 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
MemoryPrompt: A Light Wrapper to Improve Context Tracking in Pre-trained Language Models
Feb 23, 2024
Transformer-based language models (LMs) track contextual information through large, hard-coded input windows. We introduce MemoryPrompt, a leaner approach in which the LM is complemented by a small auxiliary recurrent network that passes information to the LM by prefixing its regular input with a sequence of vectors, akin to soft prompts, without requiring LM finetuning. Tested on a task designed to probe a LM's ability to keep track of multiple fact updates, a MemoryPrompt-augmented LM outperforms much larger LMs that have access to the full input history. We also test MemoryPrompt on a long-distance dialogue dataset, where its performance is comparable to that of a model conditioned on the entire conversation history. In both experiments we also observe that, unlike full-finetuning approaches, MemoryPrompt does not suffer from catastrophic forgetting when adapted to new tasks, thus not disrupting the generalist capabilities of the underlying LM.
RoboEXP: Action-Conditioned Scene Graph via Interactive Exploration for Robotic Manipulation
Feb 23, 2024Robots need to explore their surroundings to adapt to and tackle tasks in unknown environments. Prior work has proposed building scene graphs of the environment but typically assumes that the environment is static, omitting regions that require active interactions. This severely limits their ability to handle more complex tasks in household and office environments: before setting up a table, robots must explore drawers and cabinets to locate all utensils and condiments. In this work, we introduce the novel task of interactive scene exploration, wherein robots autonomously explore environments and produce an action-conditioned scene graph (ACSG) that captures the structure of the underlying environment. The ACSG accounts for both low-level information, such as geometry and semantics, and high-level information, such as the action-conditioned relationships between different entities in the scene. To this end, we present the Robotic Exploration (RoboEXP) system, which incorporates the Large Multimodal Model (LMM) and an explicit memory design to enhance our system's capabilities. The robot reasons about what and how to explore an object, accumulating new information through the interaction process and incrementally constructing the ACSG. We apply our system across various real-world settings in a zero-shot manner, demonstrating its effectiveness in exploring and modeling environments it has never seen before. Leveraging the constructed ACSG, we illustrate the effectiveness and efficiency of our RoboEXP system in facilitating a wide range of real-world manipulation tasks involving rigid, articulated objects, nested objects like Matryoshka dolls, and deformable objects like cloth.
Towards Faithful and Robust LLM Specialists for Evidence-Based Question-Answering
Feb 26, 2024Advances towards more faithful and traceable answers of Large Language Models (LLMs) are crucial for various research and practical endeavors. One avenue in reaching this goal is basing the answers on reliable sources. However, this Evidence-Based QA has proven to work insufficiently with LLMs in terms of citing the correct sources (source quality) and truthfully representing the information within sources (answer attributability). In this work, we systematically investigate how to robustly fine-tune LLMs for better source quality and answer attributability. Specifically, we introduce a data generation pipeline with automated data quality filters, which can synthesize diversified high-quality training and testing data at scale. We further introduce four test sets to benchmark the robustness of fine-tuned specialist models. Extensive evaluation shows that fine-tuning on synthetic data improves performance on both in- and out-of-distribution. Furthermore, we show that data quality, which can be drastically improved by proposed quality filters, matters more than quantity in improving Evidence-Based QA.
Automated Floodwater Depth Estimation Using Large Multimodal Model for Rapid Flood Mapping
Feb 26, 2024Information on the depth of floodwater is crucial for rapid mapping of areas affected by floods. However, previous approaches for estimating floodwater depth, including field surveys, remote sensing, and machine learning techniques, can be time-consuming and resource-intensive. This paper presents an automated and fast approach for estimating floodwater depth from on-site flood photos. A pre-trained large multimodal model, GPT-4 Vision, was used specifically for estimating floodwater. The input data were flooding photos that contained referenced objects, such as street signs, cars, people, and buildings. Using the heights of the common objects as references, the model returned the floodwater depth as the output. Results show that the proposed approach can rapidly provide a consistent and reliable estimation of floodwater depth from flood photos. Such rapid estimation is transformative in flood inundation mapping and assessing the severity of the flood in near-real time, which is essential for effective flood response strategies.
