 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Coverage Probability of STAR-RIS assisted Massive MIMO systems with Correlation and Phase Errors
May 31, 2022
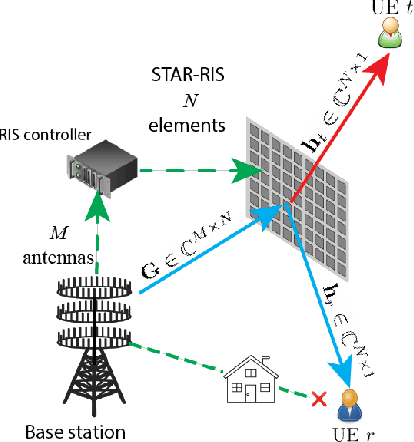
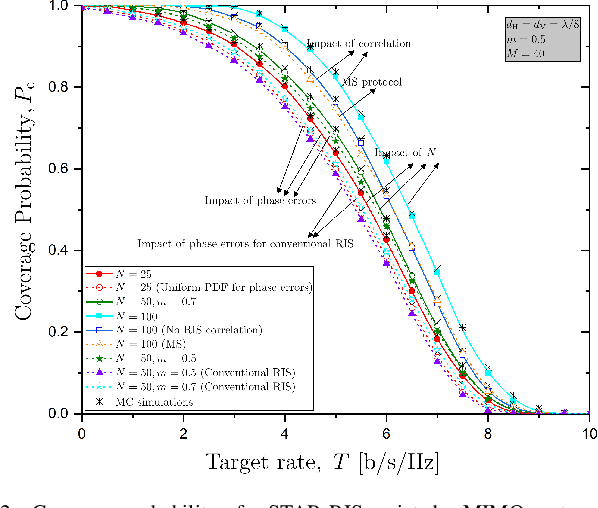
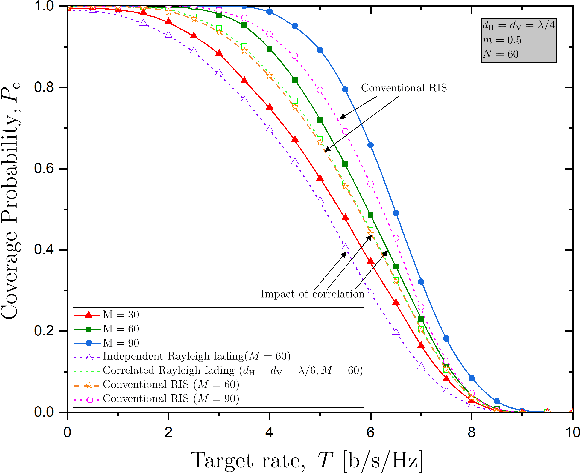
In this paper, we investigate a simultaneous transmitting and reflecting reconfigurable intelligent surface (STAR-RIS) assisting a massive multiple-input multiple-output (mMIMO) system. In particular, we derive a closed-form expression for the coverage probability of a STAR-RIS assisted mMIMO system while accounting for correlated fading and phase-shift errors. Notably, the phase configuration takes place at every several coherence intervals by optimizing the coverage probability since the latter depends on statistical channel state information (CSI) in terms of large-scale statistics. As a result, we achieve a reduced complexity and overhead for the optimization of passive beamforming, which are increased in the case of STAR-RIS networks with instantaneous CSI. Numerical results corroborate our analysis, shed light on interesting properties such as the impact of the number of RIS elements and the effect of phase errors, along with affirming the superiority of STAR-RIS against reflective-only RIS.
