 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInvoice Haystack: Benchmarking Document Retrieval and Visual Question Answering Under Strong Visual Homogeneity
Jun 24, 2026Vision Language Models have achieved near-human performance on single-document Visual Question Answering, yet their effectiveness degrades significantly when retrieving information from large collections of visually homogeneous documents. Existing multi-document benchmarks aggregate diverse document types, creating artificial separation in embedding space that does not reflect enterprise document repositories where thousands of records share identical visual templates. We identify this as embedding collapse and introduce Invoice Haystack, a benchmark with 1,500 anonymized invoice images paired with 200 discriminative question-answer pairs, specifically designed to stress-test retrieval under strong visual homogeneity. Invoice Haystack exhibits a mean pairwise cosine similarity of 0.73, compared to 0.38 (DocHaystack) and 0.31 (InfoHaystack) in existing benchmarks, posing a fundamentally more challenging retrieval problem. Addressing the identified challenge, we propose VL-RAG, a hybrid retrieval-augmented generation framework that jointly leverages text and visual embeddings to harness the complementary strengths of both modalities, followed by a VLM-based verification filter for precise document identification. VL-RAG achieves 60.0\% Recall@1 on Invoice Haystack-500, outperforming existing state-of-the-art method by up to an absolute 13.5 percentage points. It further improves retrieval considerably on DocHaystack-1000 (77.1\% vs.\ 75.2\%) and InfoHaystack-1000 (84.5\% vs.\ 80.0\%), establishing the proposed dual-stream fusion as a consistently superior retrieval strategy across both homogeneous and heterogeneous document collections.
Pixel Wised Lesion Prediction on COVID-19 CT Imagery: A Comparative Analysis of Automated Image Segmentation Architectures
May 19, 2026In recent years, there has been a notable increase in the level of attention that is given to algorithms based on deep learning in the context of medical image segmentation. Nevertheless, the reliability of the field has been hindered due to the absence of a standardized methodology for performance analysis and the utilization of different datasets in previous research. The primary objective of the research is to comprehensively evaluate contemporary segmentation frameworks combined with state-of-the-art pre-trained backbones in order to accurately predict COVID-19 lesions in CT images. Moreover, this evaluation can serve as a point of reference for the segmentation of images in various other imaging scenarios. In order to accomplish this, we integrate four distinct deep learning architectures, namely Unet, PSPNet, Linknet, and FPN, with six pre-trained encoders, including VGG 19, DenseNet 121, Inception ResNet V2, MobileNet V2, SeresNet 101, and EfficientNet B0. This approach enables the development of diverse testing architectures. In the context of image segmentation, our research encompassed both binary and multi-class experimentation. The findings derived from our analysis of three distinct COVID-19 CT segmentation datasets indicate that deep learning architectures yield precise and efficient segmentation outcomes. Significantly, a maximum F1-Score of 98% was attained for binary class segmentation, while multi-class segmentation yielded F1-Scores of 75% and 77% across two separate datasets. The utilization of artificial intelligence and deep learning enhances the diagnostic process for pandemic diseases across multiple dimensions.
A Comprehensive Comparison of Deep Learning Architectures for COVID-19 Classification on CT & X-ray Imagery
May 19, 2026COVID-19 was a significant challenge that led to the loss of numerous lives daily. Not only a certain country was involved in this outbreak, but even the world has suffered because of the coronavirus. Imaging techniques using computed tomography (CT) and X-rays of the lungs are the most useful tools for the COVID-19 or any other pandemic disease screening process. Technology today has revolutionized the world by using artificial intelligence to replace manual processes with automated machines, which enable the system to imitate the human brain by making wise decisions based on experience. Motivated by this, our work proposes to use convolutional neural networks (CNN) based models for designing a computer-aided diagnosis (CAD) system that differentiates between COVID-19 and healthy lung pictures. We used two different sets of X-ray images of the lungs in addition to two different sets of CT scans and the classification is done using a variety of networks that have been pre-trained such as VGG (16, 19), Densenet (121), Resnet (50, 50 V2, 101 V2), Mobile net (V2), Xception Inception (V3, Resnet V2), Efficient net (B0) and Nasnet (Large). On the X-ray and CT image datasets, Resnet and VGG architecture have shown the ability to properly differentiate COVID-19 from normal images, with an average accuracy of 95 to 98 percent respectively. Our acquired results on the classification datasets are competitive and superior to previously reported findings in the literature.