CFRet-DVQA: Coarse-to-Fine Retrieval and Efficient Tuning for Document Visual Question Answering
Feb 26, 2024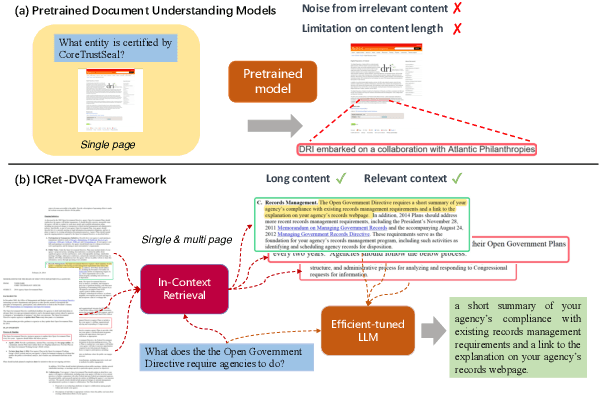
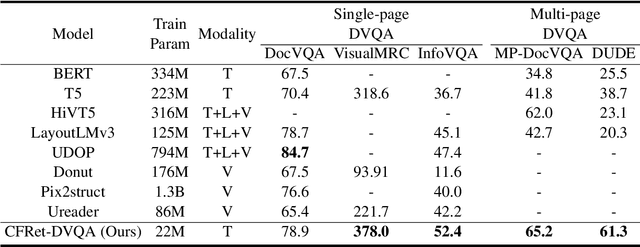
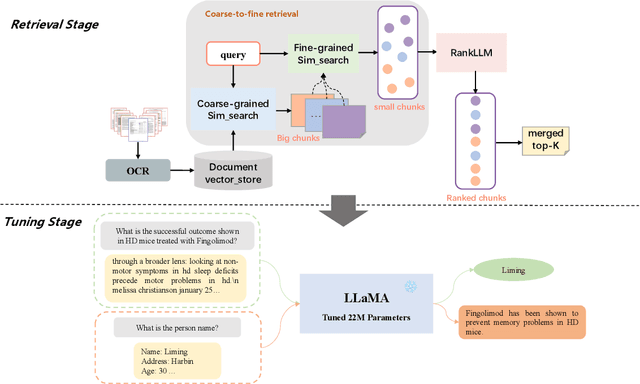
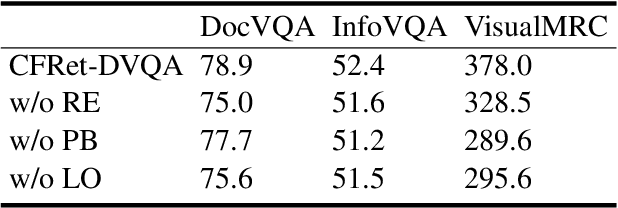
Document Visual Question Answering (DVQA) is a task that involves responding to queries based on the content of images. Existing work is limited to locating information within a single page and does not facilitate cross-page question-and-answer interaction. Furthermore, the token length limitation imposed on inputs to the model may lead to truncation of segments pertinent to the answer. In this study, we introduce a simple but effective methodology called CFRet-DVQA, which focuses on retrieval and efficient tuning to address this critical issue effectively. For that, we initially retrieve multiple segments from the document that correlate with the question at hand. Subsequently, we leverage the advanced reasoning abilities of the large language model (LLM), further augmenting its performance through instruction tuning. This approach enables the generation of answers that align with the style of the document labels. The experiments demonstrate that our methodology achieved state-of-the-art or competitive results with both single-page and multi-page documents in various fields.
Information Leakage Detection through Approximate Bayes-optimal Prediction
Jan 25, 2024In today's data-driven world, the proliferation of publicly available information intensifies the challenge of information leakage (IL), raising security concerns. IL involves unintentionally exposing secret (sensitive) information to unauthorized parties via systems' observable information. Conventional statistical approaches, which estimate mutual information (MI) between observable and secret information for detecting IL, face challenges such as the curse of dimensionality, convergence, computational complexity, and MI misestimation. Furthermore, emerging supervised machine learning (ML) methods, though effective, are limited to binary system-sensitive information and lack a comprehensive theoretical framework. To address these limitations, we establish a theoretical framework using statistical learning theory and information theory to accurately quantify and detect IL. We demonstrate that MI can be accurately estimated by approximating the log-loss and accuracy of the Bayes predictor. As the Bayes predictor is typically unknown in practice, we propose to approximate it with the help of automated machine learning (AutoML). First, we compare our MI estimation approaches against current baselines, using synthetic data sets generated using the multivariate normal (MVN) distribution with known MI. Second, we introduce a cut-off technique using one-sided statistical tests to detect IL, employing the Holm-Bonferroni correction to increase confidence in detection decisions. Our study evaluates IL detection performance on real-world data sets, highlighting the effectiveness of the Bayes predictor's log-loss estimation, and finds our proposed method to effectively estimate MI on synthetic data sets and thus detect ILs accurately.