NAGphormer: Neighborhood Aggregation Graph Transformer for Node Classification in Large Graphs
Jun 10, 2022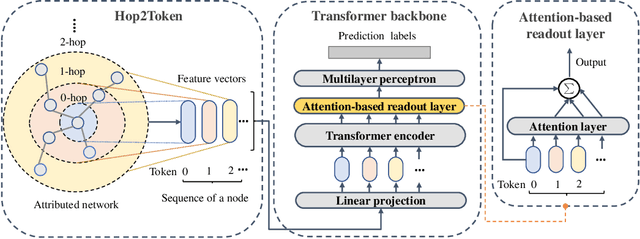
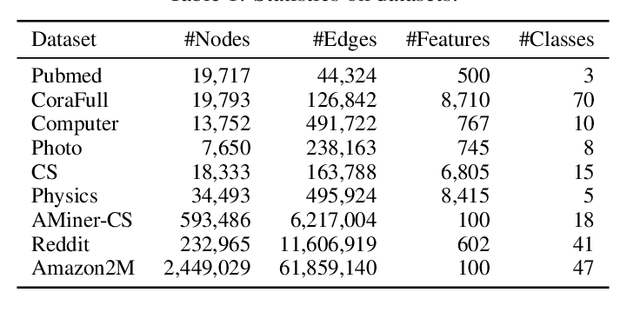
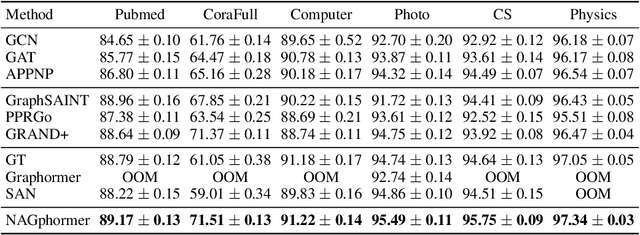
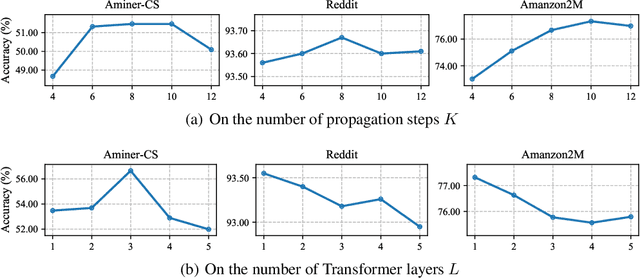
Graph Transformers have demonstrated superiority on various graph learning tasks in recent years. However, the complexity of existing Graph Transformers scales quadratically with the number of nodes, making it hard to scale to graphs with thousands of nodes. To this end, we propose a Neighborhood Aggregation Graph Transformer (NAGphormer) that is scalable to large graphs with millions of nodes. Before feeding the node features into the Transformer model, NAGphormer constructs tokens for each node by a neighborhood aggregation module called Hop2Token. For each node, Hop2Token aggregates neighborhood features from each hop into a representation, and thereby produces a sequence of token vectors. Subsequently, the resulting sequence of different hop information serves as input to the Transformer model. By considering each node as a sequence, NAGphormer could be trained in a mini-batch manner and thus could scale to large graphs. NAGphormer further develops an attention-based readout function so as to learn the importance of each hop adaptively. We conduct extensive experiments on various popular benchmarks, including six small datasets and three large datasets. The results demonstrate that NAGphormer consistently outperforms existing Graph Transformers and mainstream Graph Neural Networks.
Beyond a Pre-Trained Object Detector: Cross-Modal Textual and Visual Context for Image Captioning
May 09, 2022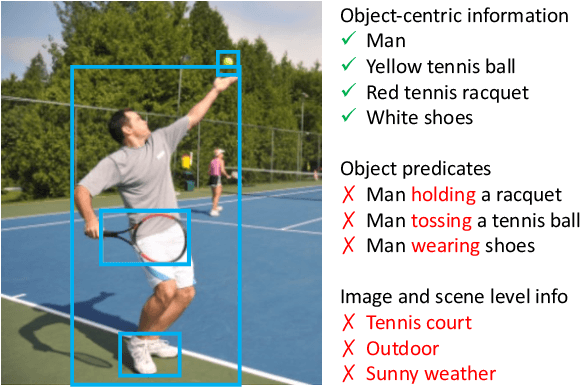
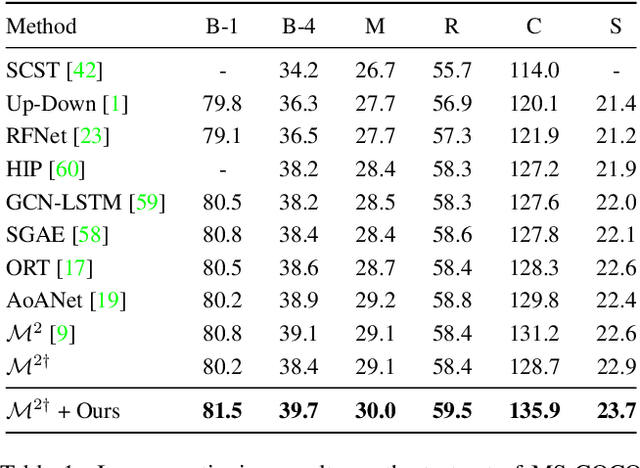
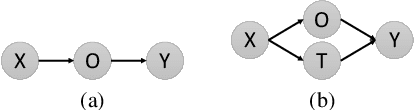
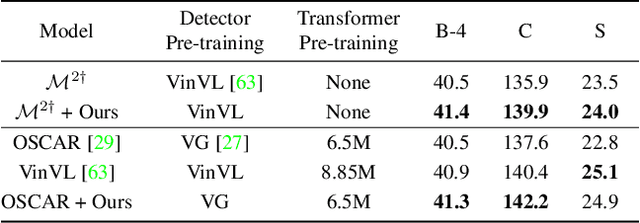
Significant progress has been made on visual captioning, largely relying on pre-trained features and later fixed object detectors that serve as rich inputs to auto-regressive models. A key limitation of such methods, however, is that the output of the model is conditioned only on the object detector's outputs. The assumption that such outputs can represent all necessary information is unrealistic, especially when the detector is transferred across datasets. In this work, we reason about the graphical model induced by this assumption, and propose to add an auxiliary input to represent