 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Multi-modal Emotion Estimation for in-the-wild Videos
Mar 31, 2022




In this paper, we briefly introduce our submission to the Valence-Arousal Estimation Challenge of the 3rd Affective Behavior Analysis in-the-wild (ABAW) competition. Our method utilizes the multi-modal information, i.e., the visual and audio information, and employs a temporal encoder to model the temporal context in the videos. Besides, a smooth processor is applied to get more reasonable predictions, and a model ensemble strategy is used to improve the performance of our proposed method. The experiment results show that our method achieves 65.55% ccc for valence and 70.88% ccc for arousal on the validation set of the Aff-Wild2 dataset, which prove the effectiveness of our proposed method.
HCFRec: Hash Collaborative Filtering via Normalized Flow with Structural Consensus for Efficient Recommendation
May 24, 2022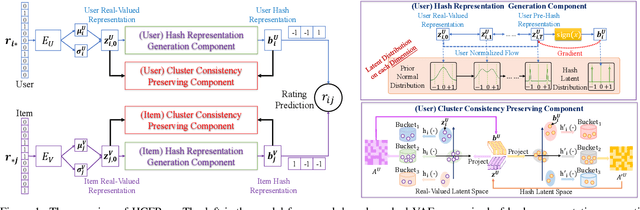
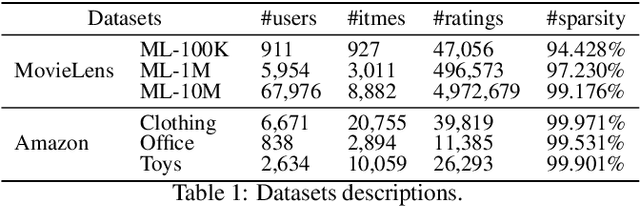
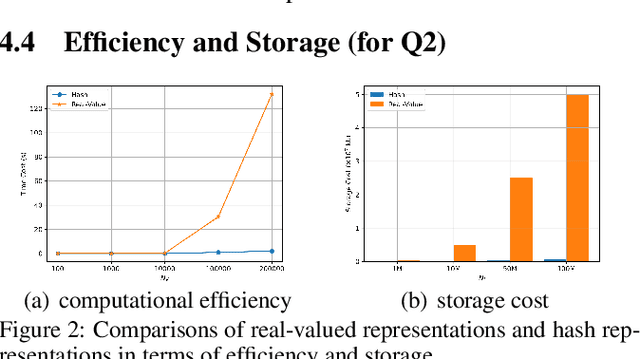
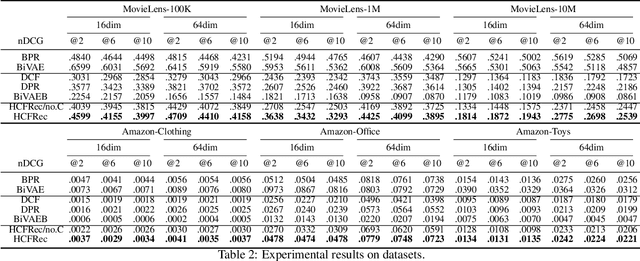
The ever-increasing data scale of user-item interactions makes it challenging for an effective and efficient recommender system. Recently, hash-based collaborative filtering (Hash-CF) approaches employ efficient Hamming distance of learned binary representations of users and items to accelerate recommendations. However, Hash-CF often faces two challenging problems, i.e., optimization on discrete representations and preserving semantic information in learned representations. To address the above two challenges, we propose HCFRec, a novel Hash-CF approach for effective and efficient recommendations. Specifically, HCFRec not only innovatively introduces normalized flow to learn the optimal hash code by efficiently fit a proposed approximate mixture multivariate normal distribution, a continuous but approximately discrete distribution, but also deploys a cluster consistency preserving mechanism to preserve the semantic structure in representations for more accurate recommendations. Extensive experiments conducted on six real-world datasets demonstrate the superiority of our HCFRec compared to the state-of-art methods in terms of effectiveness and efficiency.
