 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEmbodied Foundation Models at the Edge: A Survey of Deployment Constraints and Mitigation Strategies
Mar 19, 2026Deploying foundation models in embodied edge systems is fundamentally a systems problem, not just a problem of model compression. Real-time control must operate within strict size, weight, and power constraints, where memory traffic, compute latency, timing variability, and safety margins interact directly. The Deployment Gauntlet organizes these constraints into eight coupled barriers that determine whether embodied foundation models can run reliably in practice. Across representative edge workloads, autoregressive Vision-Language-Action policies are constrained primarily by memory bandwidth, whereas diffusion-based controllers are limited more by compute latency and sustained execution cost. Reliable deployment therefore depends on system-level co-design across memory, scheduling, communication, and model architecture, including decompositions that separate fast control from slower semantic reasoning.
Epi-Curriculum: Episodic Curriculum Learning for Low-Resource Domain Adaptation in Neural Machine Translation
Sep 06, 2023



Neural Machine Translation (NMT) models have become successful, but their performance remains poor when translating on new domains with a limited number of data. In this paper, we present a novel approach Epi-Curriculum to address low-resource domain adaptation (DA), which contains a new episodic training framework along with denoised curriculum learning. Our episodic training framework enhances the model's robustness to domain shift by episodically exposing the encoder/decoder to an inexperienced decoder/encoder. The denoised curriculum learning filters the noised data and further improves the model's adaptability by gradually guiding the learning process from easy to more difficult tasks. Experiments on English-German and English-Romanian translation show that: (i) Epi-Curriculum improves both model's robustness and adaptability in seen and unseen domains; (ii) Our episodic training framework enhances the encoder and decoder's robustness to domain shift.
Towards Implementing Energy-aware Data-driven Intelligence for Smart Health Applications on Mobile Platforms
Feb 01, 2023



Recent breakthrough technological progressions of powerful mobile computing resources such as low-cost mobile GPUs along with cutting-edge, open-source software architectures have enabled high-performance deep learning on mobile platforms. These advancements have revolutionized the capabilities of today's mobile applications in different dimensions to perform data-driven intelligence locally, particularly for smart health applications. Unlike traditional machine learning (ML) architectures, modern on-device deep learning frameworks are proficient in utilizing computing resources in mobile platforms seamlessly, in terms of producing highly accurate results in less inference time. However, on the flip side, energy resources in a mobile device are typically limited. Hence, whenever a complex Deep Neural Network (DNN) architecture is fed into the on-device deep learning framework, while it achieves high prediction accuracy (and performance), it also urges huge energy demands during the runtime. Therefore, managing these resources efficiently within the spectrum of performance and energy efficiency is the newest challenge for any mobile application featuring data-driven intelligence beyond experimental evaluations. In this paper, first, we provide a timely review of recent advancements in on-device deep learning while empirically evaluating the performance metrics of current state-of-the-art ML architectures and conventional ML approaches with the emphasis given on energy characteristics by deploying them on a smart health application. With that, we are introducing a new framework through an energy-aware, adaptive model comprehension and realization (EAMCR) approach that can be utilized to make more robust and efficient inference decisions based on the available computing/energy resources in the mobile device during the runtime.
