 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Modeling electronic health record data using a knowledge-graph-embedded topic model
Jun 03, 2022
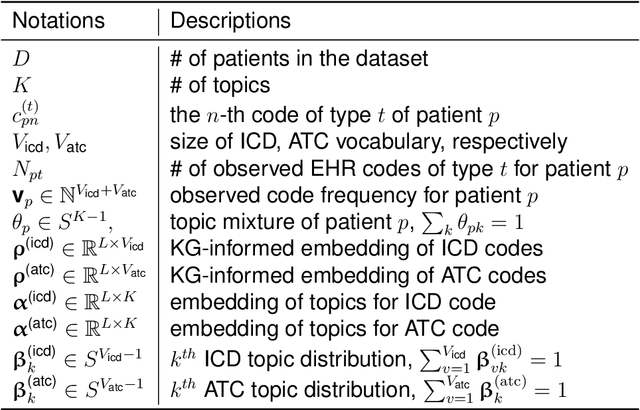

The rapid growth of electronic health record (EHR) datasets opens up promising opportunities to understand human diseases in a systematic way. However, effective extraction of clinical knowledge from the EHR data has been hindered by its sparsity and noisy information. We present KG-ETM, an end-to-end knowledge graph-based multimodal embedded topic model. KG-ETM distills latent disease topics from EHR data by learning the embedding from the medical knowledge graphs. We applied KG-ETM to a large-scale EHR dataset consisting of over 1 million patients. We evaluated its performance based on EHR reconstruction and drug imputation. KG-ETM demonstrated superior performance over the alternative methods on both tasks. Moreover, our model learned clinically meaningful graph-informed embedding of the EHR codes. In additional, our model is also able to discover interpretable and accurate patient representations for patient stratification and drug recommendations.
SSR-GNNs: Stroke-based Sketch Representation with Graph Neural Networks
Apr 27, 2022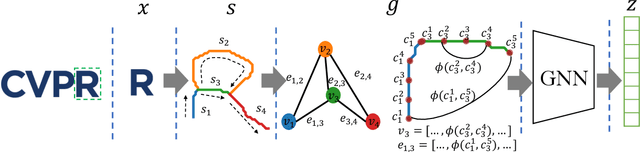
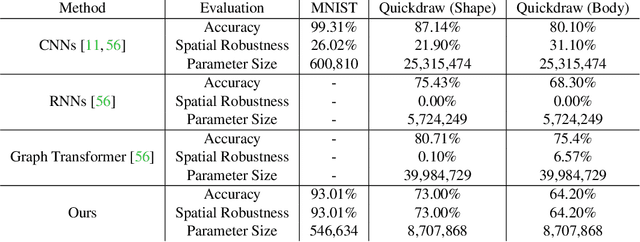
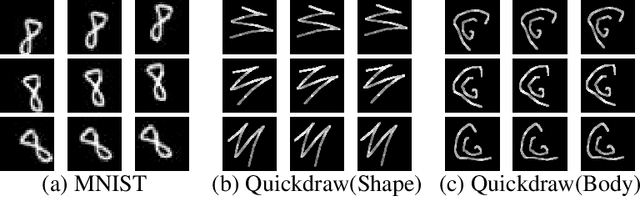
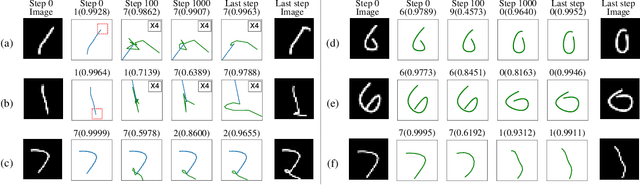
This paper follows cognitive studies to investigate a graph representation for sketches, where the information of strokes, i.e., parts of a sketch, are encoded on vertices and information of inter-stroke on edges. The resultant graph representation facilitates the training of a Graph Neural Networks for classification tasks, and achieves accuracy and robustness comparable to the state-of-the-art against translation and rotation attacks, as well as stronger attacks on graph vertices and topologies, i.e., modifications and addition of strokes, all without resorting to adversarial training. Prior studies on sketches, e.g., graph transformers, encode control points of stroke on vertices, which are not invariant to spatial transformations. In contrary, we encode vertices and edges using pairwise distances among control points to achieve invariance. Compared with existing generative sketch model for one-shot classification, our method does not rely on run-time statistical inference. Lastly, the proposed representation enables generation of novel sketches that are structurally similar to while separable from the existing dataset.
