 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSEMASIA: A Large-Scale Dataset of Semantically Structured Latent Representations
May 10, 2026Latent representations learned by neural networks often exhibit semantic structure, where concept similarity is reflected by geometric proximity in embedding space. However, comparing such spaces across models remains difficult: changes in architecture, pretraining data, objective, or random seed can yield embeddings with similar content but incompatible geometry. This latent space alignment problem is central to interpretability, transfer and multimodal learning, federated systems, and semantic communication; however, progress remains limited by the lack of large-scale, model-diverse, and metadata-rich benchmarks. To address this gap, we introduce SEMASIA, a large-scale collection of latent representations extracted from approximately 1,700 pretrained vision models across eight standard image-classification benchmarks. SEMASIA pairs embeddings with structured metadata describing architectures, training regimes, pretraining sources, and model scale. We demonstrate three applications of the resource. First, we analyze the conceptual organization of individual latent spaces, showing consistent prototype-like clustering and hierarchical semantic neighborhoods across models and datasets. Second, we benchmark supervised alignment mappings between latent spaces using reconstruction error and downstream task performance. Third, we perform a large-scale regression analysis of how pretraining-data complexity, specialization, transfer learning, augmentation, and model scale relate to geometric and probing properties of embeddings. By coupling representational scale with standardized metadata, SEMASIA provides a reproducible foundation for studying latent geometry, evaluating alignment methods, and developing next-generation heterogeneous and interoperable AI systems.
Toward Integrated Sensing, Communications, and Edge Intelligence Networks
Mar 24, 2026Wireless systems are expanding their purposes, from merely connecting humans and things to connecting intelligence and opportunistically sensing of the environment through radio-frequency signals. In this paper, we introduce the concept of triple-functional networks in which the same infrastructure and resources are shared for integrated sensing, communications, and (edge) Artificial Intelligence (AI) inference. This concept opens up several opportunities, such as devising non-orthogonal resource deployment and power consumption to concurrently update multiple services, but also challenges related to resource management and signaling cross-talk, among others. The core idea of this work is that computation-related aspects, including computing resources and AI models availability, should be explicitly considered when taking resource allocation decisions, to address the conflicting goals of the services coexistence. After showing the natural coupling between theoretical performance bounds of the three services, we formulate a service coexistence optimization problem that is solved optimally, and showcase the advantages against a disjoint allocation strategy.
Metasurfaces-Integrated Wireless Neural Networks for Lightweight Over-The-Air Edge Inference
Feb 22, 2026The upcoming sixth Generation (6G) of wireless networks envisions ultra-low latency and energy efficient Edge Inference (EI) for diverse Internet of Things (IoT) applications. However, traditional digital hardware for machine learning is power intensive, motivating the need for alternative computation paradigms. Over-The-Air (OTA) computation is regarded as an emerging transformative approach assigning the wireless channel to actively perform computational tasks. This article introduces the concept of Metasurfaces-Integrated Neural Networks (MINNs), a physical-layer-enabled deep learning framework that leverages programmable multi-layer metasurface structures and Multiple-Input Multiple-Output (MIMO) channels to realize computational layers in the wave propagation domain. The MINN system is conceptualized as three modules: Encoder, Channel (uncontrollable propagation features and metasurfaces), and Decoder. The first and last modules, realized respectively at the multi-antenna transmitter and receiver, consist of conventional digital or purposely designed analog Deep Neural Network (DNN) layers, and the metasurfaces responses of the Channel module are optimized alongside all modules as trainable weights. This architecture enables computation offloading into the end-to-end physical layer, flexibly among its constituent modules, achieving performance comparable to fully digital DNNs while significantly reducing power consumption. The training of the MINN framework, two representative variations, and performance results for indicative applications are presented, highlighting the potential of MINNs as a lightweight and sustainable solution for future EI-enabled wireless systems. The article is concluded with a list of open challenges and promising research directions.
