 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Teachers in concordance for pseudo-labeling of 3D sequential data
Jul 13, 2022
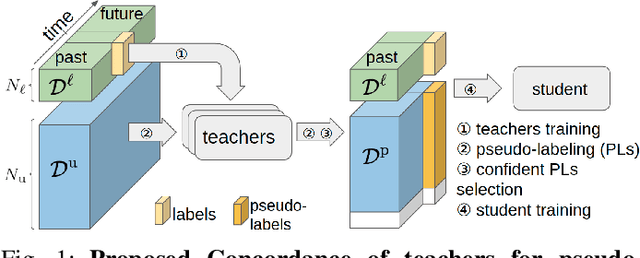
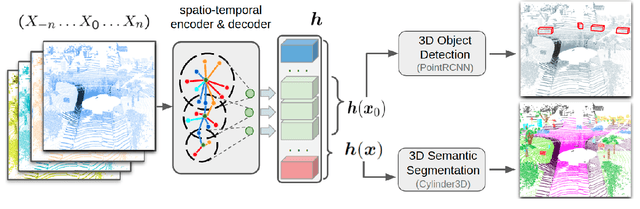

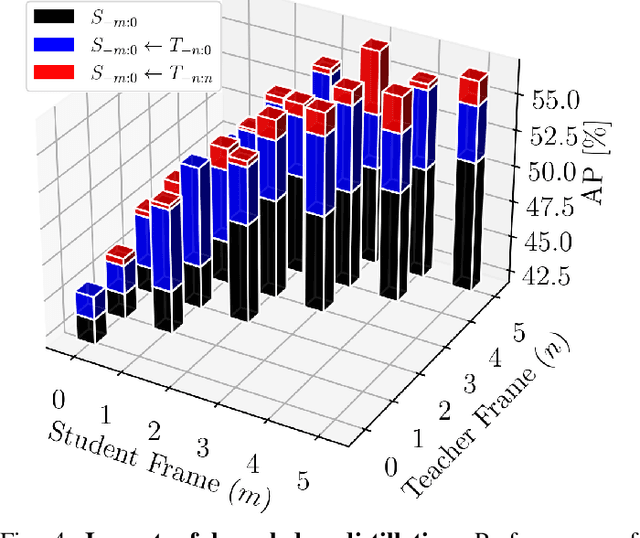
Automatic pseudo-labeling is a powerful tool to tap into large amounts of sequential unlabeled data. It is especially appealing in safety-critical applications of autonomous driving where performance requirements are extreme, datasets large, and manual labeling is very challenging. We propose to leverage the sequentiality of the captures to boost the pseudo-labeling technique in a teacher-student setup via training multiple teachers, each with access to different temporal information. This set of teachers, dubbed Concordance, provides higher quality pseudo-labels for the student training than standard methods. The output of multiple teachers is combined via a novel pseudo-label confidence-guided criterion. Our experimental evaluation focuses on the 3D point cloud domain in urban driving scenarios. We show the performance of our method applied to multiple model architectures with tasks of 3D semantic segmentation and 3D object detection on two benchmark datasets. Our method, using only 20% of manual labels, outperforms some of the fully supervised methods. Special performance boost is achieved for classes rarely appearing in the training data, e.g., bicycles and pedestrians. The implementation of our approach is publicly available at https://github.com/ctu-vras/T-Concord3D.
