 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHallucination Detection and Mitigation in Large Language Models
Jan 14, 2026Large Language Models (LLMs) and Large Reasoning Models (LRMs) offer transformative potential for high-stakes domains like finance and law, but their tendency to hallucinate, generating factually incorrect or unsupported content, poses a critical reliability risk. This paper introduces a comprehensive operational framework for hallucination management, built on a continuous improvement cycle driven by root cause awareness. We categorize hallucination sources into model, data, and context-related factors, allowing targeted interventions over generic fixes. The framework integrates multi-faceted detection methods (e.g., uncertainty estimation, reasoning consistency) with stratified mitigation strategies (e.g., knowledge grounding, confidence calibration). We demonstrate its application through a tiered architecture and a financial data extraction case study, where model, context, and data tiers form a closed feedback loop for progressive reliability enhancement. This approach provides a systematic, scalable methodology for building trustworthy generative AI systems in regulated environments.
Modeling electronic health record data using a knowledge-graph-embedded topic model
Jun 03, 2022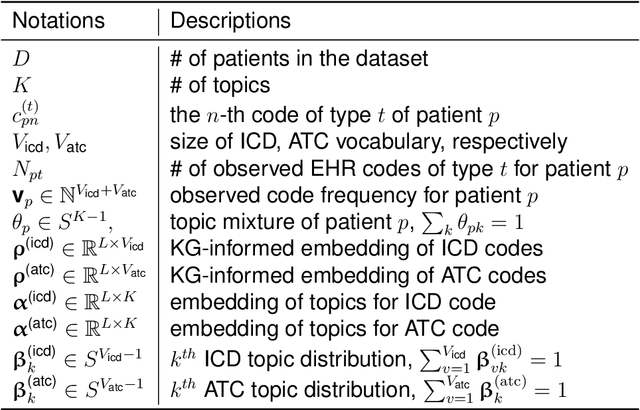

The rapid growth of electronic health record (EHR) datasets opens up promising opportunities to understand human diseases in a systematic way. However, effective extraction of clinical knowledge from the EHR data has been hindered by its sparsity and noisy information. We present KG-ETM, an end-to-end knowledge graph-based multimodal embedded topic model. KG-ETM distills latent disease topics from EHR data by learning the embedding from the medical knowledge graphs. We applied KG-ETM to a large-scale EHR dataset consisting of over 1 million patients. We evaluated its performance based on EHR reconstruction and drug