 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobustification of Multilingual Language Models to Real-world Noise with Robust Contrastive Pretraining
Oct 10, 2022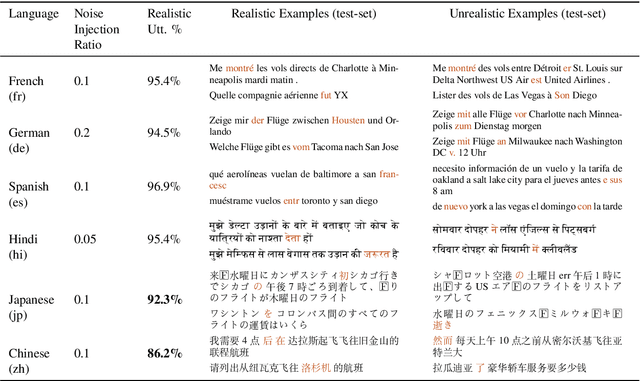
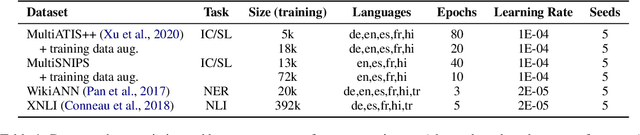
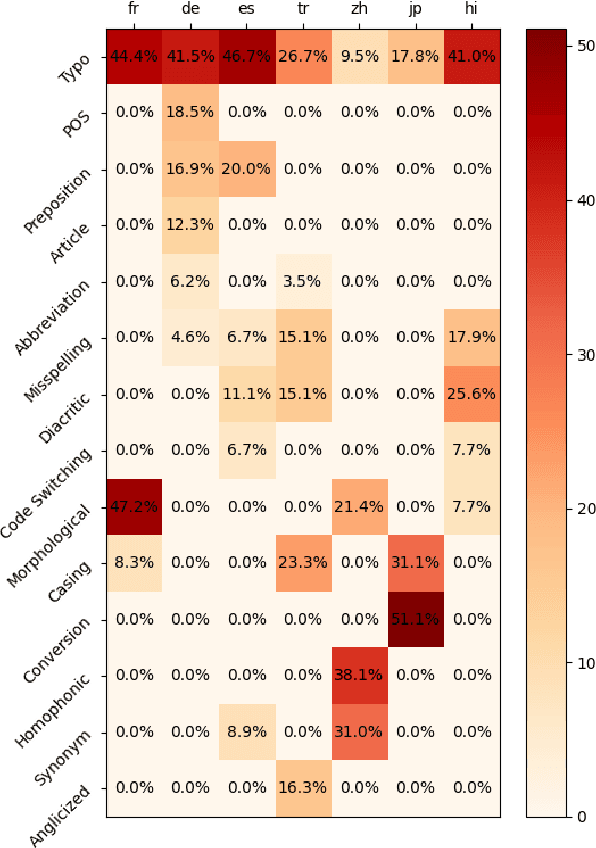
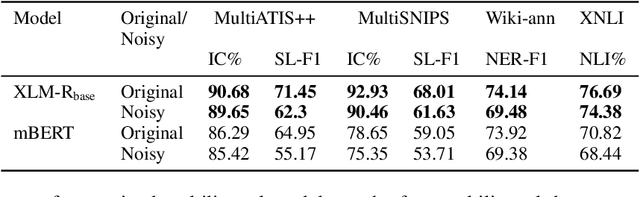
Advances in neural modeling have achieved state-of-the-art (SOTA) results on public natural language processing (NLP) benchmarks, at times surpassing human performance. However, there is a gap between public benchmarks and real-world applications where noise such as typos or grammatical mistakes is abundant, resulting in degraded performance. Unfortunately, works that assess the robustness of neural models on noisy data and suggest improvements are limited to the English language. Upon analyzing noise in different languages, we observe that noise types vary across languages and thus require their own investigation. Thus, to benchmark the performance of pretrained multilingual models, we construct noisy datasets covering five languages and four NLP tasks. We see a gap in performance between clean and noisy data. After investigating ways to boost the zero-shot cross-lingual robustness of multilingual pretrained models, we propose Robust Contrastive Pretraining (RCP). RCP combines data augmentation with a contrastive loss term at the pretraining stage and achieves large improvements on noisy (& original test data) across two sentence-level classification (+3.2%) and two sequence-labeling (+10 F1-score) multilingual tasks.
