 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
CroMo: Cross-Modal Learning for Monocular Depth Estimation
Mar 28, 2022
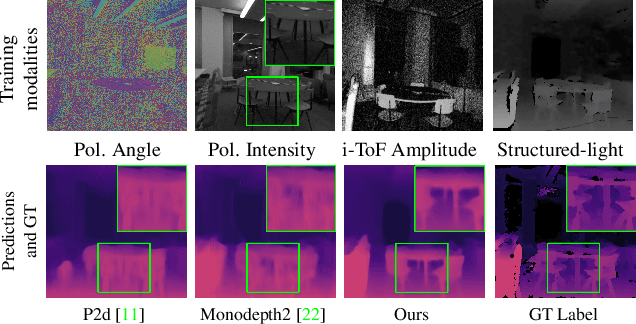
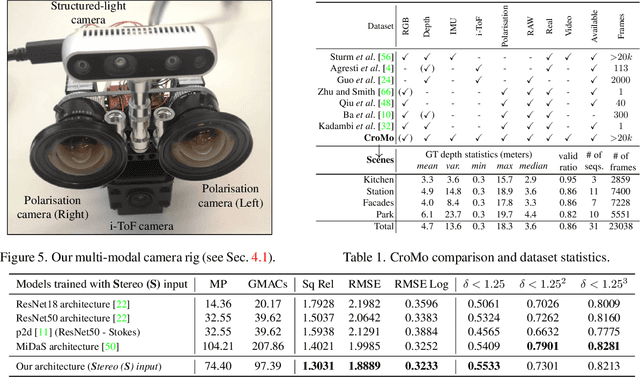

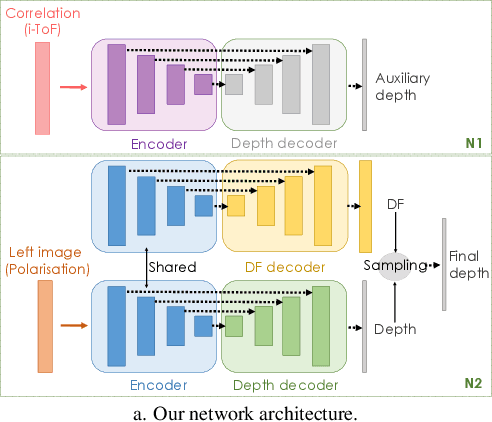
Learning-based depth estimation has witnessed recent progress in multiple directions; from self-supervision using monocular video to supervised methods offering highest accuracy. Complementary to supervision, further boosts to performance and robustness are gained by combining information from multiple signals. In this paper we systematically investigate key trade-offs associated with sensor and modality design choices as well as related model training strategies. Our study leads us to a new method, capable of connecting modality-specific advantages from polarisation, Time-of-Flight and structured-light inputs. We propose a novel pipeline capable of estimating depth from monocular polarisation for which we evaluate various training signals. The inversion of differentiable analytic models thereby connects scene geometry with polarisation and ToF signals and enables self-supervised and cross-modal learning. In the absence of existing multimodal datasets, we examine our approach with a custom-made multi-modal camera rig and collect CroMo; the first dataset to consist of synchronized stereo polarisation, indirect ToF and structured-light depth, captured at video rates. Extensive experiments on challenging video scenes confirm both qualitative and quantitative pipeline advantages where we are able to outperform competitive monocular depth estimation method.
