 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Dual Power Spectrum Manifold and Toeplitz HPD Manifold: Enhancement and Analysis for Matrix CFAR Detection
Jun 24, 2022

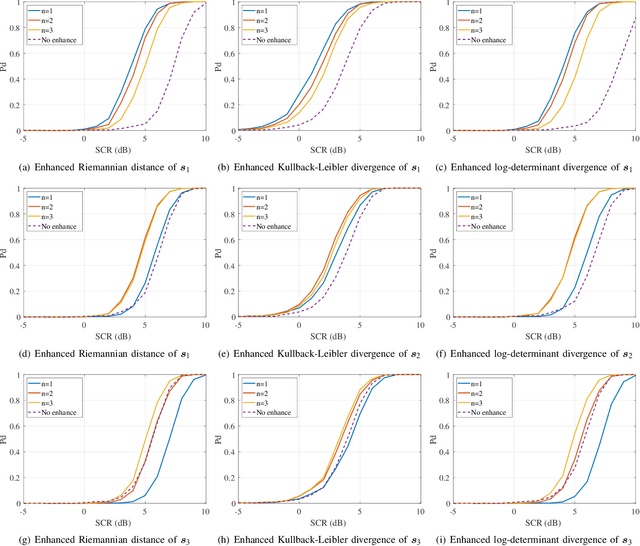
Recently, an innovative matrix CFAR detection scheme based on information geometry, also referred to as the geometric detector, has been developed speedily and exhibits distinct advantages in several practical applications. These advantages benefit from the geometry of the Toeplitz Hermitian positive definite (HPD) manifold $\mathcal{M}_{\mathcal{T}H_{++}}$, but the sophisticated geometry also results in some challenges for geometric detectors, such as the implementation of the enhanced detector to improve the SCR (signal-to-clutter ratio) and the analysis of the detection performance. To meet these challenges, this paper develops the dual power spectrum manifold $\mathcal{M}_{\text{P}}$ as the dual space of $\mathcal{M}_{\mathcal{T}H_{++}}$. For each affine invariant geometric measure on $\mathcal{M}_{\mathcal{T}H_{++}}$, we show that there exists an equivalent function named induced potential function on $\mathcal{M}_{\text{P}}$. By the induced potential function, the measurements of the dissimilarity between two matrices can be implemented on $\mathcal{M}_{\text{P}}$, and the geometric detectors can be reformulated as the form related to the power spectrum. The induced potential function leads to two contributions: 1) The enhancement of the geometric detector, which is formulated as an optimization problem concerning $\mathcal{M}_{\mathcal{T}H_{++}}$, is transformed to an equivalent and simpler optimization on $\mathcal{M}_{\text{P}}$. In the presented example of the enhancement, the closed-form solution, instead of the gradient descent method, is provided through the equivalent optimization. 2) The detection performance is analyzed based on $\mathcal{M}_{\text{P}}$, and the advantageous characteristics, which benefit the detection performance, can be deduced by analyzing the corresponding power spectrum to the maximal point of the induced potential function.