HSFM: Hard-Set-Guided Feature-Space Meta-Learning for Robust Classification under Spurious Correlations
Mar 31, 2026Deep neural networks often rely on spurious features to make predictions, which makes them brittle under distribution shift and on samples where the spurious correlation does not hold (e.g., minority-group examples). Recent studies have shown that, even in such settings, the feature extractor of an Empirical Risk Minimization (ERM)-trained model can learn rich and informative representations, and that much of the failure may be attributed to the classifier head. In particular, retraining a lightweight head while keeping the backbone frozen can substantially improve performance on shifted distributions and minority groups. Motivated by this observation, we propose a bilevel meta-learning method that performs augmentation directly in feature space to improve spurious correlation handling in the classifier head. Our method learns support-side feature edits such that, after a small number of inner-loop updates on the edited features, the classifier achieves lower loss on hard examples and improved worst-group performance. By operating at the backbone output rather than in pixel space or through end-to-end optimization, the method is highly efficient and stable, requiring only a few minutes of training on a single GPU. We further validate our method with CLIP-based visualizations, showing that the learned feature-space updates induce semantically meaningful shifts aligned with spurious attributes.
Altered Thoughts, Altered Actions: Probing Chain-of-Thought Vulnerabilities in VLA Robotic Manipulation
Mar 13, 2026Recent Vision-Language-Action (VLA) models increasingly adopt chain-of-thought (CoT) reasoning, generating a natural-language plan before decoding motor commands. This internal text channel between the reasoning module and the action decoder has received no adversarial scrutiny. We ask: which properties of this intermediate plan does the action decoder actually rely on, and can targeted corruption of the reasoning trace alone -- with all inputs left intact -- degrade a robot's physical task performance? We design a taxonomy of seven text corruptions organized into three attacker tiers (blind noise, mechanical-semantic, and LLM-adaptive) and apply them to a state-of-the-art reasoning VLA across 40 LIBERO tabletop manipulation tasks. Our results reveal a striking asymmetry: substituting object names in the reasoning trace reduces overall success rate by 8.3~percentage points (pp) -- reaching $-$19.3~pp on goal-conditioned tasks and $-$45~pp on individual tasks -- whereas sentence reordering, spatial-direction reversal, token noise, and even a 70B-parameter LLM crafting plausible-but-wrong plans all have negligible impact (within $\pm$4~pp). This asymmetry indicates that the action decoder depends on entity-reference integrity rather than reasoning quality or sequential structure. Notably, a sophisticated LLM-based attacker underperforms simple mechanical object-name substitution, because preserving plausibility inadvertently retains the entity-grounding structure the decoder needs. A cross-architecture control using a non-reasoning VLA confirms the vulnerability is exclusive to reasoning-augmented models, while instruction-level attacks degrade both architectures -- establishing that the internal reasoning trace is a distinct and stealthy threat vector invisible to input-validation defenses.
Leveraging Text-to-Image Generation for Handling Spurious Correlation
Mar 21, 2025Deep neural networks trained with Empirical Risk Minimization (ERM) perform well when both training and test data come from the same domain, but they often fail to generalize to out-of-distribution samples. In image classification, these models may rely on spurious correlations that often exist between labels and irrelevant features of images, making predictions unreliable when those features do not exist. We propose a technique to generate training samples with text-to-image (T2I) diffusion models for addressing the spurious correlation problem. First, we compute the best describing token for the visual features pertaining to the causal components of samples by a textual inversion mechanism. Then, leveraging a language segmentation method and a diffusion model, we generate new samples by combining the causal component with the elements from other classes. We also meticulously prune the generated samples based on the prediction probabilities and attribution scores of the ERM model to ensure their correct composition for our objective. Finally, we retrain the ERM model on our augmented dataset. This process reduces the model's reliance on spurious correlations by learning from carefully crafted samples for in which this correlation does not exist. Our experiments show that across different benchmarks, our technique achieves better worst-group accuracy than the existing state-of-the-art methods.