Face Recognition Accuracy Across Demographics: Shining a Light Into the Problem
Jun 04, 2022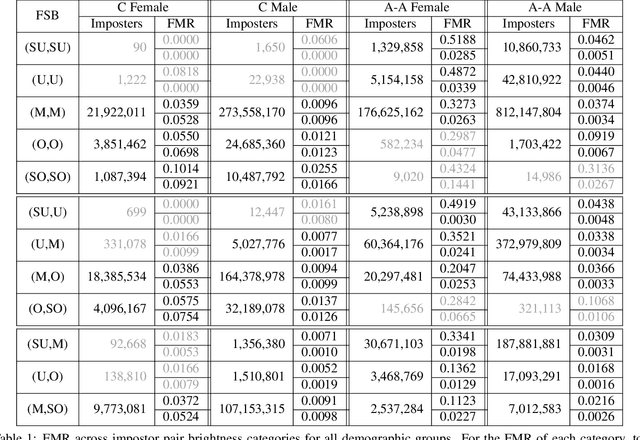

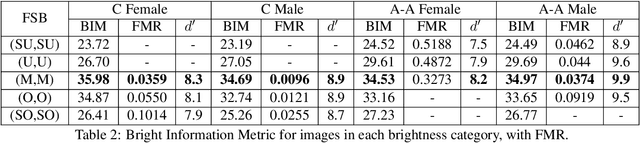
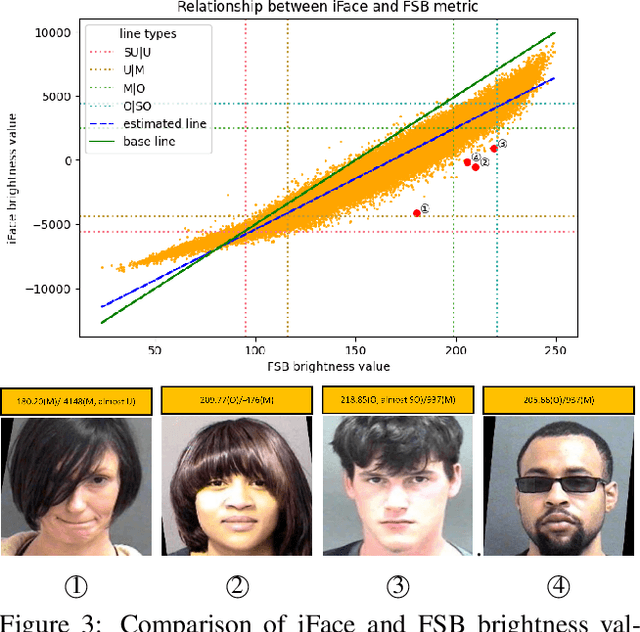
This is the first work that we are aware of to explore how the level of brightness of the skin region in a pair of face images impacts face recognition accuracy. Image pairs with both images having mean face skin brightness in an upper-middle range of brightness are found to have the highest matching accuracy across demographics and matchers. Image pairs with both images having mean face skin brightness that is too dark or too light are found to have an increased false match rate (FMR). Image pairs with strongly different face skin brightness are found to have decreased FMR and increased false non-match rate (FNMR). Using a brightness information metric that captures the variation in brightness in the face skin region, the variation in matching accuracy is shown to correlate with the level of information available in the face skin region. For operational scenarios where image acquisition is controlled, we propose acquiring images with lighting adjusted to yield face skin brightness in a narrow range.
Hierarchical Similarity Learning for Aliasing Suppression Image Super-Resolution
Jun 07, 2022



As a highly ill-posed issue, single image super-resolution (SISR) has been widely investigated in recent years. The main task of SISR is to recover the information loss caused by the degradation procedure. According to the Nyquist sampling theory, the degradation leads to aliasing effect and makes it hard to restore the correct textures from low-resolution (LR) images. In practice, there are correlations and self-similarities among the adjacent patches in the natural images. This paper considers the self-similarity and proposes a hierarchical image super-resolution network (HSRNet) to suppress the influence of aliasing. We consider the SISR issue in the optimization perspective, and propose an iterative solution pattern based on the half-quadratic splitting (HQS) method. To explore the texture with local image prior, we design a hierarchical exploration block (HEB) and progressive increase the receptive field. Furthermore, multi-level spatial attention (MSA) is devised to obtain the relations of adjacent feature and enhance the high-frequency information, which acts as a crucial role for visual experience. Experimental result shows HSRNet achieves better quantitative and visual performance than other works, and remits the aliasing more effectively.