Label Semantic Aware Pre-training for Few-shot Text Classification
Apr 14, 2022
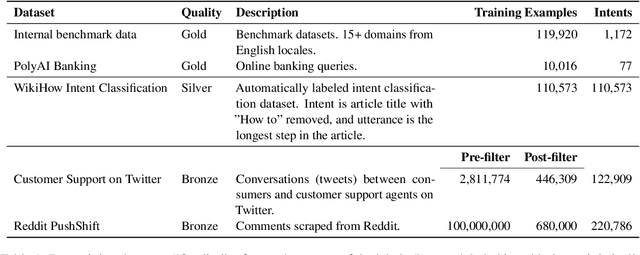
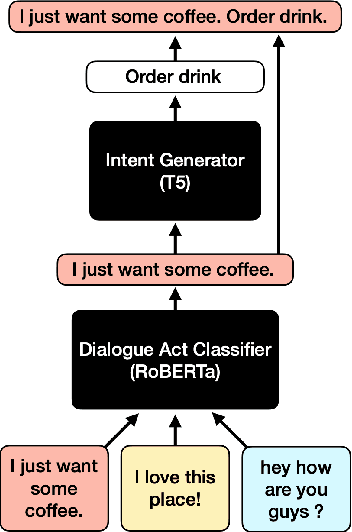
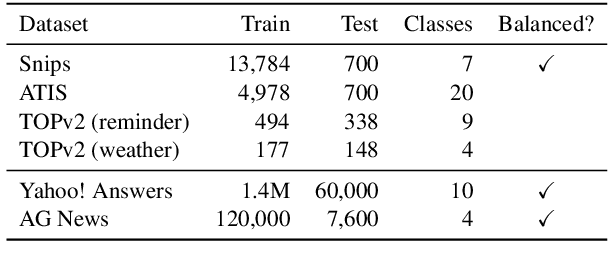
In text classification tasks, useful information is encoded in the label names. Label semantic aware systems have leveraged this information for improved text classification performance during fine-tuning and prediction. However, use of label-semantics during pre-training has not been extensively explored. We therefore propose Label Semantic Aware Pre-training (LSAP) to improve the generalization and data efficiency of text classification systems. LSAP incorporates label semantics into pre-trained generative models (T5 in our case) by performing secondary pre-training on labeled sentences from a variety of domains. As domain-general pre-training requires large amounts of data, we develop a filtering and labeling pipeline to automatically create sentence-label pairs from unlabeled text. We perform experiments on intent (ATIS, Snips, TOPv2) and topic classification (AG News, Yahoo! Answers). LSAP obtains significant accuracy improvements over state-of-the-art models for few-shot text classification while maintaining performance comparable to state of the art in high-resource settings.
Soft Layer Selection with Meta-Learning for Zero-Shot Cross-Lingual Transfer
Jul 21, 2021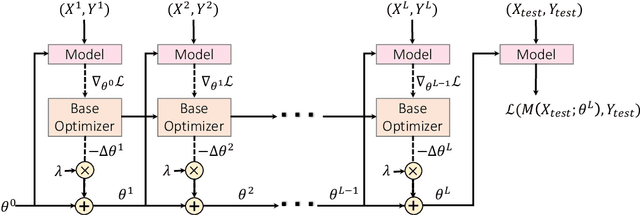
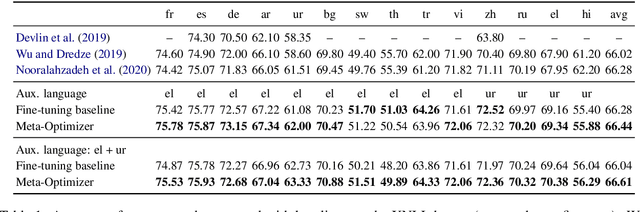

Multilingual pre-trained contextual embedding models (Devlin et al., 2019) have achieved impressive performance on zero-shot cross-lingual transfer tasks. Finding the most effective fine-tuning strategy to fine-tune these models on high-resource languages so that it transfers well to the zero-shot languages is a non-trivial task. In this paper, we propose a novel meta-optimizer to soft-select which layers of the pre-trained model to freeze during fine-tuning. We train the meta-optimizer by simulating the zero-shot transfer scenario. Results on cross-lingual natural language inference show that our approach improves over the simple fine-tuning baseline and X-MAML (Nooralahzadeh et al., 2020).
