 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
HTCInfoMax: A Global Model for Hierarchical Text Classification via Information Maximization
Apr 12, 2021
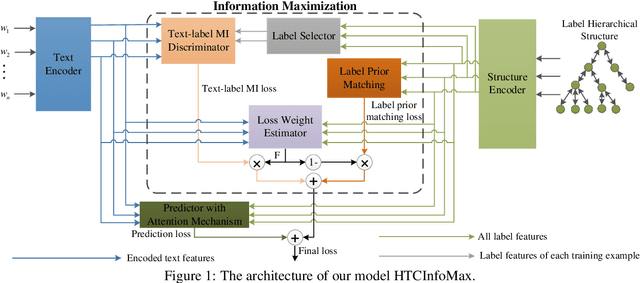
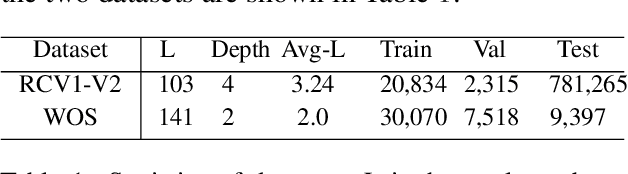
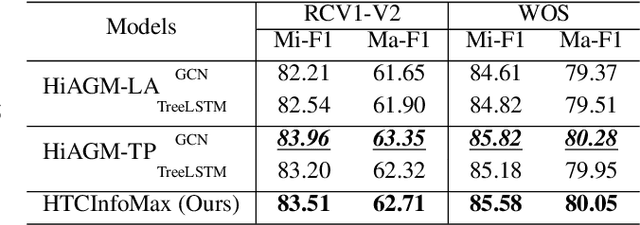
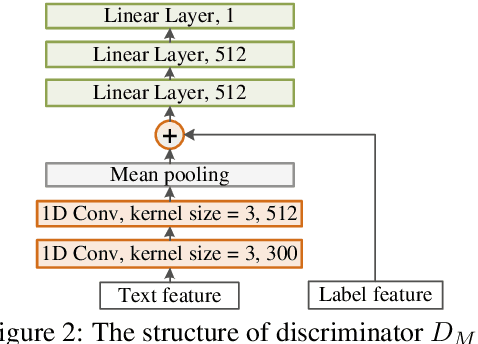
The current state-of-the-art model HiAGM for hierarchical text classification has two limitations. First, it correlates each text sample with all labels in the dataset which contains irrelevant information. Second, it does not consider any statistical constraint on the label representations learned by the structure encoder, while constraints for representation learning are proved to be helpful in previous work. In this paper, we propose HTCInfoMax to address these issues by introducing information maximization which includes two modules: text-label mutual information maximization and label prior matching. The first module can model the interaction between each text sample and its ground truth labels explicitly which filters out irrelevant information. The second one encourages the structure encoder to learn better representations with desired characteristics for all labels which can better handle label imbalance in hierarchical text classification. Experimental results on two benchmark datasets demonstrate the effectiveness of the proposed HTCInfoMax.
Predicting Day-Ahead Stock Returns using Search Engine Query Volumes: An Application of Gradient Boosted Decision Trees to the S&P 100
Jun 01, 2022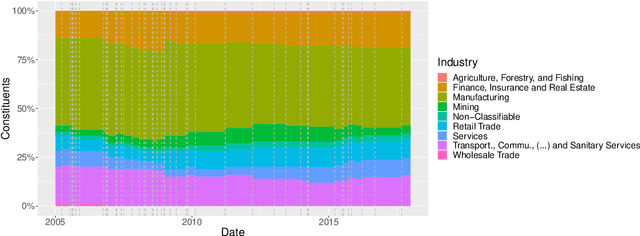
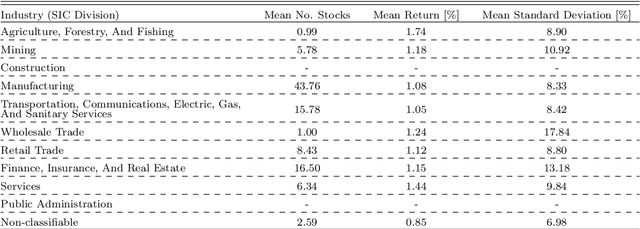
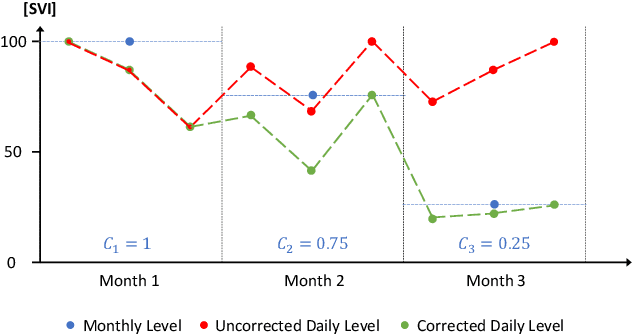

The internet has changed the way we live, work and take decisions. As it is the major modern resource for research, detailed data on internet usage exhibits vast amounts of behavioral information. This paper aims to answer the question whether this information can be facilitated to predict future returns of stocks on financial capital markets. In an empirical analysis it implements gradient boosted decision trees to learn relationships between abnormal returns of stocks within the S&P 100 index and lagged predictors derived from historical financial data, as well as search term query volumes on the internet search engine Google. Models predict the occurrence of day-ahead stock returns in