 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Pose Uncertainty Aware Movement Synchrony Estimation via Spatial-Temporal Graph Transformer
Aug 01, 2022
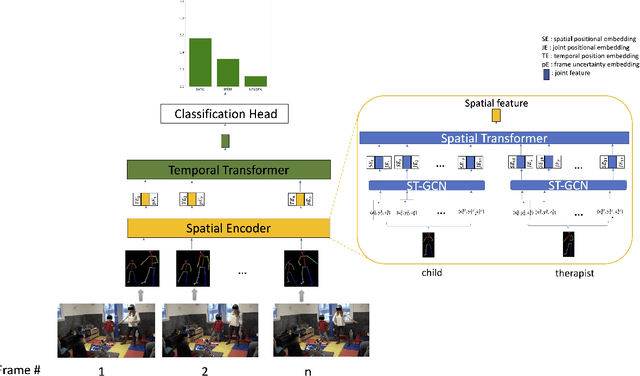
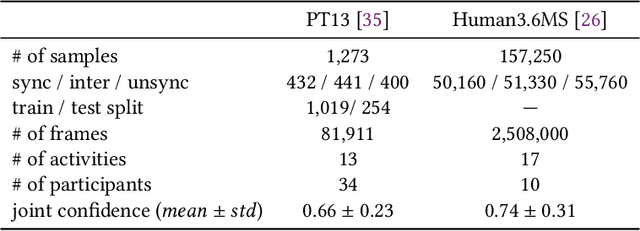
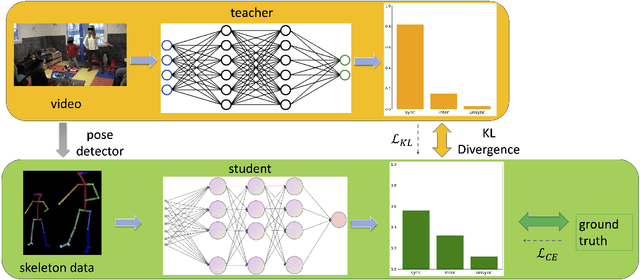
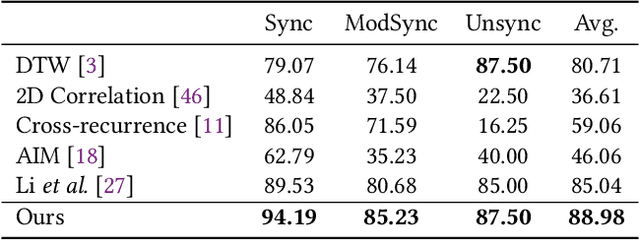
Movement synchrony reflects the coordination of body movements between interacting dyads. The estimation of movement synchrony has been automated by powerful deep learning models such as transformer networks. However, instead of designing a specialized network for movement synchrony estimation, previous transformer-based works broadly adopted architectures from other tasks such as human activity recognition. Therefore, this paper proposed a skeleton-based graph transformer for movement synchrony estimation. The proposed model applied ST-GCN, a spatial-temporal graph convolutional neural network for skeleton feature extraction, followed by a spatial transformer for spatial feature generation. The spatial transformer is guided by a uniquely designed joint position embedding shared between the same joints of interacting individuals. Besides, we incorporated a temporal similarity matrix in temporal attention computation considering the periodic intrinsic of body movements. In addition, the confidence score associated with each joint reflects the uncertainty of a pose, while previous works on movement synchrony estimation have not sufficiently emphasized this point. Since transformer networks demand a significant amount of data to train, we constructed a dataset for movement synchrony estimation using Human3.6M, a benchmark dataset for human activity recognition, and pretrained our model on it using contrastive learning. We further applied knowledge distillation to alleviate information loss introduced by pose detector failure in a privacy-preserving way. We compared our method with representative approaches on PT13, a dataset collected from autism therapy interventions. Our method achieved an overall accuracy of 88.98% and surpassed its counterparts by a wide margin while maintaining data privacy.