DeepFormableTag: End-to-end Generation and Recognition of Deformable Fiducial Markers
Jun 16, 2022
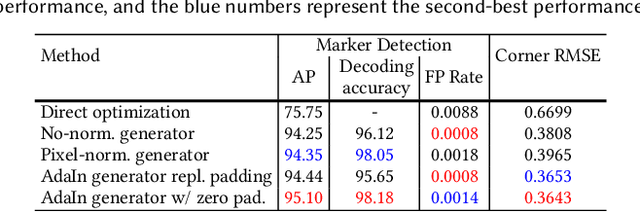
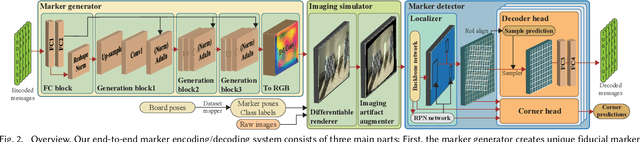

Fiducial markers have been broadly used to identify objects or embed messages that can be detected by a camera. Primarily, existing detection methods assume that markers are printed on ideally planar surfaces. Markers often fail to be recognized due to various imaging artifacts of optical/perspective distortion and motion blur. To overcome these limitations, we propose a novel deformable fiducial marker system that consists of three main parts: First, a fiducial marker generator creates a set of free-form color patterns to encode significantly large-scale information in unique visual codes. Second, a differentiable image simulator creates a training dataset of photorealistic scene images with the deformed markers, being rendered during optimization in a differentiable manner. The rendered images include realistic shading with specular reflection, optical distortion, defocus and motion blur, color alteration, imaging noise, and shape deformation of markers. Lastly, a trained marker detector seeks the regions of interest and recognizes multiple marker patterns simultaneously via inverse deformation transformation. The deformable marker creator and detector networks are jointly optimized via the differentiable photorealistic renderer in an end-to-end manner, allowing us to robustly recognize a wide range of deformable markers with high accuracy. Our deformable marker system is capable of decoding 36-bit messages successfully at ~29 fps with severe shape deformation. Results validate that our system significantly outperforms the traditional and data-driven marker methods. Our learning-based marker system opens up new interesting applications of fiducial markers, including cost-effective motion capture of the human body, active 3D scanning using our fiducial markers' array as structured light patterns, and robust augmented reality rendering of virtual objects on dynamic surfaces.
Learning to Reach, Swim, Walk and Fly in One Trial: Data-Driven Control with Scarce Data and Side Information
Jun 19, 2021
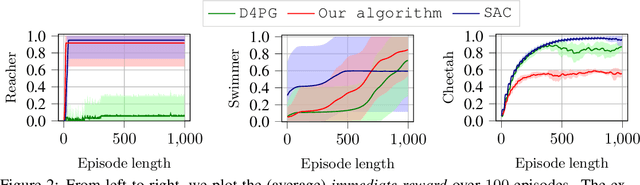
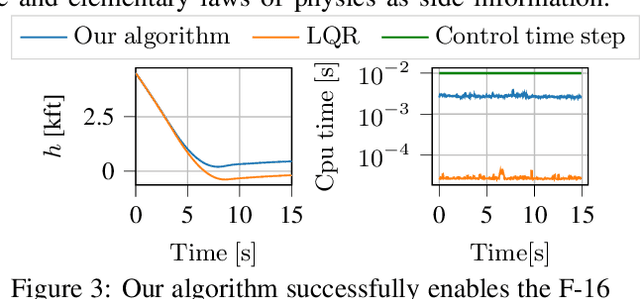
We develop a learning-based control algorithm for unknown dynamical systems under very severe data limitations. Specifically, the algorithm has access to streaming data only from a single and ongoing trial. Despite the scarcity of data, we show -- through a series of examples -- that the algorithm can provide performance comparable to reinforcement learning algorithms trained over millions of environment interactions. It accomplishes such performance by effectively leveraging various forms of side information on the dynamics to reduce the sample complexity. Such side information typically comes from elementary laws of physics and qualitative properties of the system. More precisely, the algorithm approximately solves an optimal control problem encoding the system's desired behavior. To this end, it constructs and refines a differential inclusion that contains the unknown vector field of the dynamics. The differential inclusion, used in an interval Taylor-based method, enables to over-approximate the set of states the system may reach. Theoretically, we establish a bound on the suboptimality of the approximate solution with respect to the case of known dynamics. We show that the longer the trial or the more side information is available, the tighter the bound. Empirically, experiments in a high-fidelity F-16 aircraft simulator and MuJoCo's environments such as the Reacher, Swimmer, and Cheetah illustrate the algorithm's effectiveness.