excess of the index median. On a time frame from 2005 to 2017, all disparate datasets exhibit valuable information. Evaluated models have average areas under the receiver operating characteristic between 54.2% and 56.7%, clearly indicating a classification better than random guessing. Implementing a simple statistical arbitrage strategy, models are used to create daily trading portfolios of ten stocks and result in annual performances of more than 57% before transaction costs. With ensembles of different data sets topping up the performance ranking, the results further question the weak form and semi-strong form efficiency of modern financial capital markets. Even though transaction costs are not included, the approach adds to the existing literature. It gives guidance on how to use and transform data on internet usage behavior for financial and economic modeling and forecasting.
Effectiveness of French Language Models on Abstractive Dialogue Summarization Task
Jul 17, 2022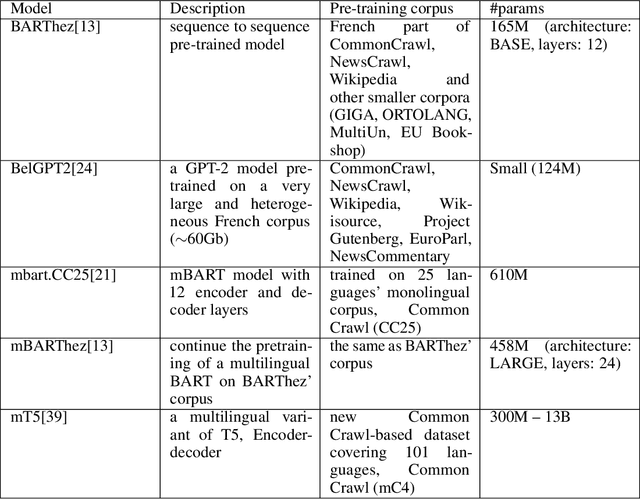
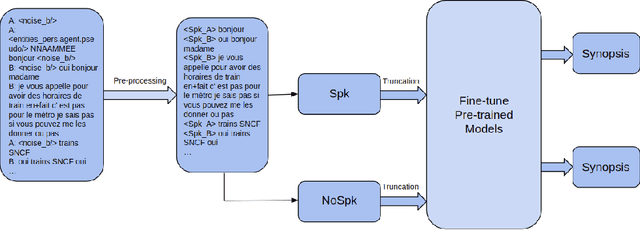


Pre-trained language models have established the state-of-the-art on various natural language processing tasks, including dialogue summarization, which allows the reader to quickly access key information from long conversations in meetings, interviews or phone calls. However, such dialogues are still difficult to handle with current models because the spontaneity of the language involves expressions that are rarely present in the corpora used for pre-training the language models. Moreover, the vast majority of the work accomplished in this field has been focused on English. In this work, we present a study on the summarization of spontaneous oral dialogues in French using several language specific pre-trained models: BARThez, and BelGPT-2, as well as multilingual pre-trained models: mBART, mBARThez, and mT5. Experiments were performed on the DECODA (Call Center) dialogue corpus whose task is to generate abstractive synopses from call center conversations between a caller and one or several agents depending on the situation. Results show that the BARThez models offer the best performance far above the previous state-of-the-art on DECODA. We further discuss the limits of such pre-trained models and the challenges that must be addressed for summarizing spontaneous dialogues.