Multiple Kernel Clustering with Dual Noise Minimization
Jul 13, 2022
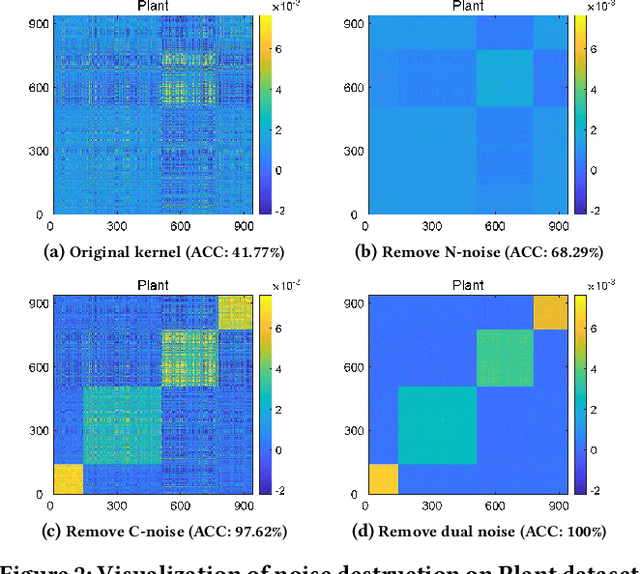
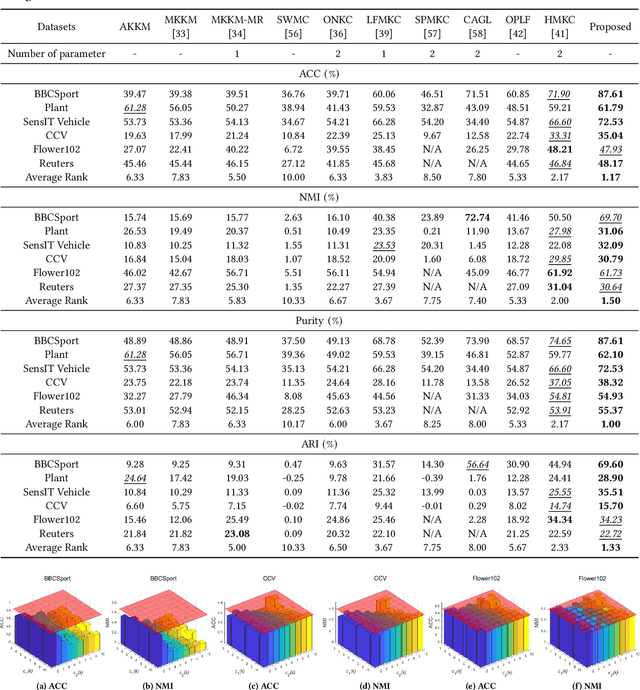
Clustering is a representative unsupervised method widely applied in multi-modal and multi-view scenarios. Multiple kernel clustering (MKC) aims to group data by integrating complementary information from base kernels. As a representative, late fusion MKC first decomposes the kernels into orthogonal partition matrices, then learns a consensus one from them, achieving promising performance recently. However, these methods fail to consider the noise inside the partition matrix, preventing further improvement of clustering performance. We discover that the noise can be disassembled into separable dual parts, i.e. N-noise and C-noise (Null space noise and Column space noise). In this paper, we rigorously define dual noise and propose a novel parameter-free MKC algorithm by minimizing them. To solve the resultant optimization problem, we design an efficient two-step iterative strategy. To our best knowledge, it is the first time to investigate dual noise within the partition in the kernel space. We observe that dual noise will pollute the block diagonal structures and incur the degeneration of clustering performance, and C-noise exhibits stronger destruction than N-noise. Owing to our efficient mechanism to minimize dual noise, the proposed algorithm surpasses the recent methods by large margins.