Label Semantic Aware Pre-training for Few-shot Text Classification
Apr 14, 2022
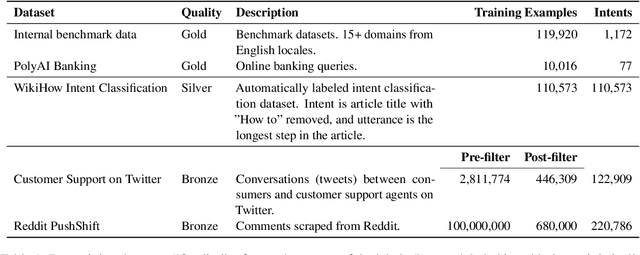
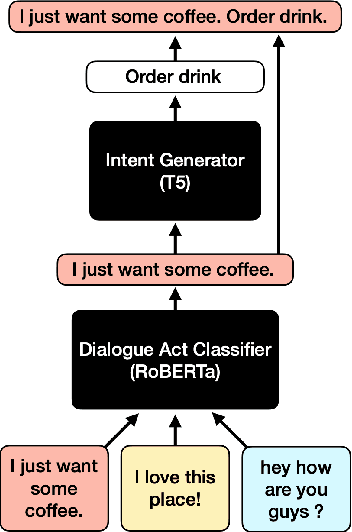
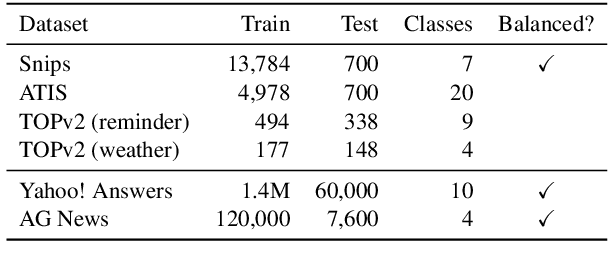
In text classification tasks, useful information is encoded in the label names. Label semantic aware systems have leveraged this information for improved text classification performance during fine-tuning and prediction. However, use of label-semantics during pre-training has not been extensively explored. We therefore propose Label Semantic Aware Pre-training (LSAP) to improve the generalization and data efficiency of text classification systems. LSAP incorporates label semantics into pre-trained generative models (T5 in our case) by performing secondary pre-training on labeled sentences from a variety of domains. As domain-general pre-training requires large amounts of data, we develop a filtering and labeling pipeline to automatically create sentence-label pairs from unlabeled text. We perform experiments on intent (ATIS, Snips, TOPv2) and topic classification (AG News, Yahoo! Answers). LSAP obtains significant accuracy improvements over state-of-the-art models for few-shot text classification while maintaining performance comparable to state of the art in high-resource settings.
