 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBenchmarking Music Autotagging with MGPHot Expert Annotations vs. Generic Tag Datasets
Sep 08, 2025



Music autotagging aims to automatically assign descriptive tags, such as genre, mood, or instrumentation, to audio recordings. Due to its challenges, diversity of semantic descriptions, and practical value in various applications, it has become a common downstream task for evaluating the performance of general-purpose music representations learned from audio data. We introduce a new benchmarking dataset based on the recently published MGPHot dataset, which includes expert musicological annotations, allowing for additional insights and comparisons with results obtained on common generic tag datasets. While MGPHot annotations have been shown to be useful for computational musicology, the original dataset neither includes audio nor provides evaluation setups for its use as a standardized autotagging benchmark. To address this, we provide a curated set of YouTube URLs with retrievable audio, and propose a train/val/test split for standardized evaluation, and precomputed representations for seven state-of-the-art models. Using these resources, we evaluated these models in MGPHot and standard reference tag datasets, highlighting key differences between expert and generic tag annotations. Altogether, our contributions provide a more advanced benchmarking framework for future research in music understanding.
The Role of Large Language Models in Musicology: Are We Ready to Trust the Machines?
Sep 03, 2024



In this work, we explore the use and reliability of Large Language Models (LLMs) in musicology. From a discussion with experts and students, we assess the current acceptance and concerns regarding this, nowadays ubiquitous, technology. We aim to go one step further, proposing a semi-automatic method to create an initial benchmark using retrieval-augmented generation models and multiple-choice question generation, validated by human experts. Our evaluation on 400 human-validated questions shows that current vanilla LLMs are less reliable than retrieval augmented generation from music dictionaries. This paper suggests that the potential of LLMs in musicology requires musicology driven research that can specialized LLMs by including accurate and reliable domain knowledge.
Towards Explainable and Interpretable Musical Difficulty Estimation: A Parameter-efficient Approach
Aug 01, 2024



Estimating music piece difficulty is important for organizing educational music collections. This process could be partially automatized to facilitate the educator's role. Nevertheless, the decisions performed by prevalent deep-learning models are hardly understandable, which may impair the acceptance of such a technology in music education curricula. Our work employs explainable descriptors for difficulty estimation in symbolic music representations. Furthermore, through a novel parameter-efficient white-box model, we outperform previous efforts while delivering interpretable results. These comprehensible outcomes emulate the functionality of a rubric, a tool widely used in music education. Our approach, evaluated in piano repertoire categorized in 9 classes, achieved 41.4% accuracy independently, with a mean squared error (MSE) of 1.7, showing precise difficulty estimation. Through our baseline, we illustrate how building on top of past research can offer alternatives for music difficulty assessment which are explainable and interpretable. With this, we aim to promote a more effective communication between the Music Information Retrieval (MIR) community and the music education one.
Music Proofreading with RefinPaint: Where and How to Modify Compositions given Context
Jul 12, 2024



Autoregressive generative transformers are key in music generation, producing coherent compositions but facing challenges in human-machine collaboration. We propose RefinPaint, an iterative technique that improves the sampling process. It does this by identifying the weaker music elements using a feedback model, which then informs the choices for resampling by an inpainting model. This dual-focus methodology not only facilitates the machine's ability to improve its automatic inpainting generation through repeated cycles but also offers a valuable tool for humans seeking to refine their compositions with automatic proofreading. Experimental results suggest RefinPaint's effectiveness in inpainting and proofreading tasks, demonstrating its value for refining music created by both machines and humans. This approach not only facilitates creativity but also aids amateur composers in improving their work.
Can Audio Reveal Music Performance Difficulty? Insights from the Piano Syllabus Dataset
Mar 06, 2024



Automatically estimating the performance difficulty of a music piece represents a key process in music education to create tailored curricula according to the individual needs of the students. Given its relevance, the Music Information Retrieval (MIR) field depicts some proof-of-concept works addressing this task that mainly focuses on high-level music abstractions such as machine-readable scores or music sheet images. In this regard, the potential of directly analyzing audio recordings has been generally neglected, which prevents students from exploring diverse music pieces that may not have a formal symbolic-level transcription. This work pioneers in the automatic estimation of performance difficulty of music pieces on audio recordings with two precise contributions: (i) the first audio-based difficulty estimation dataset -- namely, Piano Syllabus (PSyllabus) dataset -- featuring 7,901 piano pieces across 11 difficulty levels from 1,233 composers; and (ii) a recognition framework capable of managing different input representations -- both unimodal and multimodal manners -- directly derived from audio to perform the difficulty estimation task. The comprehensive experimentation comprising different pre-training schemes, input modalities, and multi-task scenarios prove the validity of the proposal and establishes PSyllabus as a reference dataset for audio-based difficulty estimation in the MIR field. The dataset as well as the developed code and trained models are publicly shared to promote further research in the field.
Predicting performance difficulty from piano sheet music images
Sep 28, 2023



