 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Disentangled Graph Variational Auto-Encoder for Multimodal Recommendation with Interpretability
Feb 25, 2024
Multimodal recommender systems amalgamate multimodal information (e.g., textual descriptions, images) into a collaborative filtering framework to provide more accurate recommendations. While the incorporation of multimodal information could enhance the interpretability of these systems, current multimodal models represent users and items utilizing entangled numerical vectors, rendering them arduous to interpret. To address this, we propose a Disentangled Graph Variational Auto-Encoder (DGVAE) that aims to enhance both model and recommendation interpretability. DGVAE initially projects multimodal information into textual contents, such as converting images to text, by harnessing state-of-the-art multimodal pre-training technologies. It then constructs a frozen item-item graph and encodes the contents and interactions into two sets of disentangled representations utilizing a simplified residual graph convolutional network. DGVAE further regularizes these disentangled representations through mutual information maximization, aligning the representations derived from the interactions between users and items with those learned from textual content. This alignment facilitates the interpretation of user binary interactions via text. Our empirical analysis conducted on three real-world datasets demonstrates that DGVAE significantly surpasses the performance of state-of-the-art baselines by a margin of 10.02%. We also furnish a case study from a real-world dataset to illustrate the interpretability of DGVAE. Code is available at: \url{https://github.com/enoche/DGVAE}.
Optimal Zero-Shot Detector for Multi-Armed Attacks
Feb 27, 2024This paper explores a scenario in which a malicious actor employs a multi-armed attack strategy to manipulate data samples, offering them various avenues to introduce noise into the dataset. Our central objective is to protect the data by detecting any alterations to the input. We approach this defensive strategy with utmost caution, operating in an environment where the defender possesses significantly less information compared to the attacker. Specifically, the defender is unable to utilize any data samples for training a defense model or verifying the integrity of the channel. Instead, the defender relies exclusively on a set of pre-existing detectors readily available "off the shelf". To tackle this challenge, we derive an innovative information-theoretic defense approach that optimally aggregates the decisions made by these detectors, eliminating the need for any training data. We further explore a practical use-case scenario for empirical evaluation, where the attacker possesses a pre-trained classifier and launches well-known adversarial attacks against it. Our experiments highlight the effectiveness of our proposed solution, even in scenarios that deviate from the optimal setup.
Speak Out of Turn: Safety Vulnerability of Large Language Models in Multi-turn Dialogue
Feb 27, 2024Large Language Models (LLMs) have been demonstrated to generate illegal or unethical responses, particularly when subjected to "jailbreak." Research on jailbreak has highlighted the safety issues of LLMs. However, prior studies have predominantly focused on single-turn dialogue, ignoring the potential complexities and risks presented by multi-turn dialogue, a crucial mode through which humans derive information from LLMs. In this paper, we argue that humans could exploit multi-turn dialogue to induce LLMs into generating harmful information. LLMs may not intend to reject cautionary or borderline unsafe queries, even if each turn is closely served for one malicious purpose in a multi-turn dialogue. Therefore, by decomposing an unsafe query into several sub-queries for multi-turn dialogue, we induced LLMs to answer harmful sub-questions incrementally, culminating in an overall harmful response. Our experiments, conducted across a wide range of LLMs, indicate current inadequacies in the safety mechanisms of LLMs in multi-turn dialogue. Our findings expose vulnerabilities of LLMs in complex scenarios involving multi-turn dialogue, presenting new challenges for the safety of LLMs.