imputation. KG-ETM demonstrated superior performance over the alternative methods on both tasks. Moreover, our model learned clinically meaningful graph-informed embedding of the EHR codes. In additional, our model is also able to discover interpretable and accurate patient representations for patient stratification and drug recommendations.
CT-SGAN: Computed Tomography Synthesis GAN
Nov 04, 2021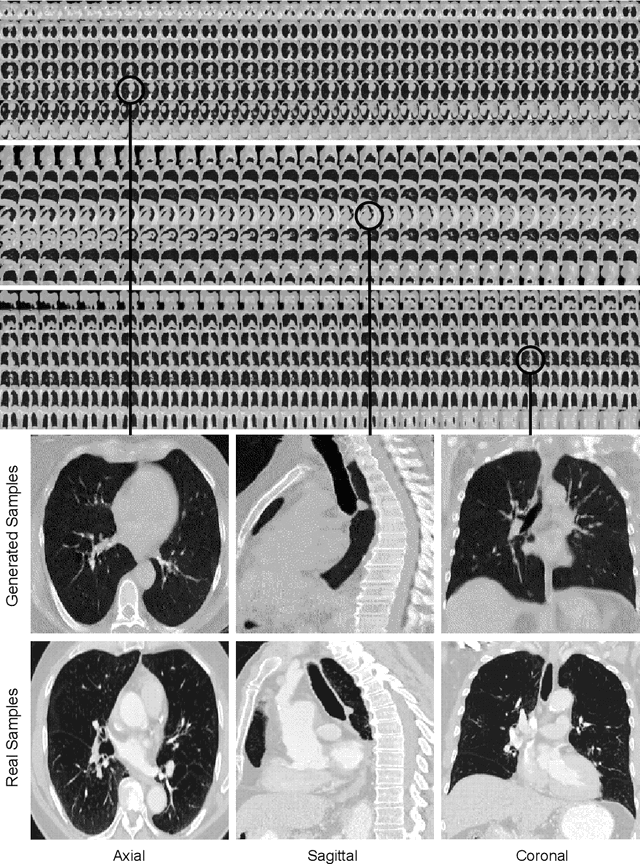

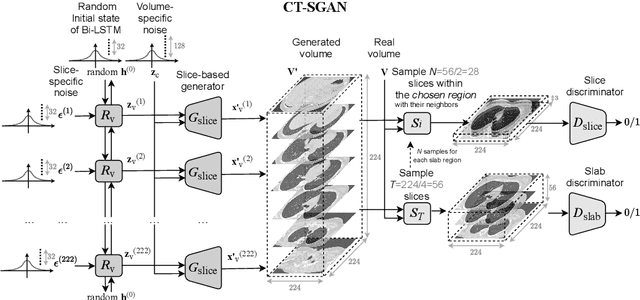
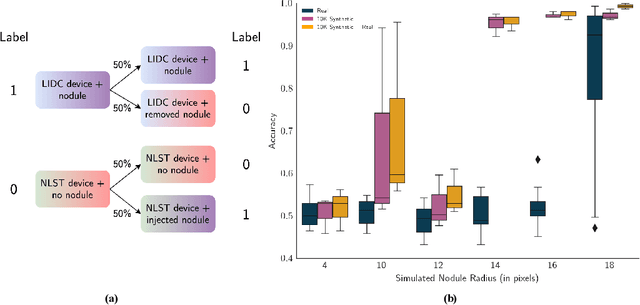
Diversity in data is critical for the successful training of deep learning models. Leveraged by a recurrent generative adversarial network, we propose the CT-SGAN model that generates large-scale 3D synthetic CT-scan volumes ($\geq 224\times224\times224$) when trained on a small dataset of chest CT-scans. CT-SGAN offers an attractive solution to two major challenges facing machine learning in medical imaging: a small number of given i.i.d. training data, and the restrictions around the sharing of patient data preventing to rapidly obtain larger and more diverse datasets. We evaluate the fidelity of the generated images qualitatively and quantitatively using various metrics including Fr\'echet Inception Distance and Inception Score. We further show that CT-SGAN can significantly improve lung nodule detection accuracy by pre-training a classifier on a vast amount of synthetic data.
Dual Adversarial Inference for Text-to-Image Synthesis
Aug 14, 2019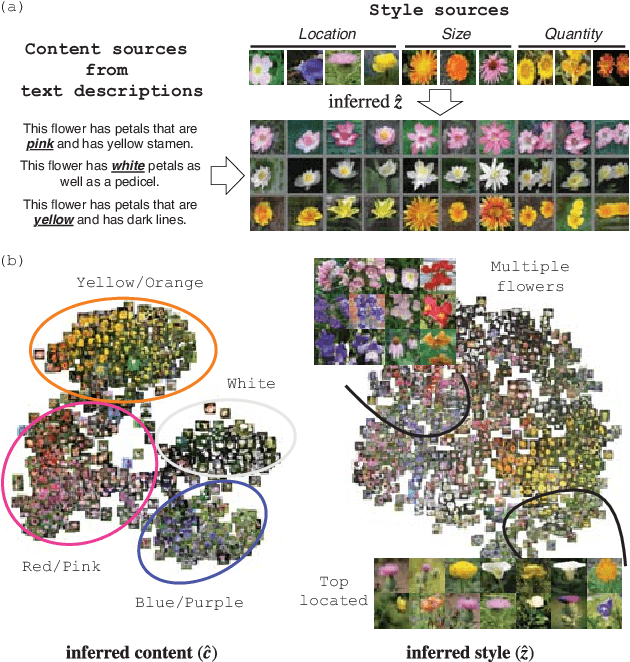
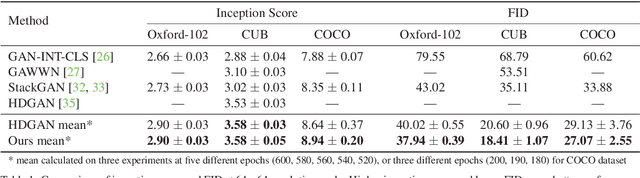
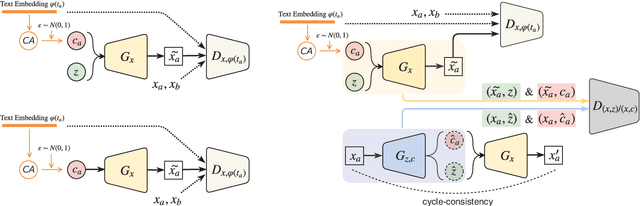
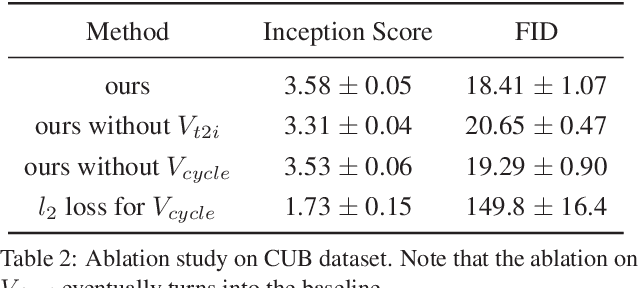
Synthesizing images from a given text description involves engaging two types of information: the content, which includes information explicitly described in the text (e.g., color, composition, etc.), and the style, which is usually not well described in the text (e.g., location, quantity, size, etc.). However, in previous works, it is typically