use transformer-based Pre-trained Language Models (PLM) trained on code. Although these models achieve the state of the arts results in many downstream tasks such as code summarization and bug detection, they are based on Transformer and PLM, which are mainly studied in the Natural Language Processing (NLP) field. The current studies rely on the reasoning and practices from NLP for these models in code, despite the differences between natural languages and programming languages. There is also limited literature on explaining how code is modeled. Here, we investigate the attention behavior of PLM on code and compare it with natural language. We pre-trained BERT, a Transformer based PLM, on code and explored what kind of information it learns, both semantic and syntactic. We run several experiments to analyze the attention values of code constructs on each other and what BERT learns in each layer. Our analyses show that BERT pays more attention to syntactic entities, specifically identifiers and separators, in contrast to the most attended token [CLS] in NLP. This observation motivated us to leverage identifiers to represent the code sequence instead of the [CLS] token when used for code clone detection. Our results show that employing embeddings from identifiers increases the performance of BERT by 605% and 4% F1-score in its lower layers and the upper layers, respectively. When identifiers' embeddings are used in CodeBERT, a code-based PLM, the performance is improved by 21-24% in the F1-score of clone detection. The findings can benefit the research community by using code-specific representations instead of applying the common embeddings used in NLP, and open new directions for developing smaller models with similar performance.
DHEN: A Deep and Hierarchical Ensemble Network for Large-Scale Click-Through Rate Prediction
Mar 11, 2022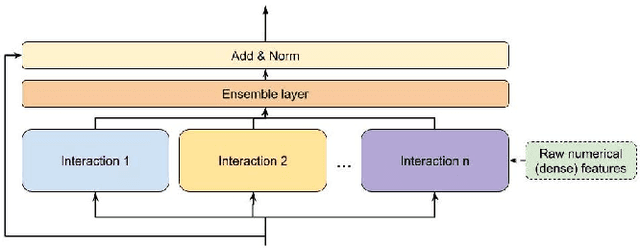
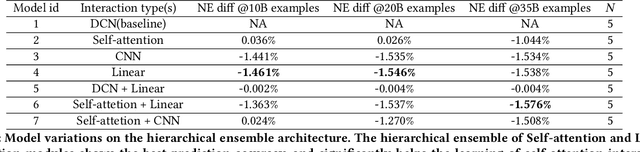
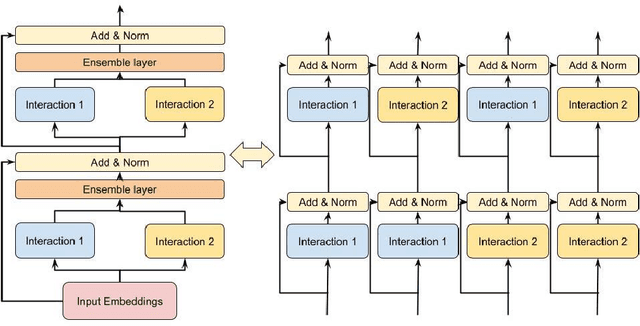

Learning feature interactions is important to the model performance of online advertising services. As a result, extensive efforts have been devoted to designing effective architectures to learn feature interactions. However, we observe that the practical performance of those designs can vary from dataset to dataset, even when the order of interactions claimed to be captured is the same. That indicates different designs may have different advantages and the interactions captured by them have non-overlapping information. Motivated by this observation, we propose DHEN - a deep and hierarchical ensemble architecture that can leverage strengths of heterogeneous interaction modules and learn a hierarchy of the interactions under different orders. To overcome the challenge brought by DHEN's deeper and multi-layer structure in training, we propose a novel co-designed training system that can further improve the training efficiency of DHEN. Experiments of DHEN on large-scale dataset from CTR prediction tasks attained 0.27\% improvement on the Normalized Entropy (NE) of prediction and 1.2x better training throughput than state-of-the-art baseline, demonstrating their effectiveness in practice.