missing information such as object relationships. We specifically propose to mine attributes and relationships from the Visual Genome dataset and condition the captioning model on them. Crucially, we propose (and show to be important) the use of a multi-modal pre-trained model (CLIP) to retrieve such contextual descriptions. Further, object detector models are frozen and do not have sufficient richness to allow the captioning model to properly ground them. As a result, we propose to condition both the detector and description outputs on the image, and show qualitatively and quantitatively that this can improve grounding. We validate our method on image captioning, perform thorough analyses of each component and importance of the pre-trained multi-modal model, and demonstrate significant improvements over the current state of the art, specifically +7.5% in CIDEr and +1.3% in BLEU-4 metrics.
AntPivot: Livestream Highlight Detection via Hierarchical Attention Mechanism
Jun 10, 2022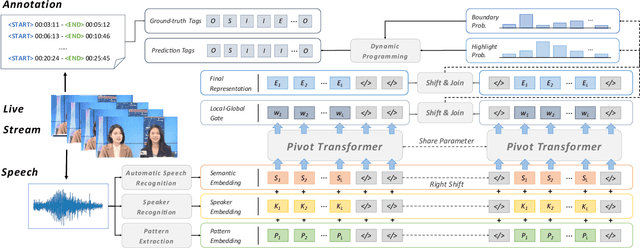

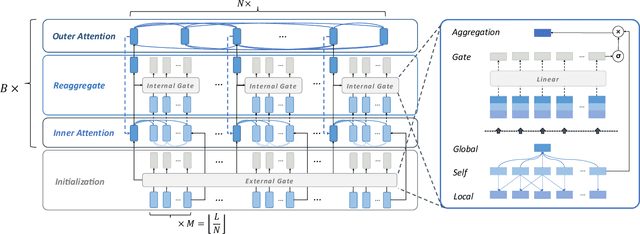
In recent days, streaming technology has greatly promoted the development in the field of livestream. Due to the excessive length of livestream records, it's quite essential to extract highlight segments with the aim of effective reproduction and redistribution. Although there are lots of approaches proven to be effective in the highlight detection for other modals, the challenges existing in livestream processing, such as the extreme durations, large topic shifts, much irrelevant information and so forth, heavily hamper the adaptation and compatibility of these methods. In this paper, we formulate a new task Livestream Highlight Detection, discuss and analyze the difficulties listed above and propose a novel architecture AntPivot to solve this problem. Concretely, we first encode the original data into multiple views and model their temporal relations to capture clues in a hierarchical attention mechanism. Afterwards, we try to convert the detection of highlight clips into the search for optimal decision sequences and use the fully integrated representations to predict the final results in a dynamic-programming mechanism. Furthermore, we construct a fully-annotated dataset AntHighlight to instantiate this task and evaluate the performance of our model. The extensive experiments indicate the effectiveness and validity of our proposed method.