Federated Latent Space Alignment for Multi-user Semantic Communications
Feb 19, 2026Semantic communication aims to convey meaning for effective task execution, but differing latent representations in AI-native devices can cause semantic mismatches that hinder mutual understanding. This paper introduces a novel approach to mitigating latent space misalignment in multi-agent AI- native semantic communications. In a downlink scenario, we consider an access point (AP) communicating with multiple users to accomplish a specific AI-driven task. Our method implements a protocol that shares a semantic pre-equalizer at the AP and local semantic equalizers at user devices, fostering mutual understanding and task-oriented communication while considering power and complexity constraints. To achieve this, we employ a federated optimization for the decentralized training of the semantic equalizers at the AP and user sides. Numerical results validate the proposed approach in goal-oriented semantic communication, revealing key trade-offs among accuracy, com- munication overhead, complexity, and the semantic proximity of AI-native communication devices.
Learning Dirac Spectral Transforms for Topological Signals
Feb 16, 2026The Dirac operator provides a unified framework for processing signals defined over different order topological domains, such as node and edge signals. Its eigenmodes define a spectral representation that inherently captures cross-domain interactions, in contrast to conventional Hodge-Laplacian eigenmodes that operate within a single topological dimension. In this paper, we compare the two alternatives in terms of the distortion/sparsity trade-off and we show how an overcomplete basis built concatenating the two dictionaries can provide better performance with respect to each approach. Then, we propose a parameterized nonredundant transform whose eigenmodes incorporate a mode-specific mass parameter that captures the interplay between node and edge modes. Interestingly, we show that learning the mass parameters from data makes the proposed transform able to achieve the best distortion-sparsity tradeoff with respect to both complete and overcomplete bases.
Learning Consistent Causal Abstraction Networks
Feb 02, 2026Causal artificial intelligence aims to enhance explainability, trustworthiness, and robustness in AI by leveraging structural causal models (SCMs). In this pursuit, recent advances formalize network sheaves and cosheaves of causal knowledge. Pushing in the same direction, we tackle the learning of consistent causal abstraction network (CAN), a sheaf-theoretic framework where (i) SCMs are Gaussian, (ii) restriction maps are transposes of constructive linear causal abstractions (CAs) adhering to the semantic embedding principle, and (iii) edge stalks correspond--up to permutation--to the node stalks of more detailed SCMs. Our problem formulation separates into edge-specific local Riemannian problems and avoids nonconvex objectives. We propose an efficient search procedure, solving the local problems with SPECTRAL, our iterative method with closed-form updates and suitable for positive definite and semidefinite covariance matrices. Experiments on synthetic data show competitive performance in the CA learning task, and successful recovery of diverse CAN structures.
Over-the-Air Goal-Oriented Communications
Dec 23, 2025Goal-oriented communications offer an attractive alternative to the Shannon-based communication paradigm, where the data is never reconstructed at the Receiver (RX) side. Rather, focusing on the case of edge inference, the Transmitter (TX) and the RX cooperate to exchange features of the input data that will be used to predict an unseen attribute of them, leveraging information from collected data sets. This chapter demonstrates that the wireless channel can be used to perform computations over the data, when equipped with programmable metasurfaces. The end-to-end system of the TX, RX, and MS-based channel is treated as a single deep neural network which is trained through backpropagation to perform inference on unseen data. Using Stacked Intelligent Metasurfaces (SIM), it is shown that this Metasurfaces-Integrated Neural Network (MINN) can achieve performance comparable to fully digital neural networks under various system parameters and data sets. By offloading computations onto the channel itself, important benefits may be achieved in terms of energy consumption, arising from reduced computations at the transceivers and smaller transmission power required for successful inference.