Mixed Attention Transformer for Leveraging Word-Level Knowledge to Neural Cross-Lingual Information Retrieval
Sep 14, 2021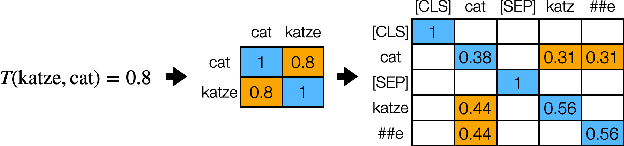

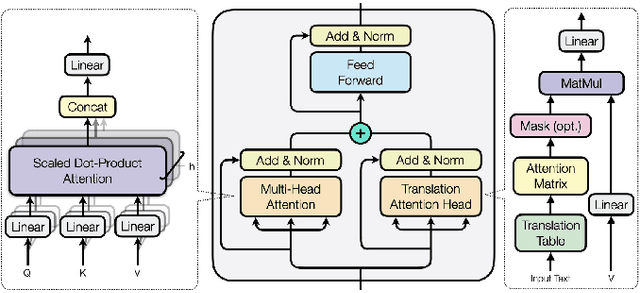
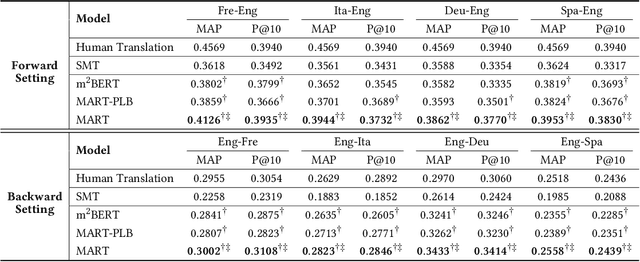
Pretrained contextualized representations offer great success for many downstream tasks, including document ranking. The multilingual versions of such pretrained representations provide a possibility of jointly learning many languages with the same model. Although it is expected to gain big with such joint training, in the case of cross lingual information retrieval (CLIR), the models under a multilingual setting are not achieving the same level of performance as those under a monolingual setting. We hypothesize that the performance drop is due to the translation gap between query and documents. In the monolingual retrieval task, because of the same lexical inputs, it is easier for model to identify the query terms that occurred in documents. However, in the multilingual pretrained models that the words in different languages are projected into the same hyperspace, the model tends to translate query terms into related terms, i.e., terms that appear in a similar context, in addition to or sometimes rather than synonyms in the target language. This property is creating difficulties for the model to connect terms that cooccur in both query and document. To address this issue, we propose a novel Mixed Attention Transformer (MAT) that incorporates external word level knowledge, such as a dictionary or translation table. We design a sandwich like architecture to embed MAT into the recent transformer based deep neural models. By encoding the translation knowledge into an attention matrix, the model with MAT is able to focus on the mutually translated words in the input sequence. Experimental results demonstrate the effectiveness of the external knowledge and the significant improvement of MAT embedded neural reranking model on CLIR task.
On the well-spread property and its relation to linear regression
Jun 16, 2022We consider the robust linear regression model $\boldsymbol{y} = X\beta^* + \boldsymbol{\eta}$, where an adversary oblivious to the design $X \in \mathbb{R}^{n \times d}$ may choose $\boldsymbol{\eta}$ to corrupt all but a (possibly vanishing) fraction of the observations $\boldsymbol{y}$ in an arbitrary way. Recent work [dLN+21, dNS21] has introduced efficient algorithms for consistent recovery of the parameter vector. These algorithms crucially rely on the design matrix being well-spread (a matrix is well-spread if its column span is far from any sparse vector). In this paper, we show that there exists a family of design matrices lacking well-spreadness such that consistent recovery of the parameter vector in the above robust linear regression model is information-theoretically impossible. We further investigate the average-case time complexity of certifying well-spreadness of random matrices. We show that it is possible to efficiently certify whether a given $n$-by-$d$ Gaussian matrix is well-spread if the number of observations is quadratic in the ambient dimension. We complement this result by showing rigorous evidence -- in the form of a lower bound against low-degree polynomials -- of the computational hardness of this same certification problem when the number of observations is $o(d^2)$.