IMUNet: Efficient Regression Architecture for IMU Navigation and Positioning
Jul 29, 2022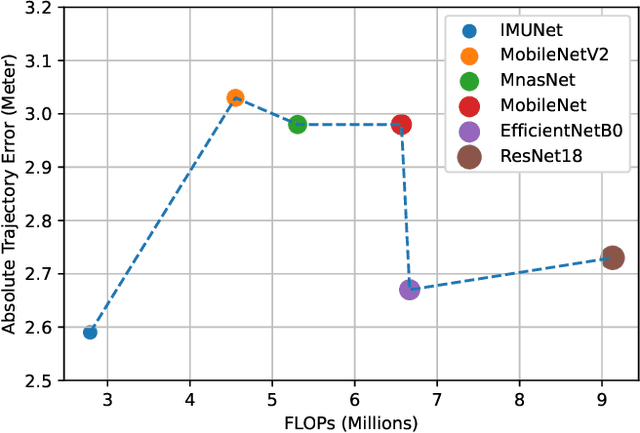
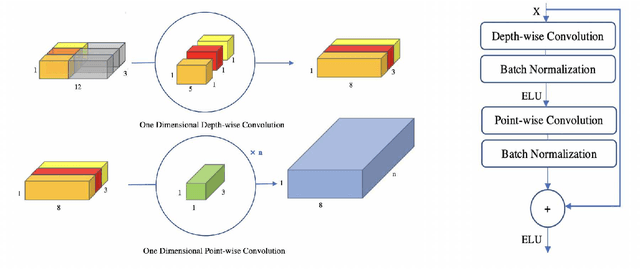
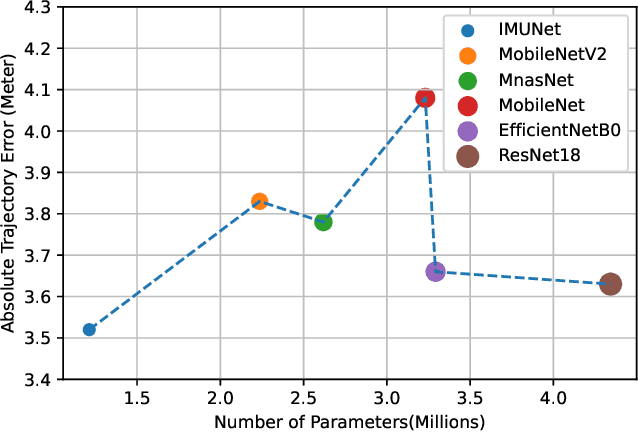

Data-driven based method for navigation and positioning has absorbed attention in recent years and it outperforms all its competitor methods in terms of accuracy and efficiency. This paper introduces a new architecture called IMUNet which is accurate and efficient for position estimation on edge device implementation receiving a sequence of raw IMU measurements. The architecture has been compared with one dimension version of the state-of-the-art CNN networks that have been introduced recently for edge device implementation in terms of accuracy and efficiency. Moreover, a new method for collecting a dataset using IMU sensors on cell phones and Google ARCore API has been proposed and a publicly available dataset has been recorded. A comprehensive evaluation using four different datasets as well as the proposed dataset and real device implementation has been done to prove the performance of the architecture. All the code in both Pytorch and Tensorflow framework as well as the Android application code have been shared to improve further research.
MC-GEN:Multi-level Clustering for Private Synthetic Data Generation
May 28, 2022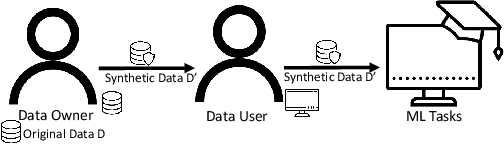


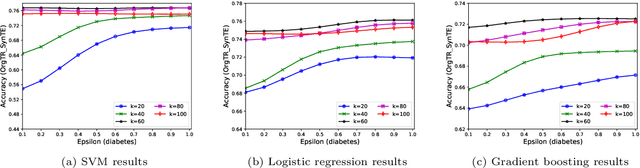
Nowadays, machine learning is one of the most common technology to turn raw data into useful information in scientific and industrial processes. The performance of the machine learning model often depends on the size of dataset. Companies and research institutes usually share or exchange their data to avoid data scarcity. However, sharing original datasets that contain private information can cause privacy leakage. Utilizing synthetic datasets which have similar characteristics as a substitute is one of the solutions to avoid the privacy issue. Differential privacy provides a strong privacy guarantee to protect the individual data records which contain sensitive information. We propose MC-GEN, a privacy-preserving synthetic data generation method under differential privacy guarantee for multiple classification tasks. MC-GEN builds differentially private generative models on the multi-level clustered data to generate synthetic datasets. Our method also reduced the noise introduced from differential privacy to improve the utility. In experimental evaluation, we evaluated the parameter effect of MC-GEN and compared MC-GEN with three existing methods. Our results showed that MC-GEN can achieve significant effectiveness under certain privacy guarantees on multiple classification tasks.