Benchmarking Heterogeneous Treatment Effect Models through the Lens of Interpretability
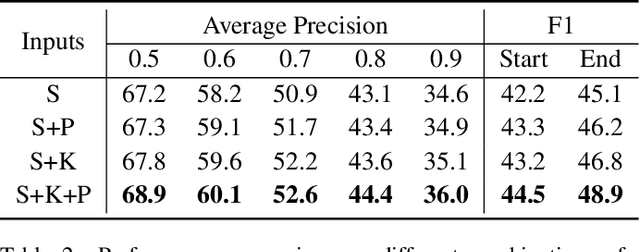
Jun 16, 2022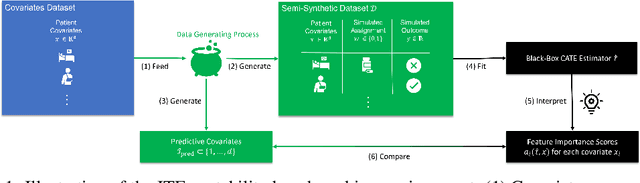

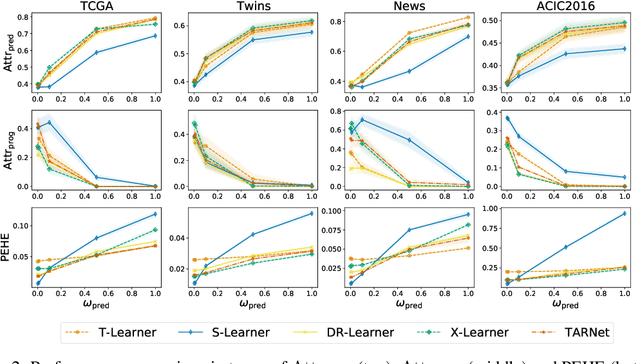
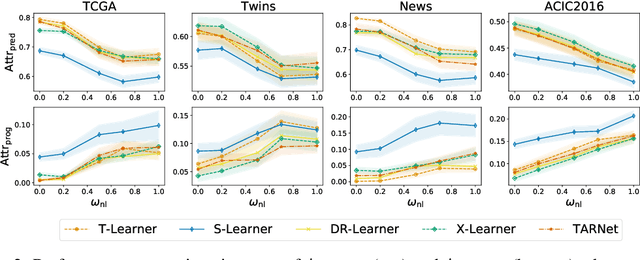
Estimating personalized effects of treatments is a complex, yet pervasive problem. To tackle it, recent developments in the machine learning (ML) literature on heterogeneous treatment effect estimation gave rise to many sophisticated, but opaque, tools: due to their flexibility, modularity and ability to learn constrained representations, neural networks in particular have become central to this literature. Unfortunately, the assets of such black boxes come at a cost: models typically involve countless nontrivial operations, making it difficult to understand what they have learned. Yet, understanding these models can be crucial -- in a medical context, for example, discovered knowledge on treatment effect heterogeneity could inform treatment prescription in clinical practice. In this work, we therefore use post-hoc feature importance methods to identify features that influence the model's predictions. This allows us to evaluate treatment effect estimators along a new and important dimension that has been overlooked in previous work: We construct a benchmarking environment to empirically investigate the ability of personalized treatment effect models to identify predictive covariates -- covariates that determine differential responses to treatment. Our benchmarking environment then enables us to provide new insight into the strengths and weaknesses of different types of treatment effects models as we modulate different challenges specific to treatment effect estimation -- e.g. the ratio of prognostic to predictive information, the possible nonlinearity of potential outcomes and the presence and type of confounding.