Bugs in Machine Learning-based Systems: A Faultload Benchmark
Jun 24, 2022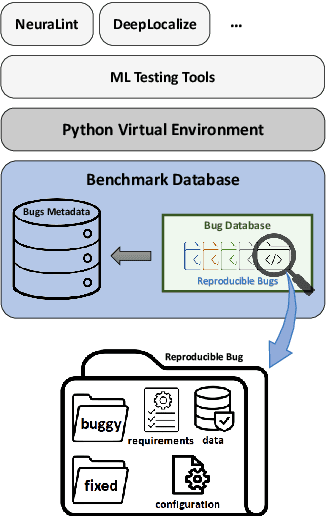


The rapid escalation of applying Machine Learning (ML) in various domains has led to paying more attention to the quality of ML components. There is then a growth of techniques and tools aiming at improving the quality of ML components and integrating them into the ML-based system safely. Although most of these tools use bugs' lifecycle, there is no standard benchmark of bugs to assess their performance, compare them and discuss their advantages and weaknesses. In this study, we firstly investigate the reproducibility and verifiability of the bugs in ML-based systems and show the most important factors in each one. Then, we explore the challenges of generating a benchmark of bugs in ML-based software systems and provide a bug benchmark namely defect4ML that satisfies all criteria of standard benchmark, i.e. relevance, reproducibility, fairness, verifiability, and usability. This faultload benchmark contains 113 bugs reported by ML developers on GitHub and Stack Overflow, using two of the most popular ML frameworks: TensorFlow and Keras. defect4ML also addresses important challenges in Software Reliability Engineering of ML-based software systems, like: 1) fast changes in frameworks, by providing various bugs for different versions of frameworks, 2) code portability, by delivering similar bugs in different ML frameworks, 3) bug reproducibility, by providing fully reproducible bugs with complete information about required dependencies and data, and 4) lack of detailed information on bugs, by presenting links to the bugs' origins. defect4ML can be of interest to ML-based systems practitioners and researchers to assess their testing tools and techniques.
Information-Theoretic Bounds for Integral Estimation