SuperCon: Supervised Contrastive Learning for Imbalanced Skin Lesion Classification
Feb 11, 2022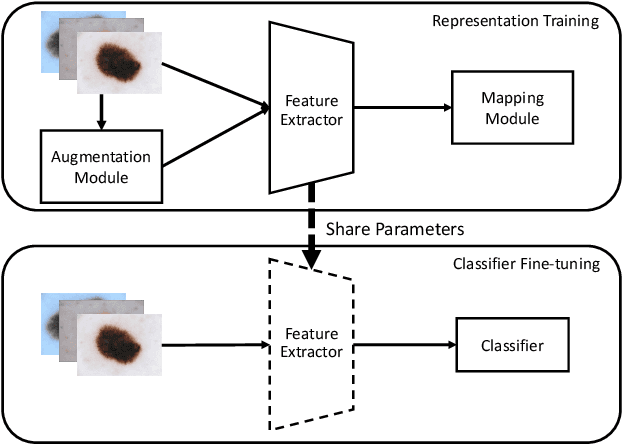
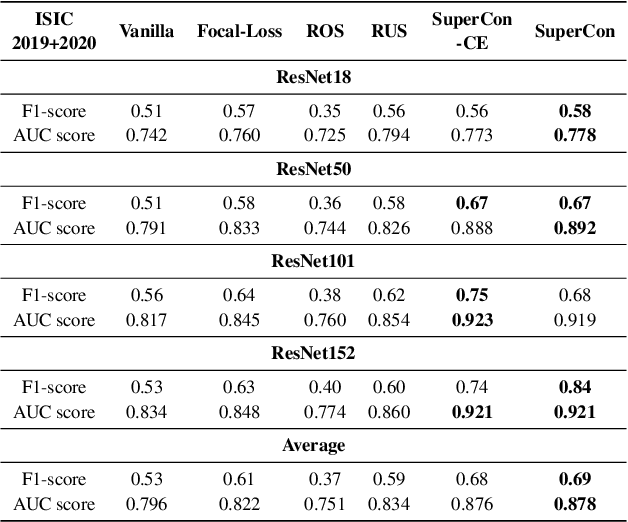

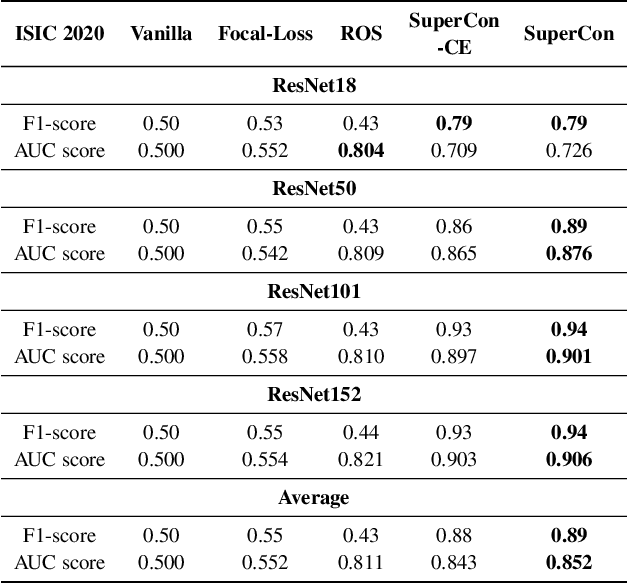
Convolutional neural networks (CNNs) have achieved great success in skin lesion classification. A balanced dataset is required to train a good model. However, due to the appearance of different skin lesions in practice, severe or even deadliest skin lesion types (e.g., melanoma) naturally have quite small amount represented in a dataset. In that, classification performance degradation occurs widely, it is significantly important to have CNNs that work well on class imbalanced skin lesion image dataset. In this paper, we propose SuperCon, a two-stage training strategy to overcome the class imbalance problem on skin lesion classification. It contains two stages: (i) representation training that tries to learn a feature representation that closely aligned among intra-classes and distantly apart from inter-classes, and (ii) classifier fine-tuning that aims to learn a classifier that correctly predict the label based on the learnt representations. In the experimental evaluation, extensive comparisons have been made among our approach and other existing approaches on skin lesion benchmark datasets. The results show that our two-stage training strategy effectively addresses the class imbalance classification problem, and significantly improves existing works in terms of F1-score and AUC score, resulting in state-of-the-art performance.