What is Right for Me is Not Yet Right for You: A Dataset for Grounding Relative Directions via Multi-Task Learning
May 05, 2022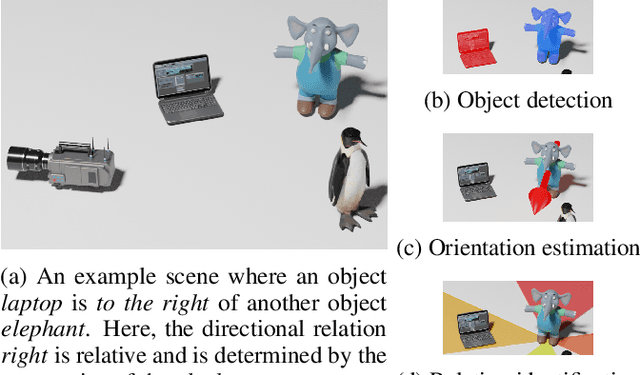


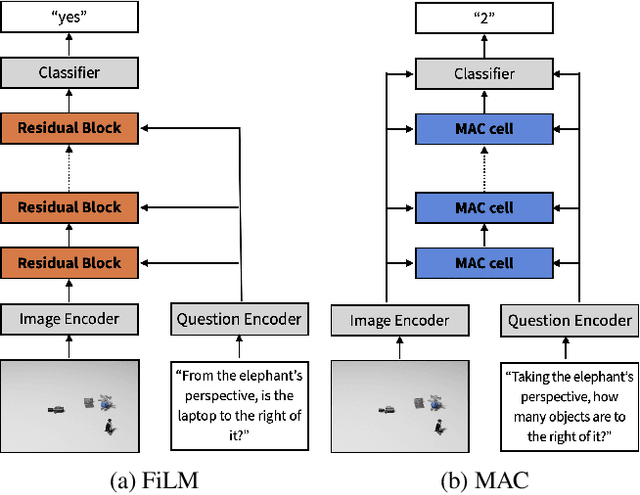
Understanding spatial relations is essential for intelligent agents to act and communicate in the physical world. Relative directions are spatial relations that describe the relative positions of target objects with regard to the intrinsic orientation of reference objects. Grounding relative directions is more difficult than grounding absolute directions because it not only requires a model to detect objects in the image and to identify spatial relation based on this information, but it also needs to recognize the orientation of objects and integrate this information into the reasoning process. We investigate the challenging problem of grounding relative directions with end-to-end neural networks. To this end, we provide GRiD-3D, a novel dataset that features relative directions and complements existing visual question answering (VQA) datasets, such as CLEVR, that involve only absolute directions. We also provide baselines for the dataset with two established end-to-end VQA models. Experimental evaluations show that answering questions on relative directions is feasible when questions in the dataset simulate the necessary subtasks for grounding relative directions. We discover that those subtasks are learned in an order that reflects the steps of an intuitive pipeline for processing relative directions.