Feb 19, 2021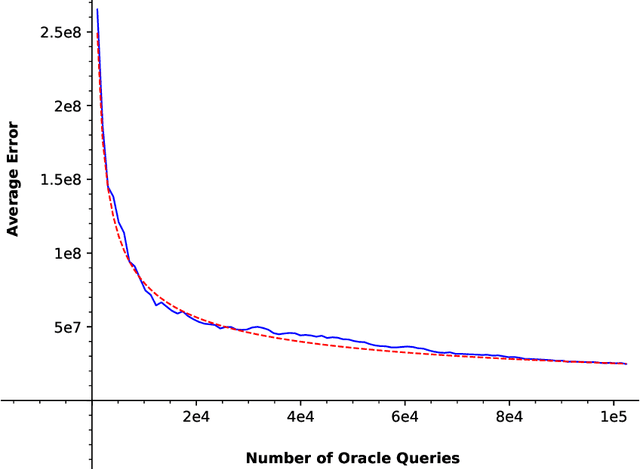
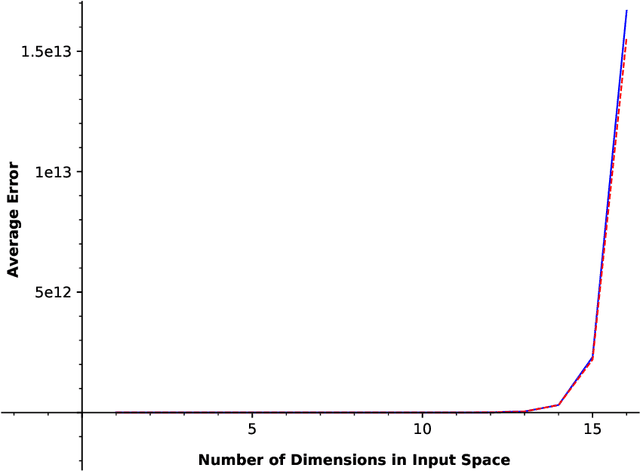
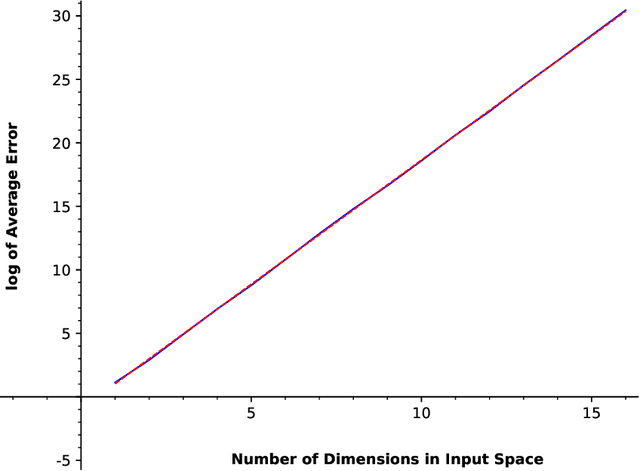
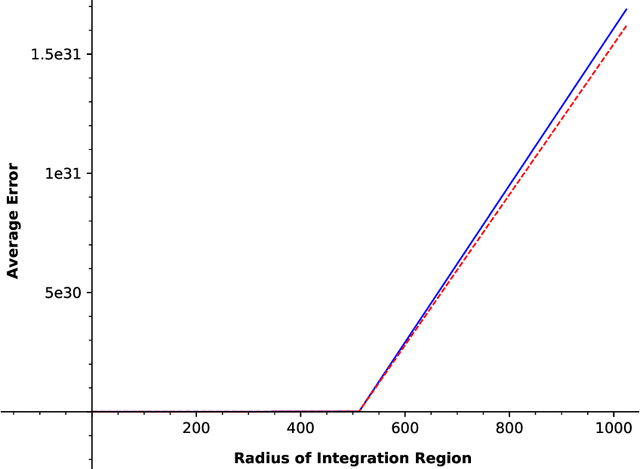
In this paper, we consider a zero-order stochastic oracle model of estimating definite integrals. In this model, integral estimation methods may query an oracle function for a fixed number of noisy values of the integrand function and use these values to produce an estimate of the integral. We first show that the information-theoretic error lower bound for estimating the integral of a $d$-dimensional function over a region with $l_\infty$ radius $r$ using at most $T$ queries to the oracle function is $\Omega(2^d r^{d+1}\sqrt{d/T})$. Additionally, we find that the Gaussian Quadrature method under the same model achieves a rate of $O(2^{d}r^d/\sqrt{T})$ for functions with zero fourth and higher-order derivatives with respect to individual dimensions, and for Gaussian oracles, this rate is tight. For functions with nonzero fourth derivatives, the Gaussian Quadrature method achieves an upper bound which is not tight with the information-theoretic lower bound. Therefore, it is not minimax optimal, so there is space for the development of better integral estimation methods for such functions.
Cross-domain Detection Transformer based on Spatial-aware and Semantic-aware Token Alignment
Jun 01, 2022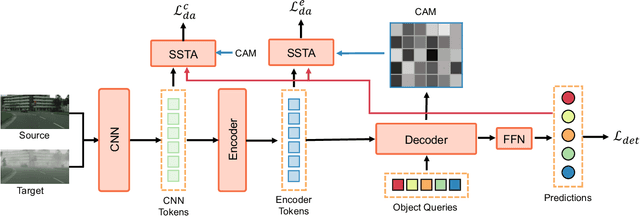
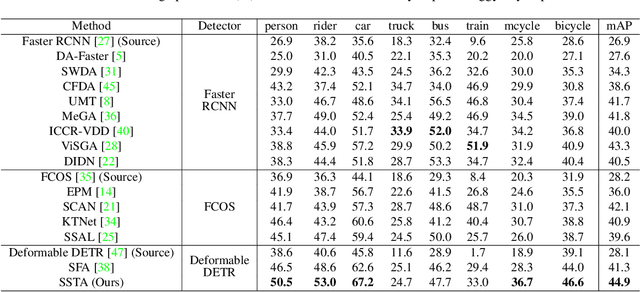
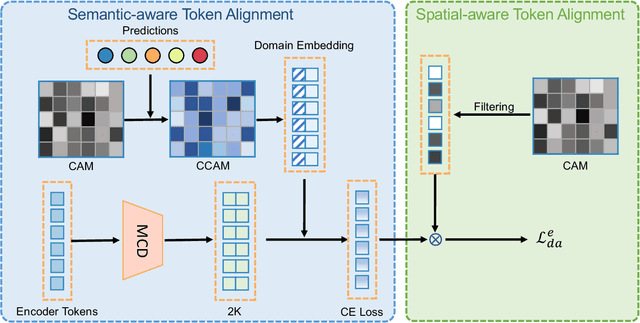
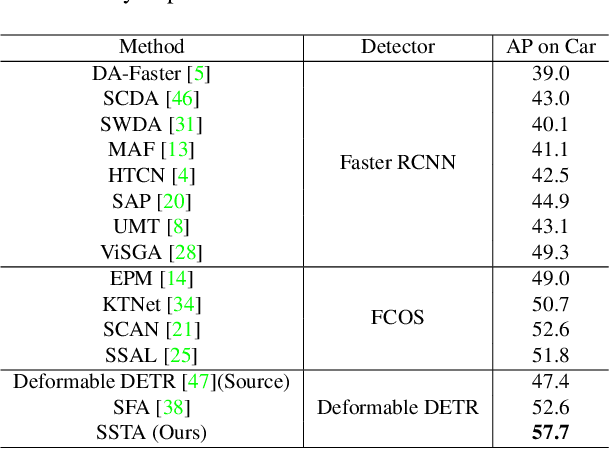