VQMIVC: Vector Quantization and Mutual Information-Based Unsupervised Speech Representation Disentanglement for One-shot Voice Conversion
Jun 18, 2021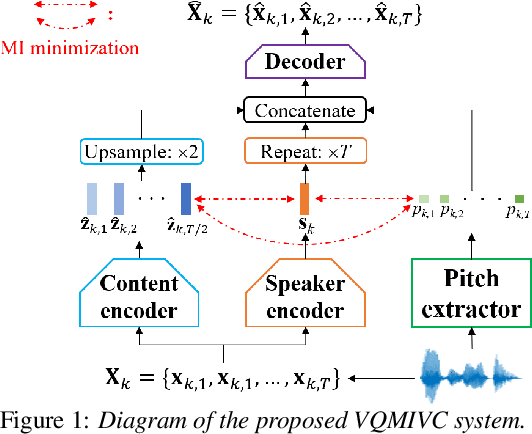
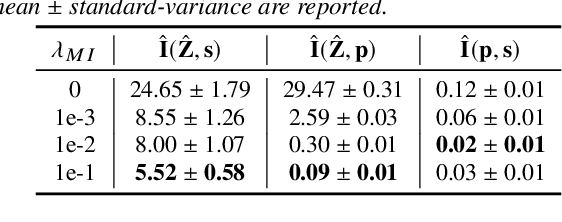
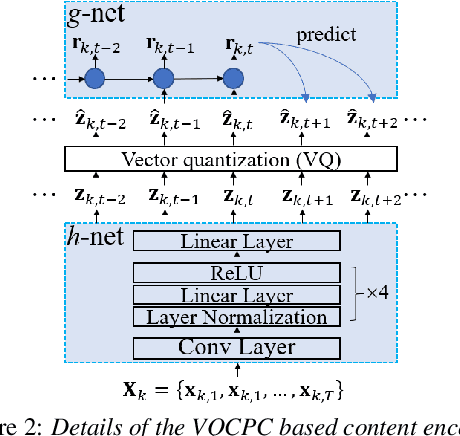
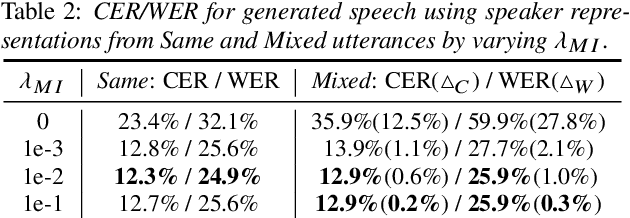
One-shot voice conversion (VC), which performs conversion across arbitrary speakers with only a single target-speaker utterance for reference, can be effectively achieved by speech representation disentanglement. Existing work generally ignores the correlation between different speech representations during training, which causes leakage of content information into the speaker representation and thus degrades VC performance. To alleviate this issue, we employ vector quantization (VQ) for content encoding and introduce mutual information (MI) as the correlation metric during training, to achieve proper disentanglement of content, speaker and pitch representations, by reducing their inter-dependencies in an unsupervised manner. Experimental results reflect the superiority of the proposed method in learning effective disentangled speech representations for retaining source linguistic content and intonation variations, while capturing target speaker characteristics. In doing so, the proposed approach achieves higher speech naturalness and speaker similarity than current state-of-the-art one-shot VC systems. Our code, pre-trained models and demo are available at https://github.com/Wendison/VQMIVC.
BackLink: Supervised Local Training with Backward Links
May 14, 2022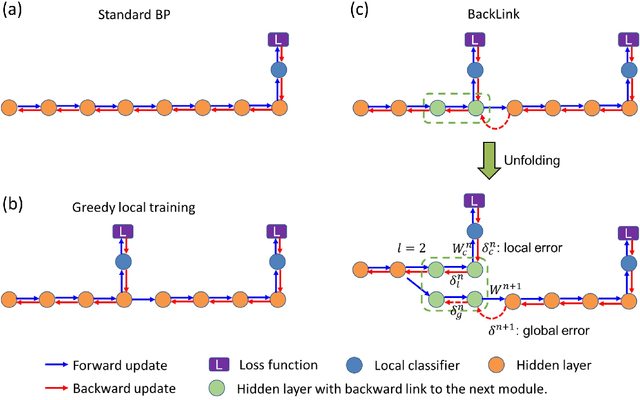
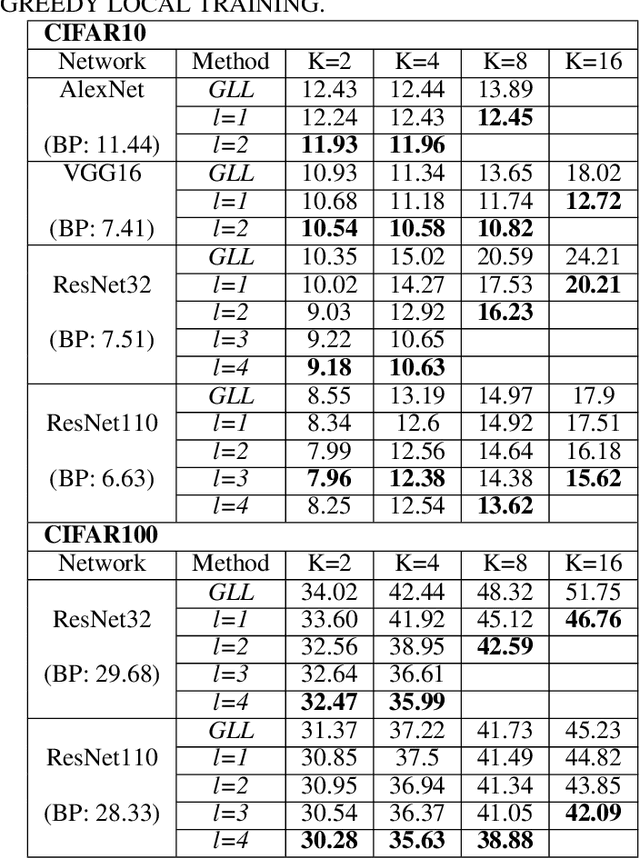
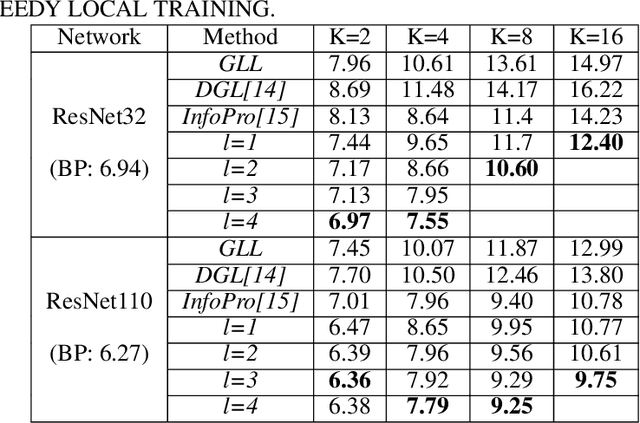
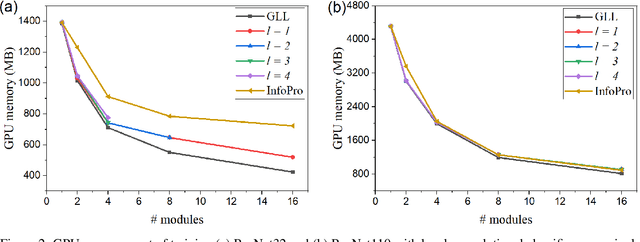