Context-based Deep Learning Architecture with Optimal Integration Layer for Image Parsing
Apr 13, 2022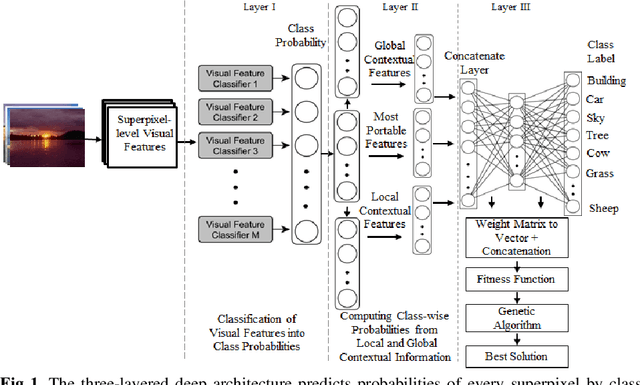
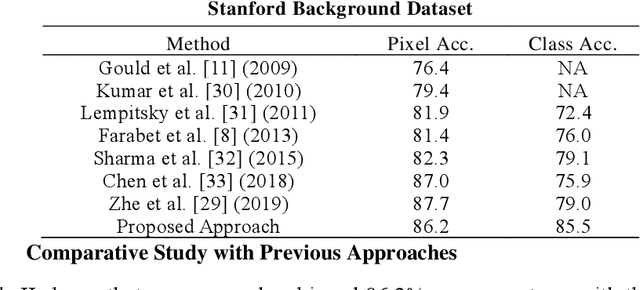
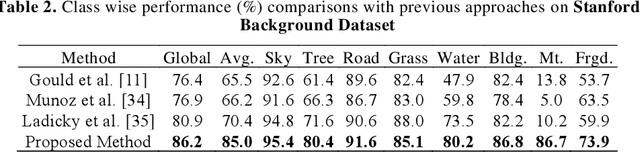
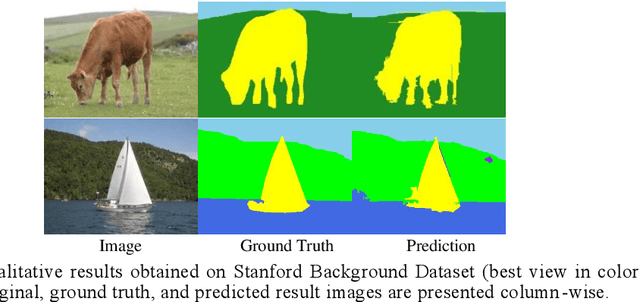
Deep learning models have been efficient lately on image parsing tasks. However, deep learning models are not fully capable of exploiting visual and contextual information simultaneously. The proposed three-layer context-based deep architecture is capable of integrating context explicitly with visual information. The novel idea here is to have a visual layer to learn visual characteristics from binary class-based learners, a contextual layer to learn context, and then an integration layer to learn from both via genetic algorithm-based optimal fusion to produce a final decision. The experimental outcomes when evaluated on benchmark datasets are promising. Further analysis shows that optimized network weights can improve performance and make stable predictions.
Probing Speech Emotion Recognition Transformers for Linguistic Knowledge
Apr 01, 2022
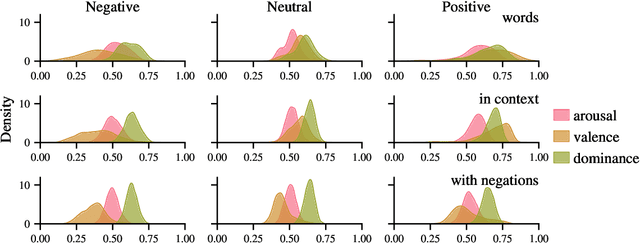
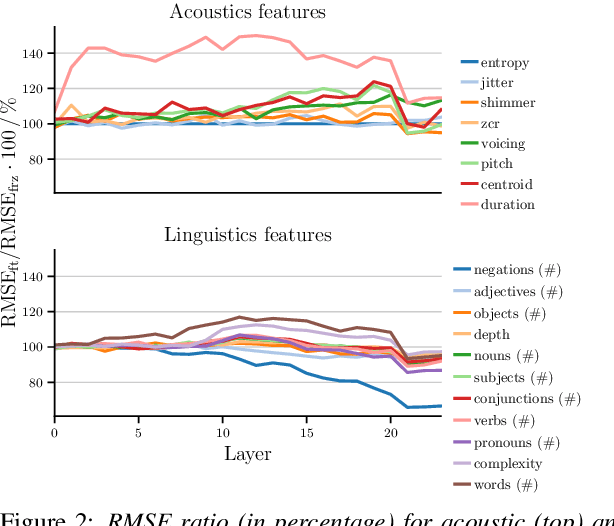
Large, pre-trained neural networks consisting of self-attention layers (transformers) have recently achieved state-of-the-art results on several speech emotion recognition (SER) datasets. These models are typically pre-trained in self-supervised manner with the goal to improve automatic speech recognition performance -- and thus, to understand linguistic information. In this work, we investigate the extent in which this information is exploited during SER fine-tuning. Using a reproducible methodology based on open-source tools, we synthesise prosodically neutral speech utterances while varying the sentiment of the text. Valence predictions of the transformer model are very reactive to positive and negative sentiment content, as well as negations, but not to intensifiers or reducers, while none of those linguistic features impact arousal or dominance. These findings show that transformers can successfully leverage linguistic information to improve their valence predictions, and that linguistic analysis should be included in their testing.