GO-N3RDet: Geometry Optimized NeRF-enhanced 3D Object Detector
Mar 19, 2025We propose GO-N3RDet, a scene-geometry optimized multi-view 3D object detector enhanced by neural radiance fields. The key to accurate 3D object detection is in effective voxel representation. However, due to occlusion and lack of 3D information, constructing 3D features from multi-view 2D images is challenging. Addressing that, we introduce a unique 3D positional information embedded voxel optimization mechanism to fuse multi-view features. To prioritize neural field reconstruction in object regions, we also devise a double importance sampling scheme for the NeRF branch of our detector. We additionally propose an opacity optimization module for precise voxel opacity prediction by enforcing multi-view consistency constraints. Moreover, to further improve voxel density consistency across multiple perspectives, we incorporate ray distance as a weighting factor to minimize cumulative ray errors. Our unique modules synergetically form an end-to-end neural model that establishes new state-of-the-art in NeRF-based multi-view 3D detection, verified with extensive experiments on ScanNet and ARKITScenes. Code will be available at https://github.com/ZechuanLi/GO-N3RDet.
Suitability of KANs for Computer Vision: A preliminary investigation
Jun 13, 2024Kolmogorov-Arnold Networks (KANs) introduce a paradigm of neural modeling that implements learnable functions on the edges of the networks, diverging from the traditional node-centric activations in neural networks. This work assesses the applicability and efficacy of KANs in visual modeling, focusing on the image recognition task. We mainly analyze the performance and efficiency of different network architectures built using KAN concepts along with conventional building blocks of convolutional and linear layers, enabling a comparative analysis with the conventional models. Our findings are aimed at contributing to understanding the potential of KANs in computer vision, highlighting both their strengths and areas for further research. Our evaluation shows that whereas KAN-based architectures perform in-line with the original claims of KAN paper for performance and model-complexity in the case of simpler vision datasets like MNIST, the advantages seem to diminish even for slightly more complex datasets like CIFAR-10.
Context-based Deep Learning Architecture with Optimal Integration Layer for Image Parsing
Apr 13, 2022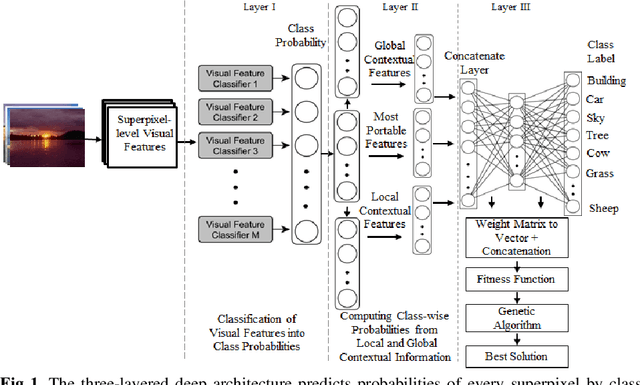
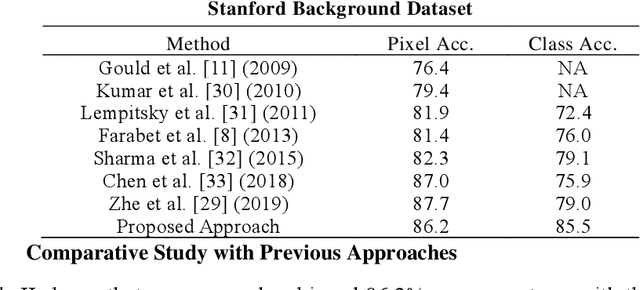
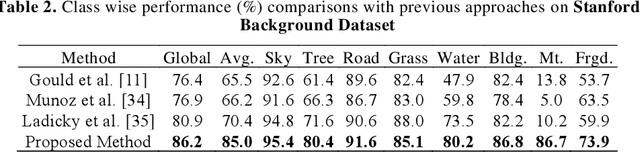
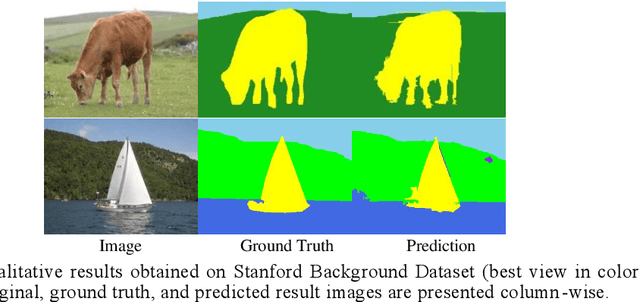
Deep learning models have been efficient lately on image parsing tasks. However, deep learning models are not fully capable of exploiting visual and contextual information simultaneously. The proposed three-layer context-based deep architecture is capable of integrating context explicitly with visual information. The novel idea here is to have a visual layer to learn visual characteristics from binary class-based learners, a contextual layer to learn context, and then an integration layer to learn from both via genetic algorithm-based optimal fusion to produce a final decision. The experimental outcomes when evaluated on benchmark datasets are promising. Further analysis shows that optimized network weights can improve performance and make stable predictions.