Empowered by the backpropagation (BP) algorithm, deep neural networks have dominated the race in solving various cognitive tasks. The restricted training pattern in the standard BP requires end-to-end error propagation, causing large memory cost and prohibiting model parallelization. Existing local training methods aim to resolve the training obstacle by completely cutting off the backward path between modules and isolating their gradients to reduce memory cost and accelerate the training process. These methods prevent errors from flowing between modules and hence information exchange, resulting in inferior performance. This work proposes a novel local training algorithm, BackLink, which introduces inter-module backward dependency and allows errors to flow between modules. The algorithm facilitates information to flow backward along with the network. To preserve the computational advantage of local training, BackLink restricts the error propagation length within the module. Extensive experiments performed in various deep convolutional neural networks demonstrate that our method consistently improves the classification performance of local training algorithms over other methods. For example, in ResNet32 with 16 local modules, our method surpasses the conventional greedy local training method by 4.00\% and a recent work by 1.83\% in accuracy on CIFAR10, respectively. Analysis of computational costs reveals that small overheads are incurred in GPU memory costs and runtime on multiple GPUs. Our method can lead up to a 79\% reduction in memory cost and 52\% in simulation runtime in ResNet110 compared to the standard BP. Therefore, our method could create new opportunities for improving training algorithms towards better efficiency and biological plausibility.
