 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Recurrent Off-Policy RL Requires a Context-Encoder-Specific Learning Rate
May 24, 2024



Real-world decision-making tasks are usually partially observable Markov decision processes (POMDPs), where the state is not fully observable. Recent progress has demonstrated that recurrent reinforcement learning (RL), which consists of a context encoder based on recurrent neural networks (RNNs) for unobservable state prediction and a multilayer perceptron (MLP) policy for decision making, can mitigate partial observability and serve as a robust baseline for POMDP tasks. However, previous recurrent RL methods face training stability issues due to the gradient instability of RNNs. In this paper, we propose Recurrent Off-policy RL with Context-Encoder-Specific Learning Rate (RESeL) to tackle this issue. Specifically, RESeL uses a lower learning rate for context encoder than other MLP layers to ensure the stability of the former while maintaining the training efficiency of the latter. We integrate this technique into existing off-policy RL methods, resulting in the RESeL algorithm. We evaluated RESeL in 18 POMDP tasks, including classic, meta-RL, and credit assignment scenarios, as well as five MDP locomotion tasks. The experiments demonstrate significant improvements in training stability with RESeL. Comparative results show that RESeL achieves notable performance improvements over previous recurrent RL baselines in POMDP tasks, and is competitive with or even surpasses state-of-the-art methods in MDP tasks. Further ablation studies highlight the necessity of applying a distinct learning rate for the context encoder.
Reward-Consistent Dynamics Models are Strongly Generalizable for Offline Reinforcement Learning
Oct 09, 2023



Learning a precise dynamics model can be crucial for offline reinforcement learning, which, unfortunately, has been found to be quite challenging. Dynamics models that are learned by fitting historical transitions often struggle to generalize to unseen transitions. In this study, we identify a hidden but pivotal factor termed dynamics reward that remains consistent across transitions, offering a pathway to better generalization. Therefore, we propose the idea of reward-consistent dynamics models: any trajectory generated by the dynamics model should maximize the dynamics reward derived from the data. We implement this idea as the MOREC (Model-based Offline reinforcement learning with Reward Consistency) method, which can be seamlessly integrated into previous offline model-based reinforcement learning (MBRL) methods. MOREC learns a generalizable dynamics reward function from offline data, which is subsequently employed as a transition filter in any offline MBRL method: when generating transitions, the dynamics model generates a batch of transitions and selects the one with the highest dynamics reward value. On a synthetic task, we visualize that MOREC has a strong generalization ability and can surprisingly recover some distant unseen transitions. On 21 offline tasks in D4RL and NeoRL benchmarks, MOREC improves the previous state-of-the-art performance by a significant margin, i.e., 4.6% on D4RL tasks and 25.9% on NeoRL tasks. Notably, MOREC is the first method that can achieve above 95% online RL performance in 6 out of 12 D4RL tasks and 3 out of 9 NeoRL tasks.
Unified Policy Optimization for Continuous-action Reinforcement Learning in Non-stationary Tasks and Games
Aug 19, 2022



This paper addresses policy learning in non-stationary environments and games with continuous actions. Rather than the classical reward maximization mechanism, inspired by the ideas of follow-the-regularized-leader (FTRL) and mirror descent (MD) update, we propose a no-regret style reinforcement learning algorithm PORL for continuous action tasks. We prove that PORL has a last-iterate convergence guarantee, which is important for adversarial and cooperative games. Empirical studies show that, in stationary environments such as MuJoCo locomotion controlling tasks, PORL performs equally well as, if not better than, the soft actor-critic (SAC) algorithm; in non-stationary environments including dynamical environments, adversarial training, and competitive games, PORL is superior to SAC in both a better final policy performance and a more stable training process.
A Survey on Model-based Reinforcement Learning
Jun 19, 2022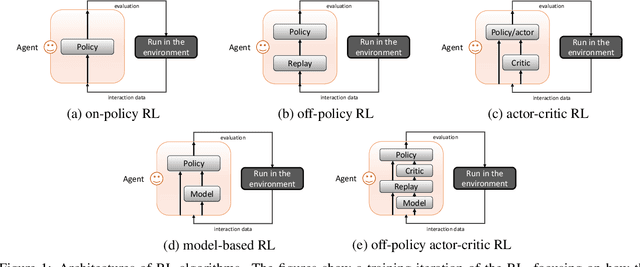
Reinforcement learning (RL) solves sequential decision-making problems via a trial-and-error process interacting with the environment. While RL achieves outstanding success in playing complex video games that allow huge trial-and-error, making errors is always undesired in the real world. To improve the sample efficiency and thus reduce the errors, model-based reinforcement learning (MBRL) is believed to be a promising direction, which builds environment models in which the trial-and-errors can take place without real costs. In this survey, we take a review of MBRL with a focus on the recent progress in deep RL. For non-tabular environments, there is always a generalization error between the learned environment model and the real environment. As such, it is of great importance to analyze the discrepancy between policy training in the environment model and that in the real environment, which in turn guides the algorithm design for better model learning, model usage, and policy training. Besides, we also discuss the recent advances of model-based techniques in other forms of RL, including offline RL, goal-conditioned RL, multi-agent RL, and meta-RL. Moreover, we discuss the applicability and advantages of MBRL in real-world tasks. Finally, we end this survey by discussing the promising prospects for the future development of MBRL. We think that MBRL has great potential and advantages in real-world applications that were overlooked, and we hope this survey could attract more research on MBRL.
Transferable Reward Learning by Dynamics-Agnostic Discriminator Ensemble
Jun 01, 2022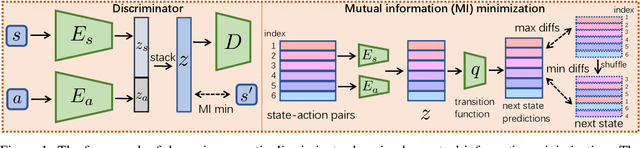

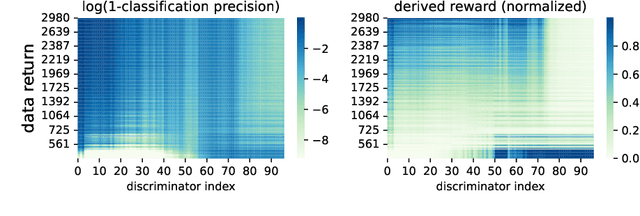

Inverse reinforcement learning (IRL) recovers the underlying reward function from expert demonstrations. A generalizable reward function is even desired as it captures the fundamental motivation of the expert. However, classical IRL methods can only recover reward functions coupled with the training dynamics, thus are hard to generalize to a changed environment. Previous dynamics-agnostic reward learning methods have strict assumptions, such as that the reward function has to be state-only. This work proposes a general approach to learn transferable reward functions, Dynamics-Agnostic Discriminator-Ensemble Reward Learning (DARL). Following the adversarial imitation learning (AIL) framework, DARL learns a dynamics-agnostic discriminator on a latent space mapped from the original state-action space. The latent space is learned to contain the least information of the dynamics. Moreover, to reduce the reliance of the discriminator on policies, the reward function is represented as an ensemble of the discriminators during training. We assess DARL in four MuJoCo tasks with dynamics transfer. Empirical results compared with the state-of-the-art AIL methods show that DARL can learn a reward that is more consistent with the true reward, thus obtaining higher environment returns.