Deep Learning Model with GA based Feature Selection and Context Integration
Apr 13, 2022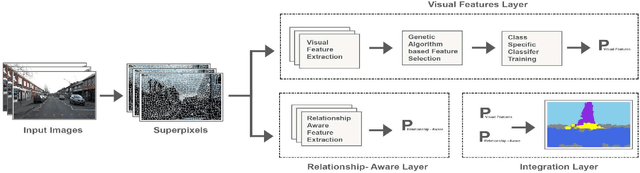
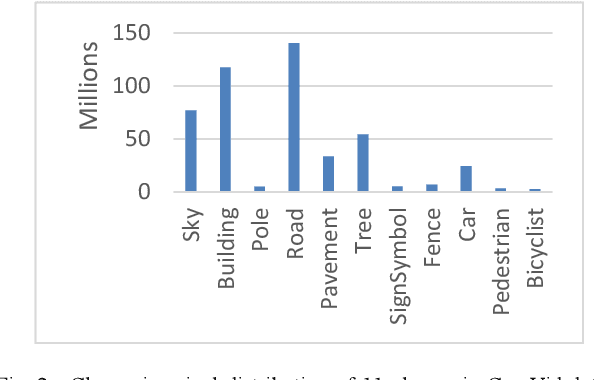
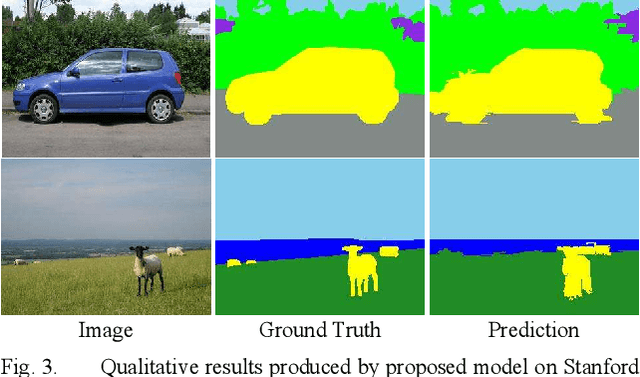

Deep learning models have been very successful in computer vision and image processing applications. Since its inception, Many top-performing methods for image segmentation are based on deep CNN models. However, deep CNN models fail to integrate global and local context alongside visual features despite having complex multi-layer architectures. We propose a novel three-layered deep learning model that assiminlate or learns independently global and local contextual information alongside visual features. The novelty of the proposed model is that One-vs-All binary class-based learners are introduced to learn Genetic Algorithm (GA) optimized features in the visual layer, followed by the contextual layer that learns global and local contexts of an image, and finally the third layer integrates all the information optimally to obtain the final class label. Stanford Background and CamVid benchmark image parsing datasets were used for our model evaluation, and our model shows promising results. The empirical analysis reveals that optimized visual features with global and local contextual information play a significant role to improve accuracy and produce stable predictions comparable to state-of-the-art deep CNN models.