Toward Deep Learning Based Access Control
Mar 28, 2022A common trait of current access control approaches is the challenging need to engineer abstract and intuitive access control models. This entails designing access control information in the form of roles (RBAC), attributes (ABAC), or relationships (ReBAC) as the case may be, and subsequently, designing access control rules. This framework has its benefits but has significant limitations in the context of modern systems that are dynamic, complex, and large-scale, due to which it is difficult to maintain an accurate access control state in the system for a human administrator. This paper proposes Deep Learning Based Access Control (DLBAC) by leveraging significant advances in deep learning technology as a potential solution to this problem. We envision that DLBAC could complement and, in the long-term, has the potential to even replace, classical access control models with a neural network that reduces the burden of access control model engineering and updates. Without loss of generality, we conduct a thorough investigation of a candidate DLBAC model, called DLBAC_alpha, using both real-world and synthetic datasets. We demonstrate the feasibility of the proposed approach by addressing issues related to accuracy, generalization, and explainability. We also discuss challenges and future research directions.
A Set Membership Approach to Discovering Feature Relevance and Explaining Neural Classifier Decisions
Apr 05, 2022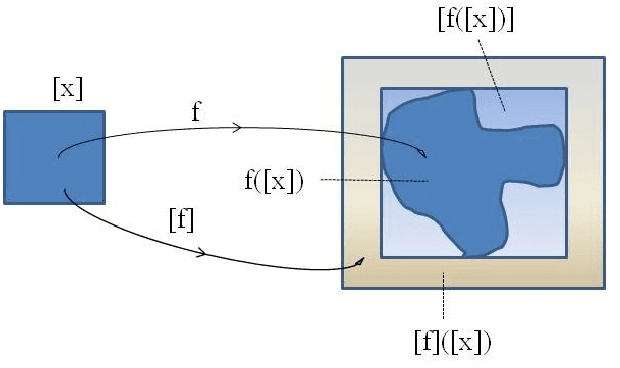
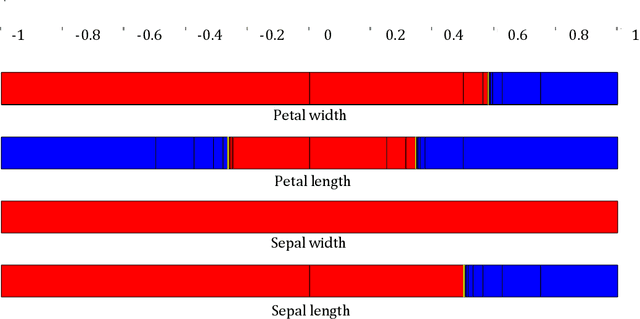
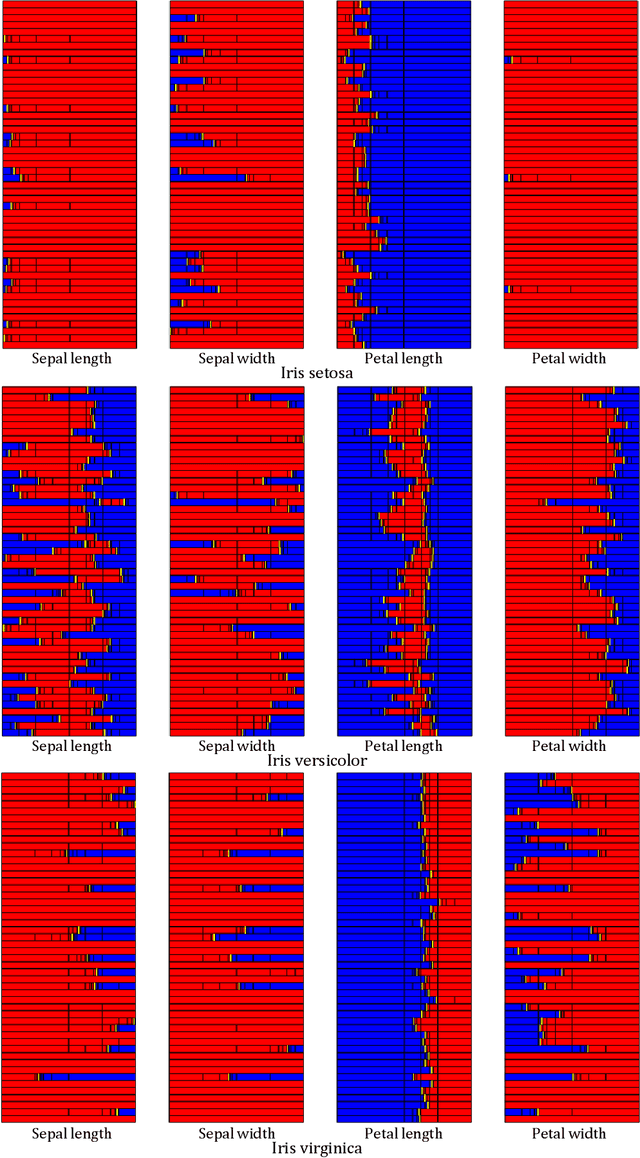
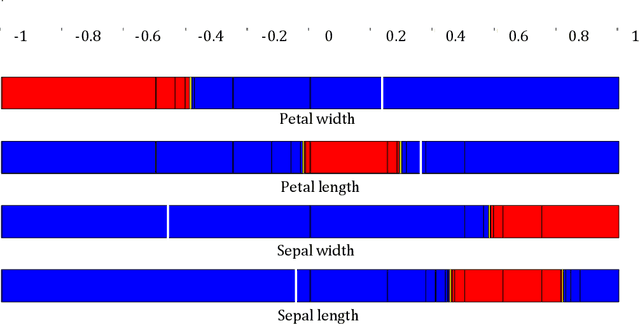
Neural classifiers are non linear systems providing decisions on the classes of patterns, for a given problem they have learned. The output computed by a classifier for each pattern constitutes an approximation of the output of some unknown function, mapping pattern data to their respective classes. The lack of knowledge of such a function along with the complexity of neural classifiers, especially when these are deep learning architectures, do not permit to obtain information on how specific predictions have been made. Hence, these powerful learning systems are considered as black boxes and in critical applications their