On the Robustness of Goal Oriented Dialogue Systems to Real-world Noise
Apr 14, 2021
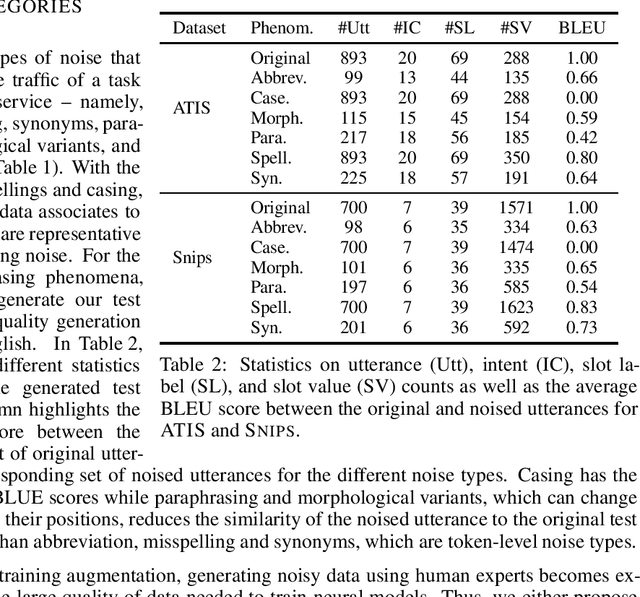
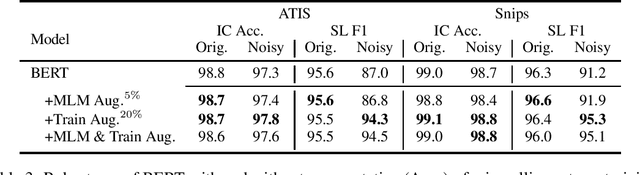
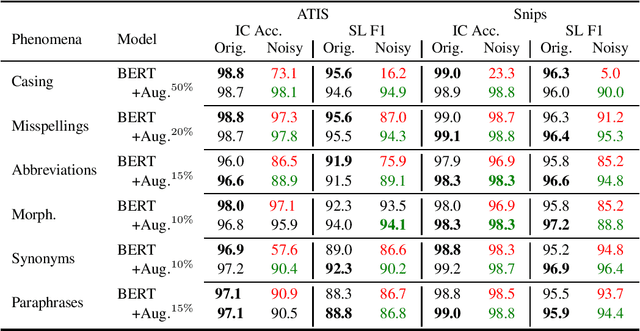
Goal oriented dialogue systems, that interact in real-word environments, often encounter noisy data. In this work, we investigate how robust goal oriented dialogue systems are to noisy data. Specifically, our analysis considers intent classification (IC) and slot labeling (SL) models that form the basis of most dialogue systems. We collect a test-suite for six common phenomena found in live human-to-bot conversations (abbreviations, casing, misspellings, morphological variants, paraphrases, and synonyms) and show that these phenomena can degrade the IC/SL performance of state-of-the-art BERT based models. Through the use of synthetic data augmentation, we are improve IC/SL model's robustness to real-world noise by +11.5 for IC and +17.3 points for SL on average across noise types. We make our suite of noisy test data public to enable further research into the robustness of dialog systems.