MMINR: Multi-frame-to-Multi-frame Inference with Noise Resistance for Precipitation Nowcasting with Radar
May 05, 2022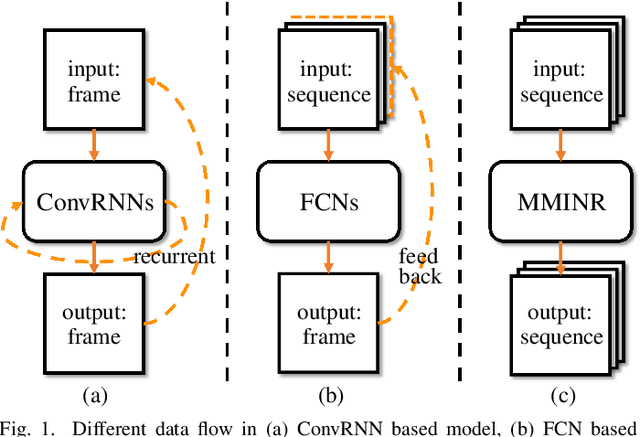
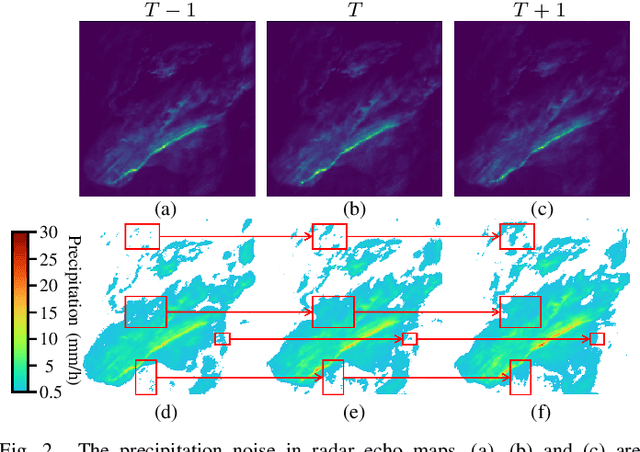
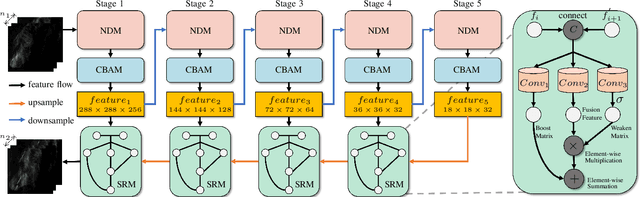
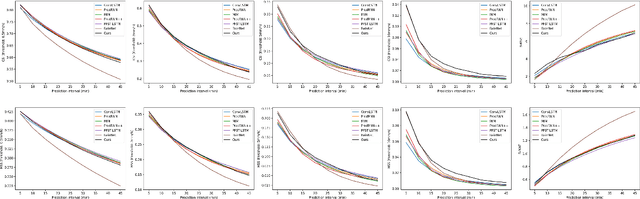
Precipitation nowcasting based on radar echo maps is essential in meteorological research. Recently, Convolutional RNNs based methods dominate this field, but they cannot be solved by parallel computation resulting in longer inference time. FCN based methods adopt a multi-frame-to-single-frame inference (MSI) strategy to avoid this problem. They feedback into the model again to predict the next time step to get multi-frame nowcasting results in the prediction phase, which will lead to the accumulation of prediction errors. In addition, precipitation noise is a crucial factor contributing to high prediction errors because of its unpredictability. To address this problem, we propose a novel Multi-frame-to-Multi-frame Inference (MMI) model with Noise Resistance (NR) named MMINR. It avoids error accumulation and resists precipitation noise\'s negative effect in parallel computation. NR contains a Noise Dropout Module (NDM) and a Semantic Restore Module (SRM). NDM deliberately dropout noise simple yet efficient, and SRM supplements semantic information of features to alleviate the problem of semantic information mistakenly lost by NDM. Experimental results demonstrate that MMINR can attain competitive scores compared with other SOTAs. The ablation experiments show that the proposed NDM and SRM can solve the aforementioned problems.