Locally Differentially Private Distributed Deep Learning via Knowledge Distillation
Feb 07, 2022



Deep learning often requires a large amount of data. In real-world applications, e.g., healthcare applications, the data collected by a single organization (e.g., hospital) is often limited, and the majority of massive and diverse data is often segregated across multiple organizations. As such, it motivates the researchers to conduct distributed deep learning, where the data user would like to build DL models using the data segregated across multiple different data owners. However, this could lead to severe privacy concerns due to the sensitive nature of the data, thus the data owners would be hesitant and reluctant to participate. We propose LDP-DL, a privacy-preserving distributed deep learning framework via local differential privacy and knowledge distillation, where each data owner learns a teacher model using its own (local) private dataset, and the data user learns a student model to mimic the output of the ensemble of the teacher models. In the experimental evaluation, a comprehensive comparison has been made among our proposed approach (i.e., LDP-DL), DP-SGD, PATE and DP-FL, using three popular deep learning benchmark datasets (i.e., CIFAR10, MNIST and FashionMNIST). The experimental results show that LDP-DL consistently outperforms the other competitors in terms of privacy budget and model accuracy.
COVID-19 Pneumonia Severity Prediction using Hybrid Convolution-Attention Neural Architectures
Jul 07, 2021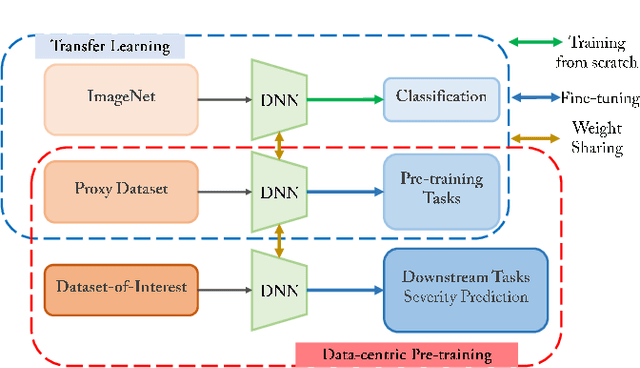
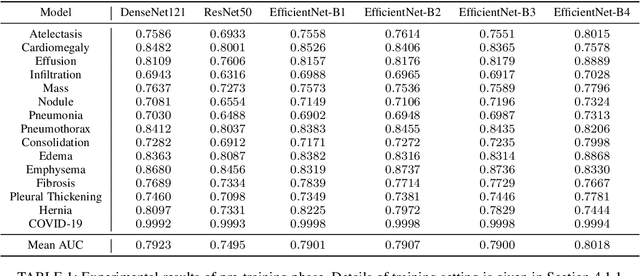
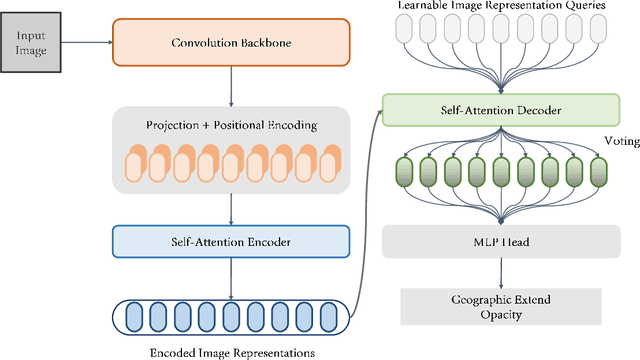
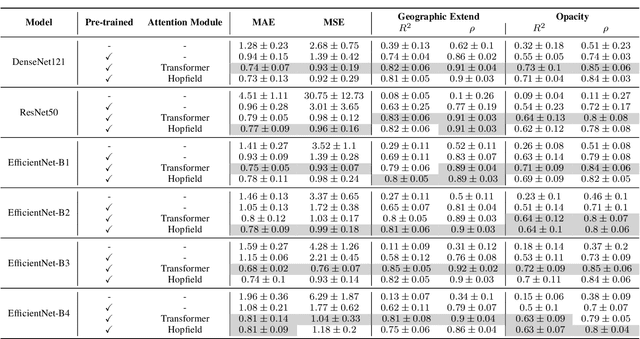