Structured Prediction as Translation between Augmented Natural Languages
Jan 28, 2021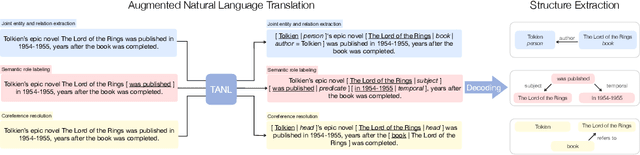
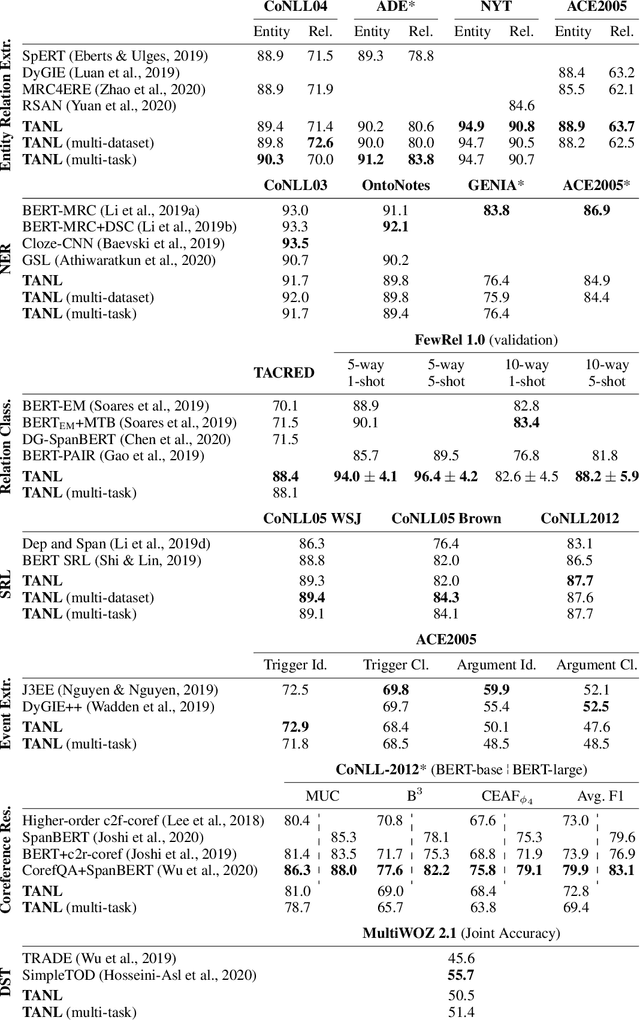
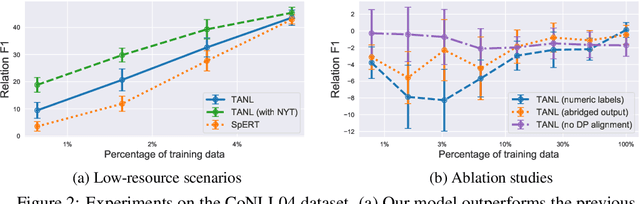
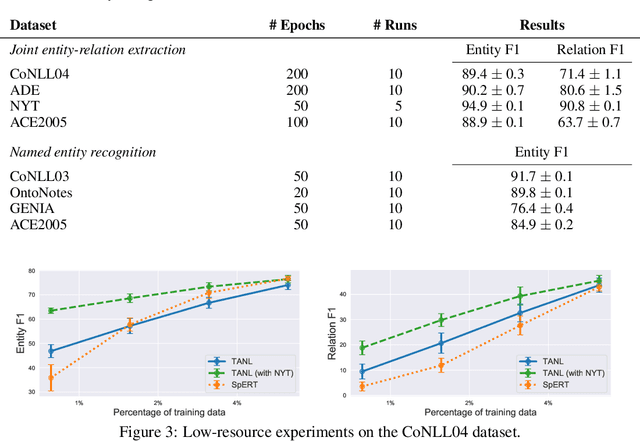
We propose a new framework, Translation between Augmented Natural Languages (TANL), to solve many structured prediction language tasks including joint entity and relation extraction, nested named entity recognition, relation classification, semantic role labeling, event extraction, coreference resolution, and dialogue state tracking. Instead of tackling the problem by training task-specific discriminative classifiers, we frame it as a translation task between augmented natural languages, from which the task-relevant information can be easily extracted. Our approach can match or outperform task-specific models on all tasks, and in particular, achieves new state-of-the-art results on joint entity and relation extraction (CoNLL04, ADE, NYT, and ACE2005 datasets), relation classification (FewRel and TACRED), and semantic role labeling (CoNLL-2005 and CoNLL-2012). We accomplish this while using the same architecture and hyperparameters for all tasks and even when training a single model to solve all tasks at the same time (multi-task learning). Finally, we show that our framework can also significantly improve the performance in a low-resource regime, thanks to better use of label semantics.