Class-incremental Novel Class Discovery
Jul 18, 2022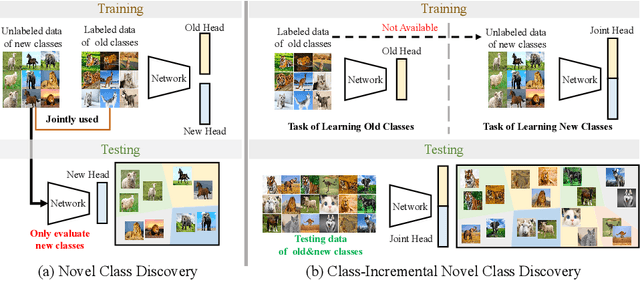
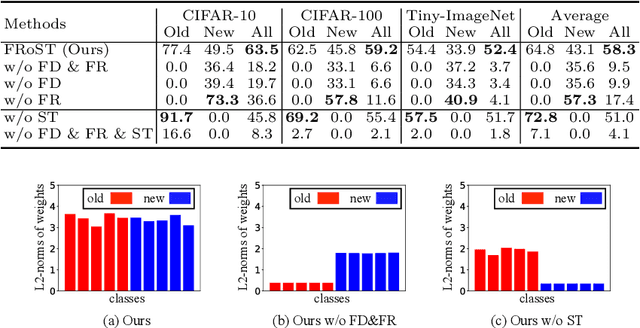
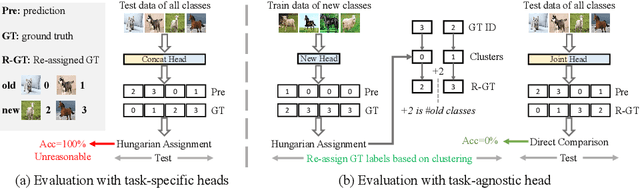

We study the new task of class-incremental Novel Class Discovery (class-iNCD), which refers to the problem of discovering novel categories in an unlabelled data set by leveraging a pre-trained model that has been trained on a labelled data set containing disjoint yet related categories. Apart from discovering novel classes, we also aim at preserving the ability of the model to recognize previously seen base categories. Inspired by rehearsal-based incremental learning methods, in this paper we propose a novel approach for class-iNCD which prevents forgetting of past information about the base classes by jointly exploiting base class feature prototypes and feature-level knowledge distillation. We also propose a self-training clustering strategy that simultaneously clusters novel categories and trains a joint classifier for both the base and novel classes. This makes our method able to operate in a class-incremental setting. Our experiments, conducted on three common benchmarks, demonstrate that our method significantly outperforms state-of-the-art approaches. Code is available at https://github.com/OatmealLiu/class-iNCD
ProtoInfoMax: Prototypical Networks with Mutual Information Maximization for Out-of-Domain Detection
Sep 10, 2021

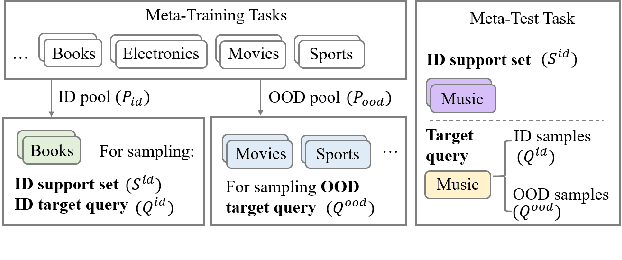
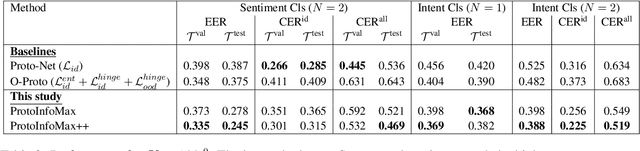
The ability to detect Out-of-Domain (OOD) inputs has been a critical requirement in many real-world NLP applications. For example, intent classification in dialogue systems. The reason is that the inclusion of unsupported OOD inputs may lead to catastrophic failure of systems. However, it remains an empirical question whether current methods can tackle such problems reliably in a realistic scenario where zero OOD training data is available. In this study, we propose ProtoInfoMax, a new architecture that extends Prototypical Networks to simultaneously process in-domain and OOD sentences via Mutual Information Maximization (InfoMax) objective. Experimental results show that our proposed method can substantially improve performance up to 20% for OOD detection in low resource settings of text classification. We also show that ProtoInfoMax is less prone to typical overconfidence errors of Neural Networks, leading to more reliable prediction results.