Terrain Classification using Transfer Learning on Hyperspectral Images: A Comparative study
Jun 19, 2022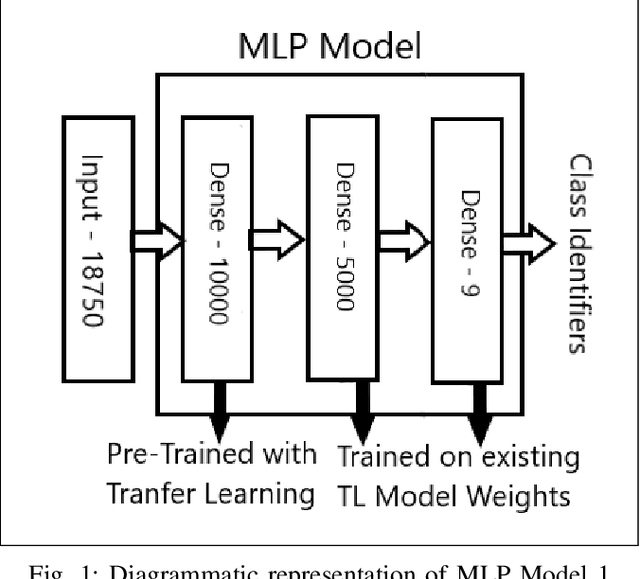
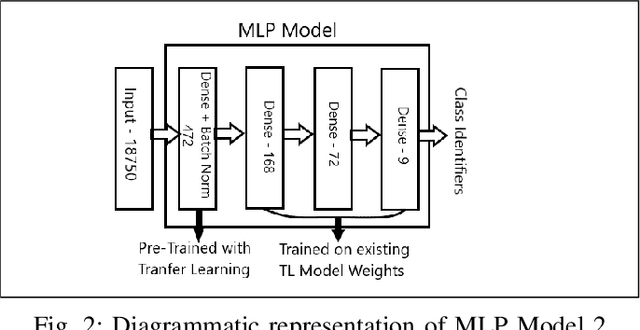
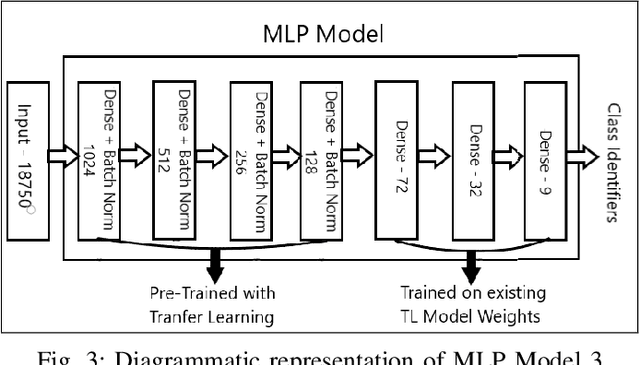
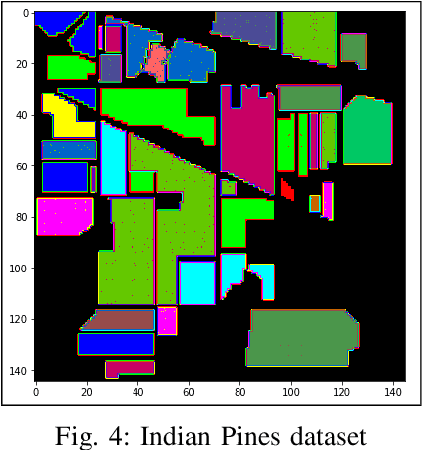
A Hyperspectral image contains much more number of channels as compared to a RGB image, hence containing more information about entities within the image. The convolutional neural network (CNN) and the Multi-Layer Perceptron (MLP) have been proven to be an effective method of image classification. However, they suffer from the issues of long training time and requirement of large amounts of the labeled data, to achieve the expected outcome. These issues become more complex while dealing with hyperspectral images. To decrease the training time and reduce the dependence on large labeled dataset, we propose using the method of transfer learning. The hyperspectral dataset is preprocessed to a lower dimension using PCA, then deep learning models are applied to it for the purpose of classification. The features learned by this model are then used by the transfer learning model to solve a new classification problem on an unseen dataset. A detailed comparison of CNN and multiple MLP architectural models is performed, to determine an optimum architecture that suits best the objective. The results show that the scaling of layers not always leads to increase in accuracy but often leads to overfitting, and also an increase in the training time.The training time is reduced to greater extent by applying the transfer learning approach rather than just approaching the problem by directly training a new model on large datasets, without much affecting the accuracy.