Dual Graph Attention based Disentanglement Multiple Instance Learning for Brain Age Estimation
Mar 02, 2024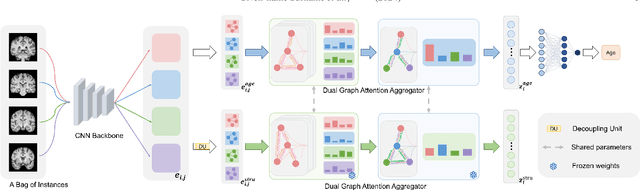

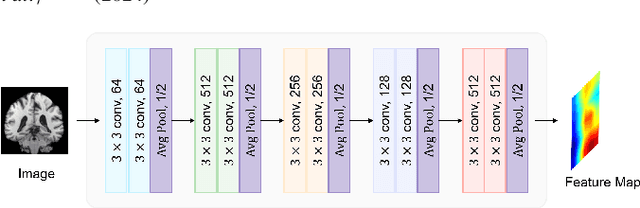
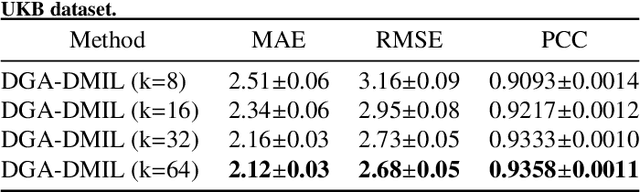
Deep learning techniques have demonstrated great potential for accurately estimating brain age by analyzing Magnetic Resonance Imaging (MRI) data from healthy individuals. However, current methods for brain age estimation often directly utilize whole input images, overlooking two important considerations: 1) the heterogeneous nature of brain aging, where different brain regions may degenerate at different rates, and 2) the existence of age-independent redundancies in brain structure. To overcome these limitations, we propose a Dual Graph Attention based Disentanglement Multi-instance Learning (DGA-DMIL) framework for improving brain age estimation. Specifically, the 3D MRI data, treated as a bag of instances, is fed into a 2D convolutional neural network backbone, to capture the unique aging patterns in MRI. A dual graph attention aggregator is then proposed to learn the backbone features by exploiting the intra- and inter-instance relationships. Furthermore, a disentanglement branch is introduced to separate age-related features from age-independent structural representations to ameliorate the interference of redundant information on age prediction. To verify the effectiveness of the proposed framework, we evaluate it on two datasets, UK Biobank and ADNI, containing a total of 35,388 healthy individuals. Our proposed model demonstrates exceptional accuracy in estimating brain age, achieving a remarkable mean absolute error of 2.12 years in the UK Biobank. The results establish our approach as state-of-the-art compared to other competing brain age estimation models. In addition, the instance contribution scores identify the varied importance of brain areas for aging prediction, which provides deeper insights into the understanding of brain aging.
Auxiliary Tasks Enhanced Dual-affinity Learning for Weakly Supervised Semantic Segmentation
Mar 02, 2024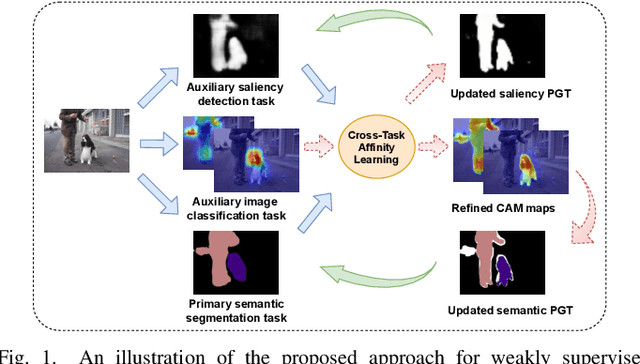
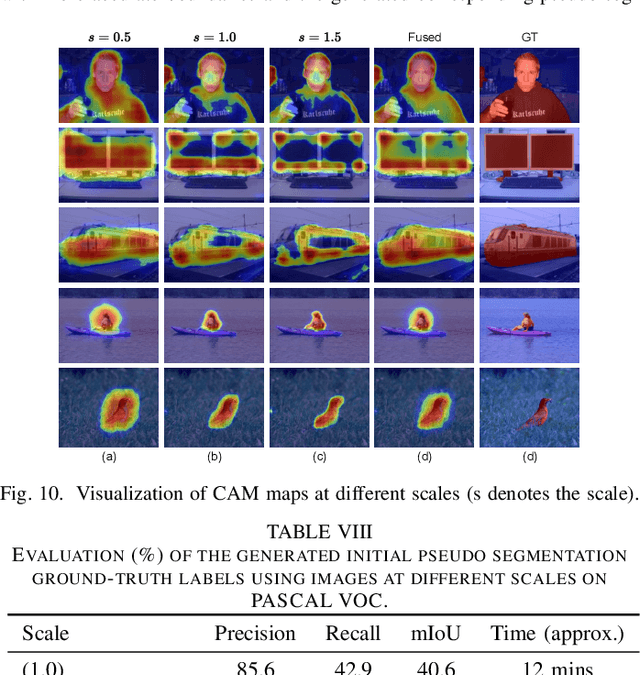

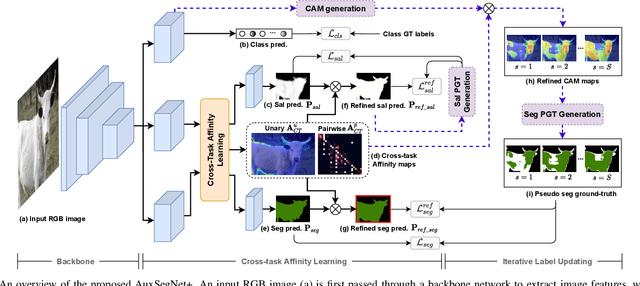
Most existing weakly supervised semantic segmentation (WSSS) methods rely on Class Activation Mapping (CAM) to extract coarse class-specific localization maps using image-level labels. Prior works have commonly used an off-line heuristic thresholding process that combines the CAM maps with off-the-shelf saliency maps produced by a general pre-trained saliency model to produce more accurate pseudo-segmentation labels. We propose AuxSegNet+, a weakly supervised auxiliary learning framework to explore the rich information from these saliency maps and the significant inter-task correlation between saliency detection and semantic segmentation. In the proposed AuxSegNet+, saliency detection and multi-label image classification are used as auxiliary tasks to improve the primary task of semantic segmentation with only image-level ground-truth labels. We also propose a cross-task affinity learning mechanism to learn pixel-level affinities from the saliency and segmentation feature maps. In particular, we propose a cross-task dual-affinity learning module to learn both pairwise and unary affinities, which are used to enhance the task-specific features and predictions by aggregating both