treated as a process of generating images only from the content, i.e., without considering learning meaningful style representations. In this paper, we aim to learn two variables that are disentangled in the latent space, representing content and style respectively. We achieve this by augmenting current text-to-image synthesis frameworks with a dual adversarial inference mechanism. Through extensive experiments, we show that our model learns, in an unsupervised manner, style representations corresponding to certain meaningful information present in the image that are not well described in the text. The new framework also improves the quality of synthesized images when evaluated on Oxford-102, CUB and COCO datasets.
One Single Deep Bidirectional LSTM Network for Word Sense Disambiguation of Text Data
Feb 25, 2018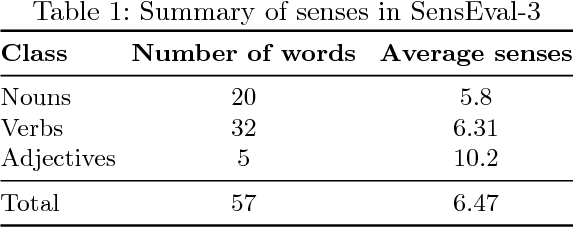
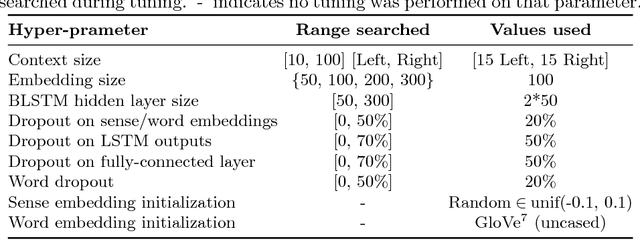
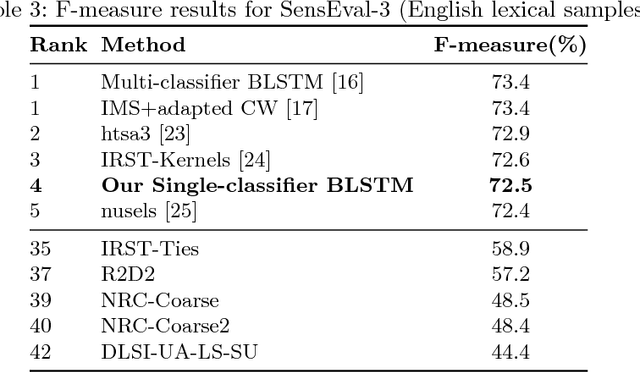

Due to recent technical and scientific advances, we have a wealth of information hidden in unstructured text data such as offline/online narratives, research articles, and clinical reports. To mine these data properly, attributable to their innate ambiguity, a Word Sense Disambiguation (WSD) algorithm can avoid numbers of difficulties in Natural Language Processing (NLP) pipeline. However, considering a large number of ambiguous words in one language or technical domain, we may encounter limiting constraints for proper deployment of existing WSD models. This paper attempts to address the problem of one-classifier-per-one-word WSD algorithms by proposing a single Bidirectional Long Short-Term Memory (BLSTM) network which by considering senses and context sequences works on all ambiguous words collectively. Evaluated on SensEval-3 benchmark, we show the result of our model is comparable with top-performing WSD algorithms. We also discuss how applying additional modifications alleviates the model fault and the need for more training data.