Detection transformers like DETR have recently shown promising performance on many object detection tasks, but the generalization ability of those methods is still quite challenging for cross-domain adaptation scenarios. To address the cross-domain issue, a straightforward way is to perform token alignment with adversarial training in transformers. However, its performance is often unsatisfactory as the tokens in detection transformers are quite diverse and represent different spatial and semantic information. In this paper, we propose a new method called Spatial-aware and Semantic-aware Token Alignment (SSTA) for cross-domain detection transformers. In particular, we take advantage of the characteristics of cross-attention as used in detection transformer and propose the spatial-aware token alignment (SpaTA) and the semantic-aware token alignment (SemTA) strategies to guide the token alignment across domains. For spatial-aware token alignment, we can extract the information from the cross-attention map (CAM) to align the distribution of tokens according to their attention to object queries. For semantic-aware token alignment, we inject the category information into the cross-attention map and construct domain embedding to guide the learning of a multi-class discriminator so as to model the category relationship and achieve category-level token alignment during the entire adaptation process. We conduct extensive experiments on several widely-used benchmarks, and the results clearly show the effectiveness of our proposed method over existing state-of-the-art baselines.
Vision-Aided Frame-Capture-Based CSI Recomposition for WiFi Sensing: A Multimodal Approach
Jun 03, 2022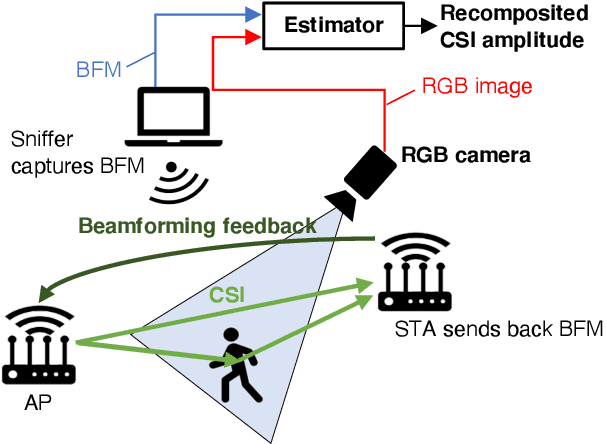
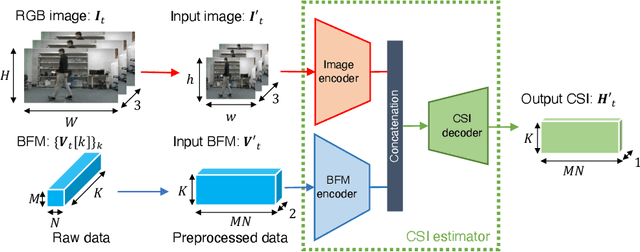
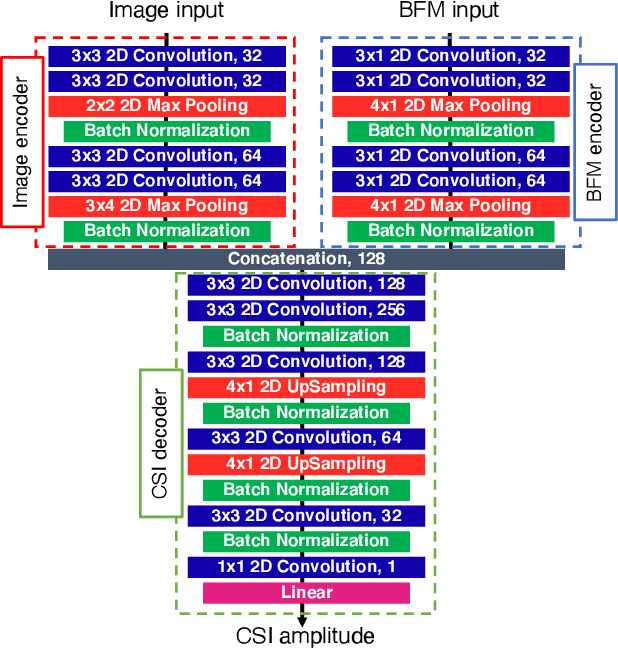
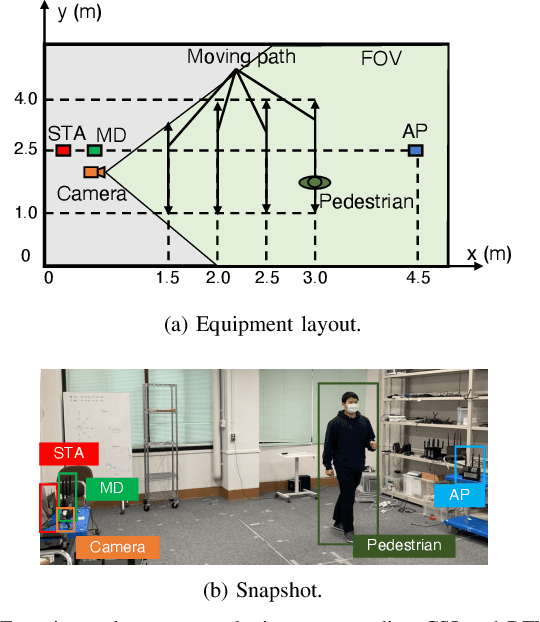
