 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEntropy Equivalence Testing
May 22, 2026We introduce the problem of \emph{entropy equivalence testing} for probability distributions, a relaxation of the well-studied closeness testing problem, where the distribution testing algorithm is now only required to distinguish, given samples from two unknown distributions $p,q$ and a parameter $\varepsilon \in(0,1/2]$, between $p=q$ and $|H(p)-H(q)| \geq \varepsilon$ (where $H$ denotes the Shannon entropy). We provide a time- and sample-efficient algorithm for this task, showing that the optimal sample complexity for this task can be significantly lower than that of closeness testing. As an application, we leverage this result to provide the first non-trivial testing algorithm for (standard) closeness of low-degree \emph{Bayesian networks}, which significantly improves on either the sample or time complexity of a baseline based on full learning.
Learning bounded-degree polytrees with known skeleton
Oct 10, 2023



We establish finite-sample guarantees for efficient proper learning of bounded-degree polytrees, a rich class of high-dimensional probability distributions and a subclass of Bayesian networks, a widely-studied type of graphical model. Recently, Bhattacharyya et al. (2021) obtained finite-sample guarantees for recovering tree-structured Bayesian networks, i.e., 1-polytrees. We extend their results by providing an efficient algorithm which learns $d$-polytrees in polynomial time and sample complexity for any bounded $d$ when the underlying undirected graph (skeleton) is known. We complement our algorithm with an information-theoretic sample complexity lower bound, showing that the dependence on the dimension and target accuracy parameters are nearly tight.
Tight Bounds for Machine Unlearning via Differential Privacy
Sep 02, 2023We consider the formulation of "machine unlearning" of Sekhari, Acharya, Kamath, and Suresh (NeurIPS 2021), which formalizes the so-called "right to be forgotten" by requiring that a trained model, upon request, should be able to "unlearn" a number of points from the training data, as if they had never been included in the first place. Sekhari et al. established some positive and negative results about the number of data points that can be successfully unlearnt by a trained model without impacting the model's accuracy (the "deletion capacity"), showing that machine unlearning could be achieved by using differentially private (DP) algorithms. However, their results left open a gap between upper and lower bounds on the deletion capacity of these algorithms: our work fully closes this gap, obtaining tight bounds on the deletion capacity achievable by DP-based machine unlearning algorithms.
Private Distribution Learning with Public Data: The View from Sample Compression
Aug 14, 2023We study the problem of private distribution learning with access to public data. In this setup, which we refer to as public-private learning, the learner is given public and private samples drawn from an unknown distribution $p$ belonging to a class $\mathcal Q$, with the goal of outputting an estimate of $p$ while adhering to privacy constraints (here, pure differential privacy) only with respect to the private samples. We show that the public-private learnability of a class $\mathcal Q$ is connected to the existence of a sample compression scheme for $\mathcal Q$, as well as to an intermediate notion we refer to as list learning. Leveraging this connection: (1) approximately recovers previous results on Gaussians over $\mathbb R^d$; and (2) leads to new ones, including sample complexity upper bounds for arbitrary $k$-mixtures of Gaussians over $\mathbb R^d$, results for agnostic and distribution-shift resistant learners, as well as closure properties for public-private learnability under taking mixtures and products of distributions. Finally, via the connection to list learning, we show that for Gaussians in $\mathbb R^d$, at least $d$ public samples are necessary for private learnability, which is close to the known upper bound of $d+1$ public samples.
Near-Optimal Degree Testing for Bayes Nets
Apr 13, 2023This paper considers the problem of testing the maximum in-degree of the Bayes net underlying an unknown probability distribution $P$ over $\{0,1\}^n$, given sample access to $P$. We show that the sample complexity of the problem is $\tilde{\Theta}(2^{n/2}/\varepsilon^2)$. Our algorithm relies on a testing-by-learning framework, previously used to obtain sample-optimal testers; in order to apply this framework, we develop new algorithms for ``near-proper'' learning of Bayes nets, and high-probability learning under $\chi^2$ divergence, which are of independent interest.
Concentration Bounds for Discrete Distribution Estimation in KL Divergence
Feb 14, 2023We study the problem of discrete distribution estimation in KL divergence and provide concentration bounds for the Laplace estimator. We show that the deviation from mean scales as $\sqrt{k}/n$ when $n \ge k$, improving upon the best prior result of $k/n$. We also establish a matching lower bound that shows that our bounds are tight up to polylogarithmic factors.