Information-theoretic Evolution of Model Agnostic Global Explanations
May 14, 2021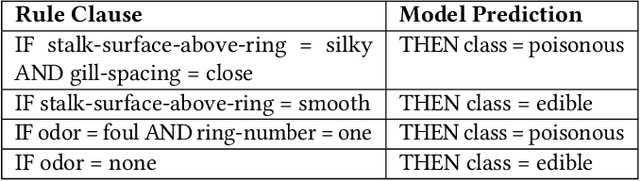
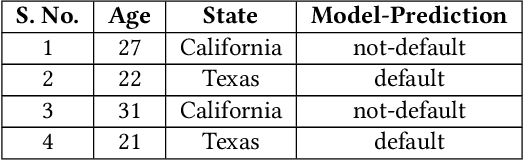
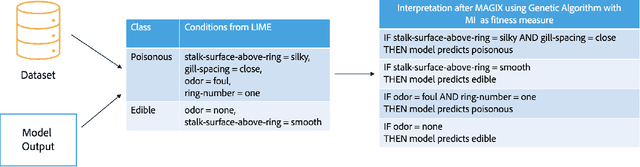
Explaining the behavior of black box machine learning models through human interpretable rules is an important research area. Recent work has focused on explaining model behavior locally i.e. for specific predictions as well as globally across the fields of vision, natural language, reinforcement learning and data science. We present a novel model-agnostic approach that derives rules to globally explain the behavior of classification models trained on numerical and/or categorical data. Our approach builds on top of existing local model explanation methods to extract conditions important for explaining model behavior for specific instances followed by an evolutionary algorithm that optimizes an information theory based fitness function to construct rules that explain global model behavior. We show how our approach outperforms existing approaches on a variety of datasets. Further, we introduce a parameter to evaluate the quality of interpretation under the scenario of distributional shift. This parameter evaluates how well the interpretation can predict model behavior for previously unseen data distributions. We show how existing approaches for interpreting models globally lack distributional robustness. Finally, we show how the quality of the interpretation can be improved under the scenario of distributional shift by adding out of distribution samples to the dataset used to learn the interpretation and thereby, increase robustness. All of the datasets used in our paper are open and publicly available. Our approach has been deployed in a leading digital marketing suite of products.
How Asynchronous Events Encode Video
Jun 09, 2022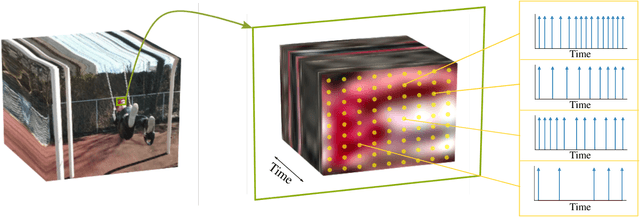
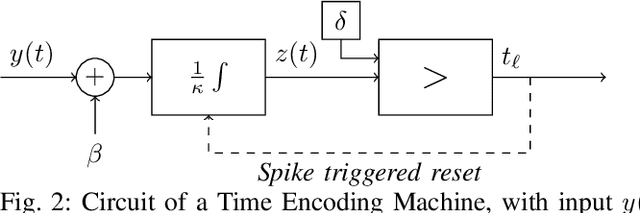
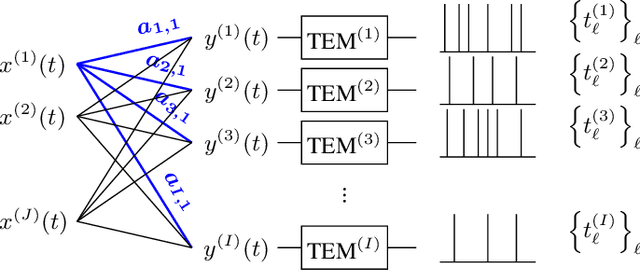
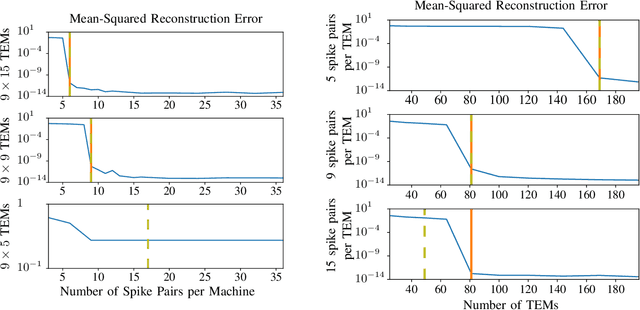
As event-based sensing gains in popularity, theoretical understanding is needed to harness this technology's potential. Instead of recording video by capturing frames, event-based cameras have sensors that emit events when their inputs change, thus encoding information in the timing of events. This creates new challenges in establishing reconstruction guarantees and algorithms, but also provides advantages over frame-based video. We use time encoding machines to model event-based sensors: TEMs also encode their inputs by emitting events characterized by their timing and reconstruction from time encodings is well understood. We consider the case of time encoding bandlimited video and demonstrate a dependence between spatial sensor density and overall spatial and temporal resolution. Such a dependence does not occur in frame-based video, where temporal resolution depends solely on the frame rate of the video and spatial resolution depends solely on the pixel grid. However, this dependence arises naturally in event-based video and allows oversampling in space to provide better time resolution. As such, event-based vision encourages using more sensors that emit fewer events over time.