Decentralized Stochastic Optimization with Inherent Privacy Protection
May 08, 2022
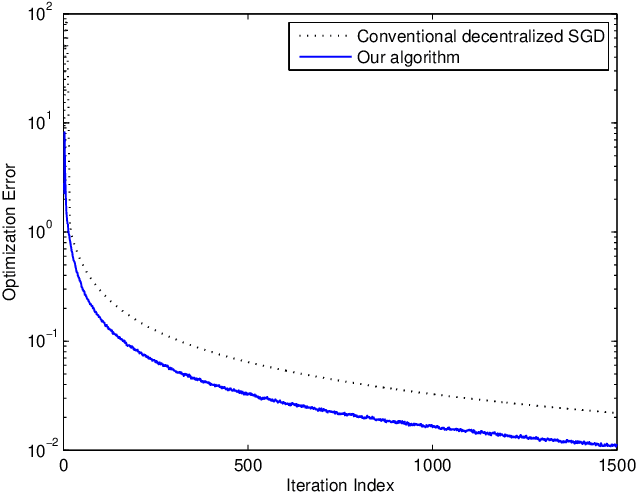
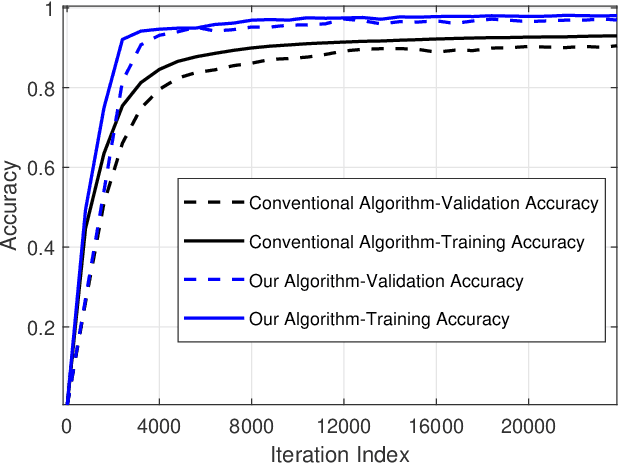

Decentralized stochastic optimization is the basic building block of modern collaborative machine learning, distributed estimation and control, and large-scale sensing. Since involved data usually contain sensitive information like user locations, healthcare records and financial transactions, privacy protection has become an increasingly pressing need in the implementation of decentralized stochastic optimization algorithms. In this paper, we propose a decentralized stochastic gradient descent algorithm which is embedded with inherent privacy protection for every participating agent against other participating agents and external eavesdroppers. This proposed algorithm builds in a dynamics based gradient-obfuscation mechanism to enable privacy protection without compromising optimization accuracy, which is in significant difference from differential-privacy based privacy solutions for decentralized optimization that have to trade optimization accuracy for privacy. The dynamics based privacy approach is encryption-free, and hence avoids incurring heavy communication or computation overhead, which is a common problem with encryption based privacy solutions for decentralized stochastic optimization. Besides rigorously characterizing the convergence performance of the proposed decentralized stochastic gradient descent algorithm under both convex objective functions and non-convex objective functions, we also provide rigorous information-theoretic analysis of its strength of privacy protection. Simulation results for a distributed estimation problem as well as numerical experiments for decentralized learning on a benchmark machine learning dataset confirm the effectiveness of the proposed approach.