Recompositing channel state information (CSI) from the beamforming feedback matrix (BFM), which is a compressed version of CSI and can be captured because of its lack of encryption, is an alternative way of implementing firmware-agnostic WiFi sensing. In this study, we propose the use of camera images toward the accuracy enhancement of CSI recomposition from BFM. The key motivation for this vision-aided CSI recomposition is to draw a first-hand insight that the BFM does not fully involve spatial information to recomposite CSI and that this could be compensated by camera images. To leverage the camera images, we use multimodal deep learning, where the two modalities, i.e., images and BFMs, are integrated to recomposite the CSI. We conducted experiments using IEEE 802.11ac devices. The experimental results confirmed that the recomposition accuracy of the proposed multimodal framework is improved compared to the single-modal framework only using images or BFMs.
PVDD: A Practical Video Denoising Dataset with Real-World Dynamic Scenes
Jul 04, 2022


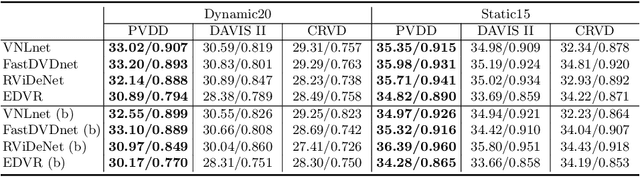
To facilitate video denoising research, we construct a compelling dataset, namely, "Practical Video Denoising Dataset" (PVDD), containing 200 noisy-clean dynamic video pairs in both sRGB and RAW format. Compared with existing datasets consisting of limited motion information, PVDD covers dynamic scenes with varying and natural motion. Different from datasets using primary Gaussian or Poisson distributions to synthesize noise in the sRGB domain, PVDD synthesizes realistic noise from the RAW domain with a physically meaningful sensor noise model followed by ISP processing. Moreover, based on this dataset, we propose a shuffle-based practical degradation model to enhance the performance of video denoising networks on real-world sRGB videos. Extensive experiments demonstrate that models trained on PVDD achieve superior denoising performance on many challenging real-world videos than on models trained on other existing datasets.