ResizeMix: Mixing Data with Preserved Object Information and True Labels
Dec 21, 2020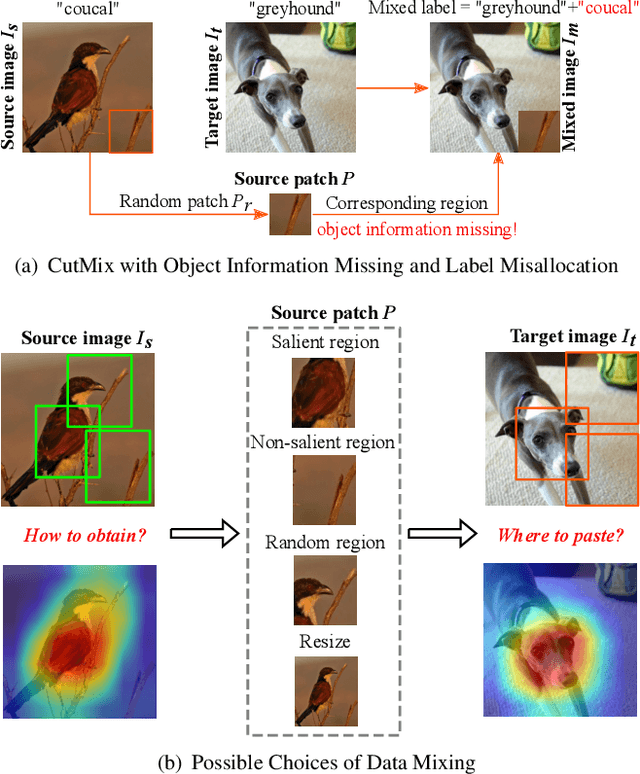
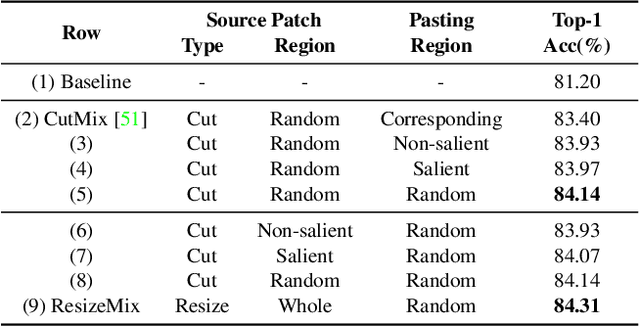
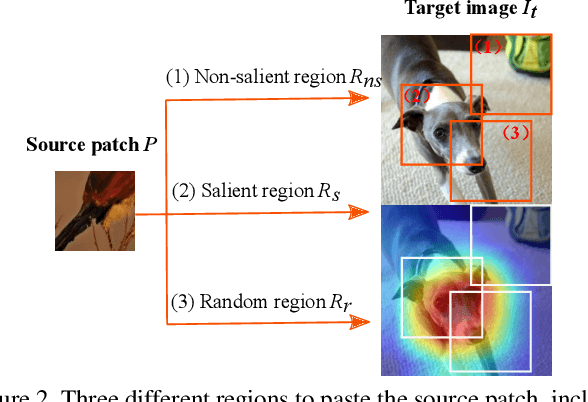
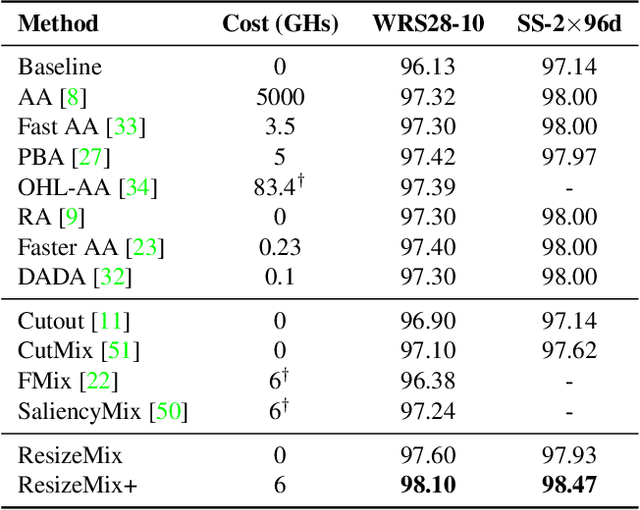
Data augmentation is a powerful technique to increase the diversity of data, which can effectively improve the generalization ability of neural networks in image recognition tasks. Recent data mixing based augmentation strategies have achieved great success. Especially, CutMix uses a simple but effective method to improve the classifiers by randomly cropping a patch from one image and pasting it on another image. To further promote the performance of CutMix, a series of works explore to use the saliency information of the image to guide the mixing. We systematically study the importance of the saliency information for mixing data, and find that the saliency information is not so necessary for promoting the augmentation performance. Furthermore, we find that the cutting based data mixing methods carry two problems of label misallocation and object information missing, which cannot be resolved simultaneously. We propose a more effective but very easily implemented method, namely ResizeMix. We mix the data by directly resizing the source image to a small patch and paste it on another image. The obtained patch preserves more substantial object information compared with conventional cut-based methods. ResizeMix shows evident advantages over CutMix and the saliency-guided methods on both image classification and object detection tasks without additional computation cost, which even outperforms most costly search-based automatic augmentation methods.