Privacy-Preserving Face Recognition with Learnable Privacy Budgets in Frequency Domain
Jul 19, 2022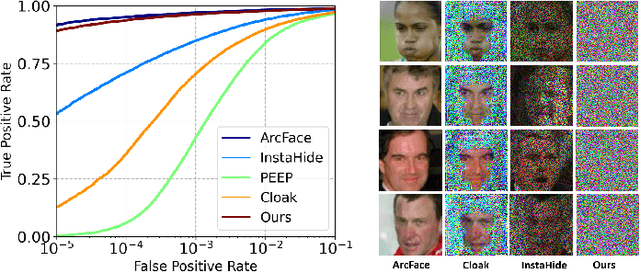

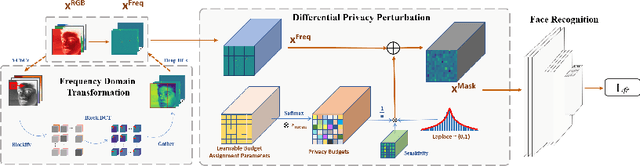
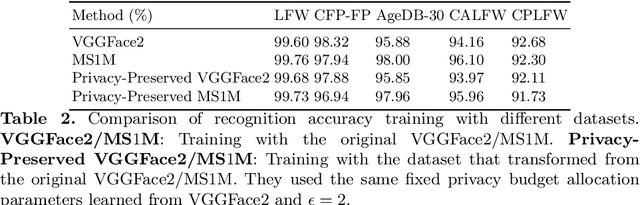
Face recognition technology has been used in many fields due to its high recognition accuracy, including the face unlocking of mobile devices, community access control systems, and city surveillance. As the current high accuracy is guaranteed by very deep network structures, facial images often need to be transmitted to third-party servers with high computational power for inference. However, facial images visually reveal the user's identity information. In this process, both untrusted service providers and malicious users can significantly increase the risk of a personal privacy breach. Current privacy-preserving approaches to face recognition are often accompanied by many side effects, such as a significant increase in inference time or a noticeable decrease in recognition accuracy. This paper proposes a privacy-preserving face recognition method using differential privacy in the frequency domain. Due to the utilization of differential privacy, it offers a guarantee of privacy in theory. Meanwhile, the loss of accuracy is very slight. This method first converts the original image to the frequency domain and removes the direct component termed DC. Then a privacy budget allocation method can be learned based on the loss of the back-end face recognition network within the differential privacy framework. Finally, it adds the corresponding noise to the frequency domain features. Our method performs very well with several classical face recognition test sets according to the extensive experiments.
Multiscale Causal Structure Learning
Jul 16, 2022
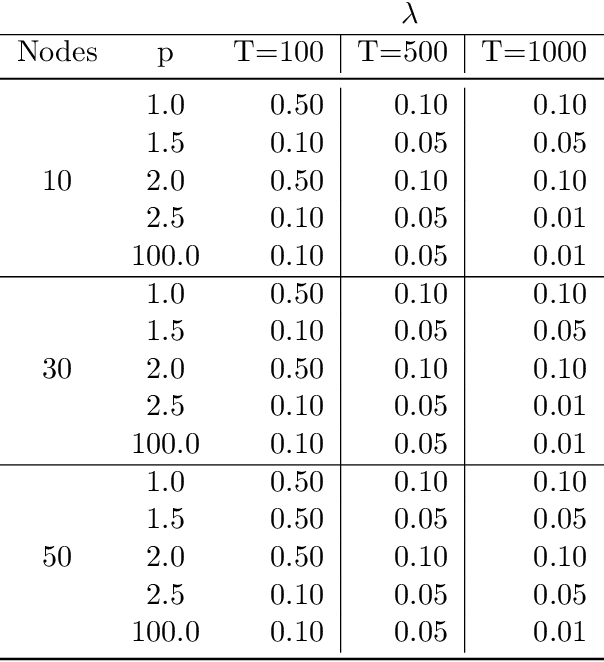
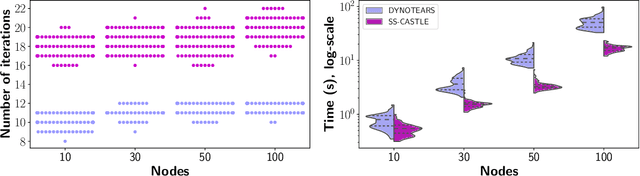
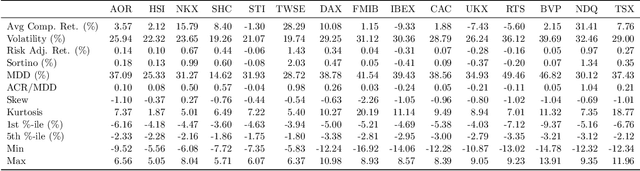
The inference of causal structures from observed data plays a key role in unveiling the underlying dynamics of the system. This paper exposes a novel method, named Multiscale-Causal Structure Learning (MS-CASTLE), to estimate the structure of linear causal relationships occurring at different time scales. Differently from existing approaches, MS-CASTLE takes explicitly into account instantaneous and lagged inter-relations between multiple time series, represented at different scales, hinging on stationary wavelet transform and non-convex optimization. MS-CASTLE incorporates, as a special case, a single-scale version named SS-CASTLE, which compares favorably in terms of computational efficiency, performance and robustness with respect to the state of the art onto synthetic data. We used MS-CASTLE to study the multiscale causal structure of the risk of 15 global equity markets, during covid-19 pandemic, illustrating how MS-CASTLE can extract meaningful information thanks to its multiscale analysis, outperforming SS-CASTLE. We found that the most persistent and strongest interactions occur at mid-term time resolutions. Moreover, we identified the stock markets that drive the risk during the considered period: Brazil, Canada and Italy. The proposed approach can be exploited by financial investors who, depending to their investment horizon, can manage the risk within equity portfolios from a causal perspective.