This study proposed a novel framework for COVID-19 severity prediction, which is a combination of data-centric and model-centric approaches. First, we propose a data-centric pre-training for extremely scare data scenarios of the investigating dataset. Second, we propose two hybrid convolution-attention neural architectures that leverage the self-attention from the Transformer and the Dense Associative Memory (Modern Hopfield networks). Our proposed approach achieves significant improvement from the conventional baseline approach. The best model from our proposed approach achieves $R^2 = 0.85 \pm 0.05$ and Pearson correlation coefficient $\rho = 0.92 \pm 0.02$ in geographic extend and $R^2 = 0.72 \pm 0.09, \rho = 0.85\pm 0.06$ in opacity prediction.
ESAI: Efficient Split Artificial Intelligence via Early Exiting Using Neural Architecture Search
Jun 21, 2021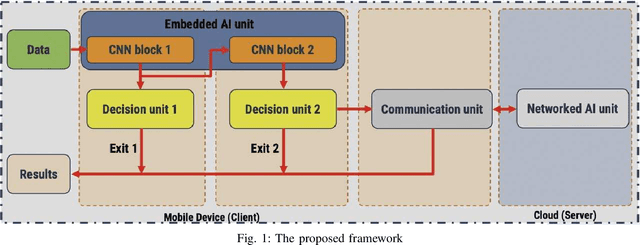
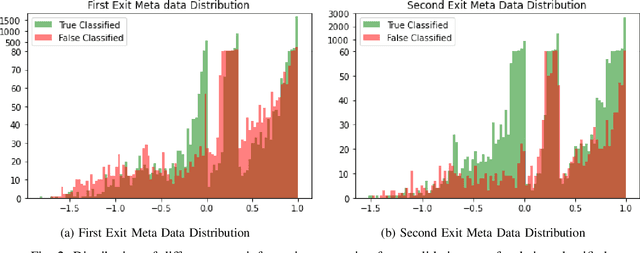
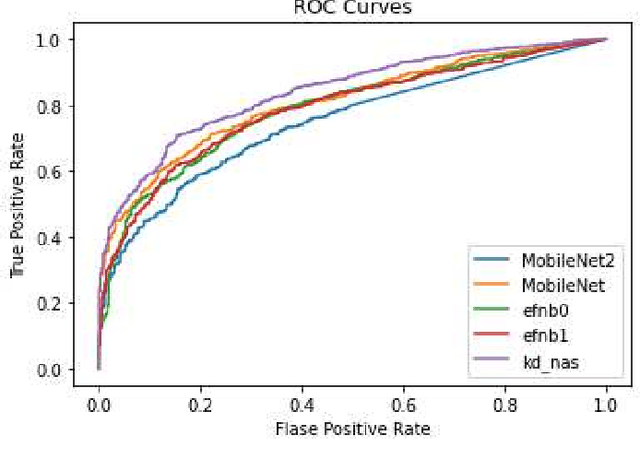
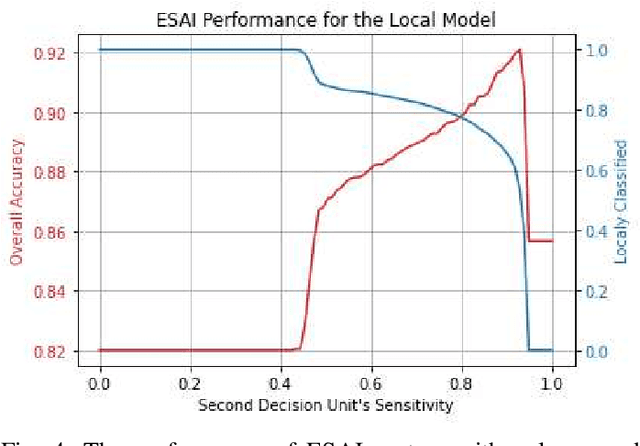
Recently, deep neural networks have been outperforming conventional machine learning algorithms in many computer vision-related tasks. However, it is not computationally acceptable to implement these models on mobile and IoT devices and the majority of devices are harnessing the cloud computing methodology in which outstanding deep learning models are responsible for analyzing the data on the server. This can bring the communication cost for the devices and make the whole system useless in those times where the communication is not available. In this paper, a new framework for deploying on IoT devices has been proposed which can take advantage of both the cloud and the on-device models by extracting the meta-information from each sample's classification result and evaluating the classification's performance for the necessity of sending the sample to the server. Experimental results show that only 40 percent of the test data should be sent to the server using this technique and the overall accuracy of the framework is 92 percent which improves the accuracy of both client and server models.