Evaluating the Fairness Impact of Differentially Private Synthetic Data
May 09, 2022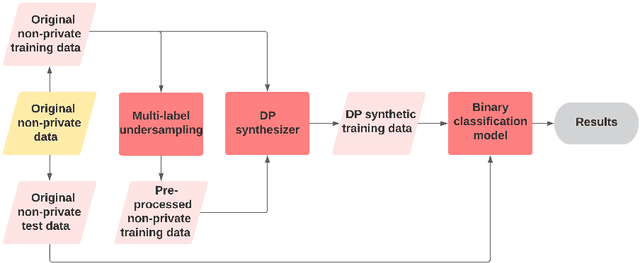
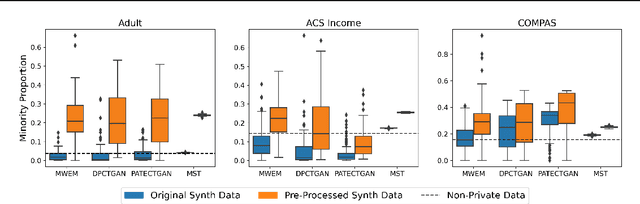
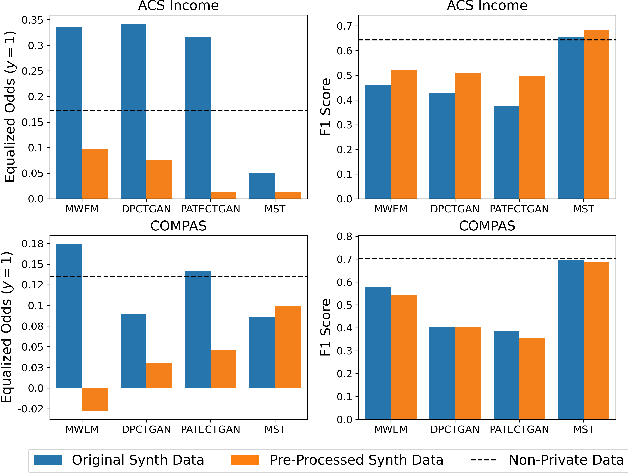
Differentially private (DP) synthetic data is a promising approach to maximizing the utility of data containing sensitive information. Due to the suppression of underrepresented classes that is often required to achieve privacy, however, it may be in conflict with fairness. We evaluate four DP synthesizers and present empirical results indicating that three of these models frequently degrade fairness outcomes on downstream binary classification tasks. We draw a connection between fairness and the proportion of minority groups present in the generated synthetic data, and find that training synthesizers on data that are pre-processed via a multi-label undersampling method can promote more fair outcomes without degrading accuracy.
Time-aware Graph Neural Networks for Entity Alignment between Temporal Knowledge Graphs
Mar 13, 2022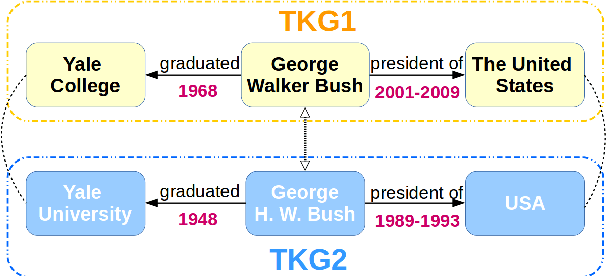

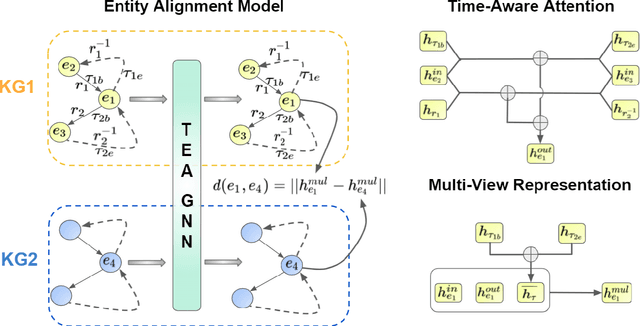
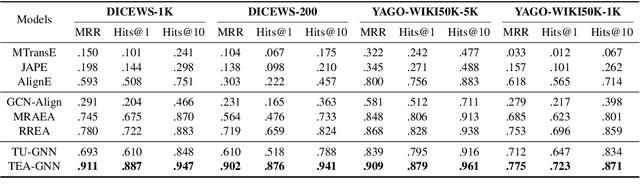
Entity alignment aims to identify equivalent entity pairs between different knowledge graphs (KGs). Recently, the availability of temporal KGs (TKGs) that contain time information created the need for reasoning over time in such TKGs. Existing embedding-based entity alignment approaches disregard time information that commonly exists in many large-scale KGs, leaving much room for improvement. In this paper, we focus on the task of aligning entity pairs between TKGs and propose a novel Time-aware Entity Alignment approach based on Graph Neural Networks (TEA-GNN). We embed entities, relations and timestamps of different KGs into a vector space and use GNNs to learn entity representations. To incorporate both relation and time information into the GNN structure of our model, we use a time-aware attention mechanism which assigns different weights to different nodes with orthogonal transformation matrices computed from embeddings of the relevant relations and timestamps in a neighborhood. Experimental results on multiple real-world TKG datasets show that our method significantly outperforms the state-of-the-art methods due to the inclusion of time information.