query-dependent and query-independent global context for both saliency detection and semantic segmentation. The learned cross-task pairwise affinity can also be used to refine and propagate CAM maps to provide better pseudo labels for both tasks. Iterative improvement of segmentation performance is enabled by cross-task affinity learning and pseudo-label updating. Extensive experiments demonstrate the effectiveness of the proposed approach with new state-of-the-art WSSS results on the challenging PASCAL VOC and MS COCO benchmarks.
A Simple but Effective Approach to Improve Structured Language Model Output for Information Extraction
Feb 20, 2024Large language models (LLMs) have demonstrated impressive abilities in generating unstructured natural language according to instructions. However, their performance can be inconsistent when tasked with producing text that adheres to specific structured formats, which is crucial in applications like named entity recognition (NER) or relation extraction (RE). To address this issue, this paper introduces an efficient method, G&O, to enhance their structured text generation capabilities. It breaks the generation into a two-step pipeline: initially, LLMs generate answers in natural language as intermediate responses. Subsequently, LLMs are asked to organize the output into the desired structure, using the intermediate responses as context. G&O effectively separates the generation of content from the structuring process, reducing the pressure of completing two orthogonal tasks simultaneously. Tested on zero-shot NER and RE, the results indicate a significant improvement in LLM performance with minimal additional efforts. This straightforward and adaptable prompting technique can also be combined with other strategies, like self-consistency, to further elevate LLM capabilities in various structured text generation tasks.
Channel Measurements and Modeling for Dynamic Vehicular ISAC Scenarios at 28 GHz
Mar 01, 2024Integrated sensing and communication (ISAC) is a promising technology for 6G, with the goal of providing end-to-end information processing and inherent perception capabilities for future communication systems. Within ISAC emerging application scenarios, vehicular ISAC technologies have the potential to enhance traffic efficiency and safety through integration of communication and synchronized perception abilities. To establish a foundational theoretical support for vehicular ISAC system design and standardization, it is necessary to conduct channel measurements, and modeling to obtain a deep understanding of the radio propagation. In this paper, a dynamic statistical channel model is proposed for vehicular ISAC scenarios, incorporating Sensing Multipath Components (S-MPCs) and Clutter Multipath Components (C-MPCs), which are identified by the proposed tracking algorithm. Based on actual vehicular ISAC channel measurements at 28 GHz, time-varying sensing characteristics in front, left, and right directions are investigated. To model the dynamic evolution process of channel, number of new S-MPCs, lifetimes, initial power and delay positions, dynamic variations within their lifetimes, clustering, power decay, and fading of C-MPCs are statistically characterized. Finally, the paper provides implementation of dynamic vehicular ISAC model and validates it by comparing key simulation statistics between measurements and simulations.