* 6 pages, 4 figures
AMOS: A Large-Scale Abdominal Multi-Organ Benchmark for Versatile Medical Image Segmentation
Jun 16, 2022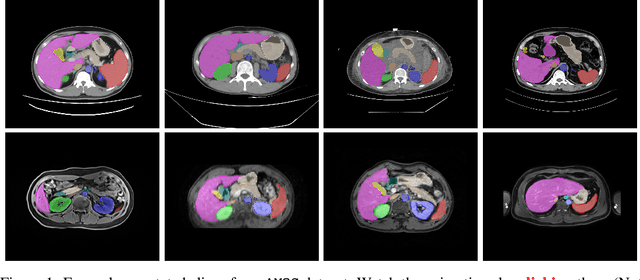
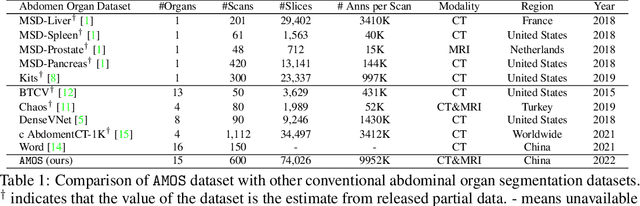
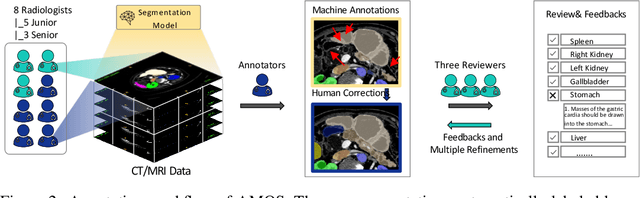
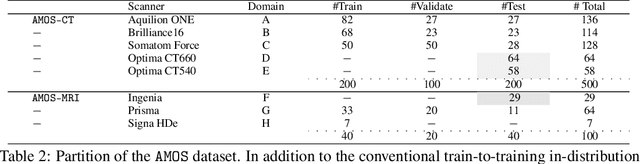
Despite the considerable progress in automatic abdominal multi-organ segmentation from CT/MRI scans in recent years, a comprehensive evaluation of the models' capabilities is hampered by the lack of a large-scale benchmark from diverse clinical scenarios. Constraint by the high cost of collecting and labeling 3D medical data, most of the deep learning models to date are driven by datasets with a limited number of organs of interest or samples, which still limits the power of modern deep models and makes it difficult to provide a fully comprehensive and fair estimate of various methods. To mitigate the limitations, we present AMOS, a large-scale, diverse, clinical dataset for abdominal organ segmentation. AMOS provides 500 CT and 100 MRI scans collected from multi-center, multi-vendor, multi-modality, multi-phase, multi-disease patients, each with voxel-level annotations of 15 abdominal organs, providing challenging examples and test-bed for studying robust segmentation algorithms under diverse targets and scenarios. We further benchmark several state-of-the-art medical segmentation models to evaluate the status of the existing methods on this new challenging dataset. We have made our datasets, benchmark servers, and baselines publicly available, and hope to inspire future research. Information can be found at https://amos22.grand-challenge.org.