use tends to be considered inappropriate. Gaining insight on such a black box operation constitutes a one way approach in interpreting operation of neural classifiers and assessing the validity of their decisions. In this paper we tackle this problem introducing a novel methodology for discovering which features are considered relevant by a trained neural classifier and how they affect the classifier's output, thus obtaining an explanation on its decision. Although, feature relevance has received much attention in the machine learning literature here we reconsider it in terms of nonlinear parameter estimation targeted by a set membership approach which is based on interval analysis. Hence, the proposed methodology builds on sound mathematical approaches and the results obtained constitute a reliable estimation of the classifier's decision premises.
The Variational Bandwidth Bottleneck: Stochastic Evaluation on an Information Budget
Apr 24, 2020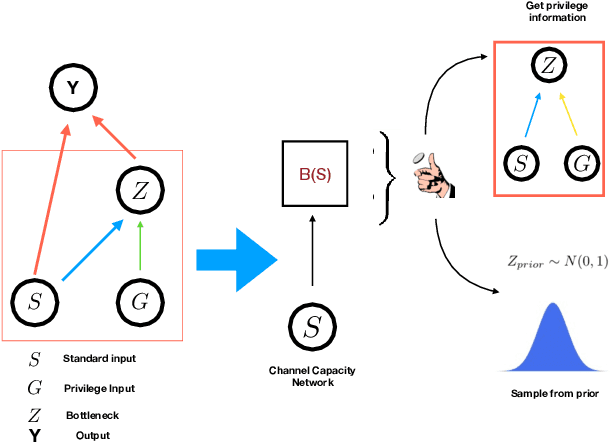

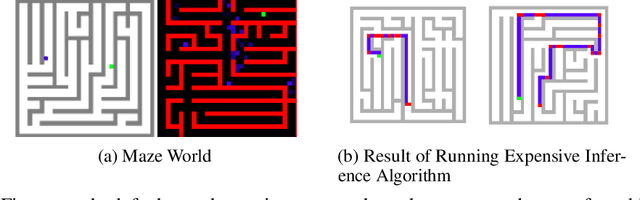
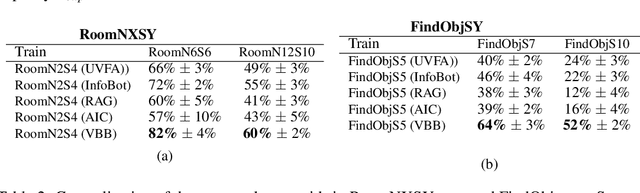
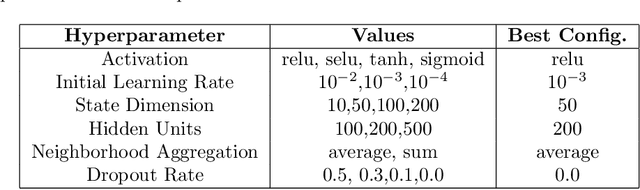
In many applications, it is desirable to extract only the relevant information from complex input data, which involves making a decision about which input features are relevant. The information bottleneck method formalizes this as an information-theoretic optimization problem by maintaining an optimal tradeoff between compression (throwing away irrelevant input information), and predicting the target. In many problem settings, including the reinforcement learning problems we consider in this work, we might prefer to compress only part of the input. This is typically the case when we have a standard conditioning input, such as a state observation, and a "privileged" input, which might correspond to the goal of a task, the output of a costly planning algorithm, or communication with another agent. In such cases, we might prefer to compress the privileged input, either to achieve better generalization (e.g., with respect to goals) or to minimize access to costly information (e.g., in the case of communication). Practical implementations of the information bottleneck based on variational inference require access to the privileged input in order to