 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Online Behaviour of the Algerian Abusers in Social Media Networks
Mar 19, 2022
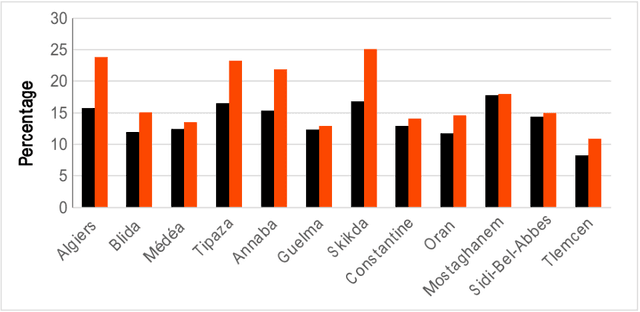
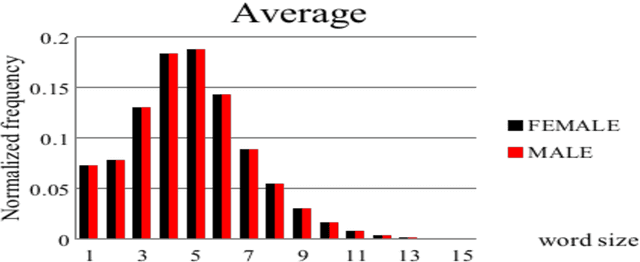
Connecting to social media networks becomes a daily task for the majority of people around the world, and the amount of shared information is growing exponentially. Thus, controlling the way in which people communicate is necessary, in order to protect them from disorientation, conflicts, aggressions, etc. In this paper, we conduct a statistical study on the cyber-bullying and the abusive content in social media (i.e. Facebook), where we try to spot the online behaviour of the abusers in the Algerian community. More specifically, we have involved 200 Facebook users from different regions among 600 to carry out this study. The aim of this investigation is to aid automatic systems of abuse detection to take decision by incorporating the online activity. Abuse detection systems require a large amount of data to perform better on such kind of texts (i.e. unstructured and informal texts), and this is due to the lack of standard orthography, where there are various Algerian dialects and languages spoken.
Offensive Language Detection in Under-resourced Algerian Dialectal Arabic Language
Mar 18, 2022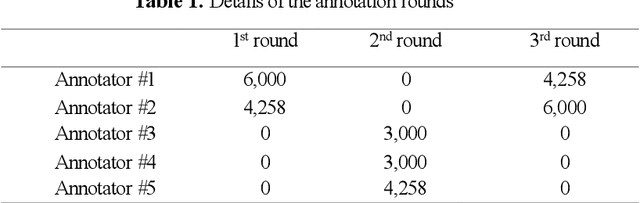

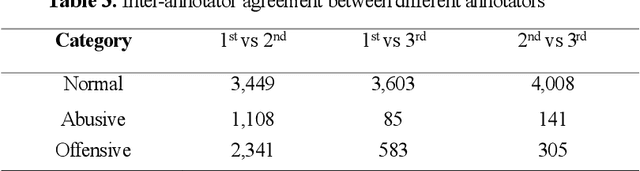

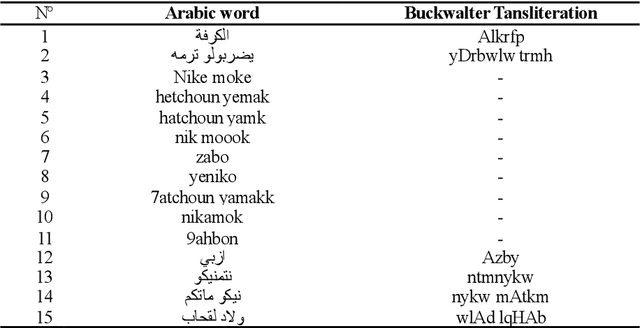
This paper addresses the problem of detecting the offensive and abusive content in Facebook comments, where we focus on the Algerian dialectal Arabic which is one of under-resourced languages. The latter has a variety of dialects mixed with different languages (i.e. Berber, French and English). In addition, we deal with texts written in both Arabic and Roman scripts (i.e. Arabizi). Due to the scarcity of works on the same language, we have built a new corpus regrouping more than 8.7k texts manually annotated as normal, abusive and offensive. We have conducted a series of experiments using the state-of-the-art classifiers of text categorisation, namely: BiLSTM, CNN, FastText, SVM and NB. The results showed acceptable performances, but the problem requires further investigation on linguistic features to increase the identification accuracy.