Near-Optimal Bounds for Testing Histogram Distributions
Jul 14, 2022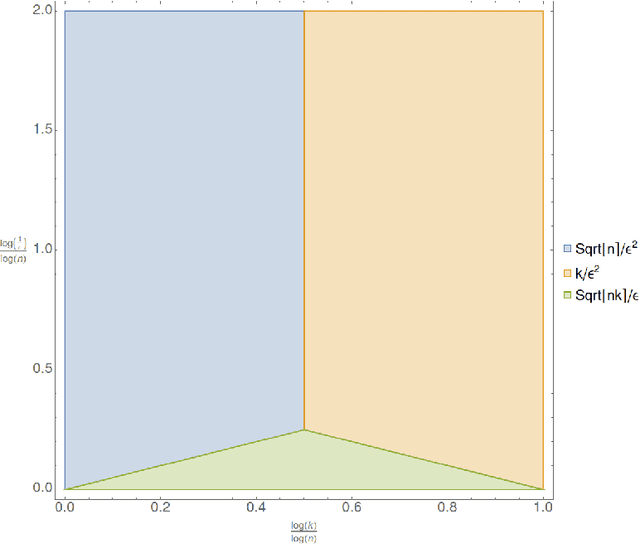
We investigate the problem of testing whether a discrete probability distribution over an ordered domain is a histogram on a specified number of bins. One of the most common tools for the succinct approximation of data, $k$-histograms over $[n]$, are probability distributions that are piecewise constant over a set of $k$ intervals. The histogram testing problem is the following: Given samples from an unknown distribution $\mathbf{p}$ on $[n]$, we want to distinguish between the cases that $\mathbf{p}$ is a $k$-histogram versus $\varepsilon$-far from any $k$-histogram, in total variation distance. Our main result is a sample near-optimal and computationally efficient algorithm for this testing problem, and a nearly-matching (within logarithmic factors) sample complexity lower bound. Specifically, we show that the histogram testing problem has sample complexity $\widetilde \Theta (\sqrt{nk} / \varepsilon + k / \varepsilon^2 + \sqrt{n} / \varepsilon^2)$.
Private independence testing across two parties
Jul 08, 2022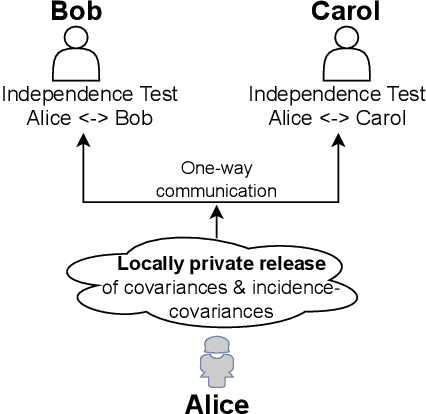

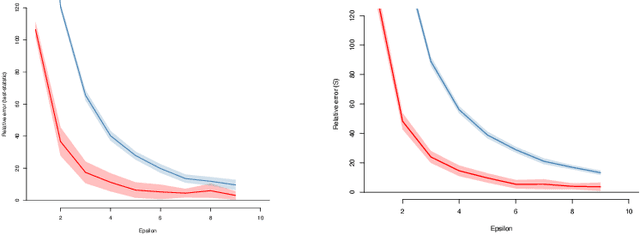
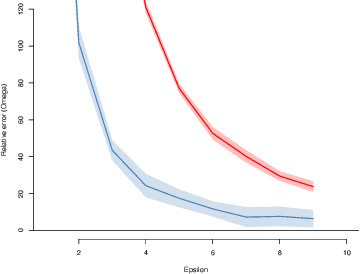
We introduce $\pi$-test, a privacy-preserving algorithm for testing statistical independence between data distributed across multiple parties. Our algorithm relies on privately estimating the distance correlation between datasets, a quantitative measure of independence introduced in Sz\'ekely et al. [2007]. We establish both additive and multiplicative error bounds on the utility of our differentially private test, which we believe will find applications in a variety of distributed hypothesis testing settings involving sensitive data.
Robust Testing in High-Dimensional Sparse Models
May 16, 2022
We consider the problem of robustly testing the norm of a high-dimensional sparse signal vector under two different observation models. In the first model, we are given $n$ i.i.d. samples from the distribution $\mathcal{N}\left(\theta,I_d\right)$ (with unknown $\theta$), of which a small fraction has been arbitrarily corrupted. Under the promise that $\|\theta\|_0\le s$, we want to correctly distinguish whether $\|\theta\|_2=0$ or $\|\theta\|_2>\gamma$, for some input parameter $\gamma>0$. We show that any algorithm for this task requires $n=\Omega\left(s\log\frac{ed}{s}\right)$ samples, which is tight up to logarithmic factors. We also extend our results to other common notions of sparsity, namely, $\|\theta\|_q\le s$ for any $0 < q < 2$. In the second observation model that we consider, the data is generated according to a sparse linear regression model, where the covariates are i.i.d. Gaussian and the regression coefficient (signal) is known to be $s$-sparse. Here too we assume that an $\epsilon$-fraction of the data is arbitrarily corrupted. We show that any algorithm that reliably tests the norm of the regression coefficient requires at least $n=\Omega\left(\min(s\log d,{1}/{\gamma^4})\right)$ samples. Our results show that the complexity of testing in these two settings significantly increases under robustness constraints. This is in line with the recent observations made in robust mean testing and robust covariance testing.
Independence Testing for Bounded Degree Bayesian Network
Apr 19, 2022
We study the following independence testing problem: given access to samples from a distribution $P$ over $\{0,1\}^n$, decide whether $P$ is a product distribution or whether it is $\varepsilon$-far in total variation distance from any product distribution. For arbitrary distributions, this problem requires $\exp(n)$ samples. We show in this work that if $P$ has a sparse structure, then in fact only linearly many samples are required. Specifically, if $P$ is Markov with respect to a Bayesian network whose underlying DAG has in-degree bounded by $d$, then $\tilde{\Theta}(2^{d/2}\cdot n/\varepsilon^2)$ samples are necessary and sufficient for independence testing.