compute the bottleneck variable, so although they perform compression, this compression operation itself needs unrestricted, lossless access. In this work, we propose the variational bandwidth bottleneck, which decides for each example on the estimated value of the privileged information before seeing it, i.e., only based on the standard input, and then accordingly chooses stochastically, whether to access the privileged input or not. We formulate a tractable approximation to this framework and demonstrate in a series of reinforcement learning experiments that it can improve generalization and reduce access to computationally costly information.
Modular multi-source prediction of drug side-effects with DruGNN
Feb 15, 2022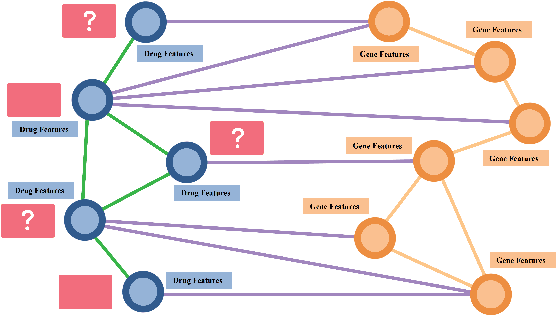
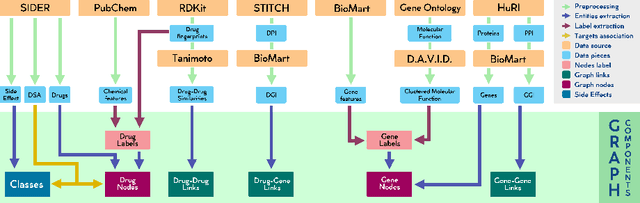

Drug Side-Effects (DSEs) have a high impact on public health, care system costs, and drug discovery processes. Predicting the probability of side-effects, before their occurrence, is fundamental to reduce this impact, in particular on drug discovery. Candidate molecules could be screened before undergoing clinical trials, reducing the costs in time, money, and health of the participants. Drug side-effects are triggered by complex biological processes involving many different entities, from drug structures to protein-protein interactions. To predict their occurrence, it is necessary to integrate data from heterogeneous sources. In this work, such heterogeneous data is integrated into a graph dataset, expressively representing the relational information between different entities, such as drug molecules and genes. The relational nature of the dataset represents an important novelty for drug side-effect predictors. Graph Neural Networks (GNNs) are exploited to predict DSEs on our dataset with very promising results. GNNs are deep learning models that can process graph-structured data, with minimal information loss, and have been applied on a wide variety of biological tasks. Our experimental results confirm the advantage of using relationships between data entities, suggesting interesting future developments in this scope. The experimentation also shows the importance of specific subsets of data in determining associations between drugs and side-effects.