A Novel Data-Driven Method for the Analysis and Reconstruction of Cardiac Cine MRI
May 24, 2022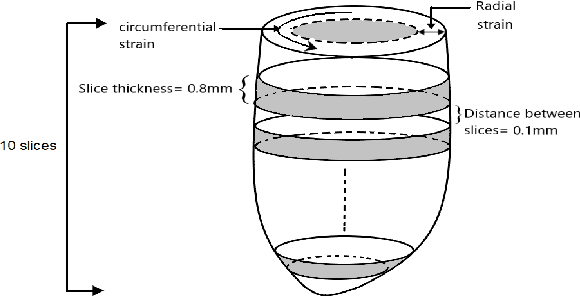
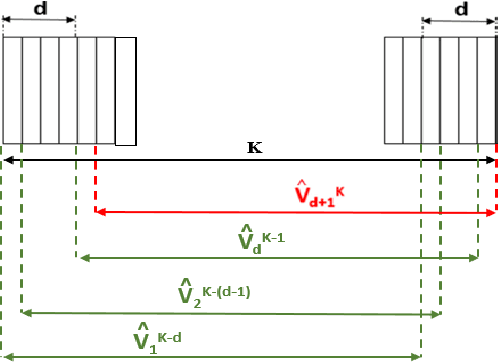
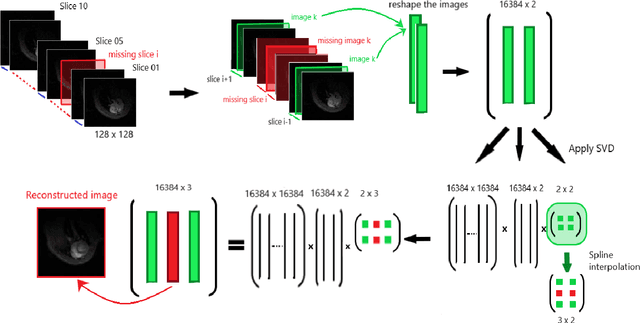
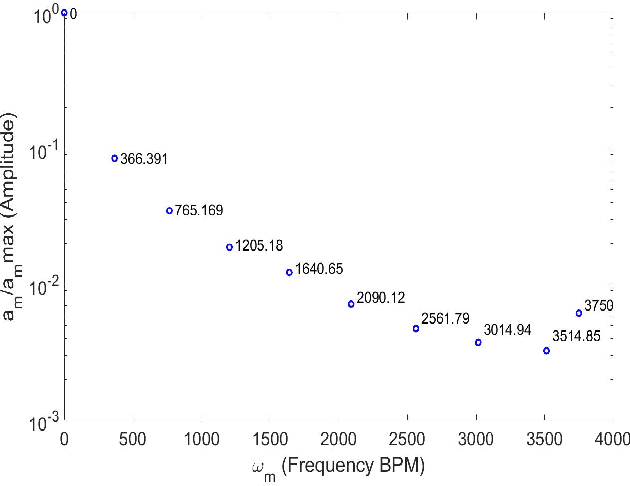
Cardiac cine magnetic resonance imaging (MRI) can be considered the optimal criterion for measuring cardiac function. This imaging technique can provide us with detailed information about cardiac structure, tissue composition and even blood flow. This work considers the application of the higher order dynamic mode decomposition (HODMD) method to a set of MR images of a heart, with the ultimate goal of identifying the main patterns and frequencies driving the heart dynamics. A novel algorithm based on singular value decomposition combined with HODMD is introduced, providing a three-dimensional reconstruction of the heart. This algorithm is applied (i) to reconstruct corrupted or missing images, and (ii) to build a reduced order model of the heart dynamics.