Uplink-Downlink Duality and Precoding Strategies with Partial CSI in Cell-Free Wireless Networks
Jan 13, 2022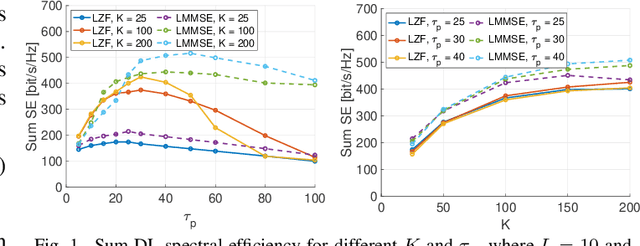
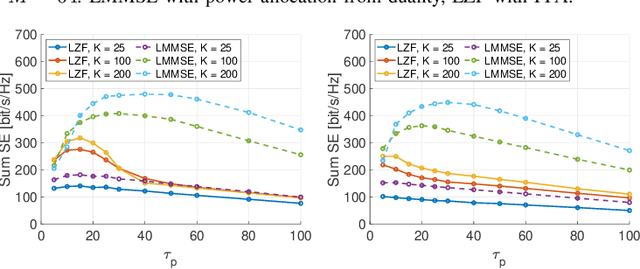
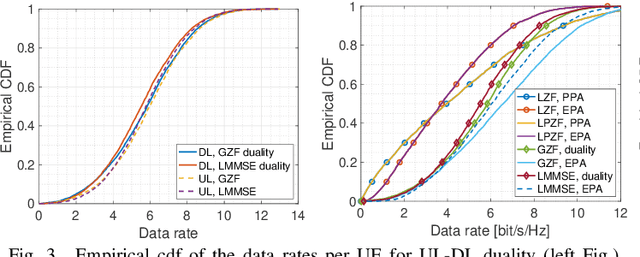
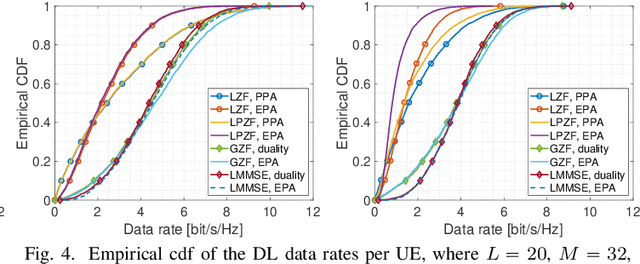
We consider a scalable user-centric wireless network with dynamic cluster formation as defined by Bj\"ornsson and Sanguinetti. After having shown the importance of dominant channel subspace information for uplink (UL) pilot decontamination and having examined different UL combining schemes in our previous work, here we investigate precoding strategies for the downlink (DL). Distributed scalable DL precoding and power allocation methods are evaluated for different antenna distributions, user densities and UL pilot dimensions. We compare distributed power allocation methods to a scheme based on a particular form of UL-DL duality which is computable by a central processor based on the available partial channel state information. The new duality method achieves almost symmetric "optimistic ergodic rates" for UL and DL while saving considerable computational complexity since the UL combining vectors are reused as DL precoders.
PatchNet: A Simple Face Anti-Spoofing Framework via Fine-Grained Patch Recognition
Mar 27, 2022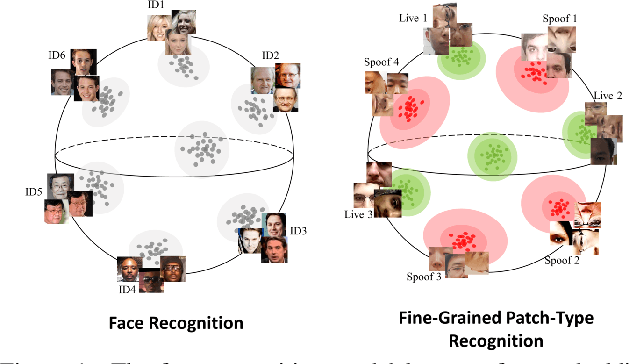
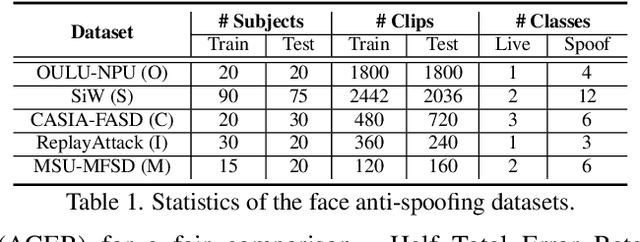
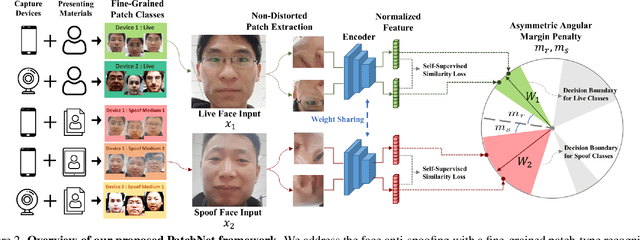
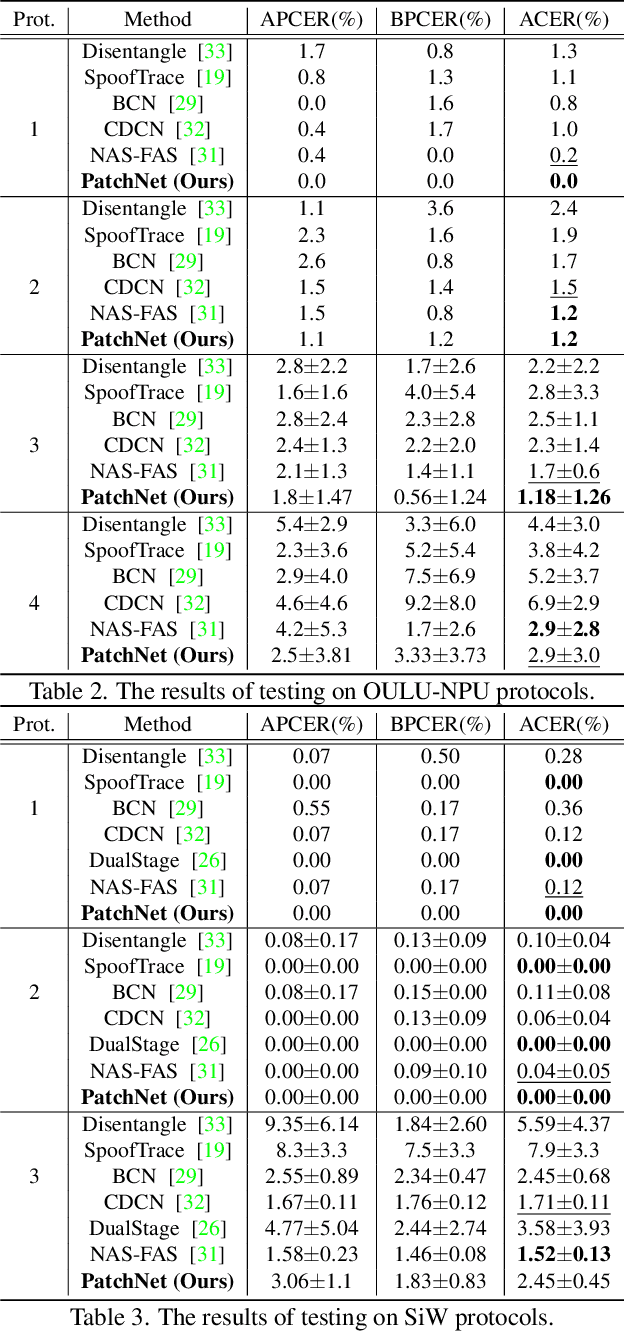
Face anti-spoofing (FAS) plays a critical role in securing face recognition systems from different presentation attacks. Previous works leverage auxiliary pixel-level supervision and domain generalization approaches to address unseen spoof types. However, the local characteristics of image captures, i.e., capturing devices and presenting materials, are ignored in existing works and we argue that such information is required for networks to discriminate between live and spoof images. In this work, we propose PatchNet which reformulates face anti-spoofing as a fine-grained patch-type recognition problem. To be specific, our framework recognizes the combination of capturing devices and presenting materials based on the patches cropped from non-distorted face images. This reformulation can largely improve the data variation and enforce the network to learn discriminative feature from local capture patterns. In addition, to further improve the generalization ability of the spoof feature, we propose the novel Asymmetric Margin-based Classification Loss and Self-supervised Similarity Loss to regularize the patch embedding space. Our experimental results verify our assumption and show that the model is capable of recognizing unseen spoof types robustly by only looking at local regions. Moreover, the fine-grained and patch-level reformulation of FAS outperforms the existing approaches on intra-dataset, cross-dataset, and domain generalization benchmarks. Furthermore, our PatchNet framework can enable practical applications like Few-Shot Reference-based FAS and facilitate future exploration of spoof-related intrinsic cues.