Collaborative 3D Object Detection for Automatic Vehicle Systems via Learnable Communications
May 24, 2022
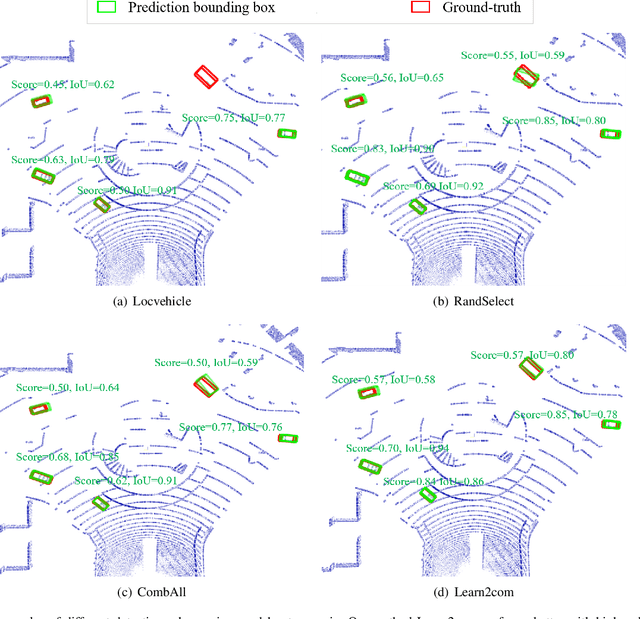
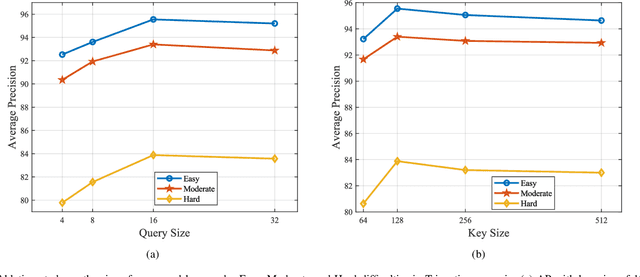
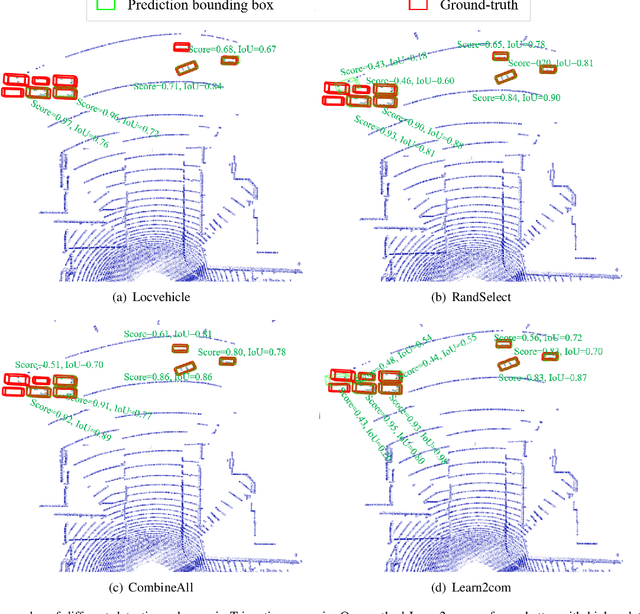
Accurate detection of objects in 3D point clouds is a key problem in autonomous driving systems. Collaborative perception can incorporate information from spatially diverse sensors and provide significant benefits for improving the perception accuracy of autonomous driving systems. In this work, we consider that the autonomous vehicle uses local point cloud data and combines information from neighboring infrastructures through wireless links for cooperative 3D object detection. However, information sharing among vehicle and infrastructures in predefined communication schemes may result in communication congestion and/or bring limited performance improvement. To this end, we propose a novel collaborative 3D object detection framework that consists of three components: feature learning networks that map point clouds into feature maps; an efficient communication block that propagates compact and fine-grained query feature maps from vehicle to support infrastructures and optimizes attention weights between query and key to refine support feature maps; a region proposal network that fuses local feature maps and weighted support feature maps for 3D object detection. We evaluate the performance of the proposed framework using a synthetic cooperative dataset created in two complex driving