Meta learning to classify intent and slot labels with noisy few shot examples
Nov 30, 2020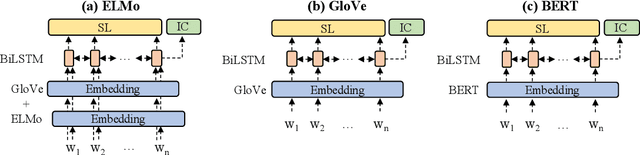
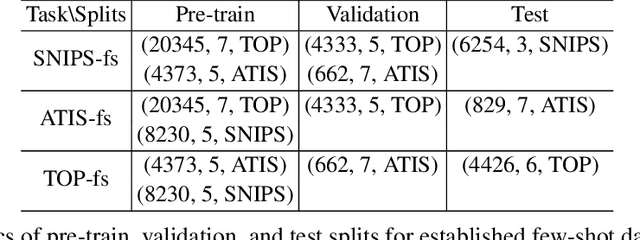
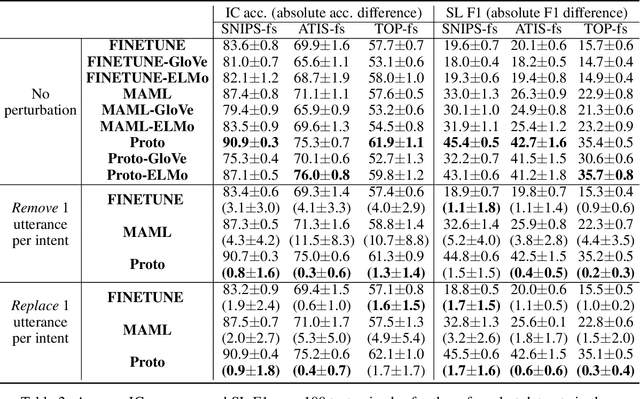
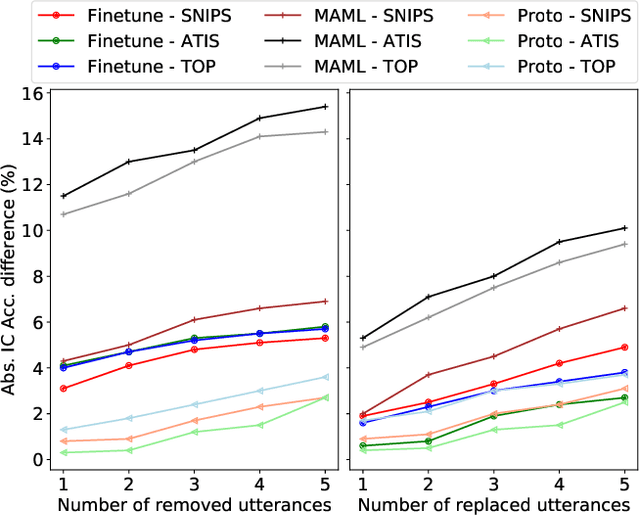
Recently deep learning has dominated many machine learning areas, including spoken language understanding (SLU). However, deep learning models are notorious for being data-hungry, and the heavily optimized models are usually sensitive to the quality of the training examples provided and the consistency between training and inference conditions. To improve the performance of SLU models on tasks with noisy and low training resources, we propose a new SLU benchmarking task: few-shot robust SLU, where SLU comprises two core problems, intent classification (IC) and slot labeling (SL). We establish the task by defining few-shot splits on three public IC/SL datasets, ATIS, SNIPS, and TOP, and adding two types of natural noises (adaptation example missing/replacing and modality mismatch) to the splits. We further propose a novel noise-robust few-shot SLU model based on prototypical networks. We show the model consistently outperforms the conventional fine-tuning baseline and another popular meta-learning method, Model-Agnostic Meta-Learning (MAML), in terms of achieving better IC accuracy and SL F1, and yielding smaller performance variation when noises are present.