Decoupling multivariate functions using a nonparametric filtered tensor decomposition
May 23, 2022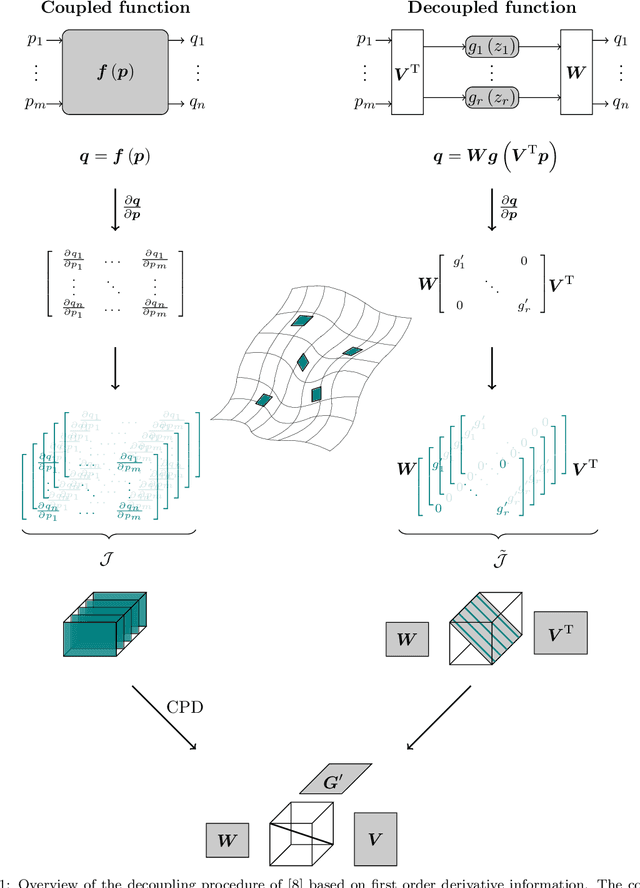
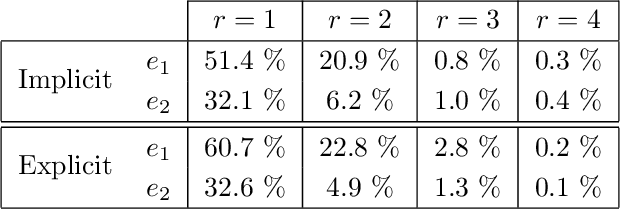
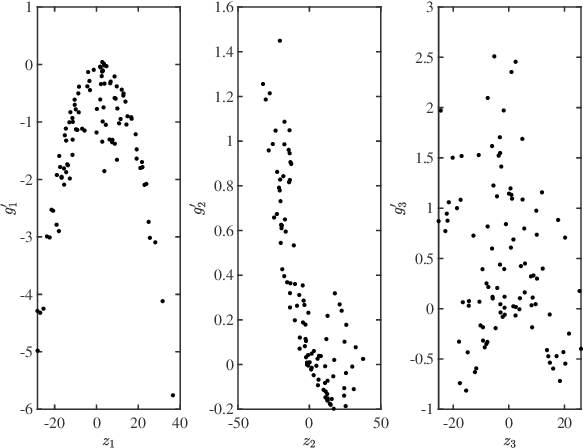
Multivariate functions emerge naturally in a wide variety of data-driven models. Popular choices are expressions in the form of basis expansions or neural networks. While highly effective, the resulting functions tend to be hard to interpret, in part because of the large number of required parameters. Decoupling techniques aim at providing an alternative representation of the nonlinearity. The so-called decoupled form is often a more efficient parameterisation of the relationship while being highly structured, favouring interpretability. In this work two new algorithms, based on filtered tensor decompositions of first order derivative information are introduced. The method returns nonparametric estimates of smooth decoupled functions. Direct applications are found in, i.a. the fields of nonlinear system identification and machine learning.
Evaluating Fairness of Machine Learning Models Under Uncertain and Incomplete Information
Feb 16, 2021
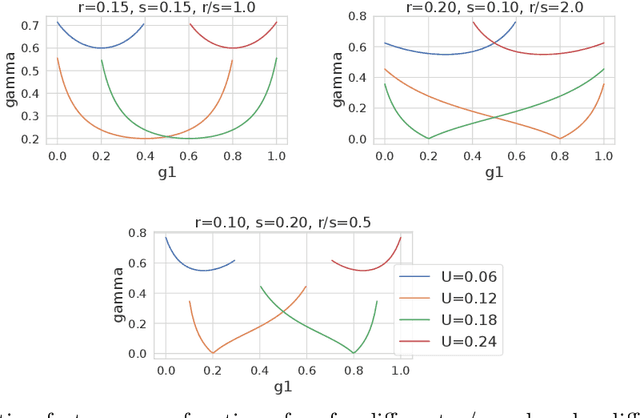


Training and evaluation of fair classifiers is a challenging problem. This is partly due to the fact that most fairness metrics of interest depend on both the sensitive attribute information and label information of the data points. In many scenarios it is not possible to collect large datasets with such information. An alternate approach that is commonly used is to separately train an attribute classifier on data with sensitive attribute information, and then use it later in the ML pipeline to evaluate the bias of a given classifier. While such decoupling helps alleviate the problem of demographic scarcity, it raises several natural questions such as: how should the attribute classifier be trained?, and how should one use a given attribute classifier for accurate bias estimation? In this work we study this question from both theoretical and empirical perspectives. We first experimentally demonstrate that the test accuracy of the attribute classifier is not always correlated with its effectiveness in bias estimation for a downstream model. In order to further investigate this phenomenon, we analyze an idealized theoretical model and characterize the structure of the optimal classifier. Our analysis has surprising and counter-intuitive implications where in certain regimes one might want to distribute the error of the attribute classifier as unevenly as possible among the different subgroups. Based on our analysis we develop heuristics for both training and using attribute classifiers for bias estimation in the data scarce regime. We empirically demonstrate the effectiveness of our approach on real and simulated data.