On Mutual Information in Contrastive Learning for Visual Representations
May 27, 2020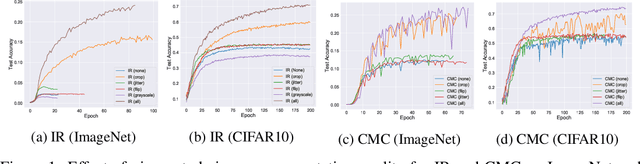
In recent years, several unsupervised, "contrastive" learning algorithms in vision have been shown to learn representations that perform remarkably well on transfer tasks. We show that this family of algorithms maximizes a lower bound on the mutual information between two or more "views" of an image; typical views come from a composition of image augmentations. Our bound generalizes the InfoNCE objective to support negative sampling from a restricted region of "difficult" contrasts. We find that the choice of (1) negative samples and (2) "views" are critical to the success of contrastive learning, the former of which is largely unexplored. The mutual information reformulation also simplifies and stabilizes previous learning objectives. In practice, our new objectives yield representations that outperform those learned with previous approaches for transfer to classification, bounding box detection, instance segmentation, and keypoint detection. The mutual information framework provides a unifying and rigorous comparison of approaches to contrastive learning and uncovers the choices that impact representation learning.
Score difficulty analysis for piano performance education based on fingering
Mar 24, 2022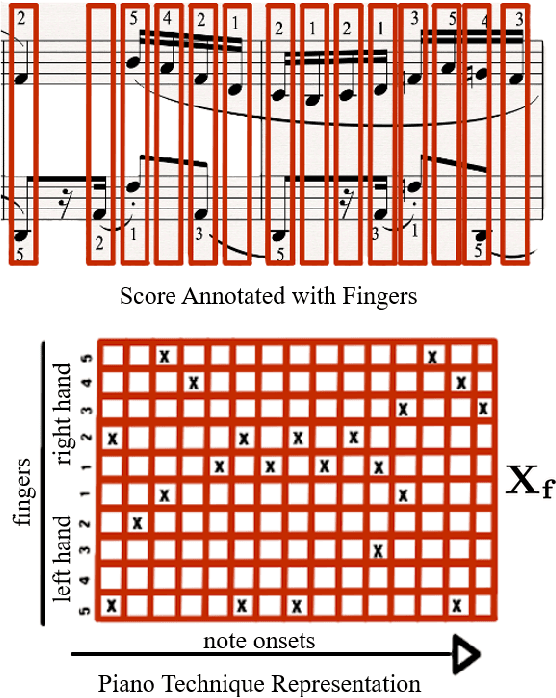

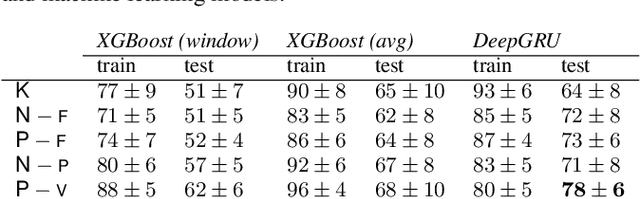
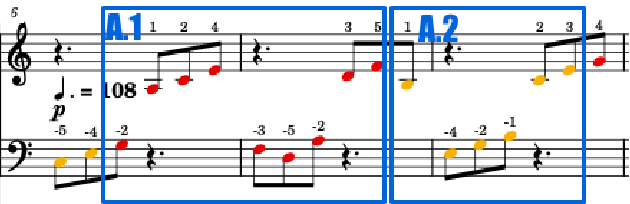
In this paper, we introduce score difficulty classification as a sub-task of music information retrieval (MIR), which may be used in music education technologies, for personalised curriculum generation, and score retrieval. We introduce a novel dataset for our task, Mikrokosmos-difficulty, containing 147 piano pieces in symbolic representation and the corresponding difficulty labels derived by its composer B\'ela Bart\'ok and the publishers. As part of our methodology, we propose