* This manuscript will be available in ACL Anthology section EMNLP2021-Findings papers
Nature-Inspired Intelligent α-Fair Hybrid Precoding in Multiuser Massive Multiple-Input Multiple-Output Systems
Jul 18, 2022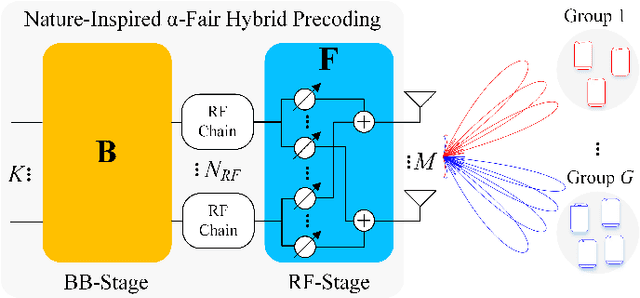
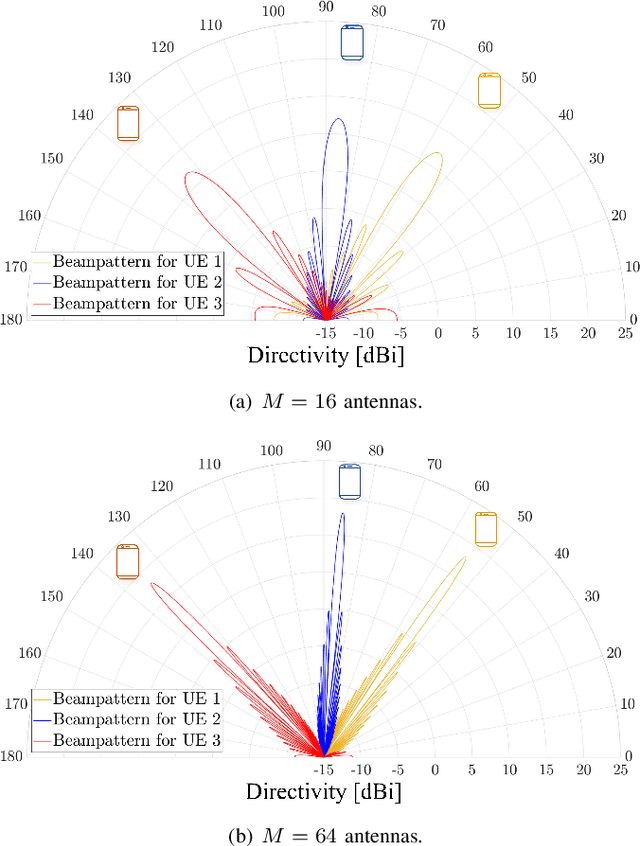
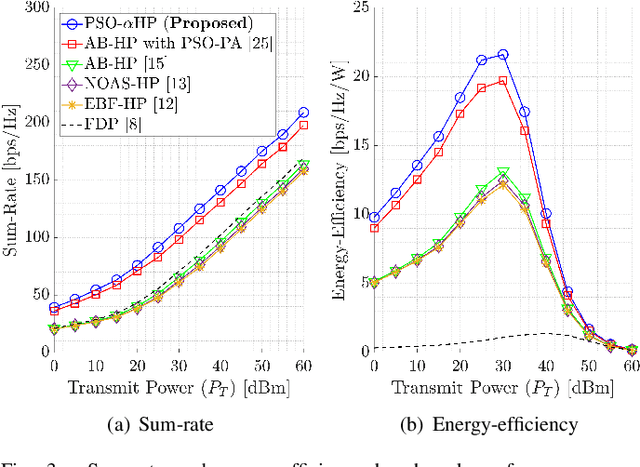
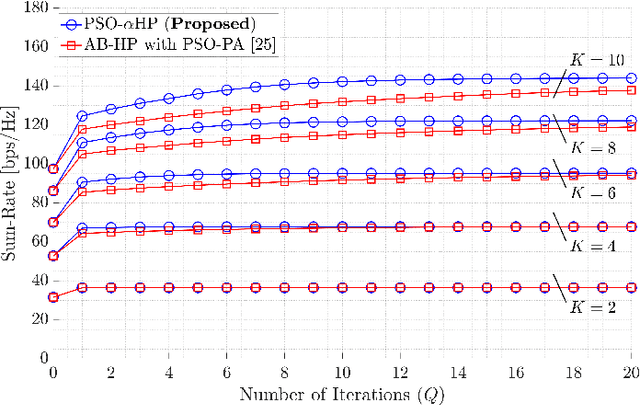
This paper proposes a novel nature-inspired $\alpha$-fair hybrid precoding (NI-$\alpha$HP) technique for millimeter-wave multi-user massive multiple-input multiple-output systems. Unlike the existing HP literature, we propose to apply $\alpha$-fairness for maintaining various fairness expectations (e.g., sum-rate maximization, proportional fairness, max-min fairness, etc.). After developing the analog RF beamformer via slow time-varying angular information, the digital baseband (BB) precoder is designed via the reduced-dimensional effective channel matrix seen from the BB-stage. For the $\alpha$-fairness, we derive the optimal digital BB precoder expression with a set of parameters, where optimizing them is an NP-hard problem. Hence, we efficiently optimize the parameters in the digital BB precoder via five nature-inspired intelligent algorithms. Numerical results present that when the sum-rate maximization is the target, the proposed NI-$\alpha$HP technique greatly improves the sum-rate capacity and energy-efficiency performance compared to other benchmarks. Moreover, NI-$\alpha$HP supports different fairness expectations and reduces the rate gap among UEs by varying the fairness level ($\alpha$).
GPPF: A General Perception Pre-training Framework via Sparsely Activated Multi-Task Learning
Aug 04, 2022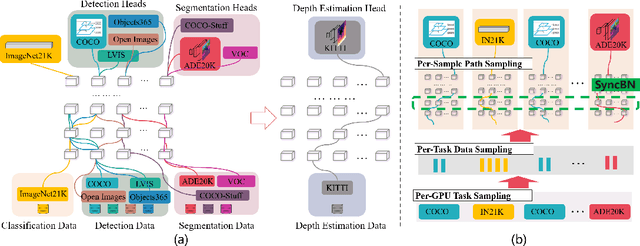
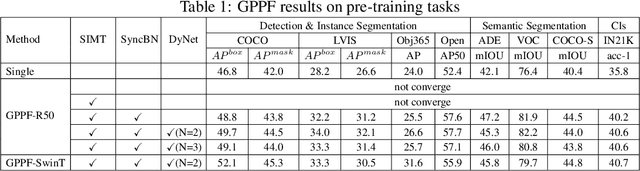
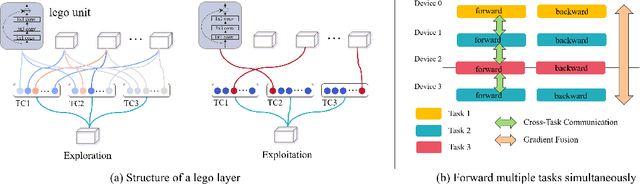