Estimating the performance difficulty of a musical score is crucial in music education for adequately designing the learning curriculum of the students. Although the Music Information Retrieval community has recently shown interest in this task, existing approaches mainly use machine-readable scores, leaving the broader case of sheet music images unaddressed. Based on previous works involving sheet music images, we use a mid-level representation, bootleg score, describing notehead positions relative to staff lines coupled with a transformer model. This architecture is adapted to our task by introducing an encoding scheme that reduces the encoded sequence length to one-eighth of the original size. In terms of evaluation, we consider five datasets -- more than 7500 scores with up to 9 difficulty levels -- , two of them particularly compiled for this work. The results obtained when pretraining the scheme on the IMSLP corpus and fine-tuning it on the considered datasets prove the proposal's validity, achieving the best-performing model with a balanced accuracy of 40.34\% and a mean square error of 1.33. Finally, we provide access to our code, data, and models for transparency and reproducibility.
Combining piano performance dimensions for score difficulty classification
Jun 14, 2023



Predicting the difficulty of playing a musical score is essential for structuring and exploring score collections. Despite its importance for music education, the automatic difficulty classification of piano scores is not yet solved, mainly due to the lack of annotated data and the subjectiveness of the annotations. This paper aims to advance the state-of-the-art in score difficulty classification with two major contributions. To address the lack of data, we present Can I Play It? (CIPI) dataset, a machine-readable piano score dataset with difficulty annotations obtained from the renowned classical music publisher Henle Verlag. The dataset is created by matching public domain scores with difficulty labels from Henle Verlag, then reviewed and corrected by an expert pianist. As a second contribution, we explore various input representations from score information to pre-trained ML models for piano fingering and expressiveness inspired by the musicology definition of performance. We show that combining the outputs of multiple classifiers performs better than the classifiers on their own, pointing to the fact that the representations capture different aspects of difficulty. In addition, we conduct numerous experiments that lay a foundation for score difficulty classification and create a basis for future research. Our best-performing model reports a 39.47% balanced accuracy and 1.13 median square error across the nine difficulty levels proposed in this study. Code, dataset, and models are made available for reproducibility.
Score difficulty analysis for piano performance education based on fingering
Mar 24, 2022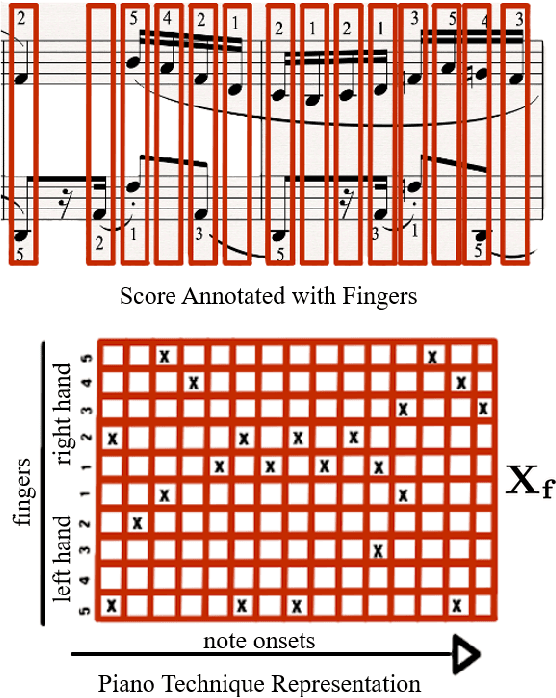

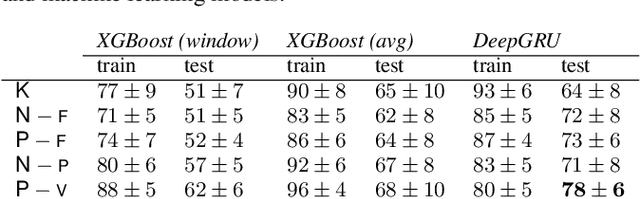
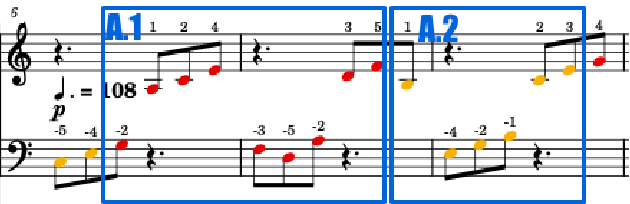
In this paper, we introduce score difficulty classification as a sub-task of music information retrieval (MIR), which may be used in music education technologies, for personalised curriculum generation, and score retrieval. We introduce a novel dataset for our task, Mikrokosmos-difficulty, containing 147 piano pieces in symbolic representation and the corresponding difficulty labels derived by its composer B\'ela Bart\'ok and the publishers. As part of our methodology, we propose piano technique feature representations based on different piano fingering algorithms. We use these features as input for two classifiers: a Gated Recurrent Unit neural network (GRU) with attention mechanism and gradient-boosted trees trained on score segments. We show that for our dataset fingering based features perform better than a simple baseline considering solely the notes in the score. Furthermore, the GRU with attention mechanism classifier surpasses the gradient-boosted trees. Our proposed models are interpretable and are capable of generating difficulty feedback both locally, on short term segments, and globally, for whole pieces. Code, datasets, models, and an online demo are made available for reproducibility