A Semantic Distance Metric Learning approach for Lexical Semantic Change Detection
Mar 01, 2024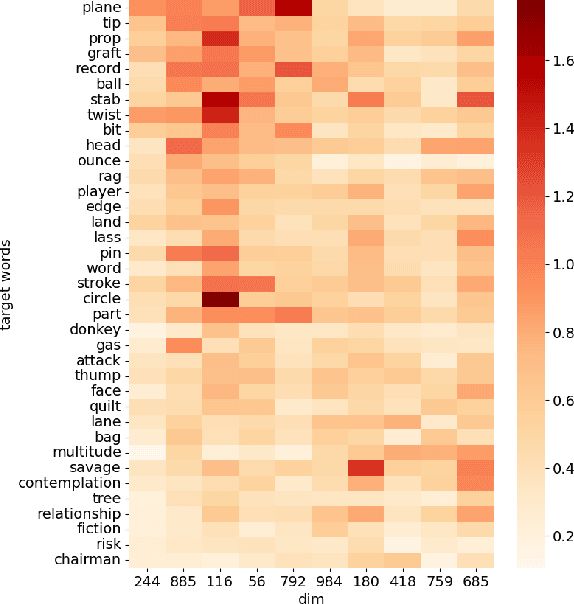
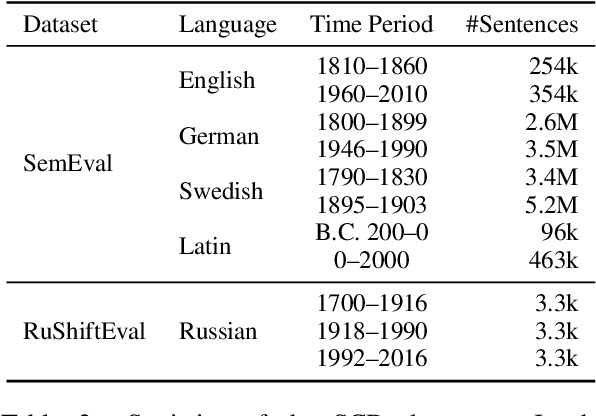
Detecting temporal semantic changes of words is an important task for various NLP applications that must make time-sensitive predictions. Lexical Semantic Change Detection (SCD) task considers the problem of predicting whether a given target word, $w$, changes its meaning between two different text corpora, $C_1$ and $C_2$. For this purpose, we propose a supervised two-staged SCD method that uses existing Word-in-Context (WiC) datasets. In the first stage, for a target word $w$, we learn two sense-aware encoder that represents the meaning of $w$ in a given sentence selected from a corpus. Next, in the second stage, we learn a sense-aware distance metric that compares the semantic representations of a target word across all of its occurrences in $C_1$ and $C_2$. Experimental results on multiple benchmark datasets for SCD show that our proposed method consistently outperforms all previously proposed SCD methods for multiple languages, establishing a novel state-of-the-art for SCD. Interestingly, our findings imply that there are specialised dimensions that carry information related to semantic changes of words in the sense-aware embedding space. Source code is available at https://github.com/a1da4/svp-sdml .
Formulation Comparison for Timeline Construction using LLMs
Mar 01, 2024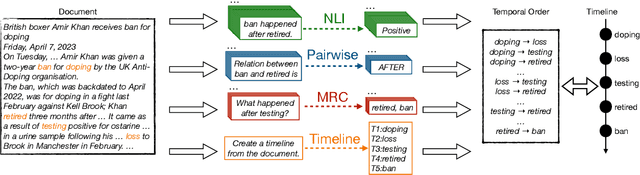

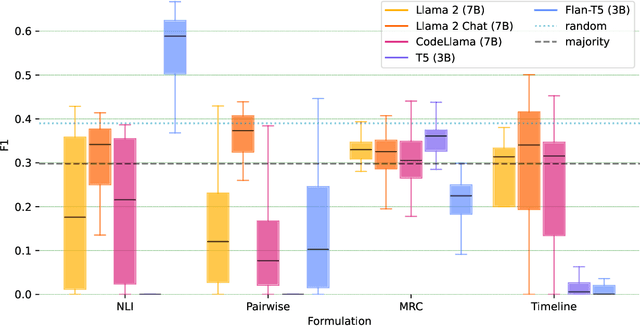
Constructing a timeline requires identifying the chronological order of events in an article. In prior timeline construction datasets, temporal orders are typically annotated by either event-to-time anchoring or event-to-event pairwise ordering, both of which suffer from missing temporal information. To mitigate the issue, we develop a new evaluation dataset, TimeSET, consisting of single-document timelines with document-level order annotation. TimeSET features saliency-based event selection and partial ordering, which enable a practical annotation workload. Aiming to build better automatic timeline construction systems, we propose a novel evaluation framework to compare multiple task formulations with TimeSET by prompting open LLMs, i.e., Llama 2 and Flan-T5. Considering that identifying temporal orders of events is a core subtask in timeline construction, we further benchmark open LLMs on existing event temporal ordering datasets to gain a robust understanding of their capabilities. Our experiments show that (1) NLI formulation with Flan-T5 demonstrates a strong performance among others, while (2) timeline construction and event temporal ordering are still challenging tasks for few-shot LLMs. Our code and data are available at https://github.com/kimihiroh/timeset.