scenarios: a roundabout and a T-junction. Experiment results and bandwidth usage analysis demonstrate that our approach can save communication and computation costs and significantly improve detection performance under different detection difficulties in all scenarios.
Enhancing Local Geometry Learning for 3D Point Cloud via Decoupling Convolution
Jul 04, 2022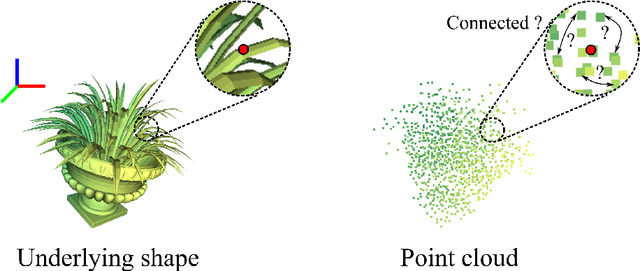
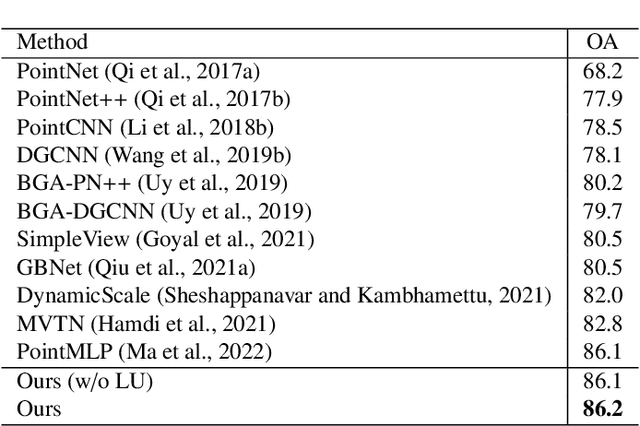
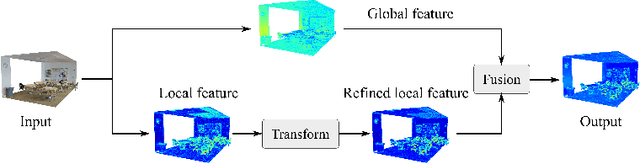
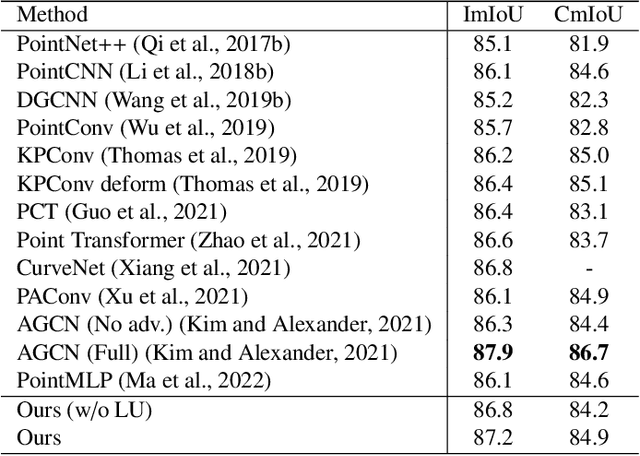
Modeling the local surface geometry is challenging in 3D point cloud understanding due to the lack of connectivity information. Most prior works model local geometry using various convolution operations. We observe that the convolution can be equivalently decomposed as a weighted combination of a local and a global component. With this observation, we explicitly decouple these two components so that the local one can be enhanced and facilitate the learning of local surface geometry. Specifically, we propose Laplacian Unit (LU), a simple yet effective architectural unit that can enhance the learning of local geometry. Extensive experiments demonstrate that networks equipped with LUs achieve competitive or superior performance on typical point cloud understanding tasks. Moreover, through establishing connections between the mean curvature flow, a further investigation of LU based on curvatures is made to interpret the adaptive smoothing and sharpening effect of LU. The code will be available.