Integrating 2D and 3D Digital Plant Information Towards Automatic Generation of Digital Twins
Apr 05, 2021
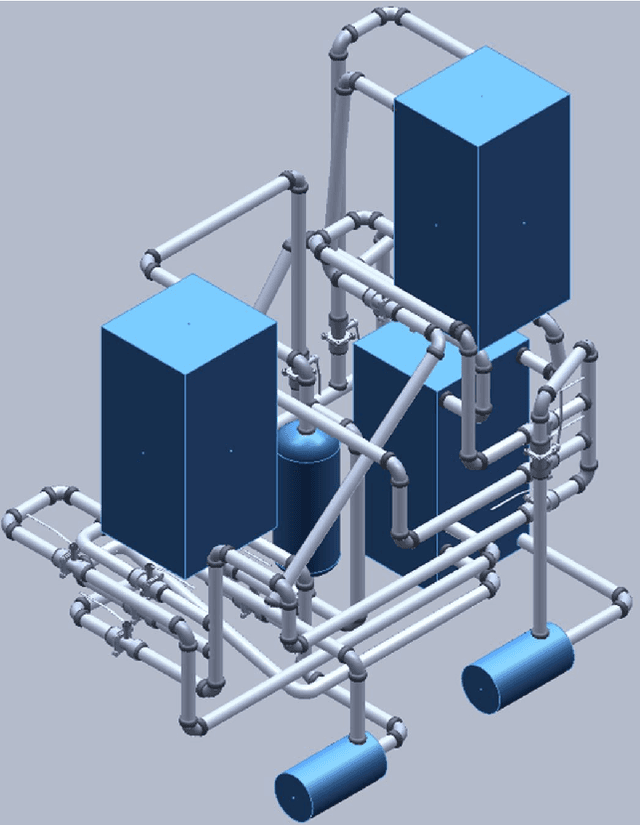
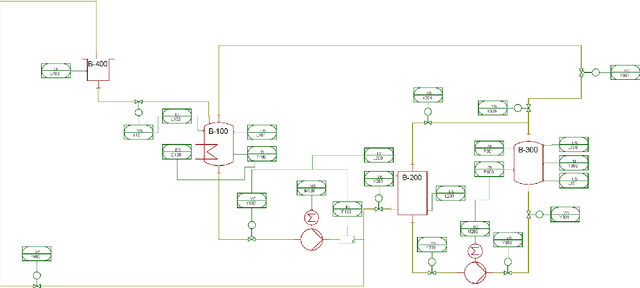
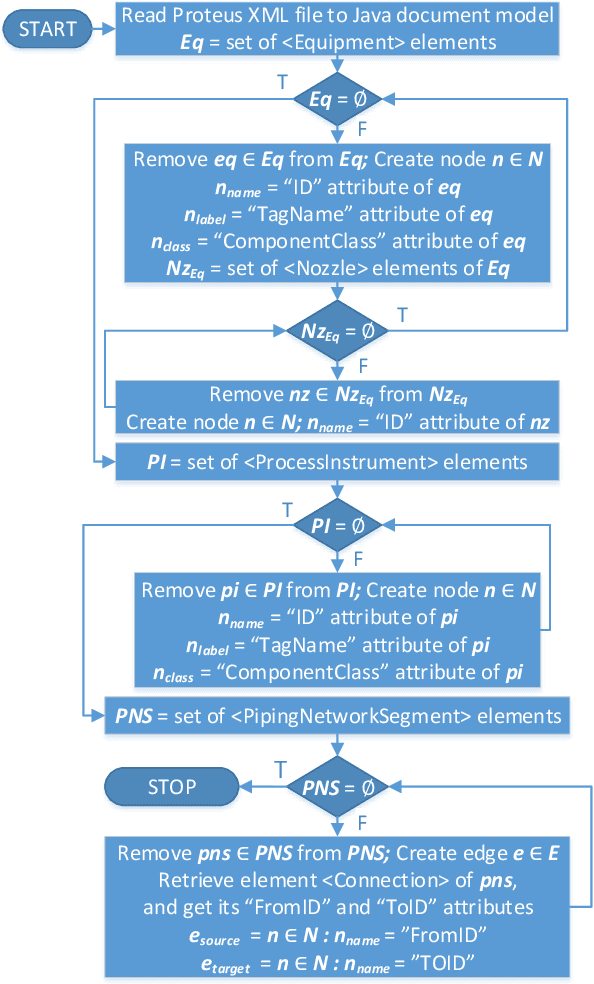
Ongoing standardization in Industry 4.0 supports tool vendor neutral representations of Piping and Instrumentation diagrams as well as 3D pipe routing. However, a complete digital plant model requires combining these two representations. 3D pipe routing information is essential for building any accurate first-principles process simulation model. Piping and instrumentation diagrams are the primary source for control loops. In order to automatically integrate these information sources to a unified digital plant model, it is necessary to develop algorithms for identifying corresponding elements such as tanks and pumps from piping and instrumentation diagrams and 3D CAD models. One approach is to raise these two information sources to a common level of abstraction and to match them at this level of abstraction. Graph matching is a potential technique for this purpose. This article focuses on automatic generation of the graphs as a prerequisite to graph matching. Algorithms for this purpose are proposed and validated with a case study. The paper concludes with a discussion of further research needed to reprocess the generated graphs in order to enable effective matching.