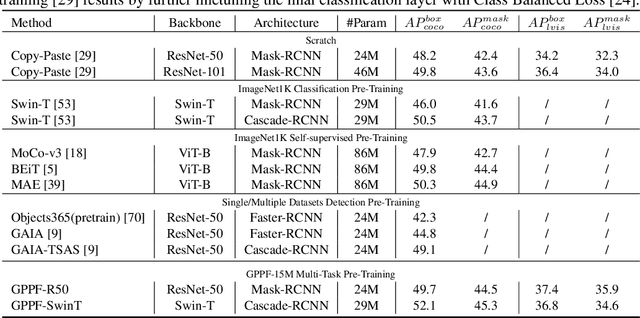
Pre-training over mixtured multi-task, multi-domain, and multi-modal data remains an open challenge in vision perception pre-training. In this paper, we propose GPPF, a General Perception Pre-training Framework, that pre-trains a task-level dynamic network, which is composed by knowledge "legos" in each layers, on labeled multi-task and multi-domain datasets. By inspecting humans' innate ability to learn in complex environment, we recognize and transfer three critical elements to deep networks: (1) simultaneous exposure to diverse cross-task and cross-domain information in each batch. (2) partitioned knowledge storage in separate lego units driven by knowledge sharing. (3) sparse activation of a subset of lego units for both pre-training and downstream tasks. Noteworthy, the joint training of disparate vision tasks is non-trivial due to their differences in input shapes, loss functions, output formats, data distributions, etc. Therefore, we innovatively develop a plug-and-play multi-task training algorithm, which supports Single Iteration Multiple Tasks (SIMT) concurrently training. SIMT lays the foundation of pre-training with large-scale multi-task multi-domain datasets and is proved essential for stable training in our GPPF experiments. Excitingly, the exhaustive experiments show that, our GPPF-R50 model achieves significant improvements of 2.5-5.8 over a strong baseline of the 8 pre-training tasks in GPPF-15M and harvests a range of SOTAs over the 22 downstream tasks with similar computation budgets. We also validate the generalization ability of GPPF to SOTA vision transformers with consistent improvements. These solid experimental results fully prove the effective knowledge learning, storing, sharing, and transfer provided by our novel GPPF framework.