A compressive multi-kernel method for privacy-preserving machine learning
Jun 20, 2021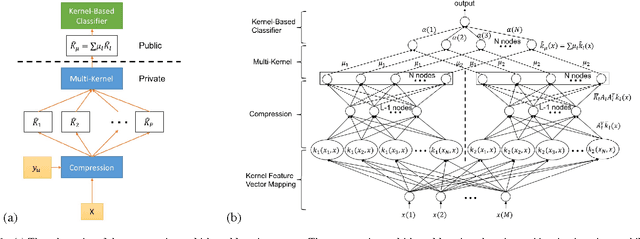
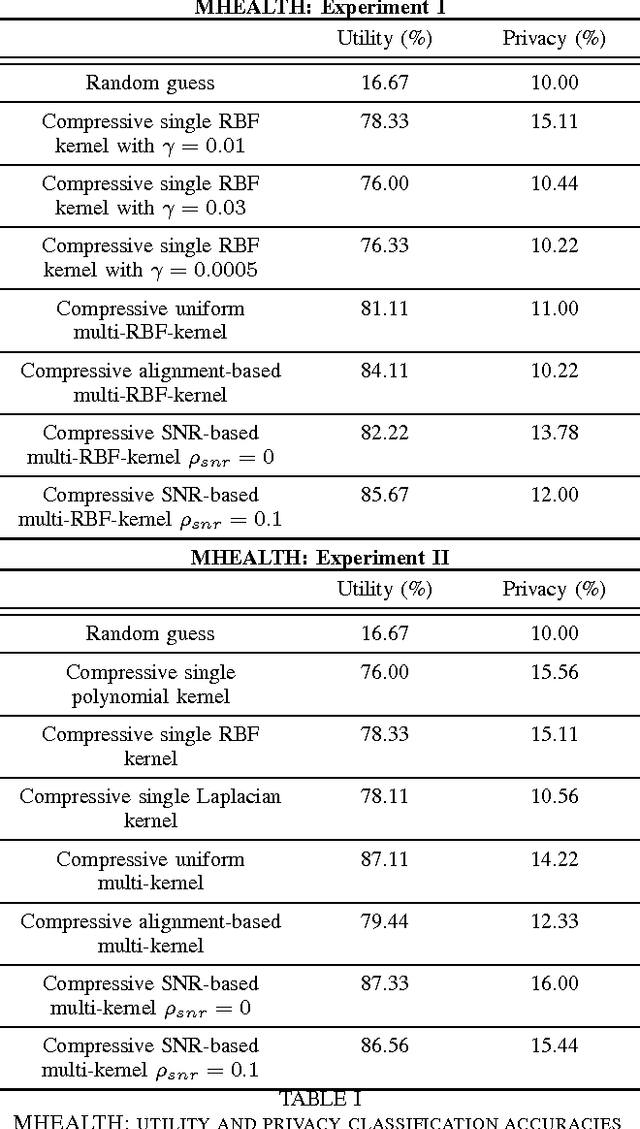
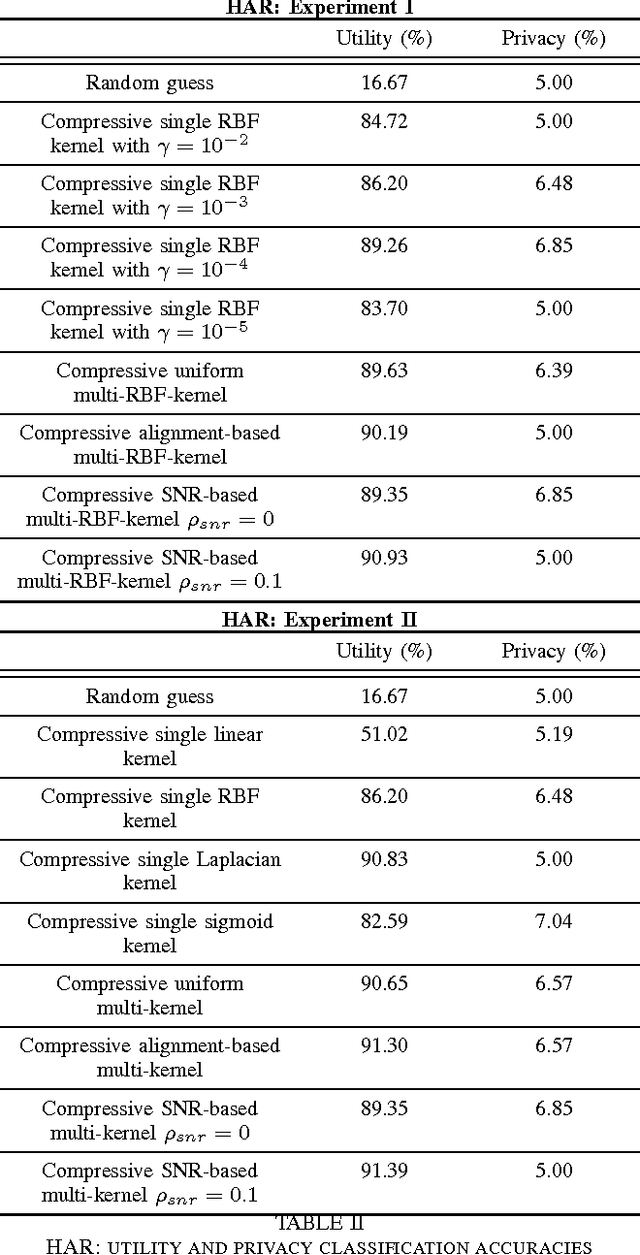
As the analytic tools become more powerful, and more data are generated on a daily basis, the issue of data privacy arises. This leads to the study of the design of privacy-preserving machine learning algorithms. Given two objectives, namely, utility maximization and privacy-loss minimization, this work is based on two previously non-intersecting regimes -- Compressive Privacy and multi-kernel method. Compressive Privacy is a privacy framework that employs utility-preserving lossy-encoding scheme to protect the privacy of the data, while multi-kernel method is a kernel based machine learning regime that explores the idea of using multiple kernels for building better predictors. The compressive multi-kernel method proposed consists of two stages -- the compression stage and the multi-kernel stage. The compression stage follows the Compressive Privacy paradigm to provide the desired privacy protection. Each kernel matrix is compressed with a lossy projection matrix derived from the Discriminant Component Analysis (DCA). The multi-kernel stage uses the signal-to-noise ratio (SNR) score of each kernel to non-uniformly combine multiple compressive kernels. The proposed method is evaluated on two mobile-sensing datasets -- MHEALTH and HAR -- where activity recognition is defined as utility and person identification is defined as privacy. The results show that the compression regime is successful in privacy preservation as the privacy classification accuracies are almost at the random-guess level in all experiments. On the other hand, the novel SNR-based multi-kernel shows utility classification accuracy improvement upon the state-of-the-art in both datasets. These results indicate a promising direction for research in privacy-preserving machine learning.