Tri-Modal Motion Retrieval by Learning a Joint Embedding Space
Mar 01, 2024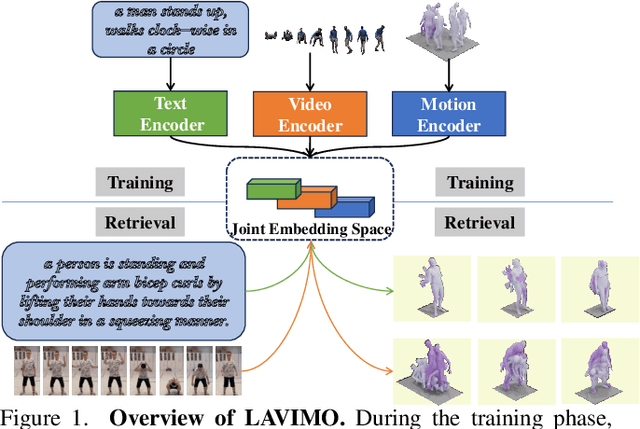
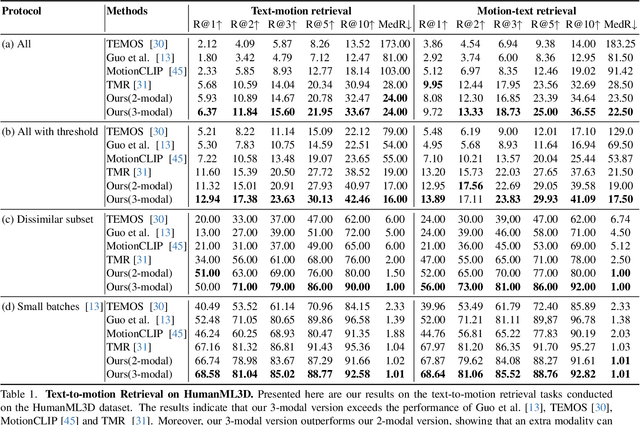
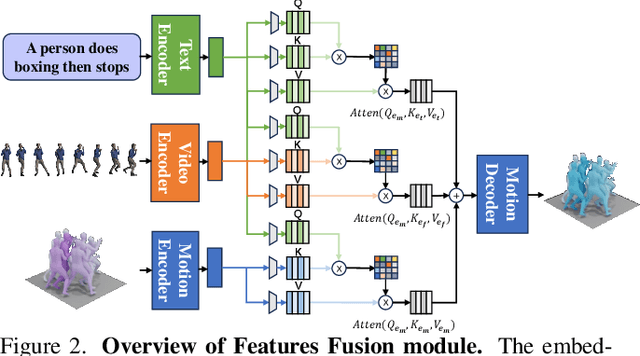
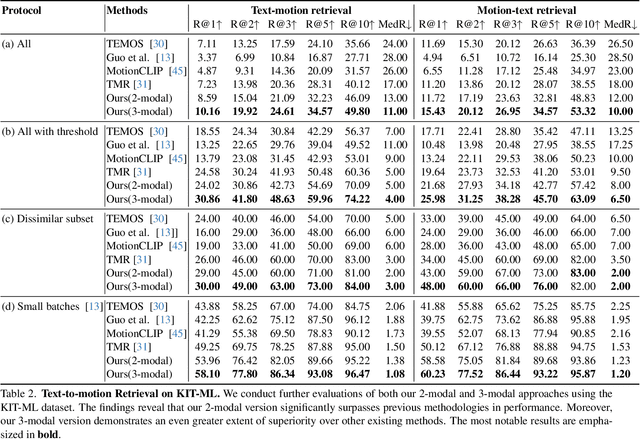
Information retrieval is an ever-evolving and crucial research domain. The substantial demand for high-quality human motion data especially in online acquirement has led to a surge in human motion research works. Prior works have mainly concentrated on dual-modality learning, such as text and motion tasks, but three-modality learning has been rarely explored. Intuitively, an extra introduced modality can enrich a model's application scenario, and more importantly, an adequate choice of the extra modality can also act as an intermediary and enhance the alignment between the other two disparate modalities. In this work, we introduce LAVIMO (LAnguage-VIdeo-MOtion alignment), a novel framework for three-modality learning integrating human-centric videos as an additional modality, thereby effectively bridging the gap between text and motion. Moreover, our approach leverages a specially designed attention mechanism to foster enhanced alignment and synergistic effects among text, video, and motion modalities. Empirically, our results on the HumanML3D and KIT-ML datasets show that LAVIMO achieves state-of-the-art performance in various motion-related cross-modal retrieval tasks, including text-to-motion, motion-to-text, video-to-motion and motion-to-video.