Developing a Component Comment Extractor from Product Reviews on E-Commerce Sites
Jul 13, 2022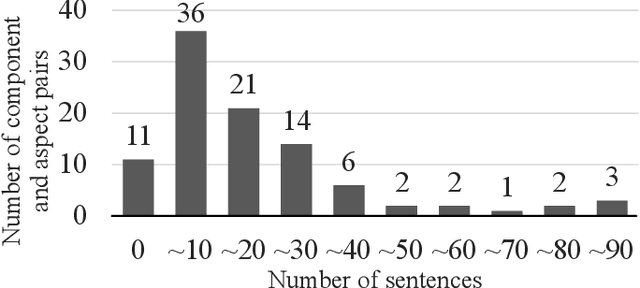
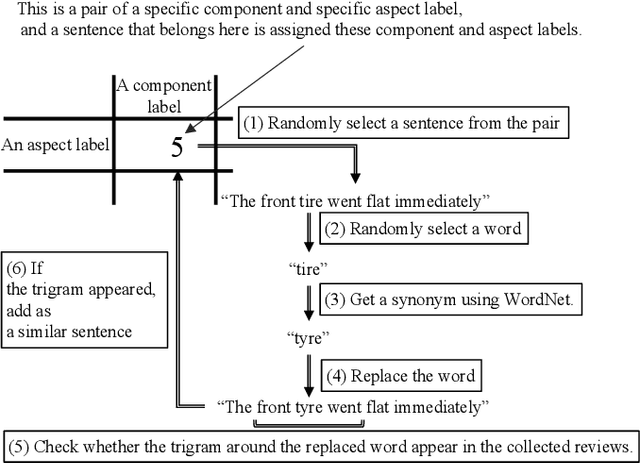
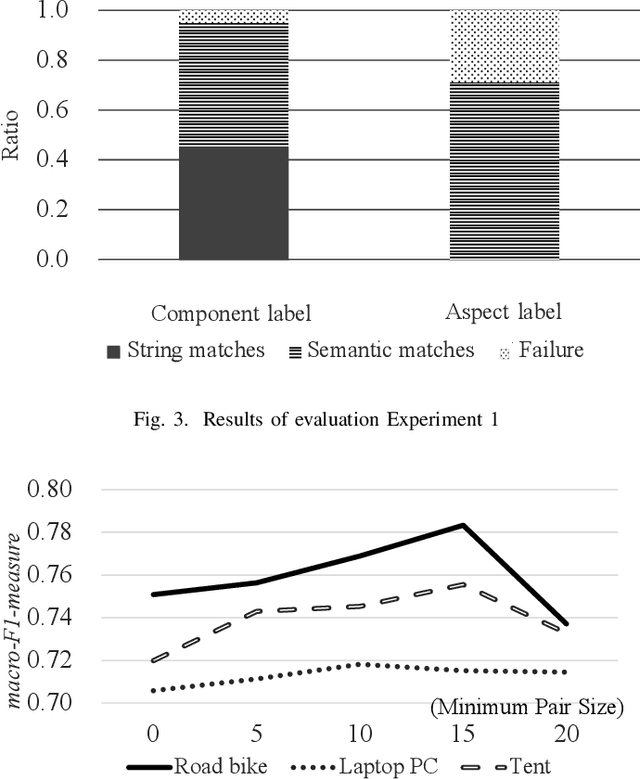
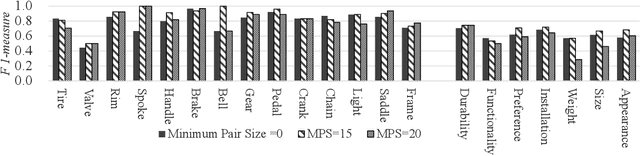
Consumers often read product reviews to inform their buying decision, as some consumers want to know a specific component of a product. However, because typical sentences on product reviews contain various details, users must identify sentences about components they want to know amongst the many reviews. Therefore, we aimed to develop a system that identifies and collects component and aspect information of products in sentences. Our BERT-based classifiers assign labels referring to components and aspects to sentences in reviews and extract sentences with comments on specific components and aspects. We determined proper labels based for the words identified through pattern matching from product reviews to create the training data. Because we could not use the words as labels, we carefully created labels covering the meanings of the words. However, the training data was imbalanced on component and aspect pairs. We introduced a data augmentation method using WordNet to reduce the bias. Our evaluation demonstrates that the system can determine labels for road bikes using pattern matching, covering more than 88\% of the indicators of components and aspects on e-commerce sites. Moreover, our data augmentation method can improve the-F1-measure on insufficient data from 0.66 to 0.76.