Video + CLIP Baseline for Ego4D Long-term Action Anticipation
Jul 01, 2022
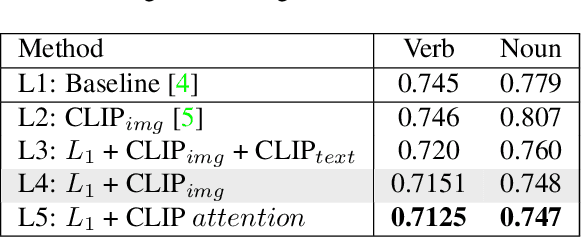
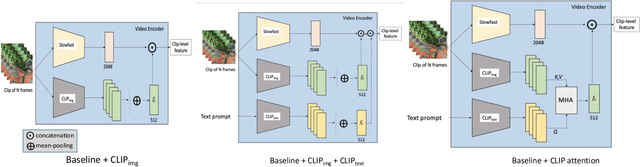
In this report, we introduce our adaptation of image-text models for long-term action anticipation. Our Video + CLIP framework makes use of a large-scale pre-trained paired image-text model: CLIP and a video encoder Slowfast network. The CLIP embedding provides fine-grained understanding of objects relevant for an action whereas the slowfast network is responsible for modeling temporal information within a video clip of few frames. We show that the features obtained from both encoders are complementary to each other, thus outperforming the baseline on Ego4D for the task of long-term action anticipation. Our code is available at github.com/srijandas07/clip_baseline_LTA_Ego4d.
UniFormer: Unified Multi-view Fusion Transformer for Spatial-Temporal Representation in Bird's-Eye-View
Jul 18, 2022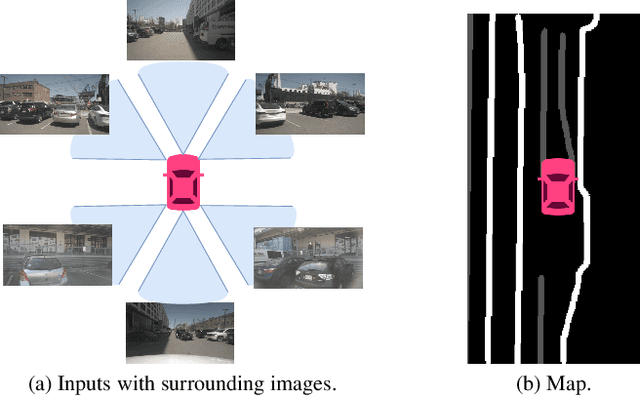

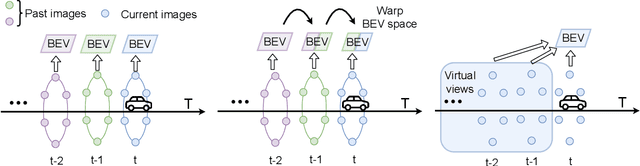
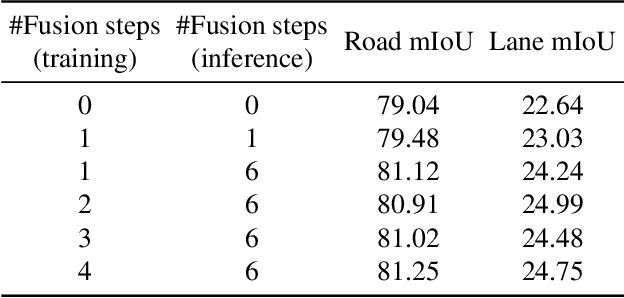
Bird's eye view (BEV) representation is a new perception formulation for autonomous driving, which is based on spatial fusion. Further, temporal fusion is also introduced in BEV representation and gains great success. In this work, we propose a new method that unifies both spatial and temporal fusion and merges them into a unified mathematical formulation. The unified fusion could not only provide a new perspective on BEV fusion but also brings new capabilities. With the proposed unified spatial-temporal fusion, our method could support long-range fusion, which is hard to achieve in conventional BEV methods. Moreover, the BEV fusion in our work is temporal-adaptive, and the weights of temporal fusion are learnable. In contrast, conventional methods mainly use fixed and equal weights for temporal fusion. Besides, the proposed unified fusion could avoid information lost in conventional BEV fusion methods and make full use of features. Extensive experiments and ablation studies on the NuScenes dataset show the effectiveness of the proposed method and our method gains the state-of-the-art performance in the map segmentation task.