How Adults Understand What Young Children Say
Jun 15, 2022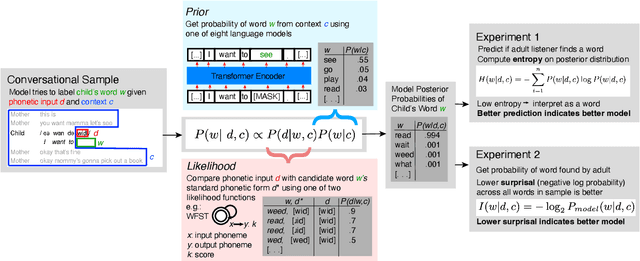
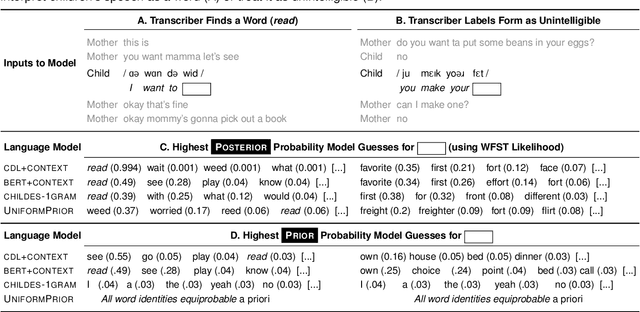
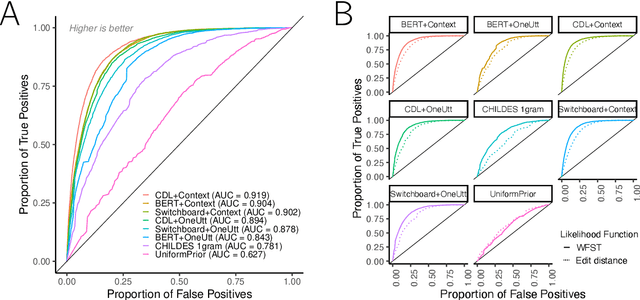
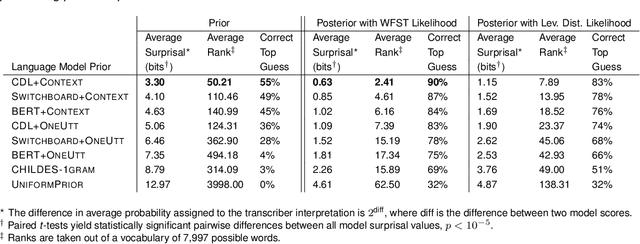
Children's early speech often bears little resemblance to adult speech in form or content, and yet caregivers often find meaning in young children's utterances. Precisely how caregivers are able to do this remains poorly understood. We propose that successful early communication (an essential building block of language development) relies not just on children's growing linguistic knowledge, but also on adults' sophisticated inferences. These inferences, we further propose, are optimized for fine-grained details of how children speak. We evaluate these ideas using a set of candidate computational models of spoken word recognition based on deep learning and Bayesian inference, which instantiate competing hypotheses regarding the information sources used by adults to understand children. We find that the best-performing models (evaluated on datasets of adult interpretations of child speech) are those that have strong prior expectations about what children are likely to want to communicate, rather than the actual phonetic contents of what children say. We further find that adults' behavior is best characterized as well-tuned to specific children: the more closely a word recognition model is tuned to the particulars of an individual child's actual linguistic behavior, the better it predicts adults' inferences about what the child has said. These results offer a comprehensive investigation into the role of caregivers as child-directed listeners, with broader consequences for theories of language acquisition.