Augmented Natural Language for Generative Sequence Labeling
Sep 15, 2020
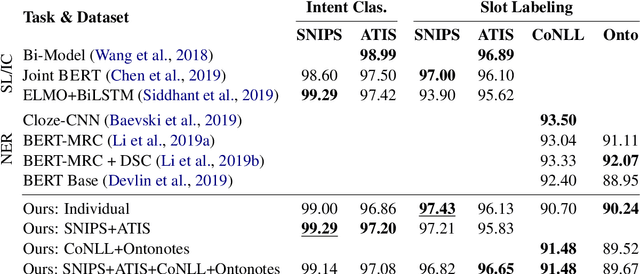
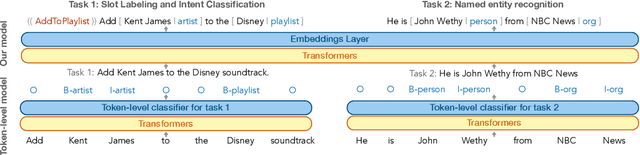
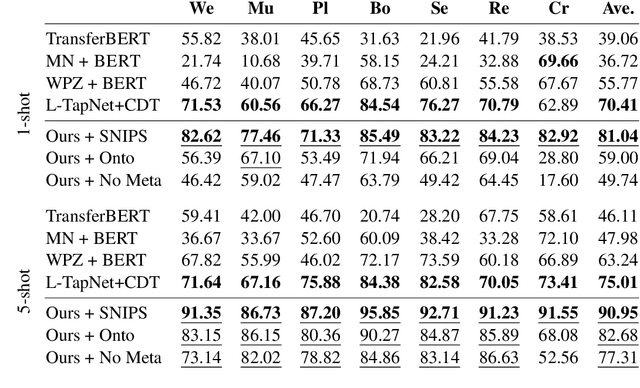
We propose a generative framework for joint sequence labeling and sentence-level classification. Our model performs multiple sequence labeling tasks at once using a single, shared natural language output space. Unlike prior discriminative methods, our model naturally incorporates label semantics and shares knowledge across tasks. Our framework is general purpose, performing well on few-shot, low-resource, and high-resource tasks. We demonstrate these advantages on popular named entity recognition, slot labeling, and intent classification benchmarks. We set a new state-of-the-art for few-shot slot labeling, improving substantially upon the previous 5-shot ($75.0\% \rightarrow 90.9\%$) and 1-shot ($70.4\% \rightarrow 81.0\%$) state-of-the-art results. Furthermore, our model generates large improvements ($46.27\% \rightarrow 63.83\%$) in low-resource slot labeling over a BERT baseline by incorporating label semantics. We also maintain competitive results on high-resource tasks, performing within two points of the state-of-the-art on all tasks and setting a new state-of-the-art on the SNIPS dataset.