Semantic Channel Equalization Strategies for Deep Joint Source-Channel Coding
Oct 06, 2025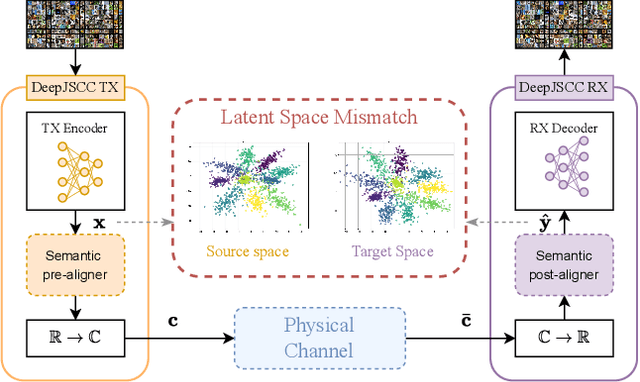

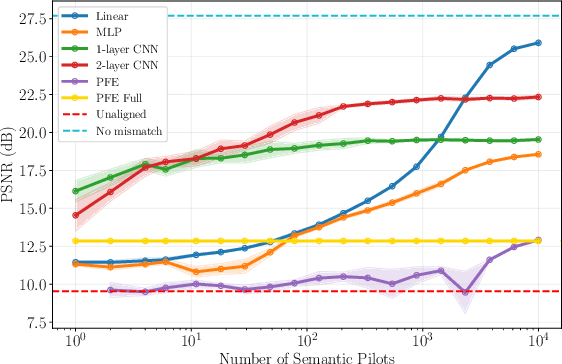
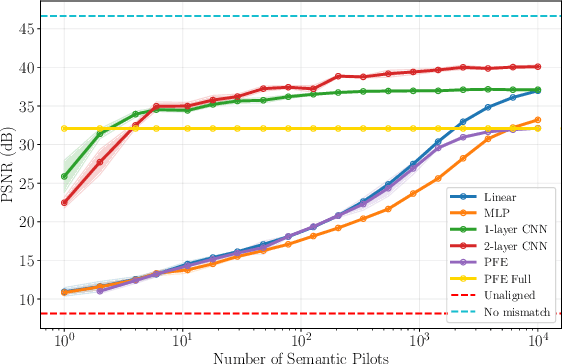
Deep joint source-channel coding (DeepJSCC) has emerged as a powerful paradigm for end-to-end semantic communications, jointly learning to compress and protect task-relevant features over noisy channels. However, existing DeepJSCC schemes assume a shared latent space at transmitter (TX) and receiver (RX) - an assumption that fails in multi-vendor deployments where encoders and decoders cannot be co-trained. This mismatch introduces "semantic noise", degrading reconstruction quality and downstream task performance. In this paper, we systematize and evaluate methods for semantic channel equalization for DeepJSCC, introducing an additional processing stage that aligns heterogeneous latent spaces under both physical and semantic impairments. We investigate three classes of aligners: (i) linear maps, which admit closed-form solutions; (ii) lightweight neural networks, offering greater expressiveness; and (iii) a Parseval-frame equalizer, which operates in zero-shot mode without the need for training. Through extensive experiments on image reconstruction over AWGN and fading channels, we quantify trade-offs among complexity, data efficiency, and fidelity, providing guidelines for deploying DeepJSCC in heterogeneous AI-native wireless networks.
Communication Efficient Split Learning of ViTs with Attention-based Double Compression
Sep 18, 2025



This paper proposes a novel communication-efficient Split Learning (SL) framework, named Attention-based Double Compression (ADC), which reduces the communication overhead required for transmitting intermediate Vision Transformers activations during the SL training process. ADC incorporates two parallel compression strategies. The first one merges samples' activations that are similar, based on the average attention score calculated in the last client layer; this strategy is class-agnostic, meaning that it can also merge samples having different classes, without losing generalization ability nor decreasing final results. The second strategy follows the first and discards the least meaningful tokens, further reducing the communication cost. Combining these strategies not only allows for sending less during the forward pass, but also the gradients are naturally compressed, allowing the whole model to be trained without additional tuning or approximations of the gradients. Simulation results demonstrate that Attention-based Double Compression outperforms state-of-the-art SL frameworks by significantly reducing communication overheads while maintaining high accuracy.
Latent Space Alignment for AI-Native MIMO Semantic Communications
Jul 24, 2025



Semantic communications focus on prioritizing the understanding of the meaning behind transmitted data and ensuring the successful completion of tasks that motivate the exchange of information. However, when devices rely on different languages, logic, or internal representations, semantic mismatches may occur, potentially hindering mutual understanding. This paper introduces a novel approach to addressing latent space misalignment in semantic communications, exploiting multiple-input multiple-output (MIMO) communications. Specifically, our method learns a MIMO precoder/decoder pair that jointly performs latent space compression and semantic channel equalization, mitigating both semantic mismatches and physical channel impairments. We explore two solutions: (i) a linear model, optimized by solving a biconvex optimization problem via the alternating direction method of multipliers (ADMM); (ii) a neural network-based model, which learns semantic MIMO precoder/decoder under transmission power budget and complexity constraints. Numerical results demonstrate the effectiveness of the proposed approach in a goal-oriented semantic communication scenario, illustrating the main trade-offs between accuracy, communication burden, and complexity of the solutions.