Repetition Improves Language Model Embeddings
Feb 23, 2024Recent approaches to improving the extraction of text embeddings from autoregressive large language models (LLMs) have largely focused on improvements to data, backbone pretrained language models, or improving task-differentiation via instructions. In this work, we address an architectural limitation of autoregressive models: token embeddings cannot contain information from tokens that appear later in the input. To address this limitation, we propose a simple approach, "echo embeddings," in which we repeat the input twice in context and extract embeddings from the second occurrence. We show that echo embeddings of early tokens can encode information about later tokens, allowing us to maximally leverage high-quality LLMs for embeddings. On the MTEB leaderboard, echo embeddings improve over classical embeddings by over 9% zero-shot and by around 0.7% when fine-tuned. Echo embeddings with a Mistral-7B model achieve state-of-the-art compared to prior open source models that do not leverage synthetic fine-tuning data.
AttributionBench: How Hard is Automatic Attribution Evaluation?
Feb 23, 2024Modern generative search engines enhance the reliability of large language model (LLM) responses by providing cited evidence. However, evaluating the answer's attribution, i.e., whether every claim within the generated responses is fully supported by its cited evidence, remains an open problem. This verification, traditionally dependent on costly human evaluation, underscores the urgent need for automatic attribution evaluation methods. To bridge the gap in the absence of standardized benchmarks for these methods, we present AttributionBench, a comprehensive benchmark compiled from various existing attribution datasets. Our extensive experiments on AttributionBench reveal the challenges of automatic attribution evaluation, even for state-of-the-art LLMs. Specifically, our findings show that even a fine-tuned GPT-3.5 only achieves around 80% macro-F1 under a binary classification formulation. A detailed analysis of more than 300 error cases indicates that a majority of failures stem from the model's inability to process nuanced information, and the discrepancy between the information the model has access to and that human annotators do.
FViT: A Focal Vision Transformer with Gabor Filter
Feb 27, 2024Vision transformers have achieved encouraging progress in various computer vision tasks. A common belief is that this is attributed to the competence of self-attention in modeling the global dependencies among feature tokens. Unfortunately, self-attention still faces some challenges in dense prediction tasks, such as the high computational complexity and absence of desirable inductive bias. To address these issues, we revisit the potential benefits of integrating vision transformer with Gabor filter, and propose a Learnable Gabor Filter (LGF) by using convolution. As an alternative to self-attention, we employ LGF to simulate the response of simple cells in the biological visual system to input images, prompting models to focus on discriminative feature representations of targets from various scales and orientations. Additionally, we design a Bionic Focal Vision (BFV) block based on the LGF. This block draws inspiration from neuroscience and introduces a Multi-Path Feed Forward Network (MPFFN) to emulate the working way of biological visual cortex processing information in parallel. Furthermore, we develop a unified and efficient pyramid backbone network family called Focal Vision Transformers (FViTs) by stacking BFV blocks. Experimental results show that FViTs exhibit highly competitive performance in various vision tasks. Especially in terms of computational efficiency and scalability, FViTs show significant advantages compared with other counterparts. Code is available at https://github.com/nkusyl/FViT
PromptMM: Multi-Modal Knowledge Distillation for Recommendation with Prompt-Tuning
Feb 27, 2024Multimedia online platforms (e.g., Amazon, TikTok) have greatly benefited from the incorporation of multimedia (e.g., visual, textual, and acoustic) content into their personal recommender systems. These modalities provide intuitive semantics that facilitate modality-aware user preference modeling. However, two key challenges in multi-modal recommenders remain unresolved: i) The introduction of multi-modal encoders with a large number of additional parameters causes overfitting, given high-dimensional multi-modal features provided by extractors (e.g., ViT, BERT). ii) Side information inevitably introduces inaccuracies and redundancies, which skew the modality-interaction dependency from reflecting true user preference. To tackle these problems, we propose to simplify and empower recommenders through Multi-modal Knowledge Distillation (PromptMM) with the prompt-tuning that enables adaptive quality distillation. Specifically, PromptMM conducts model compression through distilling u-i edge relationship and multi-modal node content from cumbersome teachers to relieve students from the additional feature reduction parameters. To bridge the semantic gap between multi-modal context and collaborative signals for empowering the overfitting teacher, soft prompt-tuning is introduced to perform student task-adaptive. Additionally, to adjust the impact of inaccuracies in multimedia data, a disentangled multi-modal list-wise distillation is developed with modality-aware re-weighting mechanism. Experiments on real-world data demonstrate PromptMM's superiority over existing techniques. Ablation tests confirm the effectiveness of key components. Additional tests show the efficiency and effectiveness.