* The 14th International Conference on E-Service and Knowledge Management (ESKM 2022), 6 pages, 6 figures, 5 tables
Organic Priors in Non-Rigid Structure from Motion
Jul 16, 2022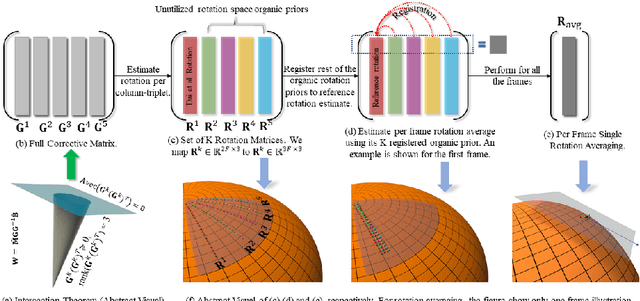
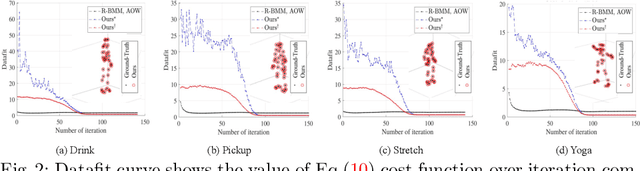

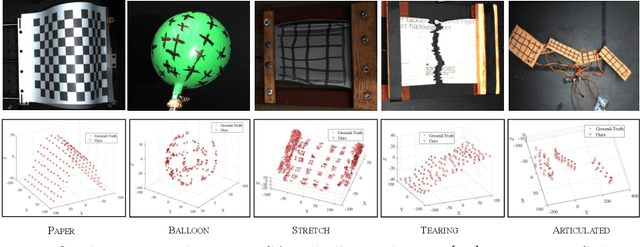
This paper advocates the use of organic priors in classical non-rigid structure from motion (NRSfM). By organic priors, we mean invaluable intermediate prior information intrinsic to the NRSfM matrix factorization theory. It is shown that such priors reside in the factorized matrices, and quite surprisingly, existing methods generally disregard them. The paper's main contribution is to put forward a simple, methodical, and practical method that can effectively exploit such organic priors to solve NRSfM. The proposed method does not make assumptions other than the popular one on the low-rank shape and offers a reliable solution to NRSfM under orthographic projection. Our work reveals that the accessibility of organic priors is independent of the camera motion and shape deformation type. Besides that, the paper provides insights into the NRSfM factorization -- both in terms of shape and motion -- and is the first approach to show the benefit of single rotation averaging for NRSfM. Furthermore, we outline how to effectively recover motion and non-rigid 3D shape using the proposed organic prior based approach and demonstrate results that outperform prior-free NRSfM performance by a significant margin. Finally, we present the benefits of our method via extensive experiments and evaluations on several benchmark datasets.