Incentivizing Combinatorial Bandit Exploration
Jun 01, 2022Consider a bandit algorithm that recommends actions to self-interested users in a recommendation system. The users are free to choose other actions and need to be incentivized to follow the algorithm's recommendations. While the users prefer to exploit, the algorithm can incentivize them to explore by leveraging the information collected from the previous users. All published work on this problem, known as incentivized exploration, focuses on small, unstructured action sets and mainly targets the case when the users' beliefs are independent across actions. However, realistic exploration problems often feature large, structured action sets and highly correlated beliefs. We focus on a paradigmatic exploration problem with structure: combinatorial semi-bandits. We prove that Thompson Sampling, when applied to combinatorial semi-bandits, is incentive-compatible when initialized with a sufficient number of samples of each arm (where this number is determined in advance by the Bayesian prior). Moreover, we design incentive-compatible algorithms for collecting the initial samples.
Dataset Condensation via Efficient Synthetic-Data Parameterization
May 30, 2022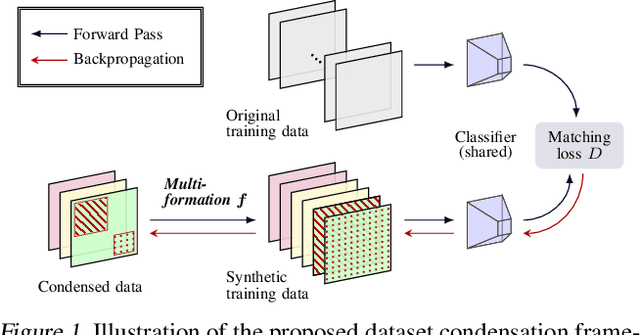
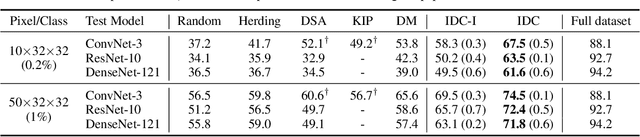
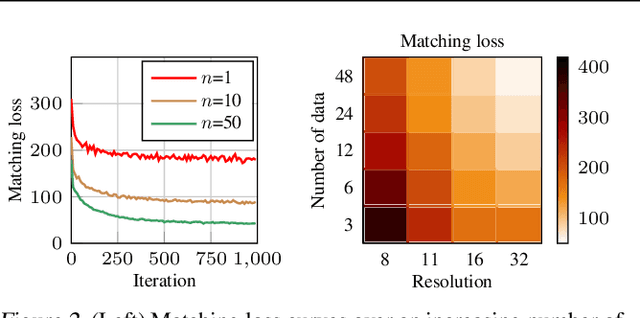
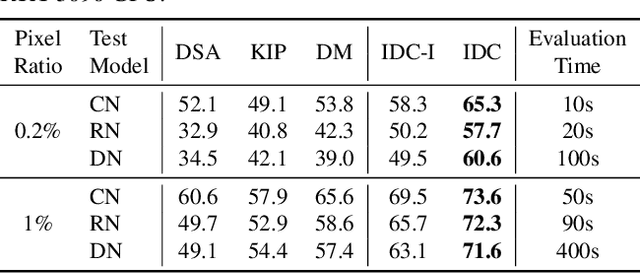
The great success of machine learning with massive amounts of data comes at a price of huge computation costs and storage for training and tuning. Recent studies on dataset condensation attempt to reduce the dependence on such massive data by synthesizing a compact training dataset. However, the existing approaches have fundamental limitations in optimization due to the limited representability of synthetic datasets without considering any data regularity characteristics. To this end, we propose a novel condensation framework that generates multiple synthetic data with a limited storage budget via efficient parameterization considering data regularity. We further analyze the shortcomings of the existing gradient matching-based condensation methods and develop an effective optimization technique for improving the condensation of training data information. We propose a unified algorithm that drastically improves the quality of condensed data against the current state-of-the-art on CIFAR-10, ImageNet, and Speech Commands.