Flow-based Visual Quality Enhancer for Super-resolution Magnetic Resonance Spectroscopic Imaging
Jul 20, 2022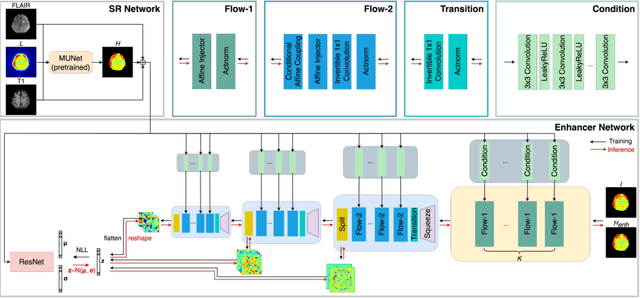
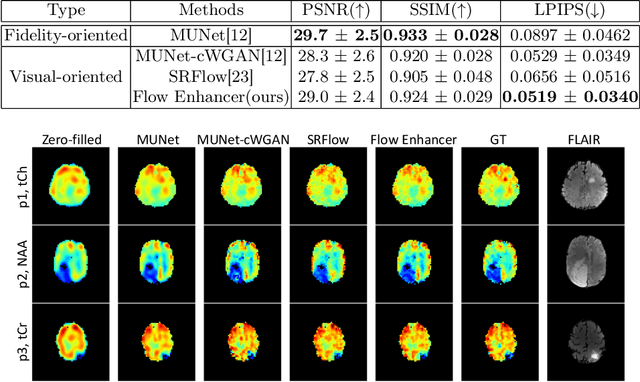
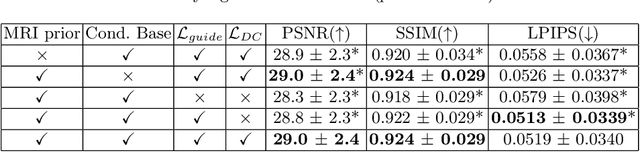
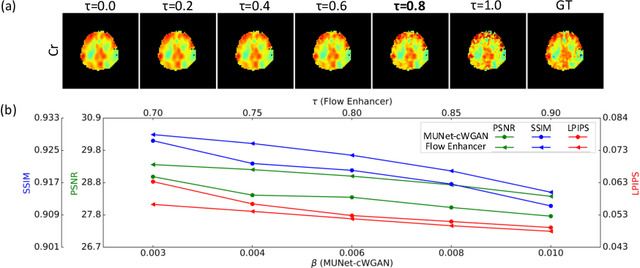
Magnetic Resonance Spectroscopic Imaging (MRSI) is an essential tool for quantifying metabolites in the body, but the low spatial resolution limits its clinical applications. Deep learning-based super-resolution methods provided promising results for improving the spatial resolution of MRSI, but the super-resolved images are often blurry compared to the experimentally-acquired high-resolution images. Attempts have been made with the generative adversarial networks to improve the image visual quality. In this work, we consider another type of generative model, the flow-based model, of which the training is more stable and interpretable compared to the adversarial networks. Specifically, we propose a flow-based enhancer network to improve the visual quality of super-resolution MRSI. Different from previous flow-based models, our enhancer network incorporates anatomical information from additional image modalities (MRI) and uses a learnable base distribution. In addition, we impose a guide loss and a data-consistency loss to encourage the network to generate images with high visual quality while maintaining high fidelity. Experiments on a 1H-MRSI dataset acquired from 25 high-grade glioma patients indicate that our enhancer network outperforms the adversarial networks and the baseline flow-based methods. Our method also allows visual quality adjustment and uncertainty estimation.