Recipe2Vec: Multi-modal Recipe Representation Learning with Graph Neural Networks
May 24, 2022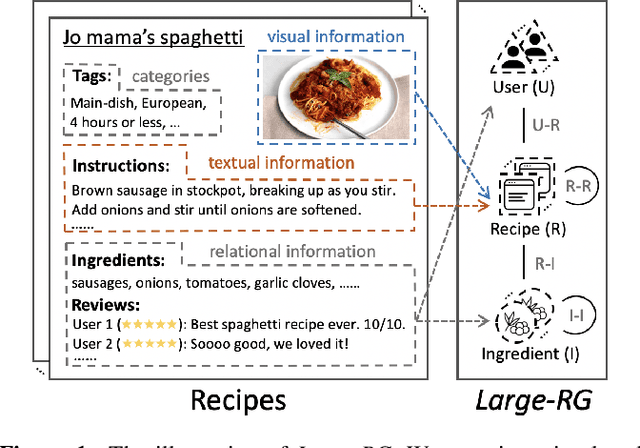
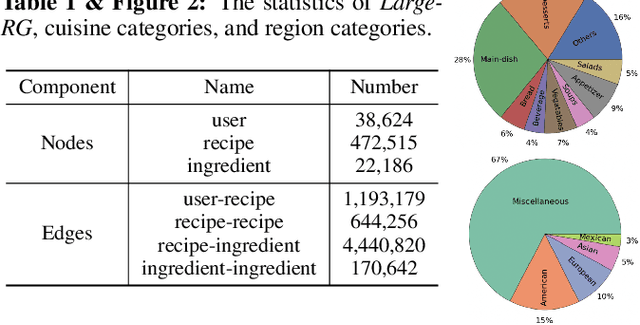
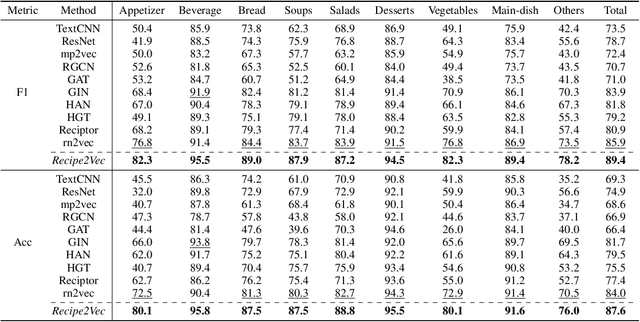
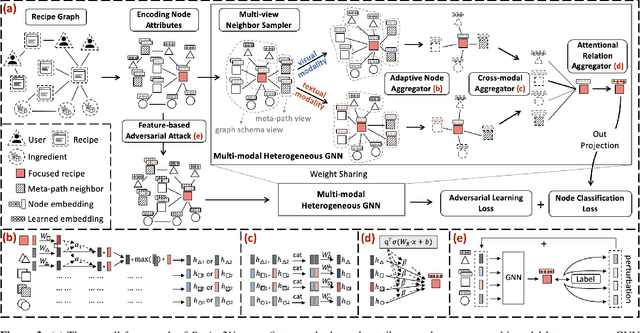
Learning effective recipe representations is essential in food studies. Unlike what has been developed for image-based recipe retrieval or learning structural text embeddings, the combined effect of multi-modal information (i.e., recipe images, text, and relation data) receives less attention. In this paper, we formalize the problem of multi-modal recipe representation learning to integrate the visual, textual, and relational information into recipe embeddings. In particular, we first present Large-RG, a new recipe graph data with over half a million nodes, making it the largest recipe graph to date. We then propose Recipe2Vec, a novel graph neural network based recipe embedding model to capture multi-modal information. Additionally, we introduce an adversarial attack strategy to ensure stable learning and improve performance. Finally, we design a joint objective function of node classification and adversarial learning to optimize the model. Extensive experiments demonstrate that Recipe2Vec outperforms state-of-the-art baselines on two classic food study tasks, i.e., cuisine category classification and region prediction. Dataset and codes are available at https://github.com/meettyj/Recipe2Vec.