piano technique feature representations based on different piano fingering algorithms. We use these features as input for two classifiers: a Gated Recurrent Unit neural network (GRU) with attention mechanism and gradient-boosted trees trained on score segments. We show that for our dataset fingering based features perform better than a simple baseline considering solely the notes in the score. Furthermore, the GRU with attention mechanism classifier surpasses the gradient-boosted trees. Our proposed models are interpretable and are capable of generating difficulty feedback both locally, on short term segments, and globally, for whole pieces. Code, datasets, models, and an online demo are made available for reproducibility
The Online Behaviour of the Algerian Abusers in Social Media Networks
Mar 19, 2022
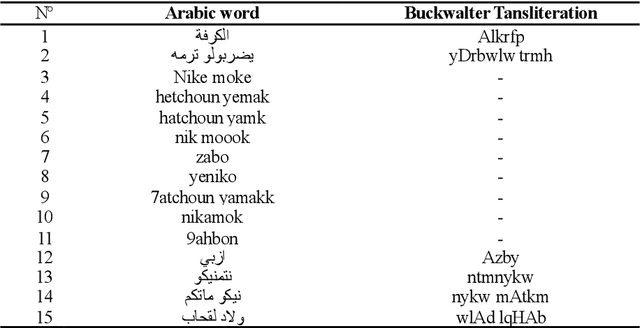
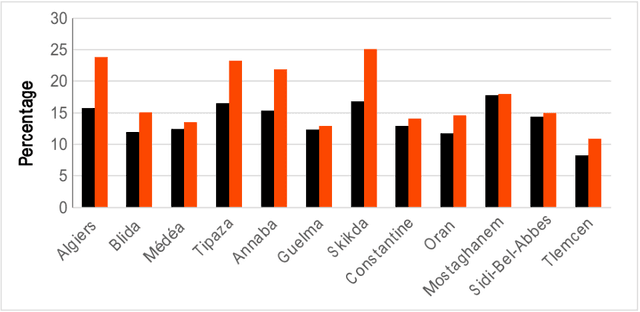
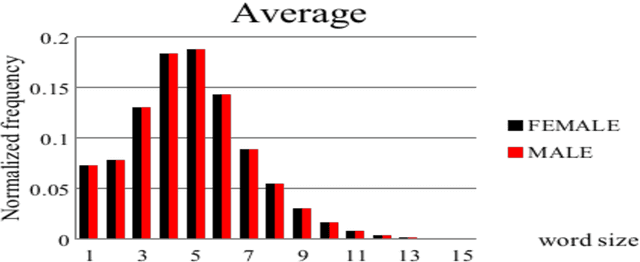
Connecting to social media networks becomes a daily task for the majority of people around the world, and the amount of shared information is growing exponentially. Thus, controlling the way in which people communicate is necessary, in order to protect them from disorientation, conflicts, aggressions, etc. In this paper, we conduct a statistical study on the cyber-bullying and the abusive content in social media (i.e. Facebook), where we try to spot the online behaviour of the abusers in the Algerian community. More specifically, we have involved 200 Facebook users from different regions among 600 to carry out this study. The aim of this investigation is to aid automatic systems of abuse detection to take decision by incorporating the online activity. Abuse detection systems require a large amount of data to perform better on such kind of texts (i.e. unstructured and informal texts), and this is due to the lack of standard orthography, where there are various Algerian dialects and languages spoken.