A Trillion Genetic Programming Instructions per Second
May 06, 2022
We summarise how a 3.0 GHz 16 core AVX512 computer can interpret the equivalent of up to on average 1103370000000 GPop/s. Citations to existing publications are given. Implementation stress is placed on both parallel computing, bandwidth limits and avoiding repeated calculation. Information theory suggests in digital computing, failed disruption propagation gives huge speed ups as FDP and incremental evaluation can be used to reduce fitness evaluation time in phenotypically converged populations. Conversely FDP may be responsible for evolution stagnation. So the wider Evolutionary Computing, Artificial Life, Unconventional Computing and Software Engineering community may need to avoid deep nesting.
S$^2$-FPN: Scale-ware Strip Attention Guided Feature Pyramid Network for Real-time Semantic Segmentation
Jun 16, 2022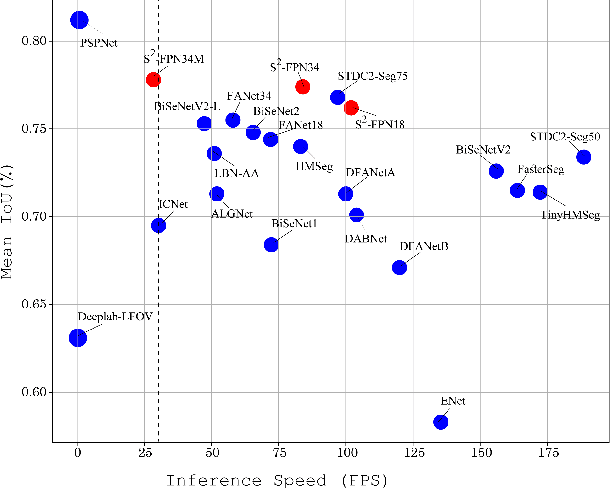
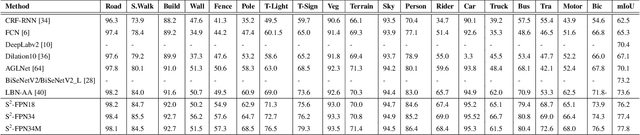
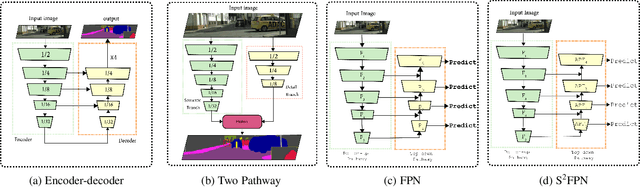
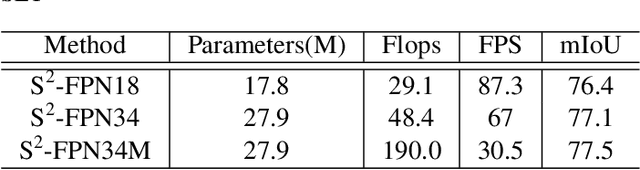
Modern high-performance semantic segmentation methods employ a heavy backbone and dilated convolution to extract the relevant feature. Although extracting features with both contextual and semantic information is critical for the segmentation tasks, it brings a memory footprint and high computation cost for real-time applications. This paper presents a new model to achieve a trade-off between accuracy/speed for real-time road scene semantic segmentation. Specifically, we proposed a lightweight model named Scale-aware Strip Attention Guided Feature Pyramid Network (S$^2$-FPN). Our network consists of three main modules: Attention Pyramid Fusion (APF) module, Scale-aware Strip Attention Module (SSAM), and Global Feature Upsample (GFU) module. APF adopts an attention mechanisms to learn discriminative multi-scale features and help close the semantic gap between different levels. APF uses the scale-aware attention to encode global context with vertical stripping operation and models the long-range dependencies, which