TrajectoryNet: An Embedded GPS Trajectory Representation for Point-based Classification Using Recurrent Neural Networks
Aug 30, 2017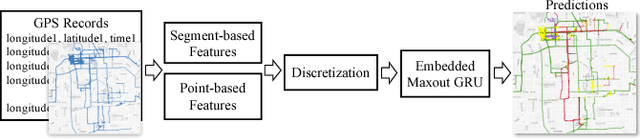

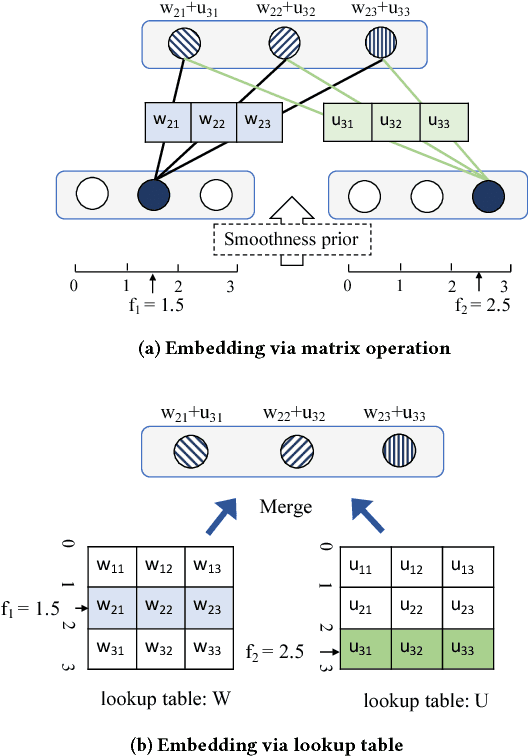
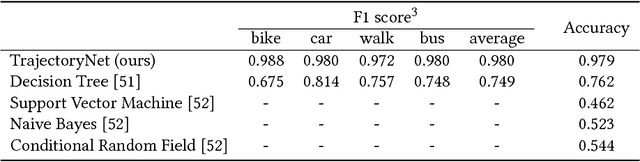
Understanding and discovering knowledge from GPS (Global Positioning System) traces of human activities is an essential topic in mobility-based urban computing. We propose TrajectoryNet-a neural network architecture for point-based trajectory classification to infer real world human transportation modes from GPS traces. To overcome the challenge of capturing the underlying latent factors in the low-dimensional and heterogeneous feature space imposed by GPS data, we develop a novel representation that embeds the original feature space into another space that can be understood as a form of basis expansion. We also enrich the feature space via segment-based information and use Maxout activations to improve the predictive power of Recurrent Neural Networks (RNNs). We achieve over 98% classification accuracy when detecting four types of transportation modes, outperforming existing models without additional sensory data or location-based prior knowledge.