Concentration of Data Encoding in Parameterized Quantum Circuits
Jun 16, 2022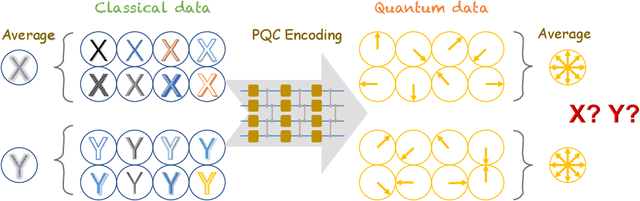

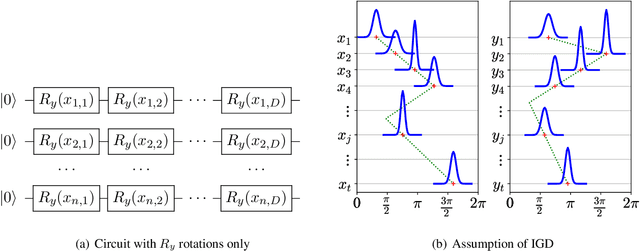
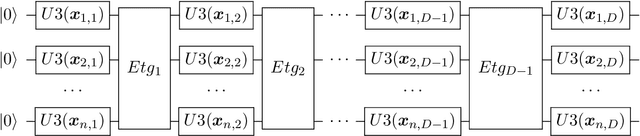
Variational quantum algorithms have been acknowledged as a leading strategy to realize near-term quantum advantages in meaningful tasks, including machine learning and combinatorial optimization. When applied to tasks involving classical data, such algorithms generally begin with quantum circuits for data encoding and then train quantum neural networks (QNNs) to minimize target functions. Although QNNs have been widely studied to improve these algorithms' performance on practical tasks, there is a gap in systematically understanding the influence of data encoding on the eventual performance. In this paper, we make progress in filling this gap by considering the common data encoding strategies based on parameterized quantum circuits. We prove that, under reasonable assumptions, the distance between the average encoded state and the maximally mixed state could be explicitly upper-bounded with respect to the width and depth of the encoding circuit. This result in particular implies that the average encoded state will concentrate on the maximally mixed state at an exponential speed on depth. Such concentration seriously limits the capabilities of quantum classifiers, and strictly restricts the distinguishability of encoded states from a quantum information perspective. We further support our findings by numerically verifying these results on both synthetic and public data sets. Our results highlight the significance of quantum data encoding in machine learning tasks and may shed light on future encoding strategies.