helps relate pixels with similar semantic label. In addition, APF employs channel-wise reweighting block (CRB) to emphasize the channel features. Finally, the decoder of S$^2$-FPN then adopts GFU, which is used to fuse features from APF and the encoder. Extensive experiments have been conducted on two challenging semantic segmentation benchmarks, which demonstrate that our approach achieves better accuracy/speed trade-off with different model settings. The proposed models have achieved a results of 76.2\%mIoU/87.3FPS, 77.4\%mIoU/67FPS, and 77.8\%mIoU/30.5FPS on Cityscapes dataset, and 69.6\%mIoU,71.0\% mIoU, and 74.2\% mIoU on Camvid dataset. The code for this work will be made available at \url{https://github.com/mohamedac29/S2-FPN
Transferable Reward Learning by Dynamics-Agnostic Discriminator Ensemble
Jun 01, 2022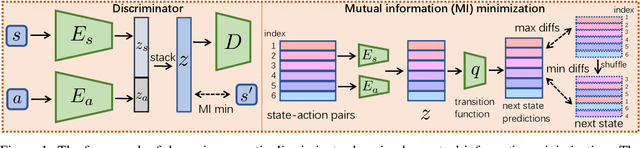

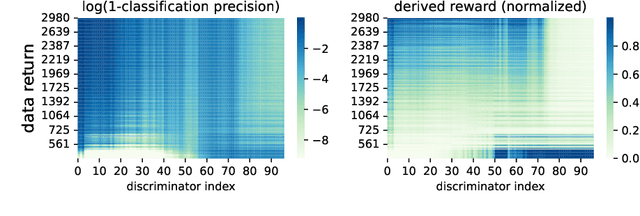

Inverse reinforcement learning (IRL) recovers the underlying reward function from expert demonstrations. A generalizable reward function is even desired as it captures the fundamental motivation of the expert. However, classical IRL methods can only recover reward functions coupled with the training dynamics, thus are hard to generalize to a changed environment. Previous dynamics-agnostic reward learning methods have strict assumptions, such as that the reward function has to be state-only. This work proposes a general approach to learn transferable reward functions, Dynamics-Agnostic Discriminator-Ensemble Reward Learning (DARL). Following the adversarial imitation learning (AIL) framework, DARL learns a dynamics-agnostic discriminator on a latent space mapped from the original state-action space. The latent space is learned to contain the least information of the dynamics. Moreover, to reduce the reliance of the discriminator on policies, the reward function is represented as an ensemble of the discriminators during training. We assess DARL in four MuJoCo tasks with dynamics transfer. Empirical results compared with the state-of-the-art AIL methods show that DARL can learn a reward that is more consistent with the true reward, thus obtaining higher environment returns.