Learning to Classify Intents and Slot Labels Given a Handful of Examples
Apr 22, 2020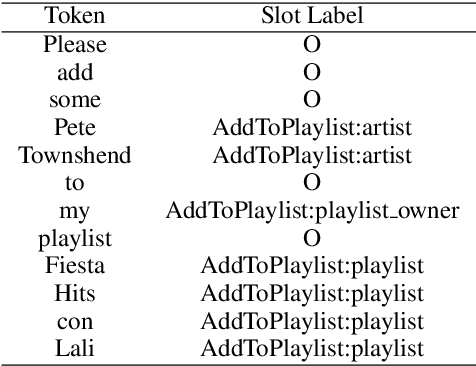
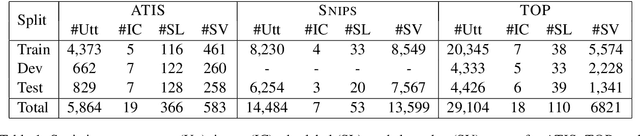

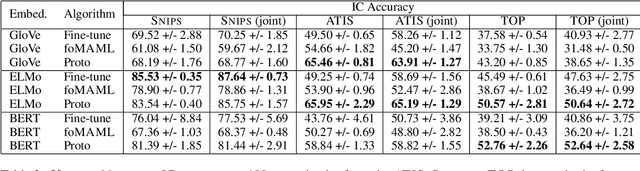
Intent classification (IC) and slot filling (SF) are core components in most goal-oriented dialogue systems. Current IC/SF models perform poorly when the number of training examples per class is small. We propose a new few-shot learning task, few-shot IC/SF, to study and improve the performance of IC and SF models on classes not seen at training time in ultra low resource scenarios. We establish a few-shot IC/SF benchmark by defining few-shot splits for three public IC/SF datasets, ATIS, TOP, and Snips. We show that two popular few-shot learning algorithms, model agnostic meta learning (MAML) and prototypical networks, outperform a fine-tuning baseline on this benchmark. Prototypical networks achieves significant gains in IC performance on the ATIS and TOP datasets, while both prototypical networks and MAML outperform the baseline with respect to SF on all three datasets. In addition, we demonstrate that joint training as well as the use of pre-trained language models, ELMo and BERT in our case, are complementary to these few-shot learning methods and yield further gains.
Multi-task Learning for Continuous Control
Feb 03, 2018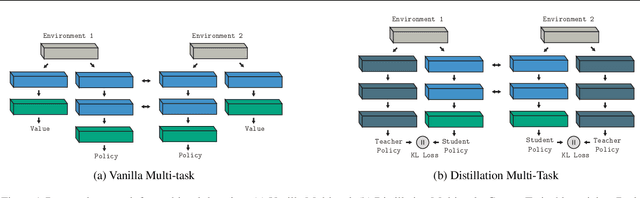

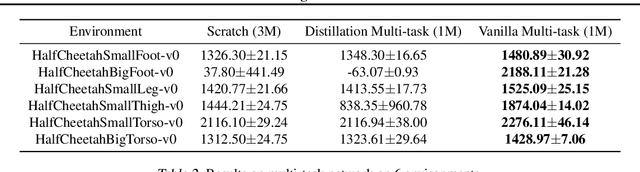
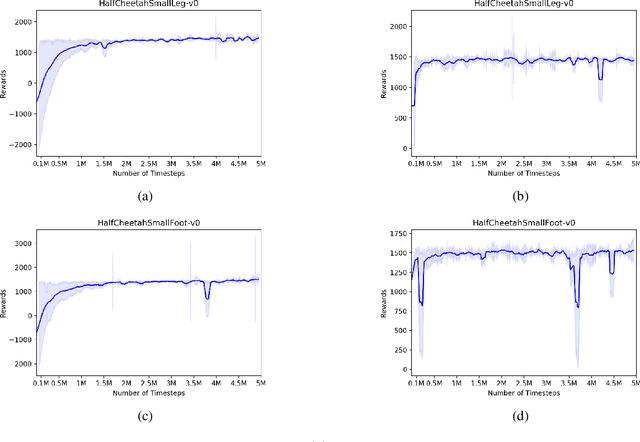
Reliable and effective multi-task learning is a prerequisite for the development of robotic agents that can quickly learn to accomplish related, everyday tasks. However, in the reinforcement learning domain, multi-task learning has not exhibited the same level of success as in other domains, such as computer vision. In addition, most reinforcement learning research on multi-task learning has been focused on discrete action spaces, which are not used for robotic control in the real-world. In this work, we apply multi-task learning methods to continuous action spaces and benchmark their performance on a series of simulated continuous control tasks. Most notably, we show that multi-task learning outperforms our baselines and alternative knowledge sharing methods.