Off-Policy Evaluation in Embedded Spaces
Mar 05, 2022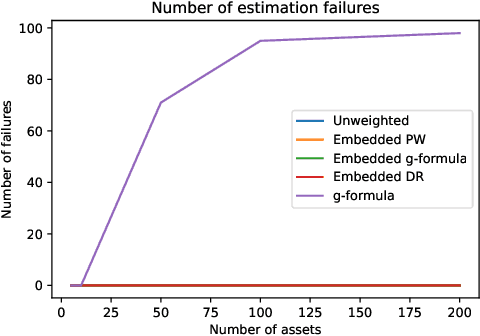
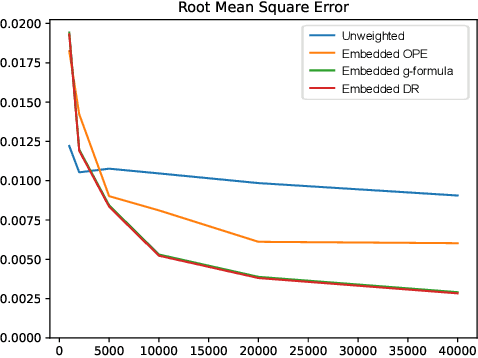
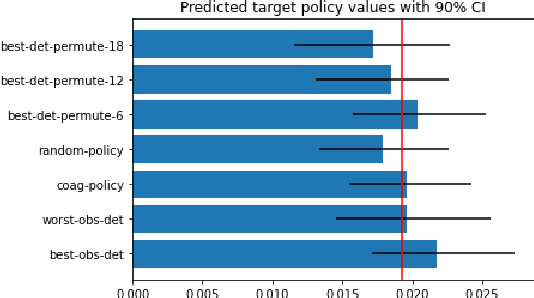
Off-policy evaluation methods are important in recommendation systems and search engines, whereby data collected under an old logging policy is used to predict the performance of a new target policy. However, in practice most systems are not observed to recommend most of the possible actions, which is an issue since existing methods require that the probability of the target policy recommending an item can only be non-zero when the probability of the logging policy is non-zero (known as absolute continuity). To circumvent this issue, we explore the use of action embeddings. By representing contexts and actions in an embedding space, we are able to share information to extrapolate behaviors for actions and contexts previously unseen.
Multilingual Knowledge Graph Completion with Self-Supervised Adaptive Graph Alignment
Mar 28, 2022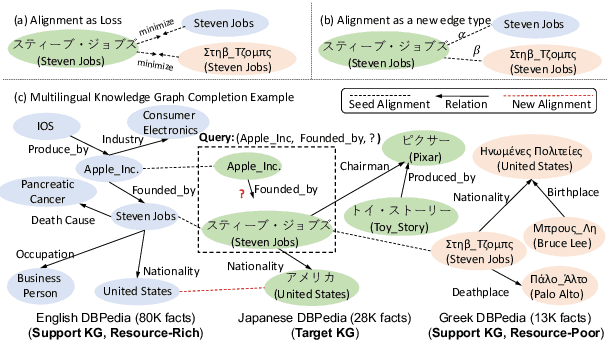
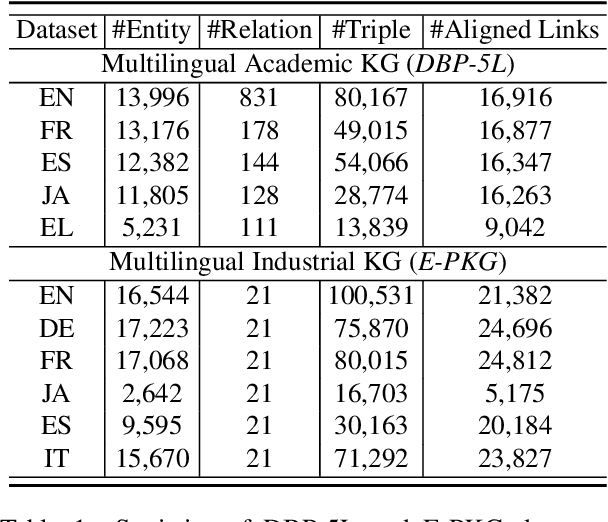
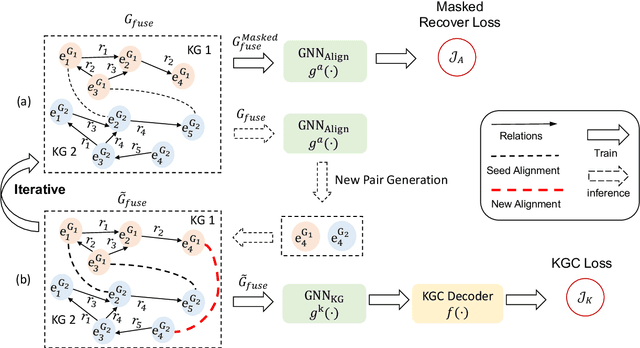
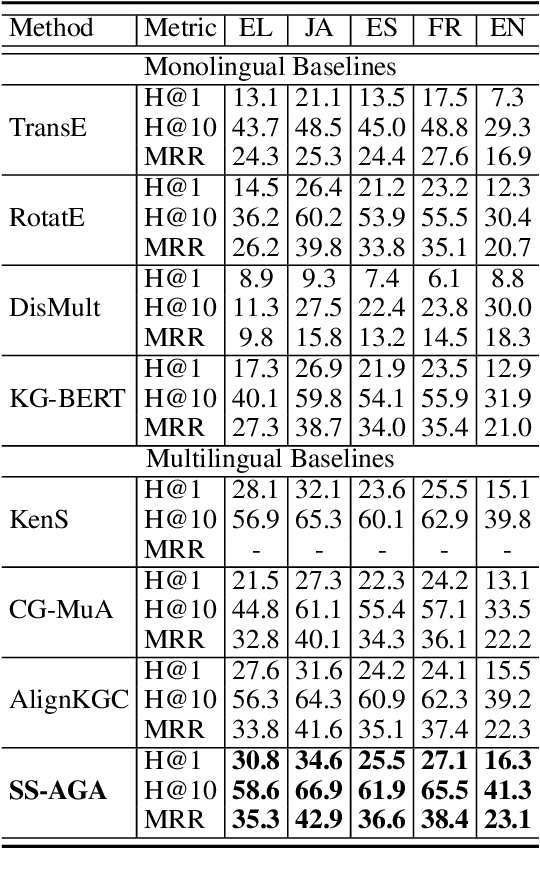
Predicting missing facts in a knowledge graph (KG) is crucial as modern KGs are far from complete. Due to labor-intensive human labeling, this phenomenon deteriorates when handling knowledge represented in various languages. In this paper, we explore multilingual KG completion, which leverages limited seed alignment as a bridge, to embrace the collective knowledge from multiple languages. However, language alignment used in prior works is still not fully exploited: (1) alignment pairs are treated equally to maximally push parallel entities to be close, which ignores KG capacity inconsistency; (2) seed alignment is scarce and new alignment identification is usually in a noisily unsupervised manner. To tackle these issues, we propose a novel self-supervised adaptive graph alignment (SS-AGA) method. Specifically, SS-AGA fuses all KGs as a whole graph by regarding alignment as a new edge type. As such, information propagation and noise influence across KGs can be adaptively controlled via relation-aware attention weights. Meanwhile, SS-AGA features a new pair generator that dynamically captures potential alignment pairs in a self-supervised paradigm. Extensive experiments on both the public multilingual DBPedia KG and newly-created industrial multilingual E-commerce KG empirically demonstrate the effectiveness of SS-AG