A Ligand-and-structure Dual-driven Deep Learning Method for the Discovery of Highly Potent GnRH1R Antagonist to treat Uterine Diseases
Jul 23, 2022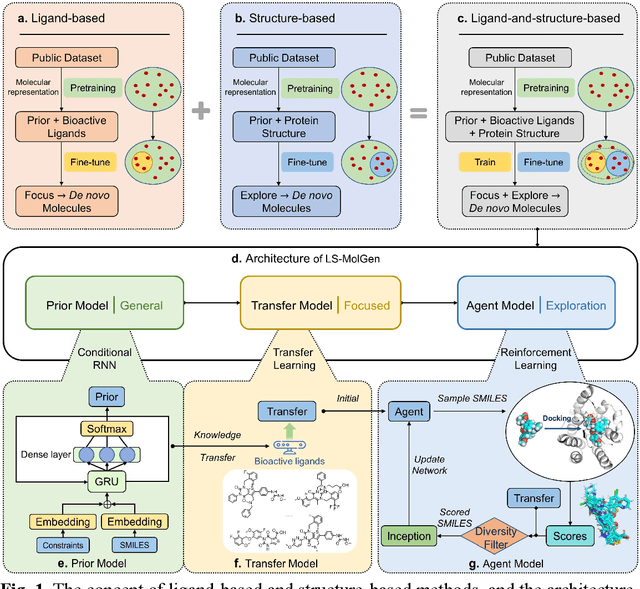
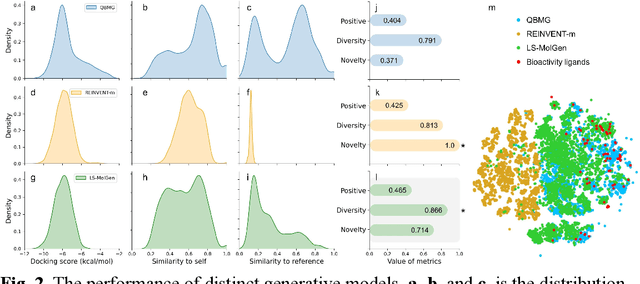
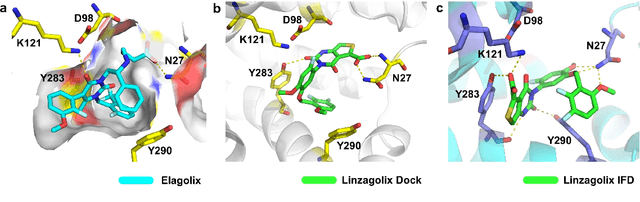
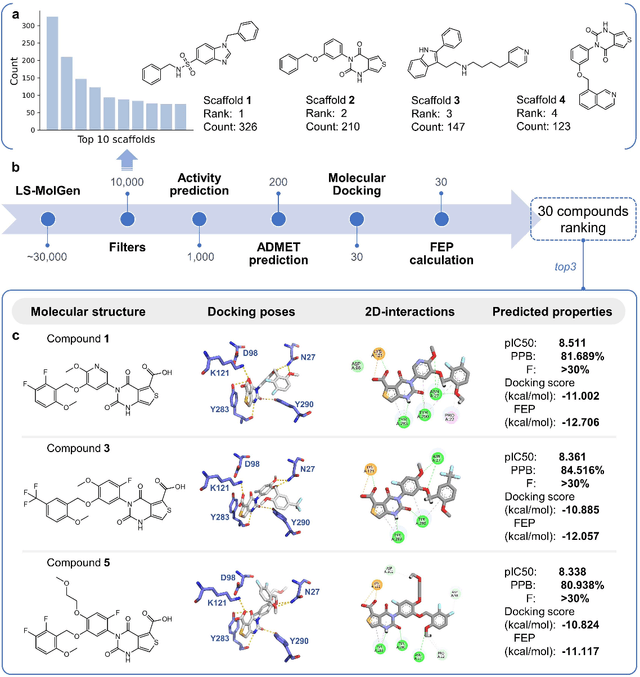
Gonadotrophin-releasing hormone receptor (GnRH1R) is a promising therapeutic target for the treatment of uterine diseases. To date, several GnRH1R antagonists are available in clinical investigation without satisfying multiple property constraints. To fill this gap, we aim to develop a deep learning-based framework to facilitate the effective and efficient discovery of a new orally active small-molecule drug targeting GnRH1R with desirable properties. In the present work, a ligand-and-structure combined model, namely LS-MolGen, was firstly proposed for molecular generation by fully utilizing the information on the known active compounds and the structure of the target protein, which was demonstrated by its superior performance than ligand- or structure-based methods separately. Then, a in silico screening including activity prediction, ADMET evaluation, molecular docking and FEP calculation was conducted, where ~30,000 generated novel molecules were narrowed down to 8 for experimental synthesis and validation. In vitro and in vivo experiments showed that three of them exhibited potent inhibition activities (compound 5 IC50 = 0.856 nM, compound 6 IC50 = 0.901 nM, compound 7 IC50 = 2.54 nM) against GnRH1R, and compound 5 performed well in fundamental PK properties, such as half-life, oral bioavailability, and PPB, etc. We believed that the proposed ligand-and-structure combined molecular generative model and the whole computer-aided workflow can potentially be extended to similar tasks for de novo drug design or lead optimization.