MC-GEN:Multi-level Clustering for Private Synthetic Data Generation
May 28, 2022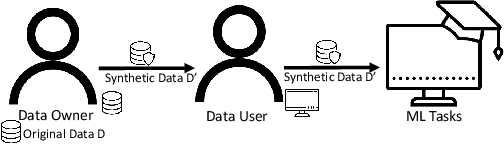


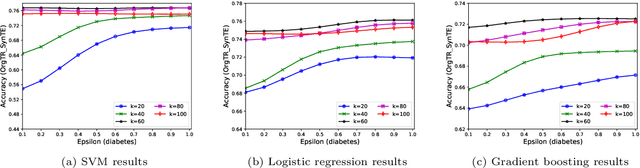
Nowadays, machine learning is one of the most common technology to turn raw data into useful information in scientific and industrial processes. The performance of the machine learning model often depends on the size of dataset. Companies and research institutes usually share or exchange their data to avoid data scarcity. However, sharing original datasets that contain private information can cause privacy leakage. Utilizing synthetic datasets which have similar characteristics as a substitute is one of the solutions to avoid the privacy issue. Differential privacy provides a strong privacy guarantee to protect the individual data records which contain sensitive information. We propose MC-GEN, a privacy-preserving synthetic data generation method under differential privacy guarantee for multiple classification tasks. MC-GEN builds differentially private generative models on the multi-level clustered data to generate synthetic datasets. Our method also reduced the noise introduced from differential privacy to improve the utility. In experimental evaluation, we evaluated the parameter effect of MC-GEN and compared MC-GEN with three existing methods. Our results showed that MC-GEN can achieve significant effectiveness under certain privacy guarantees on multiple classification tasks.
Contextual Bandits with Smooth Regret: Efficient Learning in Continuous Action Spaces
Jul 12, 2022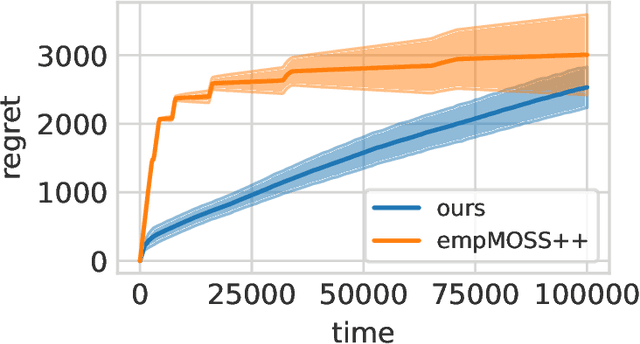
Designing efficient general-purpose contextual bandit algorithms that work with large -- or even continuous -- action spaces would facilitate application to important scenarios such as information retrieval, recommendation systems, and continuous control. While obtaining standard regret guarantees can be hopeless, alternative regret notions have been proposed to tackle the large action setting. We propose a smooth regret notion for contextual bandits, which dominates previously proposed alternatives. We design a statistically and computationally efficient algorithm -- for the proposed smooth regret -- that works with general function approximation under standard supervised oracles. We also present an adaptive algorithm that automatically adapts to any smoothness level. Our algorithms can be used to recover the previous minimax/Pareto optimal guarantees under the standard regret, e.g., in bandit problems with multiple best arms and Lipschitz/H{\"o}lder bandits. We conduct large-scale empirical evaluations demonstrating the efficacy of our proposed algorithms.